Shell脚本
目录
引导
我们所输入的命令,计算机是不会识别的,这时就需要一种程序来帮助我们进行翻译,变成计算机能识别的二进制程序,同时又把计算机生成的结果返回给我们
编程语言的分类
编程语言主要用:低级语言和高级语言
1.低级语言:
机器语言:二进制语言,早期计算机就通过穿孔纸去跑一个程序,有空代表1,无孔代表0

汇编语言:符号语言,使用助记符号来代替操作码,也就是用符号代替机器语言的二进制码,它们都是面向机器的语言
2.高级语言
它是比较接近自然语言,或者说与人类语言的一种编程,用人们能够容易理解的方式进行编写程序
静态语言:编译型语言 如:C、C++、Java,
动态语言:解释型语言 如:php、shell、python、perl
gcc编译器:(解释器) 将人类理解的语言翻译成机器理解的语言
一、Shell基础知识
(一)什么是shell
Shell是一个命令的解释器,它在操作系统的最外层,负责直接将与用户进行对话,把用户输入的命令给操作系统,并处理各种各样的操作系统的输出结果,输出到屏幕反馈给用户。这种对话方式可以是交互的,也可以是非交互式的。
交互式(Interactive):用户输入一条命令,Shell 解释并执行一条。
非交互式,又叫批处理(Batch):用户事先编写一个 Shell 脚本(Script),其中包含诸多命令,Shel1 会一次执行完所有命令。
不同的Unix和类Unix系统可能使用不同的Shell,常见的有:Bash(Bourne Again Shell)、sh(Bourne Shell)、csh(C Shell)、tcsh(增强型C Shell)等。
我们可以使用命令查看当前系统支持哪些类型的shell

(二)什么是shell脚本
shell脚本:就是把原来的Linux语句或命令放在一个文件中,然后通过这个程序文件去执行时,我们就说这个程序为shell脚本或shell程序,我们可以在脚本中输入一系统命令以及相关语法语句组合。Shell 脚本需要用到很多的 Linux 命令以及结合之前学习过的正则表达法、管道符,重定向等语法规则来完成指定任务。把它们有机结合起来形成了一个功能强大的shell脚本。
1.shell脚本的基本格式
首先来创建一个基础的脚本

1.#!/bin/bash
#第一行开头“#!/bin/bash”,表示此行以下的代码语句是通过/bin/bash程序来解释执行。
#!/bin/bash为默认的解释器还有其他类型的解释器,#!/bin/python #!/bin/expect
2.#this is shell
#第二行为注释内容,以#开头为注释信息,执行时被忽略。可以写一些shell脚本的介绍
3.echo ?"hello ?world"
4.mkdir ?/opt/test
5.touch ?/opt/test/a.txt
#第3+行为执行语句或命令shell脚本文件一般以.sh结尾
那么如何去执行呢?需要加一个执行权限,使用bash去执行它

可以看到,脚本文件中的信息,都会按顺序一一执行。
2.shell脚本执行逻辑
那么可能会有人问,如果顺序错误或这命令错误会有什么后果?
如果顺序错误者命令错误,它会显示该命令的报错信息,并继续执行下面的命令

脚本的执行是有逻辑的
1|顺序执行:程序按从上到下顺序执行
2|选择执行:程序执行过程中,根据条件的不同,进行选择不同分支继续执行
3|循环执行:程序执行过程中需要重复执行多次某段语句3.shell脚本执行的方式
执行脚本的方式有三种
脚本路径执行:可以是绝对路径,也可以是相对路径。

shell解释器执行:指定使用bash去执行,不需要权限

source或.:也可以直接执行,不需要权限,但是会影响当前环境

这是因为使用bash 执行脚本,会开启一个新的bash环境去执行,脚本执行完毕后会自动关闭,不会对当前操作有任何影响
脚本路径执行默认的是当前shell环境,就是/bin/bash
而source是在当前终端的shell环境直接执行
(三)脚本错误调试
脚本中常见的错误有以下三种
1.命令错误
默认后续的命令还会继续执行,用bash -n 无法检查出来 ,可以使用 bash -x 进行观察

