数据库基础(实体,管理系统,日志,数据类型,键与约束)
基本概念

-
数据(Data): 数据是描述事物的信息,可以是数字、文字、图像、音频等形式。数据库中存储的就是这些数据,这些数据可以是具体的实体(如一个人的信息),也可以是抽象的概念(如订单、交易等)。
-
表(Table): 表是数据库中的一种结构化的数据组织方式,它是由行和列组成的二维表格。每一列代表一种属性,每一行代表一个记录。表是用来存储和组织数据的基本单元,可以通过表来表示和操作各种业务实体。
-
数据库(Database): 数据库是一个组织和存储数据的集合,它可以包含一个或多个表,以及定义表之间关系的元数据。数据库是一个独立的实体,可以用来存储和检索大量数据。数据库可以分为关系型数据库和非关系型数据库,前者采用表格的形式组织数据,而后者则使用其他方式(如文档、图形等)。
总体而言,数据是数据库中存储的信息,表是用于组织和表示数据的结构,而数据库是一个包含多个表的数据存储和管理系统。这三者一起构成了数据库系统的基本组成部分,用于有效地组织、存储和检索数据。
表
数据库中的表是一种结构化的数据对象,它是由行和列组成的二维数据结构,用于存储特定类型的数据。下面是关于数据库表的一些基本概念:
-
表(Table): 表是数据库中的基本组织单元,它由行和列组成。每个表都有一个唯一的名称,用于标识和引用该表。表以列的形式定义数据的结构,并以行的形式存储实际的数据记录。
-
列(Column): 表中的列代表数据的特定属性或字段。每一列都有一个名称和数据类型,用于定义该列可以存储的数据内容。例如,姓名、年龄、地址等都可以作为表中的列。
-
行(Row): 表中的行是由列的值组成的数据记录。每一行代表一个实体或记录,其中包含了各个列的具体数值或信息。
-
字段(Field): 字段是表中的列,是表结构的组成部分。它定义了每一列所包含的数据类型和属性。
-
主键(Primary Key): 主键是表中用于唯一标识每个记录的字段或列。主键的值在整个表中必须是唯一的,并且不允许为空。
-
外键(Foreign Key): 外键是表中的一列,它建立了与另一个表的关联。外键是另一个表中的主键,用于维护表与表之间的关联关系。
-
约束(Constraint): 约束是对表中数据的限制条件,用于确保数据的完整性和一致性。常见的约束包括主键约束、唯一约束、非空约束等。
表是数据库中存储数据的核心结构,它通过列和行的方式组织和存储数据,同时使用约束来确保数据的有效性和完整性。
数据库管理系统(DBMS)
数据库管理系统(DBMS)是一种软件,用于管理、存储和操纵数据库。它是一个支持用户对数据库进行访问、操作和管理的系统。DBMS允许用户通过特定的数据操作语言(如SQL)执行各种操作,包括增加、删除、更新和检索数据。
DBMS的主要功能和特点包括:
-
数据定义(Data Definition): DBMS提供数据定义语言(DDL),用于定义数据库中的数据结构,例如创建表、定义列、设置约束等。
-
数据操作(Data Manipulation): DBMS提供数据操作语言(DML),允许用户对数据库中的数据进行增加、删除、更新和查询等操作。
-
数据存储与管理(Data Storage and Management): DBMS负责有效地存储和管理数据,包括数据的物理存储方式、索引建立、数据缓存等。
-
数据维护(Data Maintenance): DBMS支持数据的备份、恢复、安全性控制以及数据的完整性维护,确保数据的一致性和可靠性。
-
数据控制与安全性(Data Control and Security): DBMS提供对数据库的访问控制和安全性管理,确保只有授权的用户可以访问数据,并且数据不会被未经授权的人员修改或删除。
-
并发控制(Concurrency Control): 当多个用户同时访问数据库时,DBMS负责管理并发访问,防止数据的丢失、错误修改或数据不一致。
-
备份与恢复(Backup and Recovery): DBMS提供备份和恢复功能,以防止数据丢失或意外损坏,并能够在需要时恢复到先前的状态。
数据库管理系统的设计和功能旨在提供有效的数据管理、安全性、可靠性和性能,使用户能够以简便的方式对大量数据进行处理和管理。
DBMS的工作模式如下:
1>接受应用程序的数据请求和处理请求
2>将用户的数据请求(高级指令)转换为复杂机器代码(底层指令)
3>实现对数据库的操作
4>从数据库的操作中接受查询结果
5>对查询结果进行处理(格式转换)
6>将处理结果返回给用户
数据库系统

