基于策略模式和简单工厂模式实现zip、tar、rar、7z四种压缩文件格式的解压

推荐语
这篇技术文章深入探讨了基于策略模式和简单工厂模式实现四种常见压缩文件格式的解压方法。通过阅读该文章,你将了解到如何利用这两种设计模式来实现灵活、可扩展的解压功能,同时适应不同的压缩文件格式。如果你对设计模式和文件处理感兴趣或刚好碰到类似的情况,那么这篇文章绝对值得一读。它会为你打开一个新的思路,并帮助你提升在软件开发中的技能和效率。
需求描述与分析
最近我遇到了一个需求,需要上传一个压缩包文件,其中包含目录和文件。上传成功后,后台会自动解压该文件,并保持压缩包内目录和文件的结构不变,然后将该结构渲染到页面上。
这个需求其实相对来说非常简单,实现起来并不困难。为了满足需求,我们需要解决以下三个问题:
- 压缩包文件有多种格式,例如ZIP、RAR、TAR等等,我们需要支持哪些格式?
- 如何选择合适的技术或工具来自动化地解压这些不同格式的文件?
- 在解压压缩包的同时,如何解析出里面的目录、文件之间的关系和结构,以便被正确地渲染到前端页面上?
实现原理
先解决第一个问题:压缩包文件的格式有很多,要支持多少种?
下面这四种相对比较常见,支持解析的格式暂时定为这四种:
- ZIP (.zip):ZIP 是最常见的压缩文件格式之一,多数操作系统都默认支持它。ZIP 文件通常用于在网络或电子邮件中传输文件,以及在本地计算机上备份和存档文件。
- TAR (.tar):TAR 是一种用于将多个文件和文件夹打包成一个单独的文件的文件格式。与其他压缩格式不同,TAR 不会对文件进行压缩,仅用于打包和归档文件。
- RAR (.rar):RAR 是另一种常见的压缩文件格式,它可以压缩许多文件,并提供比 ZIP 更好的压缩率。RAR 格式通常用于将大型文件分成多个部分,以便在互联网上分发和下载。
- 7Z (.7z):7Z 是一种开源的压缩文件格式,可提供比其他压缩文件格式更高的压缩率。7Z 文件通常用于压缩大型文件和文件夹,以便在网络上传输和存储。
第二个问题:如何解压这些不同格式的文件?
支付的压缩文件的格式暂定为上面四种格式的压缩包文件那如何对这些不同格式的压缩包文件进行解压操作呢?如文章标题,基于策略模式和 简单工厂模式先实现上面四种格式的压缩文件解压,具体怎么实现呢?
- 定义一个解压策略的抽象接口,内部定义一个抽象方法,作用是执行解压操作,但是这里不提供具体实现,具体实现由不同格式的具体解压策略来实现,这个方法的输入参数采用java标准的输入流,方便与其他业务对象,输出参数则是一个List集合类型,集合内存储的是解压文件的FileObj对象;
- 分别根据四种压缩文件格式,定义四个不同的解压策略实现类,这四个解压策略实现类来实现上面的解压策略抽象接口,重写接口的抽象方法,方法的业务逻辑是来执行具体格式的压缩文件的解压操作;
- 再定义一个解压策略的简单工厂类,用于根据不同的后缀,生成不同的解压策略,这个工工厂类最大的意义莫过于实现了解压客户端业务与具体解压操作的解耦;如果后续业务变更,需要新增其他格式的压缩文件解压,可以实现一个具体的解压策略类,然后再扩展一下这里的工厂类;解压客户端业务不需要做任何变更,这也符合设计模式中的单一职责;
第三个问题:压缩包文件解压的同时,怎么解析出压缩包里面的目录、文件的关系和结构?
