NLP论文阅读记录 - ACL 2022 | 抽象文本摘要的拒绝学习
文章目录
前言

Learning with Rejection for Abstractive Text Summarization(2302)
0、论文摘要
最先进的抽象摘要系统经常会产生源文档不支持的内容,这主要是由于训练数据集中的噪声造成的。现有的方法选择完全从训练集中删除噪声样本或标记,从而减少有效训练集的大小并产生从源复制单词的人为倾向。
在这项工作中,我们提出了基于拒绝学习的抽象概括的训练目标,其中模型学习是否拒绝潜在的噪声标记。
我们进一步提出了一个正则化解码目标,通过使用训练期间学到的拒绝概率来惩罚推理期间的非事实候选摘要。
我们表明,与五个基线模型相比,我们的方法大大提高了自动评估和人工评估中生成的摘要的真实性,并且在增加生成摘要的抽象性的同时。 1
一、Introduction
1.1目标问题
近年来,抽象摘要取得了显着的进步,如 ROUGE 这样的自动评估分数就证明了这一点(Lin,2004)。然而,现有的抽象摘要系统很容易产生非事实摘要,其中包含来源不支持的信息(Kryscinski et al., 2019; Maynez et al., 2020; Durmus et al., 2020; Chao et al. .,2020;Kryscinski 等人,2020;Narayan 等人,2021)。根据最近的研究,造成这种现象的原因之一是训练集中的噪声,例如参考文献中不受支持的事实(Kang 和 Hashimoto,2020;Goyal 和 Durrett,2021;Raunak 等,2021)。具体来说,广泛使用的负对数似然目标旨在匹配基础数据分布。如果摘要模型在包含错误引用的噪声数据集 1https://github.com/mcao516/rej-summ 上进行训练,它们将倾向于模仿甚至放大不需要的生成(Kang 和 Hashimoto,2020)。
1.2相关的尝试
人们提出了不同的方法来减少非事实幻觉。法尔克等人。 (2019);赵等人。 (2020)采用基于重新排名的方法,根据开箱即用的事实一致性评估系统的事实性分数来对候选摘要进行排名。康和桥本(2020);戈亚尔和杜雷特(2021);戈亚尔等人。 (2022)使用基于损失截断的方法,在训练期间丢弃高损失句子/标记。曹等人。 (2022)提出了基于强化学习(RL)的方法,用负奖励来惩罚幻觉代币。

表 1 显示了包含不受支持信息的参考摘要的一个实例。我们可以看到,参考摘要包含有关政府资助的精确金额(1280 万英镑)的详细信息,但源文件中没有这一金额。参考摘要中的这种噪声具有很强的欺骗性,可能会导致摘要模型产生幻觉。此外,噪声可以“破坏”波束搜索过程,因为与噪声相关的短语(例如,已被授予[…])在推理过程中以高概率被解码。因此,我们认为摘要模型了解哪些信息是未知的并拒绝可能发生幻觉的上下文至关重要。
1.3本文贡献