数据库系统是由数据库及其管理软件组成的系统。它是一个用于收集、存储、管理和提供数据访问的系统,具有以下关键特征和组成部分:
-
数据库(Database): 数据库DB是一个有组织的数据集合,以某种特定的方式储存在计算机中。它可以包含一个或多个表,用于存储各种类型的数据。
-
数据库管理系统(DBMS): DBMS是一个软件,用于管理数据库。它允许用户创建、访问、更新和管理数据库中的数据。DBMS还负责处理数据的安全性、完整性和并发访问。
-
数据库应用(Database Application): 数据库系统可以支持各种应用程序,这些应用程序使用数据库中的数据来进行特定的任务。例如,企业资源规划(ERP)、在线交易处理(OLTP)、数据挖掘等都是基于数据库系统的应用。
-
数据库管理员(Database Administrator,DBA): DBA负责管理和维护数据库系统。他们负责数据库的设计、安全性、备份和恢复、性能优化以及监视数据库系统的运行。
-
用户和应用程序界面(User and Application Interface): 数据库系统提供了不同级别的用户接口,允许用户和应用程序通过查询语言(如SQL)或其他接口与数据库交互。
数据库系统的设计旨在提供一个结构化、可靠且高效的方式来存储和管理大量数据,并且能够满足各种不同应用场景下的需求。它是现代信息管理和数据处理的核心。
关系与非关系型数据库
关系型数据库(RDBMS)和非关系型数据库(NoSQL)是两种不同类型的数据库系统,它们在数据组织、存储和查询等方面有着明显的区别。以下是它们的一些主要特点和区别:
关系型数据库(RDBMS):
-
数据结构: 使用表格的结构,数据以行和列的形式组织,形成二维表格。
-
模式(Schema): 数据表具有预定义的结构,需要先定义表的模式,包括列名、数据类型和约束。
-
事务: 提供强大的事务支持,保证数据的原子性、一致性、隔离性和持久性(ACID属性)。
-
SQL语言: 查询和操作数据使用结构化查询语言(SQL),是一种强大而通用的标准查询语言。
-
适用场景: 适用于需要复杂事务处理和数据关联的场景,如企业级应用、金融系统等。
-
一致性: 严格的数据一致性,确保数据的完整性和准确性。
-
水平扩展(Scale-up): 水平扩展相对复杂,通常通过增加服务器性能(CPU、内存等)来提高性能。
非关系型数据库(NoSQL):
-
数据结构: 不使用固定的表格结构,可以使用文档、键值对、列族等不同的数据模型。
-
模式: 可以是无模式的,也就是说每个记录可以有不同的字段,灵活适应变化。
-
事务: 一些NoSQL数据库放宽了对事务的要求,强调分布式系统中的可用性和分区容错性(CAP定理)。
-
查询语言: 不一定使用SQL,一些数据库提供自己的查询语言,也有支持SQL的NoSQL数据库。
-
适用场景: 适用于需要高度可伸缩性和灵活性的场景,如大规模的分布式系统、实时分析等。
-
一致性: 可以是最终一致性,放宽了一致性的要求,允许在一段时间内数据不一致,但最终会达到一致状态。
-
水平扩展(Scale-out): 水平扩展相对容易,通过增加节点来提高性能,适用于大规模数据和用户的场景。
选择关系型数据库还是非关系型数据库取决于具体应用的需求。如果应用的数据结构相对稳定,需要复杂的事务支持,并且对数据一致性有较高要求,关系型数据库是一个合适的选择。而如果应用需要高度的可伸缩性、灵活性和处理大量的非结构化数据,非关系型数据库可能更为适用。
优缺点
关系型数据库:
-
优点: 数据一致性强、支持复杂查询和事务处理、成熟稳定。
-
缺点: 扩展性有限、需要严格的结构化数据模式、相对较高的成本。
非关系型数据库:
-
优点: 高扩展性、灵活的数据模型、适应大规模数据存储和高并发访问。
-
缺点: 牺牲一致性、不提供统一的查询语言、数据一致性难以保证。
选择数据库类型需要根据具体应用场景和需求来决定,有时也会使用混合方案以兼顾不同的优势
mysql日志
MySQL使用不同类型的日志来记录数据库的活动,其中包括三大主要日志:二进制日志(binlog)、重做日志(redo log)和撤销日志(undo log)。以下是它们的简要介绍:
- 二进制日志(Binary Log - binlog):
-
作用: 记录对数据库执行的写入性操作(不包括查询)。
-
形式: 以二进制的形式保存在磁盘中。
-