2.语法错误
会导致后续的命令不继续执行,可以用bash -n 检查错误,但是提示的出错行数可能会因为嵌套结构而显得不准确

注释:if是shell脚本中的一种语法,有固定的格式,如if-then-fi 结构 、if-elif-else-fi 结构。意思就是开头如果写if,那么中间就要写then,结尾就要写fi。还有一些其它的语法,后期会慢慢讲到。
3.逻辑错误
逻辑错误是指程序执行了预期之外的操作,可能是条件判断错误、循环逻辑混乱、变量引用不当等。这类问题仅通过语法检查和命令输出观察很难发现,确实需要通过bash -x或其他调试手段逐步跟踪脚本的执行流程,以定位到具体的问题点。此外,良好的代码结构、注释以及单元测试也是避免和发现逻辑错误的有效方法。
4.调试
在执行脚本时,如果不小心将命令输错,可能导致后续命令出现更加严重的错误
例如,所在当前目录是根目录,在脚本中写到:
cd? /opy
?rm? -rf? ./*
本来是想要切换到/opt目录,并删除该目录下的所有内容,结果目录不存在,但第二条命令还会继续执行,此时就会删除/目录,这是十分危险的操作。
在脚本前面加上set? -e,表示脚本中如果出现错误,立即停止
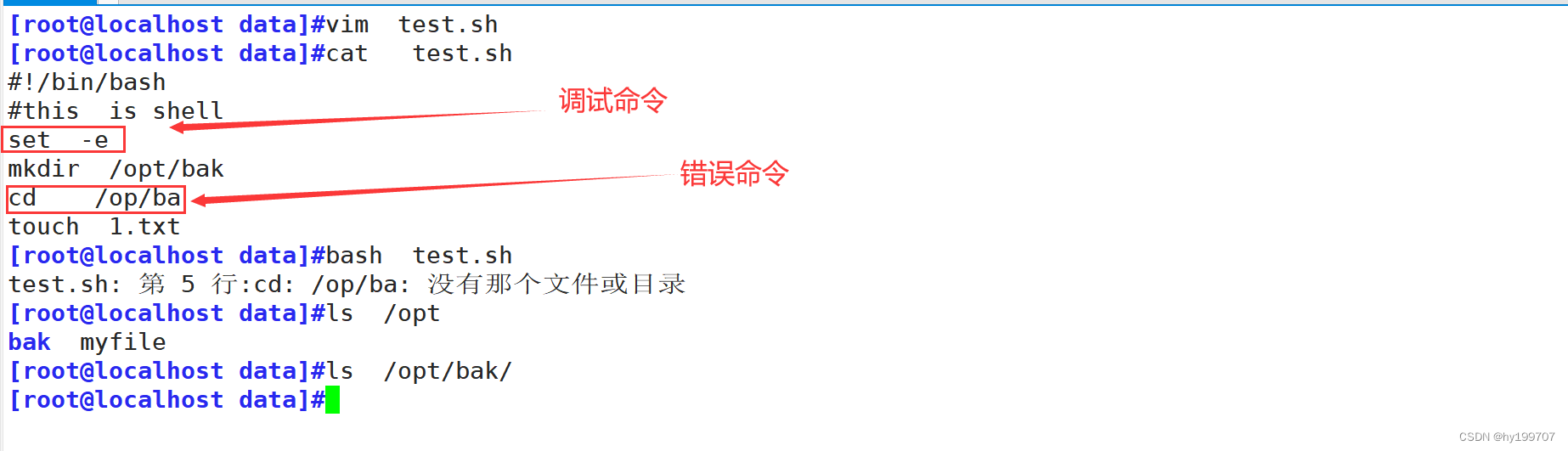
但是,此调试可能会影响一些脚本进度,选择性使用
二、输入输出重定向与管道符
(一)输入输出重定向
在学习标准输入输出重定向前,我们先看一个简单的演示吧:查看/data目录的信息
刚刚先查看了一个名为/data目录内的文件,后又尝试查看名为”xxx”目录内的文件,显示该目录并不存在。
虽然好像命令都执行成功了,但其实有所差异,我们自己输入的内容就属于标准输入,前者执行后返回的是标准输出,而后者执行失败返回的是错误输出。
1.交互式硬件设备
这些设备在/dev/目录下

