StarRocks中有趣的点
最近在工作中,遇到有小伙伴使用StarRocks,所以看了下文档,感觉以下几点比较有趣。
支持MySQL协议
想必是为了通用性,StarRocks 提供MySQL协议接口,支持标准SQL语法。即可通过MySQL客户端连接StarRocks,并执行SQL。
版本升级
StarRocks目前有两个版本,旧版本在数据存储方面有劣势,存在冗余数据。
优化后的版本将数据部分抽离了出来。支持使用hdfs进行存储。
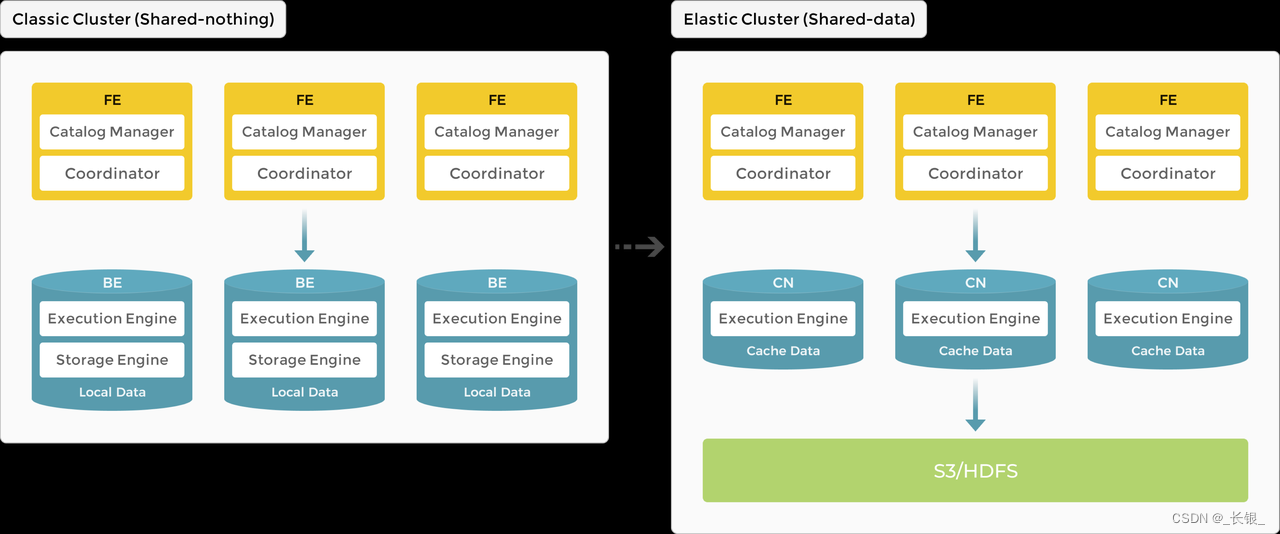
可用性概念
为了保证可用性及响应性能,多节点使用时仍用到了主从的概念。
如下表格来自官方文档,其中选举的部分还是值得了解一下的。
| FE 角色 | 元数据读写 | Leader 选举 |
| Leader | Leader FE 提供元数据读写服务,Follower 和 Observer 只有读取权限,无写入权限。Follower 和 Observer 将元数据写入请求路由到 Leader,Leader 更新完元数据后,会通过 BDB JE (Berkeley DB Java Edition) 同步给 Follower 和 Observer。必须有半数以上的 Follower 节点同步成功才算作元数据写入成功。 | Leader 从 Follower 中自动选出。如果当前 Leader 节点失败,Follower 会发起新一轮选举。 |
| Follower | 只有元数据读取权限,无写入权限。通过回放 Leader 的元数据日志来异步同步数据。 | Follower 参与 Leader 选举,会通过类 Paxos 的 BDBJE 协议自动选举出一个 Leader,必须有半数以上的 Follower 节点存活才能进行选主。 |
| Observer | 同 Follower。 | Observer 主要用于扩展集群的查询并发能力,可选部署。Observer 不参与选主,不会增加集群的选主压力。 |
高性能原理
下面一段话摘自官方原文:
“在执行 SQL 计算时,一条 SQL 语句首先会按照语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在对应的 BE 节点上执行,这样可以实现本地计算,避免数据的传输与拷贝,从而得到极速的查询性能。”
SQL的拆分执行是一种非常有趣的思路,实质是以空间换时间的手法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Modbus协议的数据模型和地址模型,Modbus寄存器40001,30001是什么意思?
- RuntimeError: GET was unable to find an engine to execute this computation
- Win10恢复环境是什么?
- Qt实现的聊天画面消息气泡
- Autosar通信实战系列08-Com模块相关开发问题总结
- 高性能、可扩展、支持二次开发的企业电子招标采购系统源码
- Python文件操作
- springboot/java/php/node/python基于SpringBoot共享单车管理信息平台【计算机毕设】
- C++day1
- TensorFlow 入门:Hello TensorFlow 编程