层次: binlog是MySQL的逻辑日志,由Server层进行记录。使用任何存储引擎的MySQL数据库都会记录binlog日志。
-
内容: 包括逻辑日志(记录的是SQL语句)。
- 重做日志(Redo Log):
-
作用: 用于保障事务的持久性,确保事务提交后对数据的修改是持久的。
-
形式: redo log包括两部分,一部分是在内存中的日志缓冲(redo log buffer),另一部分是落盘的重做日志文件。
-
层次: redo log是InnoDB存储引擎特有的日志。
- 撤销日志(Undo Log):
-
作用: 用于支持事务的回滚操作和多版本并发控制(MVCC)。
-
形式: 存储在undo tablespace中,也可以存在回滚段(rollback segment)中。
-
层次: undo log是InnoDB存储引擎特有的日志。
这些日志在数据库的正常运行中起到重要的作用,确保了数据的一致性、可靠性,以及事务的持久性。在数据库的恢复和备份过程中,这些日志也发挥了关键的作用。了解这些日志的工作原理和用途对于MySQL数据库的管理和优化是非常重要的。
基本数据类型
数据库中的数据类型
-
字符型:相当于Java中字符+字符串
-
varchar: 可变长字符串
name varchar(10),
定义一个名字是name的列,数据类型是varchar(10)10表示能接受的最大字节数,可以输入0~10个任意字节。var 存储空间是可变的,当你放入1个字节的数据的时候,实际占用的存储空间就是1字节,存储空间总是随着实际存储的数据量发生变化。
-
char: 定长字符串
name char(10),
定义一个名字是name的列,数据类型是char(10)
10表示能接受的最大字节数,可以输入0~10个任意字节
char的存储空间是不可变的,不管用户输入的多长的字符串,一定占有10字节的存储空间。实际存储空间不会随着用户输入的数据发生变化。
tips:char和varchar实际使用场景
由于varchar总是要按照传入的数据分配存储空间,它的空间分配是临时的,要按照数据临时分配存储位置,写入的效率较低,空间使用率较高
char总是占用恒定的存储空间,它的存储空间不需要临时分配,可以预设一些存储的位置,写入的效率较高,空间使用率较低。
当存储手机号、身份证、学号、订单号等固定长度的数据的时候,一般选择char
当存储用户名、密码、简介信息等长度可变的数据的时候,一般选择varchar
-
数字型:相当于Java中的整型+浮点型
int: 整型
float: 浮点型
它的使用和Java中基本一致
- 时间类型:Java中的时间类型Date存储一个时间点
在MySQL中,它分为年月日、年月日时分秒两种类型
date: 年月日,存储的精度到日期就结束了(在高版本中也可以存储时分秒了)
datetime: 年月日时分秒,存储精度到秒
timestamp: 时间戳,是一个随动的时间点
使用场景:
存储纪念日一般使用年月日
存储发生时间点一般使用年月日时分秒
-
其他类型:
boolean:布尔值,true、false
blob:二进制大数据,一般结合IO流,可以将一个文件以流的形式存储到数据库中存储,就要用blob作为流的存储数据类型
text:字符中的一种,长文本,varchar和char有存储的上限,做多是6w字左右,text专门用来存储长文本的,存储大小的上限2GB.
键与约束
primary key 这就是主键,键是一系列特殊的列。
对于表中的列数据的特殊要求就是约束。例如这里主键就带有主键约束,主键约束的要求是非空且唯一。
键
主键
在数据表中同时只能出现一个主键列,主键列通常和业务数据没有直接关系,只是在数据层面上表示一个唯一的标志。
在后续的代码应用中通常用主键值代指这一行的数据。
如何设置主键
第一种方式是在建表的时候同步设置主键
create table t_emp(
e_id int primary key,
在需要设为主键的列后面直接标注primary key。
第二种方式是在表已经建成的基础上后续添加主键的设置
先创建一张没有主键的表
create table t_test(
t_id int,
t_no varchar(10)
);
使用alter语句修改这张表指定一列是主键列
alter table ttest add primary key(tid);