在这项工作中,我们提出了一个训练目标,使摘要模型能够识别和拒绝不支持的目标文本范围。受到图像分类拒绝学习的启发(Grandvalet et al., 2008; Cortes et al., 2016; Thulasidasan et al., 2019),我们在训练时引入了一个新的拒绝类,为模型提供了拒绝令人困惑的标记的选项,而不是而不是为所有参考标记分配高概率。此外,我们的方法不需要标记或数据预处理。学习以训练为基础抽象摘要系统的动力学,其中干净的样本可以快速学习,而噪声样本的损失相对较高(Goyal 等人,2022;Kang 和 Hashimoto,2020)。我们证明拒绝学习目标允许摘要模型学习指示不受支持的信息的特征。如表 1 中的示例所示,使用拒绝目标训练的模型在短语“已被授予”之后正确拒绝,因为源中不存在此类信息。根据对人类注释的事实数据集的分析,我们的模型可以准确拒绝由最先进的抽象概括模型产生的 77.6% 的非事实幻觉。
此外,我们还为使用拒绝训练目标训练的摘要模型提供正则化解码目标。我们在原始解码目标中添加了一个正则化项,以使用训练期间学到的拒绝概率来惩罚候选者。我们证明,正则化解码目标与拒绝训练相结合,可以使用自动和人工评估极大地提高摘要模型的真实性。与 MLE 基线相比,我们的方法将句子真实率提高了 25.4%(34.6% → 43.4%,由 DAE 测量(Goyal 和 Durrett,2021))和 41.7%(22.8% → 32.3%,由 FACTCC 测量(Kryscinski 等人)等,2020))。最近的一项研究表明,先前方法带来的忠实度提高部分源于模型输出的提取性水平的提高(Ladhak 等人,2022)。我们证明我们的方法提高了模型的真实性,同时增加了生成的摘要的抽象性。
总之,我们的贡献如下:
(i)我们引入拒绝学习目标来训练抽象概括模型。我们演示了额外的训练目标如何使摘要模型能够在推理过程中精确拒绝幻觉标记(第 5.1 节)。
(ii)我们基于训练期间学到的拒绝概率提出了一种新颖的事实感知正则化解码目标。与五个基线模型相比,我们的方法显着提高了自动和人工评估中生成的摘要的真实性。
(iii) 我们证明,与基线相比,我们的方法生成的摘要也表现出更高水平的抽象性,具有更多新颖的 n 元语法和更少的复制。
二.相关工作
随着基于 Transformer 的摘要模型的出现(Lewis et al., 2020;Zhang et al., 2020;Qi et al., 2020;Liu and Liu, 2021;Liu et al., 2022),当前系统生成的摘要往往流畅且突出。然而,对这些系统输出的详细分析表明,这一代人中的大多数人都存在幻觉(Kryscinski 等人,2020 年;Pagnoni 等人,2021 年)。此外,Maynez 等人的注释。 (2020)表明这些幻觉大多数是外在的;也就是说,它们包含无法从源直接推断的信息。
许多先前的研究认为模型产生的外在幻觉是不受欢迎的,并提出了不同的方法来减少这些幻觉(Falke et al., 2019; Dong et al., 2020; Zhu et al., 2021; Cao et al., 2020; Pagnoni等人,2021 年;Nan 等人,2021 年)。另一方面,一些先前的工作(Maynez 等人,2020;Cao 等人,2022;Dong 等人,2022)表明,其中许多幻觉实际上是事实,并且可用于提供额外的背景信息。