- 从压缩包文件中解析出文件后,解压结果是一个包含FileObj对象的集合,FileObj对象包含了三个属性:1、文件在压缩包内的全路径(包含有文件名称、后缀);2、文件后缀;3、文件的全部字节(这里封装为字节的目的是方便,后面的处理,如写入本地、写入远程文件服务器等);
- 从解析结果中提取出文件在压缩包内的全路径;然后再进一步处理,转换为一个包含FileDir类型对象的集合,FileDir对象中有两个重要属性当前文件或目录的唯一标识和其父级的唯一标识,据此可以构建出一个树形结构,也就还原了压缩包里面的目录、文件的关第和结构;
实现方案
mavne依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.24.0</version>
</dependency>
<dependency>
<groupId>net.sf.sevenzipjbinding</groupId>
<artifactId>sevenzipjbinding</artifactId>
<version>16.02-2.01</version>
</dependency>
<dependency>
<groupId>org.tukaani</groupId>
<artifactId>xz</artifactId>
<version>1.9</version>
</dependency>
<dependency>
<groupId>com.github.junrar</groupId>
<artifactId>junrar</artifactId>
<version>7.5.5</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>net.sf.sevenzipjbinding</groupId>
<artifactId>sevenzipjbinding-all-platforms</artifactId>
<version>16.02-2.01</version>
</dependency>
<dependency>
<groupId>org.apache.ant</groupId>
<artifactId>ant</artifactId>
<version>1.10.12</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.23</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.6</version>
</dependency>FileObj和FileDir
FileObj:从压缩包中解压出的每一个文件,封装到一个FileObj对象中,FileObj对象有三个属性:1、文件在压缩包内的全路径(包含有文件名称、后缀);2、文件后缀;3、文件的全部字节(这里封装为字节的目的是方便,后面的处理,如写入本地、写入远程文件服务器等)
@Data
public class FileObj {
/**
* 压缩包内文件全路径
*/
private String filePath;
/**
* 压缩包内文件后缀
*/
private String suffix;
/**
* 压缩包内文件的字节
*/
private byte[] bytes;
}FileDir:把压缩包文件里的每一个目录封装成一个FileDir对象,FileDir对象包有六个属性:1、目录名称;2、目录级别,根目录为1,其子目录依次递增;3、父级目录的名称,如果是根目录,则父级目录为空;4、目录的唯一标识;5、父级目录的唯一标识;6、当前节点的孩子节点;这里注意一下要重写一个hashCode和equals方法,因为在解析压缩文件内的目录、文件的关系和结构时,使用了Set集合的去重功能;
@Data
public class FileDir{
/**
* 类型,1:目录;2:文件;
*/
private Integer docType=1;
/**
* 目录名称
*/
private String docName;
/**
* 目录级别,根目录为1,其子目录依次递增
*/
private Integer level;
/**
* 父级目录名称
*/
private String parentDocName;
/**
* 目录唯一标识
*/
private Long id;
/**
* 父级目录唯一标识
*/
private Long parentId;
/**
* 当前节点的孩子节点
*/
private List<FileDir> children;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
FileDir fileDir = (FileDir) o;
if (!Objects.equals(docType, fileDir.docType)) return false;
if (!Objects.equals(docName, fileDir.docName)) return false;
if (!Objects.equals(level, fileDir.level)) return false;
if (!Objects.equals(parentDocName, fileDir.parentDocName))
return false;
if (!Objects.equals(id, fileDir.id)) return false;
if (!Objects.equals(parentId, fileDir.parentId)) return false;
return Objects.equals(children, fileDir.children);
}
@Override
public int hashCode() {
int result = docType != null ? docType.hashCode() : 0;
result = 31 * result + (docName != null ? docName.hashCode() : 0);
result = 31 * result + (level != null ? level.hashCode() : 0);