tips:在id已经被设为主键的时候,请再尝试将no也设为主键

会报错,提示多个主键被定义(每张表只能有一列被设为主键列)
删除主键
alter table t_test drop primary key;
tips:通过主键移除后对于数据的限制的查看发现,主键和主键约束不是一个东西,他们也不都是同进同退的。例如移除主键之后,随主键约束带来的非空和默认值约束都没有被还原。
主键自增长
MySQL中支持对主键的值进行自增长,前提是数据类型是可以自增长的int类型
只能对主键列进行自增长,设置方式是在建表的时候对primary key添加
auto_increment自动增长
使用t_test表演示一下主键自增长
create table t_test(
t_id int primary key auto_increment,
t_no varchar(20)
);
insert into t_test values(1, ‘001’); 这是在为所有的列给出明确的值
当设置自增长之后主键值可以由MySQL自动生成,也就不需要手动输入了
insert into t_test values(null, ‘001’); 使用null表示这一列的值不再手动输入,由后台自动分配一个合适的值。

当然设置了自增长之后还是可以手动传值的,但是传的值如果不是连续的话,会影响id的自动生成的下一个值。
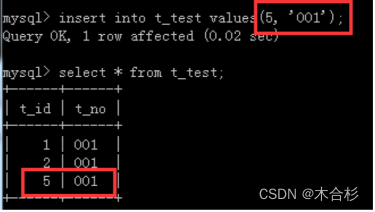
如图所示,如果手动设置的id已经不在原有的序列中了,那么下一位自动生成的id会按照用户输入的数字进行+1获取后续的值。

外键
以之前写过的两个练习为例,在tuser和tscore中都出现了uid这个字段,在tuser表中是用户的主键,唯一标识用户表中的一行数据,在tscore表中它表示的是这个成绩是哪个用户的,可以分析出成绩表中不能独立定义一个新的用户id,因为它在引用tuser中的主键表示数据之间的关联关系。
就可以把tscore表中的uid字段认为是一个外键,它的数据不能凭空自定义必须要引用另外一张表中对应列的数据。
tips:和主键不一样,主键是对一张单表的限制,根据上面的描述外键描述的是两张表之间列的关系。所以在定义的时候一定会涉及多张表。
如何设置外键
先创建主表(被引用的表)
t_class 班级表
create table t_class(
c_id int primary key,
c_name varchar(50)
);
insert into t_class values(1, '一班');
insert into t_class values(2, '二班');
再创建从表(需要引用别人的表)
t_stu学生表
create table t_stu(
s_id int primary key,
s_name varchar(50),
c_id int
);
insert into t_stu values(1, 'zhangsan', 1);
insert into t_stu values(2, 'lisi', 3);
这里的c_id就是要被设置外键的列,控制它的数据必须来源于t_class表
1、随从表的创建添加
create table t_stu(
s_id int primary key,
s_name varchar(50),
c_id int,
constraint fk_stu_cid foreign key(c_id) references t_class(c_id)
);
2、在从表建立后添加
alter table 从表 add constraint 约束名 foreign key(从表列) references 主表(主表列);
alter table t_stu add constraint fk_stu_cid foreign key(c_id) references t_class(c_id);

tips:当当前表格中数据不符合外键约束的时候,是不能添加外键的
当从表的外键列尝试插入主表中不存在的数据的时候,会显示外键约束失败并报错(插入也不能生效)。

移除外键
tips:在移除外键的时候一定要先知道设置外键的时候给外键约束起的名字
alter table 外键所在表 drop foreign key 外键约束名字;
alter table tstu drop foreign key fkstu_cid;
- 约束:主键约束,外键约束,非空约束,唯一约束,默认值约束
约束
主键约束 唯一+非空,伴随主键的添加而添加
外键约束 数据必须引用自主表(也可以是null),随外键的添加而添加
非空约束
create table t_test(
t_id int primary key,
t_no varchar(20) not null
);

主键约束和非空约束修饰的列都不能接受null值
如何对已经建立的表格中的列添加非空约束、如何移除非空约束
change(使用同名、同类型、不同约束的列进行替换)
alter table t_test change t_no t_no varchar(20) not null; 追加非空约束
alter table t_test change t_no t_no varchar(20); 移除非空约束
modify(使用modify修改列的类型和约束条件)
alter table t_test modify t_no varchar(20) not null; 追加非空约束
alter table t_test modify t_no varchar(20); 移除非空约束
唯一约束
unique
create table t_test(
t_id int primary key,
t_no varchar(20) unique
);
alter table t_test change t_no t_no varchar(20) unique;
alter table t_test change t_no t_no varchar(20)
唯一这个概念比较特殊,当一列设为唯一之后,所以新进入的数据都要和老数据进行匹配判断是否出现重复。这个时候当然不会是和select一样真的逐行进行判断,数据库会分配一个索引给所有的唯一列。
索引:提供快速查询的数据支持。索引这个结构是独立于列之外的,生成索引需要占用大量的cpu的资源,也要占用磁盘的存储空间(该列数据*2起步)。
根据这个特性,一般只会对不再需要大量修改的列添加索引,也只会在索引列中保存尽量小的数据。
当移除主键约束和唯一约束的时候,随之生成的索引是不会被删除的,所以要谨慎添加。
默认值约束
就是在desc中能够看到的default这一列