与我们最相似的工作是在训练阶段使用损失截断来减少噪声的方法。 Kang 和 Hashimoto (2020) 以及 Goyal 等人。 (2022)提出句子和令牌级损失截断以减少幻觉。这些策略基于这样的假设:噪声样本难以学习,从而导致较高的训练损失。简单地删除这些难以学习的高对数损失样本可能会减少模型幻觉。然而,丢弃太多样本可能会使训练过程效率低下。它还使摘要模型更具提取性。丢弃高损失令牌可能也无效,因为模型无法学习在解码过程中生成的正确令牌。
相反,我们在训练中使用所谓的拒绝(或弃权)方法来对抗噪音。 Thulasidasan 等人提出了损失弃权方法。 (2019)用于分类任务,训练分类器在训练期间避免错误标记的图像。受这个想法的启发,我们引入了生成任务的拒绝损失(第 3.1 节)。与损失截断相比,损失弃权的优点是它能够学习可能??导致幻觉的文本特征,而不是简单地忽略它们。这些特征可以在推理过程中使用,以避免产生幻觉。
三.本文方法
3.1拒绝中学习
3.1.1 问题表述
我们将抽象摘要视为条件语言生成任务。给定带有 L 个标记的源文档 x = (x1, …, xL),任务是学习生成摘要 y = (y1, …, y|y) 的概率模型 ? pθ(y|x) |),其中 yi 来自预定义词汇 V。θ 表示模型的参数。 ? pθ 通过将序列的概率分解为给定先前上下文的每个标记的条件概率来建模: ? pθ(y) = ∏|y| t=1 ? pθ(yt | y<t, x)。通常,^ pθ 使用最大似然估计(MLE)目标进行训练,其目的是最大化人类编写的参考摘要的可能性:
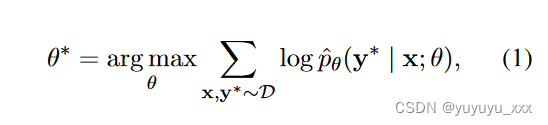
其中 D 表示训练集,y* 是参考摘要。对于给定的文档 x 和参考摘要 y*,MLE 目标相当于最小化真实标记的负对数似然之和:
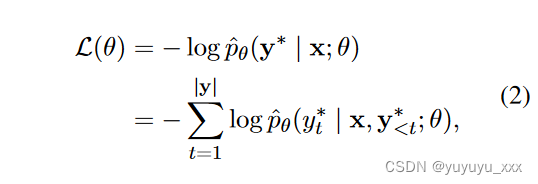
其中 y* i ∈ V 是参考摘要中的真实标记。方程 2 也相当于交叉熵损失目标,其中真实分布是单热分布。
为了符号简洁,我们定义pit = ? pθ (y i t | y* < t, x), (0 ≤ i ≤ |V| ? 1) 作为第 i 个词汇标记在 t- 的条件概率。给定真实前缀的第时间步。
3.1.2 拒绝损失
MLE 目标寻求最大化所有训练样本的可能性。知道底层训练数据充满噪音,我们希望模型能够自动识别参考文献中不支持的文本范围,并在训练期间拒绝它们(Thulasidasan 等人,2019)。为此,我们可以在原始 |V| 中添加一个额外的拒绝类别 r类(即标记)。设 ptr = ? pθ(r | x, y* <t) 表示第 t 步拒绝的概率,修改后的损失函数为
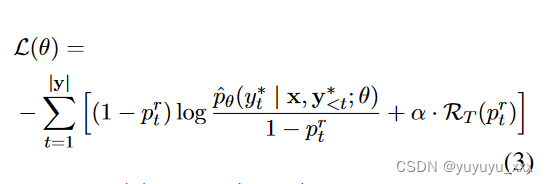