result = 31 * result + (parentDocName != null ? parentDocName.hashCode() : 0);
result = 31 * result + (id != null ? id.hashCode() : 0);
result = 31 * result + (parentId != null ? parentId.hashCode() : 0);
result = 31 * result + (children != null ? children.hashCode() : 0);
return result;
}
}
UnZipStrategy
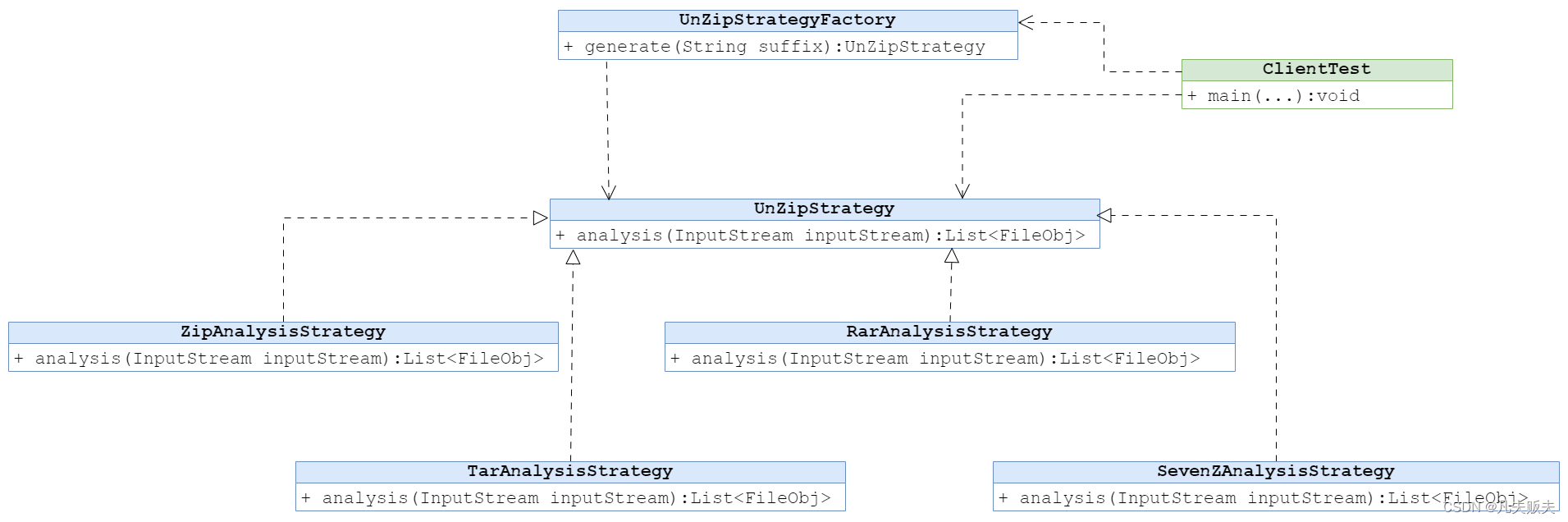
UnZipStrategy:是解压策略的抽象接口,内部定义一个抽象方法,作用是执行解压操作,具体实现由不同格式的具体解压策略来实现,这个方法的输入参数采用java标准的输入流,方便与其他业务对象,输出参数则是一个List集合类型,集合内存储的是解压文件的FileObj对象;
public interface UnZipStrategy {
List<FileObj> analysis(InputStream inputStream);
}ZipAnalysisStrategy
ZipAnalysisStrategy:是zip格式的压缩文件的解压策略,实现UnZipStrategy抽象接口,具体来执行zip格式的压缩文件的解压操作;
@Slf4j
public class ZipAnalysisStrategy implements UnZipStrategy {
@Override
public List<FileObj> analysis(InputStream inputStream) {
List<FileObj> list = new ArrayList<>();
ArchiveInputStream ais = new ZipArchiveInputStream(inputStream);
ArchiveEntry entry;
try {
while ((entry = ais.getNextEntry()) != null) {
if (!entry.isDirectory()) {
FileObj fileObj = extractFile(ais, entry);
list.add(fileObj);
}
}
ais.close();
inputStream.close();
} catch (IOException e) {
log.error("zip格式压缩文件在解压时发生错误:",e);
throw new RuntimeException(e);
}
return list;
}
private FileObj extractFile(ArchiveInputStream ais, ArchiveEntry entry) throws IOException {
String name = entry.getName();
log.info("解析文件:{}",name);
int index = name.lastIndexOf(".");
String suffix = name.substring(index + 1);
FileObj fileObj = new FileObj();
fileObj.setFilePath(entry.getName());
fileObj.setSuffix(suffix);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = ais.read(buffer)) > 0) {
byteArrayOutputStream.write(buffer, 0, length);
}
byte[] bytes = byteArrayOutputStream.toByteArray();
fileObj.setBytes(bytes);
byteArrayOutputStream.close();
return fileObj;
}
}TarAnalysisStrategy
TarAnalysisStrategy:是tar格式的压缩文件的解压策略,实现UnZipStrategy抽象接口,具体来执行tar格式的压缩文件的解压操作;
@Slf4j
public class TarAnalysisStrategy implements UnZipStrategy {
@Override
public List<FileObj> analysis(InputStream inputStream) {
List<FileObj> list=new ArrayList<>();
FileObj fileObj;
TarInputStream tarInputStream = new TarInputStream(inputStream, 1024 * 2);
TarEntry entry;
try {
while ((entry = tarInputStream.getNextEntry()) != null) {
if (!entry.isDirectory()) {
fileObj=new FileObj();
String name = entry.getName();
int index = name.lastIndexOf(".");
String suffix = name.substring(index + 1);
fileObj.setFilePath(name);
fileObj.setSuffix(suffix);
int count;
byte data[] = new byte[2048];
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
while ((count = tarInputStream.read(data)) != -1) {
outputStream.write(data, 0, count);
}