可以看到默认值都是null,也就是说当用户使用缺省插入的时候,如果没有给这一列赋值,会自动填充null进行占位。
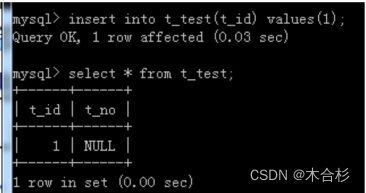
insert into ttest(tid) values(1);
此次只给id赋值,no不赋值,不赋值的列就会使用默认值进行填充。
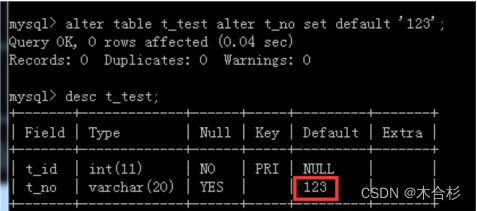
在已经建好的表上添加默认值
alter table 表名 alter 列名 set default 默认值;
alter table ttest alter tno set default '123';
在存在默认值的情况下再向表中缺省插入数据

当用户没有给存在默认值的列传值的时候,MySQL才会使用默认值填充
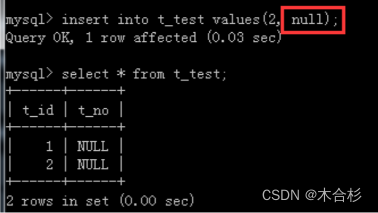
当用户指定要插入的数据(即使数据是null),MySQL就不会让默认值生效,用户输入什么就是什么
移除默认值
alter table 表名 alter 列名 drop default;
alter table ttest alter tno drop default;
补充函数
这里补充几个函数
1、关于数学函数
ceil 向上取整,不管小数位数值是多少,整数位 + 1舍弃掉所有的小数
ceil(12.1) == 13

floor 向下取整,不管小数位数值是多少,全部舍弃。
floor(12.1) == 12

round 四舍五入,按照四舍五入的规则保留整数位
round(12.1) == 12
round(12.9) ==13
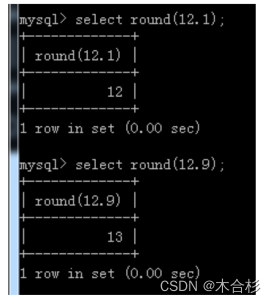
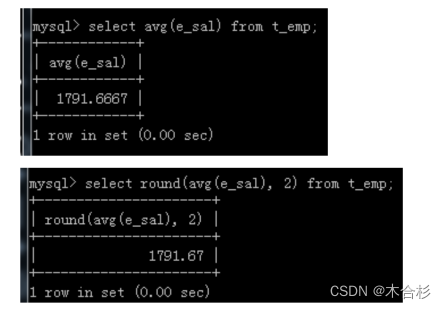
round(需要计算的数, 保留有效小数位数)
round(1.123, 2);保留两位小数 = 1.12

mod(a, b);
获取a/b得到的余数。称为取余
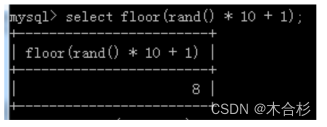
rand() 0-1之间的小数(小数位特别多) [0, 1)
rand(seed)可以定义生成策略(传入随机数生成的种子)
小练习:尝试用rand生成1-10之间的整数数字
2、时间函数
now(); 获取当前时间(这个是根据数据库所在的操作系统的系统时间返回的)
now = 年月日 + 时分秒
获取日期的方法 只需要年月日
curdate() 获取当前日期(不含时分秒)
获取时分秒
curtime() 获取当前时间
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 木鱼念经助手,支持多端,一年后能赚多少钱?
- 鸿蒙的基本入门理解
- 用笨办法-刻意练习来提高自己的编程能力
- SpringCloud:Ribbon
- 如何学习程序设计?
- 旧电脑追加内存条
- Multi-Task Learning based Video Anomaly Detection with Attention 论文阅读
- 【linux 多线程并发】多线程的控制,挂起线程暂停运行,直到唤醒线程,取消线程运行,可以设置合适的取消点属性避免不安全点被中止
- 【SpringBoot系列】AOP详解
- 利用提示工程,提升LLM将自然语言转化为SQL的准确性