其中 RT § = log (1 ? p) 是拒绝的正则化函数。在第一项中,增加 ^ pθ(y* | x, y* <t; θ) 或 ptr 将使损失函数最小化。在训练过程中,当真实标记包含错误注释或不受支持的信息时,术语 log ? pθ (y ? t | x, y? <t; θ) 将异常高(Kang 和 Hashimoto,2020)。在这种情况下,最小化对数损失会导致产生幻觉的次优模型。通过引入拒绝类别,模型可以选择增加拒绝概率,以最小化总损失。在 ptr = 1 的极端情况下,第一个损失项将为零。为了防止模型恶化到极端情况,我们添加了第二个正则化项来惩罚大的拒绝概率。在训练过程中,我们设置 ptr = 0 以完全恢复前 m 个步骤的原始交叉熵损失(方程 2)。这使得模型能够快速吸收简单的模式。在我们的实验中,我们仅将拒绝损失应用于实体令牌。
3.2拒绝解码
让我们考虑如何对使用上述拒绝损失目标训练的模型进行解码。在推理时,拒绝概率反映了模型对其预测的不确定性程度。当拒绝类别在时间步骤 t 被分配高概率时,生成的内容在该步骤很可能是幻觉和非事实的(参见第 5.1 节)。因此,我们可以利用拒绝概率来惩罚非事实的候选摘要。我们考虑以下正则化解码目标:
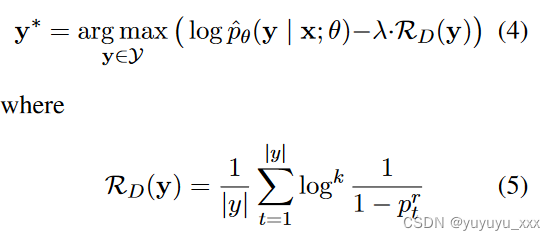
Y 是假设空间。 k是对数的指数,当ptr很大时可以放大正则化项的效果。在接下来的实验中我们设置k=1。我们还考虑一个最大正则化器,它可以在生成的摘要中找到具有最高拒绝概率的标记:
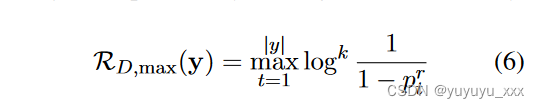
在推理过程中,拒绝标记仅用于正则化,不会生成。在每个解码步骤 t 中,我们仅从原始词汇 V 中选择标记。每个标记坑的概率除以 1 ? ptr 以确保模型输出词汇表单词的正确概率分布。
四 实验效果
4.1数据集
我们在 XSUM(Narayan 等人,2018)数据集上评估了我们的方法。 XSUM 包含 226,711 篇英国广播公司 (BBC) 在线文章,涵盖新闻、政治、体育、商业等领域。每篇文章都配有 BBC 记者撰写的一句话摘要。数据集分为三个子集:训练集(204,045,90%)、验证集(11,332,5%)和测试集(11,334,5%)。我们选择 XSUM 是因为它比其他汇总数据集更抽象。由于其创建方式,它也相对嘈杂(Maynez et al., 2020)。
对于细粒度实体级事实性分析(参见第 5.1 节),我们使用由 Cao 等人创建的 XENT 数据集。 (2022)。 XENT 包含 800 个文章和摘要对,其中文章是从 XSUM 测试集采样的,摘要是使用微调的 BART 模型生成的(Lewis 等人,2020)。在XENT中,摘要中的每个实体都注释有三个标签:非幻觉、事实幻觉和非事实幻觉。事实幻觉是指可以通过世界知识验证但不能直接从源文本推断出的实体。我们在 XENT 测试集上评估我们的模型,其中包含 240 个摘要和 835 个实体。
4.2 对比模型