byte[] byteArray = outputStream.toByteArray();
outputStream.close();
fileObj.setBytes(byteArray);
list.add(fileObj);
}
}
inputStream.close();
tarInputStream.close();
} catch (IOException e) {
log.error("tar格式压缩文件在解压时发生错误:",e);
throw new RuntimeException(e);
}
return list;
}
}SevenZAnalysisStrategy
SevenZAnalysisStrategy:是7z格式的压缩文件的解压策略,实现UnZipStrategy抽象接口,具体来执行7z格式的压缩文件的解压操作;
@Slf4j
public class SevenZAnalysisStrategy implements UnZipStrategy {
@Override
public List<FileObj> analysis(InputStream inputStream) {
List<FileObj> list = new ArrayList<>();
FastByteArrayOutputStream read = IoUtil.read(inputStream);
byte[] byteArray = read.toByteArray();
SeekableInMemoryByteChannel seekableInMemoryByteChannel = new SeekableInMemoryByteChannel(byteArray);
try {
SevenZFile sevenZFile = new SevenZFile(seekableInMemoryByteChannel);
// 创建输出目录
SevenZArchiveEntry entry;
while ((entry = sevenZFile.getNextEntry()) != null) {
if (!entry.isDirectory()) {
FileObj fileObj = new FileObj();
String name = entry.getName();
log.info("解析文件:{}",name);
int index = name.lastIndexOf(".");
String suffix = name.substring(index + 1);
fileObj.setFilePath(name);
fileObj.setSuffix(suffix);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
int len = 0;
byte[] b = new byte[2048];
while ((len = sevenZFile.read(b)) != -1) {
outputStream.write(b, 0, len);
}
byte[] bytes = outputStream.toByteArray();
outputStream.close();
fileObj.setBytes(bytes);
list.add(fileObj);
}
}
inputStream.close();
read.close();
seekableInMemoryByteChannel.close();
} catch (IOException e) {
log.error("7z格式的压缩文件在解压时发生错误:",e);
throw new RuntimeException(e);
}
return list;
}
}RarAnalysisStrategy
RarAnalysisStrategy:是rar格式的压缩文件的解压策略,实现UnZipStrategy抽象接口,具体来执行rar格式的压缩文件的解压操作;这个格式的压缩文件解压起来稍微有点费力,用到了一个回调RarExtractCallback类,这个RarExtractCallback类实现IArchiveExtractCallback接口,重写getStream()和setOperationResult(),来实现压缩文件的解压;
@Slf4j
public class RarAnalysisStrategy implements UnZipStrategy {
@Override
public List<FileObj> analysis(InputStream inputStream) {
try {
byte[] bytes = IoUtil.readBytes(inputStream);
ByteArrayStream byteArrayStream = new ByteArrayStream(bytes, false);
IInArchive inArchive = SevenZip.openInArchive(null, byteArrayStream);
int[] in = new int[inArchive.getNumberOfItems()];
for (int i = 0; i < in.length; i++) {
in[i] = i;
}
//使用回调函数
RarExtractCallback rarExtractCallback = new RarExtractCallback(inArchive);
inArchive.extract(in, false, rarExtractCallback);
byteArrayStream.close();
inputStream.close();
return rarExtractCallback.getFileObjs();
} catch (IOException e) {
log.error("rar格式的压缩文件在解压时发生错误:", e);
throw new RuntimeException(e);
}
}
}@Slf4j
public class RarExtractCallback implements IArchiveExtractCallback {