我们将我们的方法与五个基线进行比较:(1)最先进的抽象概括模型 BART(Lewis 等人,2020)。 (2)Kang和Hashimoto(2020)提出的损失截断方法。 (3)Goyal等人提出的代币级损失截断方法。 (2022)。 (4)GOLD(通过离策略学习演示生成),Pang 和 He(2021)提出的离策略强化学习算法。 (5) (Cao et al., 2022) 提出的一种用于文本摘要的事实感知离策略强化学习算法。 BART 是一种常用的基于变压器的总结模型。它采用编码器解码器架构,本质上是一个去噪自动编码器,通过注入噪声来重建原始文本,例如标记删除、替换、屏蔽和句子排列。 Kang 和 Hashimoto (2020) 提出的损失截断方法自适应地丢弃高对数损失示例,作为减少生成中幻觉的一种方法。类似地,Goyal 等人中的代币级损失截断。 (2022) 删除了具有挑战性或太容易学习的高损失和低损失令牌。 GOLD(Pang and He,2021)的提出是为了缓解 MLE 中训练和评估目标之间的差异(例如过度概括、暴露偏差)。 Pang 和 He(2021)表明,在文本摘要方面,GOLD 在 ROUGE 分数和人类评估方面优于 BART。曹等人。 (2022) 使用实体级事实分类器生成的事实奖励增强了 GOLD。
4.3实施细节
在以下实验中,我们使用预训练的 BART-LARGE 作为模型的骨干。编码器和解码器模块的隐藏层大小设置为 1024,最大序列长度设置为 1024。我们在 XSUM 训练集上对模型进行了 20,000 步的微调,其中预热期为 500 步。我们使用 Adam 优化器(Kingma 和 Ba,2014),其值为 1e-8,初始学习率为 3e-5。每层都应用 dropout 和attention dropout,dropout 率设置为 0.1。除非另有说明,等式 3 中的 α 设置为 1.0。我们使用公式 5 中定义的总和正则化器来获得主要结果。所有实验均在 4 个具有 32GB 内存的 Tesla V100 GPU 上进行。
4.4评估指标
对于句子级别的可信度评估,我们使用 FACTCC (Kryscinski et al., 2020) 和 DAE (Goyal and Durrett, 2021)。 FACTCC 是一个在综合数据集上训练的句子级忠实度分类器,该数据集是基于对最先进的摘要模型所产生的错误的分析而创建的。 DAE 经过抽象概括模型对事实错误进行细粒度的人工注释的训练。给定文档和摘要对 (x, y),两种方法都预测标签 y ∈ {0, 1},其中 0 表示摘要不忠实,1 表示摘要忠实。被分类器预测为忠实的句子的百分比用作句子真实率。
对于实体级事实性评估,我们使用Cao等人提出的ENTFA。 (2022)。 ENTFA 是一种 k-NN 模型,它使用先验概率和后验概率作为特征来预测给定摘要中实体的事实性和幻觉状态。我们使用输出摘要中被预测为非事实幻觉的实体百分比作为表 2 中的实体幻觉率。对于所有三种评估方法,我们使用论文中提供的评估脚本和参数。为了衡量每种方法对摘要抽象性的影响,我们计算了新颖的 n 元语法和覆盖率的百分比、摘要中作为源文档提取片段一部分的单词的百分比(Grusky 等人,2018)
4.5 实验结果
4.5.1真实性评估
自动评估结果
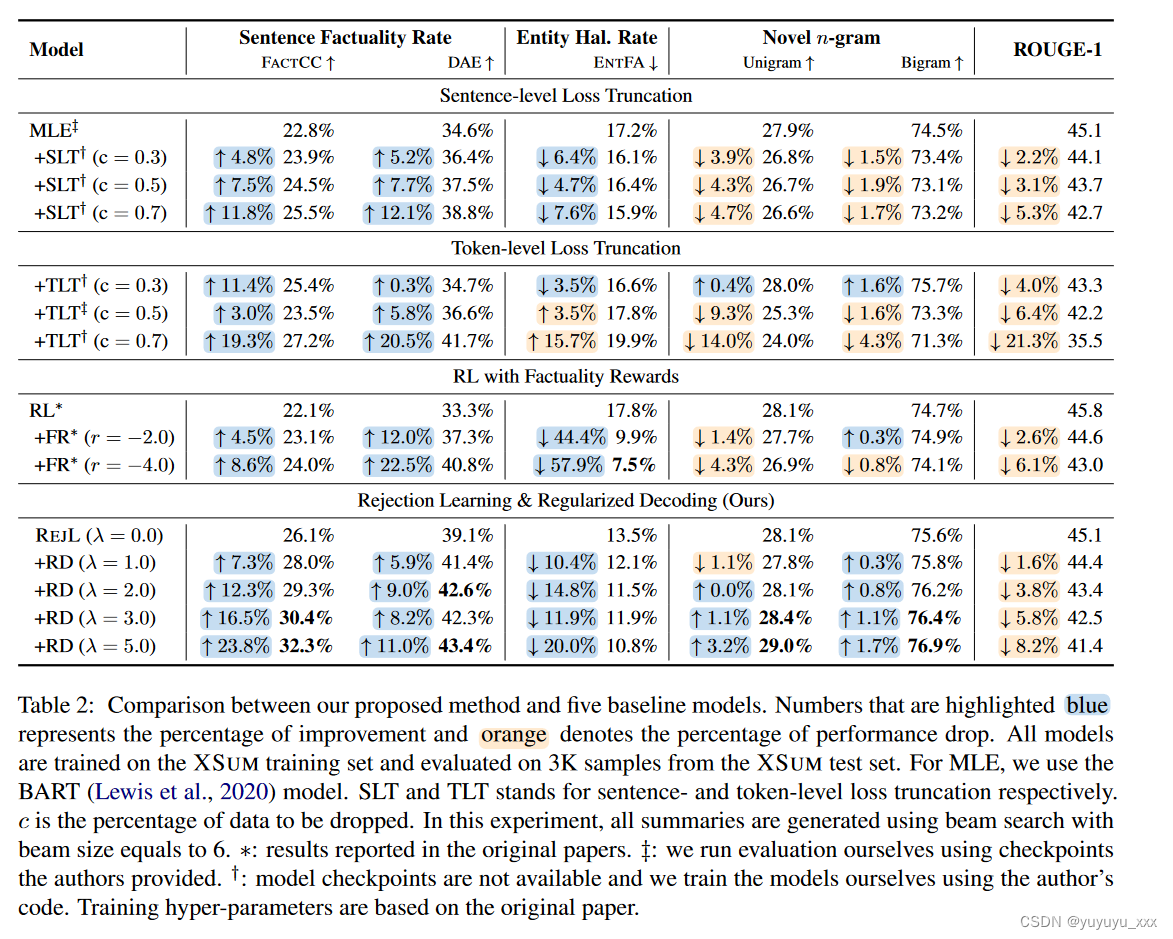
XSUM 测试集的事实性评估结果如表 2 所示。我们通过设置 λ = 0 来评估没有正则化解码的拒绝损失的影响。我们做出以下观察:(1)在句子级摘要的评估中事实上,我们提出的方法——拒绝损失目标与正则化解码相结合——优于所有基线方法。与 MLE 训练相比,我们观察到 FACTCC 评分提高了 41.7% (22.8% → 32.3%),DAE 评分提高了 25.4% (34.6% → 43.4%)(当 λ = 5.0 时)。我们的方法在实体级事实性评估方面也优于 MLE 和损失截断基线,但它低于 RL+FR 基线。我们推测这是因为 RL 方法专门针对使用 ENTFA 生成的实体级事实性奖励进行了优化。
(2) 当我们增加 λ 值时,我们观察到事实性得分(几乎)持续提高。这符合我们的预期,因为具有不确定性的候选摘要将受到更大的 λ 的更严重的惩罚。一个有趣的发现是,当拒绝损失对象时,摘要的真实性大大增加tive 单独使用,无需正则化解码。与 MLE 基线相比,使用拒绝损失目标(无正则化解码)训练的摘要模型达到了相同的 ROUGE-1 分数 45.1,但事实性分数显着更高(FACTCC:22.8% → 26.1%;DAE:34.6% → 39.1%; ENTFA:15.5%→13.5%)并且有更多新颖的n-gram。这些发现意味着,当底层数据集有噪声时,拒绝损失目标通常比文本摘要的本机交叉熵目标表现更好。目前尚不清楚这是否可以推广到其他文本生成任务,例如基于知识的对话生成,其中训练数据集经常包含噪声(Dziri 等人,2022)。这将留给以后的工作。
(3) 当 λ 增加时,所得的摘要变得更加抽象。表 2 中的观察结果支持了这一点,其中随着 λ 的增加,生成的摘要包含更多新颖的 n 元语法。因此,我们的方法可以同时增加生成的摘要的抽象性和真实性。相反,如果我们尝试在损失截断和强化学习方法中使生成的摘要更加真实,新颖的 n 元语法的比例就会下降。新颖的 n 元语法的下降表明,基线带来的事实性改善可能来自于提取性水平的提高。这与 Ladhak 等人的研究结果一致。 (2022)。我们还根据 Ladhak 等人最近的工作绘制了忠实性-抽象性权衡曲线。 (2022),如图 1 所示。我们采用 Grusky 等人 (2022) 中定义的覆盖范围。 (2018)衡量提取性水平:覆盖率越高的摘要被认为更具提取性。忠诚度是使用 DAE 分数来衡量的。在图 1 中,我们模型的抽象性和真实性呈正相关。相反,损失截断方法表现出负相关性。这个结果进一步证实了我们的观点。
(4) 我们观察到随着摘要真实性的增加,ROUGE 分数下降。根据我们的计算,生成的平均长度
不同 λ 的摘要保持不变(大约 18 个单词)。因此,摘要长度不太可能在 ROUGE 分数下降中发挥作用。相反,我们推测 ROUGE 分数的下降是由于抽象性的增加造成的。例如,表 1 中的正则化解码摘要是高度抽象的。它没有提及资金,因为来源中没有具体说明资金的价值。相比之下,BART 生成的摘要在 n 元语法重叠方面与参考更接近,即使它包含非事实幻觉。根据这个例子,MLE 目标似乎可能会鼓励摘要模型产生幻觉,以提高 ROUGE 分数。曼彻斯特大学已获得 ___ MLE:350 万英镑,用于资助一个新的研究中心。我们的:350 万英镑 (…)% 相同。 150 万英镑 (…) % 不同。 1280 万英镑 (…) % 事实上是一大笔钱 (…) % 删除实体。 % 拒绝令牌 表 4:我们如何在 XENT 上评估拒绝模型的示例(Cao 等人,2022)。在此示例中,BART 生成了 350 万英镑,并由人类注释者标记为非事实幻觉。我们为我们的模型提供相同的上下文,并分析模型中五种不同类型输出的分布。我们对 XENT 中的事实和非事实实体进行了分析。