private Integer index;
private IInArchive inArchive;
private ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
@Getter
private List<FileObj> fileObjs=new ArrayList<>();
public RarExtractCallback(IInArchive inArchive) {
this.inArchive = inArchive;
}
@Override
public void setCompleted(long arg0) throws SevenZipException {
}
@Override
public void setTotal(long arg0) throws SevenZipException {
}
@Override
public ISequentialOutStream getStream(int index, ExtractAskMode extractAskMode) throws SevenZipException {
this.index=index;
boolean isFolder = (boolean) inArchive.getProperty(index, PropID.IS_FOLDER);
return data -> {
if (!isFolder) {
try {
outputStream.write(data);
} catch (IOException e) {
log.error("rar格式的压缩文件在解压时发生错误:",e);
throw new RuntimeException(e);
}
}
return data.length;
};
}
@Override
public void prepareOperation(ExtractAskMode arg0) throws SevenZipException {
}
@Override
public void setOperationResult(ExtractOperationResult extractOperationResult) throws SevenZipException {
String path = (String) inArchive.getProperty(index, PropID.PATH);
boolean isFolder = (boolean) inArchive.getProperty(index, PropID.IS_FOLDER);
if (!isFolder) {
FileObj fileObj=new FileObj();
fileObj.setFilePath(path);
log.info("解析文件:{}",path);
int index1 = path.lastIndexOf(".");
String suffix = path.substring(index1 + 1);
fileObj.setSuffix(suffix);
byte[] byteArray = outputStream.toByteArray();
outputStream.reset();
fileObj.setBytes(byteArray);
fileObjs.add(fileObj);
}
}
}UnZipStrategyFactory
UnZipStrategyFactory:解压策略的简单工厂类,用于根据不同的后缀,生成不同的解压策略,最大的意义莫过于实现了解压主业务与具体解压操作的解耦;
public class UnZipStrategyFactory {
public static UnZipStrategy generate(String suffix){
UnZipStrategy strategy;
switch (suffix){
case "zip":
strategy=new ZipAnalysisStrategy();
break;
case "tar":
strategy=new TarAnalysisStrategy();
break;
case "rar":
strategy=new RarAnalysisStrategy();
break;
case "7z":
strategy=new SevenZAnalysisStrategy();
break;
default:
strategy=null;
break;
}
return strategy;
}
}FileDirProcessor
FileDirProcessor:用于从压缩包里解压出的文件列表里,解析出目录与文件的结构,即包含FileDir对象的集合;
public class FileDirProcessor {
public static List<FileDir> process(List<String> list) {
//解析和去重
Set<FileDir> sets = new HashSet<>();
if (CollUtil.isNotEmpty(list)) {
for (String dirStr : list) {
String[] split = dirStr.split("/");
if (split.length > 0) {
if (split.length == 1) {
FileDir fileDir = new FileDir();
fileDir.setDocName(split[0]);
fileDir.setDocType(2);
fileDir.setLevel(1);
fileDir.setParentDocName("");
sets.add(fileDir);
} else {
for (int i = 0; i < split.length; i++) {
FileDir fileDir = new FileDir();
fileDir.setDocName(split[i]);
fileDir.setLevel(i + 1);
fileDir.setDocType(1);
if (i == 0) {