人工评价
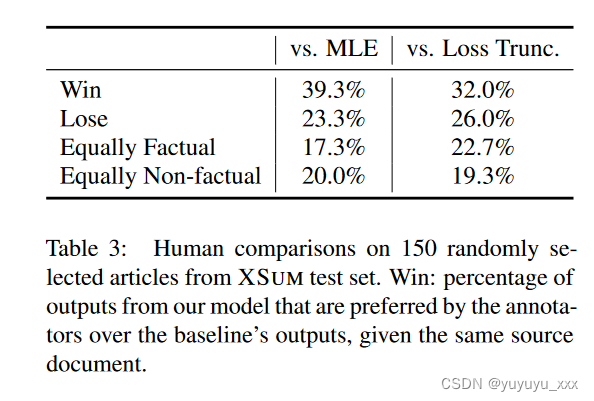
除了自动评估之外,我们还进行了人工评估,将我们的模型(λ=2.0)与 MLE 和代币级损失截断 c = 0.5 基线进行比较。我们向参与者展示了我们的模型和比较模型的输出,并要求他们根据自己的忠实度在两个摘要之间做出成对的偏好判断。具体来说,我们从 XSUM 测试集中随机抽取了 150 篇文章进行总结。为了使评估过程更加有效,我们过滤掉了生成的摘要对具有超过 70% 一元重叠的样本。我们以随机顺序呈现了两个摘要,并要求参与者仔细考虑每个摘要的真实性。然后我们要求他们选择他们喜欢的摘要,或者说它们同样是事实/非事实。更详细的注释指南可以在附录A中找到。表3显示了人类评估结果。从表中我们可以发现,与两个基线相比,人类注释者更喜欢由我们的模型生成的摘要。2
五 总结
在这项工作中,我们提出了一种基于拒绝学习的抽象概括模型训练目标,该模型对于数据集中存在的噪声具有鲁棒性。所提出的训练目标允许模型学习与噪声相关的特征并在训练期间拒绝它们。我们还提出了一种新颖的正则化解码目标,可以在推理过程中有效地惩罚非事实候选摘要。我们表明,与使用自动和人工评估的五个基线模型相比,我们的方法极大地提高了生成摘要的真实性。进一步的分析表明,我们的模型增强了摘要的真实性,同时增加了生成摘要的抽象性。
局限
我们在这项工作中的假设是,噪声引用包含源中不存在的信息,这为摘要模型创建了不可能的学习任务。因此,噪声样本在训练过程中损失较高,这使得拒绝学习能够识别并拒绝它们。然而,尚不清楚是否还存在“困难”但干净的样本,它们也具有高损失,因为它们对于模型来说很难学习。例如,训练集中的一些文章包含数值数据,可能需要算术推理才能生成良好的摘要。如果存在这样的样本,我们的方法可能会拒绝它们而不是学习。这种情况是否会发生还有待评估。此外,所提出的方法仅在摘要任务上进行了测试。尽管我们的方法可以应用于其他 NLG 任务,例如机器翻译和基于知识的对话生成,但在事实性方面是否能获得类似的优势还有待观察。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一个寒假能不能学好黑客?自学黑客到底难不难
- 手把手入门MO | 如何使用 DolphinScheduler 连接 MatrixOne
- 【AI】国内好用的AI工具推荐
- nodejs+vue+ElementUi音乐分享社交网站77l8j
- 使用opencv的Canny算子实现图像边缘检测
- 中小企业实施了MES系统后,同样具备大企业的生产能力
- 每日一道算法题 11(2023-12-19)
- nvidia-smi GPU卡信息获取
- MySQL从0到1全教程【1】MySQL数据库的基本概念以及MySQL8.0版本的部署
- 自动计算薪资-全优学堂