fileDir.setParentDocName("");
}
if (i == (split.length - 1)) {
fileDir.setDocType(2);
fileDir.setParentDocName(split[i - 1]);
}
if (i != 0 && i != split.length - 1) {
fileDir.setParentDocName(split[i - 1]);
}
sets.add(fileDir);
}
}
}
}
}
if (CollUtil.isNotEmpty(sets)) {
//设置id
Map<String, Long> map = new HashMap<>();
Snowflake snowflake = IdUtil.getSnowflake();
for (FileDir fileDir : sets) {
long id = snowflake.nextId();
fileDir.setId(id);
map.put(fileDir.getLevel() + fileDir.getDocName(), id);
}
//设置父id
for (FileDir fileDir : sets) {
if (fileDir.getLevel() == 1) {
fileDir.setParentId(0L);
} else {
Long parentId = map.get((fileDir.getLevel() - 1) + fileDir.getParentDocName());
fileDir.setParentId(parentId);
}
}
}
return new ArrayList<>(sets);
}
}
FileDirTree
FileDirTree:在FileDirProcessor类的解析结果中定义了两个关键东西,当前文件或目录的唯一标识id和父id,FileDirTree的作用用在于把FileDirProcessor类的解析结果转换成一种树形结构,以便在页面上渲染展示;
public class FileDirTree {
public List<FileDir> nodeList;
public FileDirTree(List<FileDir> nodeList) {
this.nodeList = nodeList;
}
private List<FileDir> getRootNode() {
List<FileDir> rootNodeList = new ArrayList<>();
for (FileDir treeNode : nodeList) {
if (0 == treeNode.getParentId()) {
rootNodeList.add(treeNode);
}
}
return rootNodeList;
}
public List<FileDir> buildTree() {
List<FileDir> treeNodes = new ArrayList<FileDir>();
for (FileDir treeRootNode : getRootNode()) {
treeRootNode = buildChildTree(treeRootNode);
treeNodes.add(treeRootNode);
}
return treeNodes;
}
private FileDir buildChildTree(FileDir pNode) {
List<FileDir> childTree = new ArrayList<FileDir>();
for (FileDir treeNode : nodeList) {
if (treeNode.getParentId().equals(pNode.getId())) {
childTree.add(buildChildTree(treeNode));
}
}
pNode.setChildren(childTree);
return pNode;
}
}单元测试
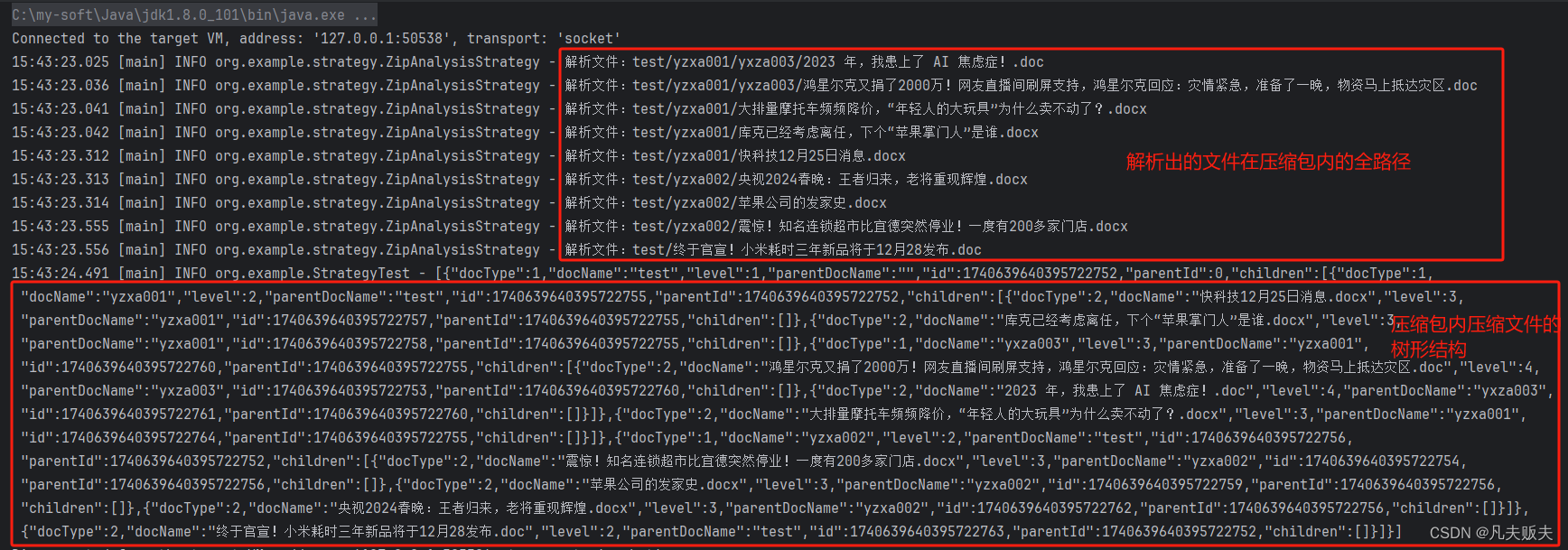
@Test
public void test4() throws IOException {
String fileName = "e:/zip/test.zip";
int index = fileName.lastIndexOf(".");
String suffix = fileName.substring(index + 1);
//构建解压策略
UnZipStrategy unZipStrategy = UnZipStrategyFactory.generate(suffix);
//开始解压
List<FileObj> analysis = unZipStrategy.analysis(Files.newInputStream(Paths.get(fileName)));
//从解压结果中获取解压文件的全路径
List<String> list = analysis.stream().map(FileObj::getFilePath).collect(Collectors.toList());
// log.info(JSONUtil.toJsonStr(list));
// this.saveFile(analysis, suffix);
//根据解压文件的全路径解析出压缩包内文件和目录的树形结构
List<FileDir> process = FileDirProcessor.process(list);
FileDirTree fileDirTree = new FileDirTree(process);
List<FileDir> tree = fileDirTree.buildTree();
log.info(JSONUtil.toJsonStr(tree));
}
源码下载
如果想获取完整的示例代码,可以从下面这个地址clone:
写在最后
感谢您阅读我的文章,如果您觉得我的内容对您有所启发或帮助,欢迎关注我并给我点赞。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!