| 标准输入(stdin,文件描述符为 0) | 默认从键盘输入,为0时表示是从其他文件或命令的输出。 |
| 标准输出(stdout,文件描述符为 1) | 默认输出到屏幕,为1时表示是文件。 |
| 错误输出(stderr,文件描述符为 2) | 默认输出到屏幕,为2时表示是文件。 |
/dev/stdin:通常关联到进程的标准输入,例如从键盘读取输入或者重定向一个文件到命令的标准输入。
/dev/stdout:指向进程的标准输出,正常情况下程序执行的输出结果会显示到终端或被重定向到其他文件或设备。
/dev/stderr:用于标准错误输出,通常用于输出错误信息,与stdout不同,它允许将错误消息和正常程序输出分离处理。
它们都是由root用户创建,并且对所有用户具有读写执行权限。链接的目标分别是/proc/self/fd/0、/proc/self/fd/1和/proc/self/fd/2。在/proc/self/fd/目录下存放的是当前进程打开的文件描述符列表,这里的0、1、2分别对应于标准输入、标准输出和标准错误输出的文件描述符。通过这种方式,操作系统能够以统一的方式访问和管理进程的输入输出流。
2.标准输出
在重定向中>表示覆盖原数据,>>表示追加到文件末尾
| 符号 | 作用 |
| 命令 > 文件 | 将标准输出重定向到一个文件中 (清空原有文件的数据) |
| 命令 2>文件 | 将错误输出重定向到一个文件中 (清空原有文件的数据) |
| 命令 >> 文件 | 将标准输出重定向到一个文件中 (追加到原有内容的后面) |
| 命令 2>>文件 | 将错误准输出重定向到一个文件中 (追加到原有内容的后面) |
| 命令 >> 文件 2>&1 | 将标准输出与错误输出共同写入到文件中 (追加到原有内容的后面) |
将查看a.txt文件的结果(标准输出),重定向到b.txt文件,会将a.txt文件的内容添加到b,txt文件,且清空b.txt文件的内容

将错误输出重定向到b.txt文件,直接使用重定向符号无法将错误输出重定向的,需要在后面加上2

将标准输出的结果重定向到其他文件,只追加,不覆盖

将标准输出与错误输出共同写入到文件中 (追加到原有内容的后面)

3.标准输入
| 符号 | 作用 |
| 命令 < 文件 | 将文件作为命令的标准输入 |
| 命令 << 分界符 | 从标准输入中读入,直到遇见“分界符”才停止 |
| < 文件1> 文件2命令 | 将文件 1 作为命令的标准输入并将标准输出到文件 2 |
将passwd.txt文件内容输入到更改密码的免交互界面

4.多行重定向
多行重定向通常用于将多行文本内容写入文件或从文件读取
语法:命令 > 文件名 <<自定义标记符 或 : 命令? <<自定义标记符 > 文件名

(二)管道符的作用
?
管道符(Pipeline)在 Linux 系统中是一个非常重要的概念,它允许将一个命令的输出作为另一个命令的输入。管道符用 "|" 表示。
管道符:将前面的命令结果当作后面命令的参数执行
管道符左边的命令一定要有标准输出
管道符右边的命令一定要有接收标准输入
举一个简单的例子:

在这个命令中,cat? ?/etc/passwd 列出文件内容,然后通过管道符将输出传递给 grep root。grep 命令会过滤出包含root字符串的行。
管道符的强大之处在于它可以将小型、单一功能的命令组合起来,以执行复杂的操作。通过管道符,用户可以灵活地构建自定义的数据处理流程,而无需编写复杂的脚本或程序。
三、变量
(一)变量基础
在Shell编程中,变量是用来存储数据的命名空间
变量是shell 传递数据的一种方法。变量是用来代表每个值的符号名。我们可以把变量当成一个容器,通过变量,可以在内存中存储数据。也可以在脚本执行中进行修改和访问存储的数据
变量的设置规则:
1.变量名称通常是大写字母,它可以由数字、字母(大小写)和下划线 组成。变量名区分大小写,但是大家要注意变量名称不能以数字开头
2.等号=用于为变量分配值,在使用过程中等号两边不能有空格
3.变量存储的数据类型是整数值和字符串值
4.在对变量赋于字符串值时,建议大家用引号将其括起来。因为如果字符串中存在空格隔符号。需要使用单引号或双引号
5.要对变量进行调用,可以在变量名称前加符号$
6.如果需要增加变量的值,那么可以进行变量值的叠加。不过变量需要用双引号包含“$变量名”或用${变量名)包含
(二)变量类型
常见的变量类型有
1.自定义变量
变量名命名规则:由字母或下划线打头,不允许数字开头,后面由字母、数字或下划线组成,并且大小写字母意义不同。在使用变量时,在变量名前加$
命名格式为:变量名=变量值

echo? $变量名:是将变量值打印在屏幕上
变量可以使用命令进行追加:变量名+=需要追加的变量值

可以使用unset命令删除变量 :unset 变量名

也可以通过修改配置文件 /etc/profile 去自定义变量
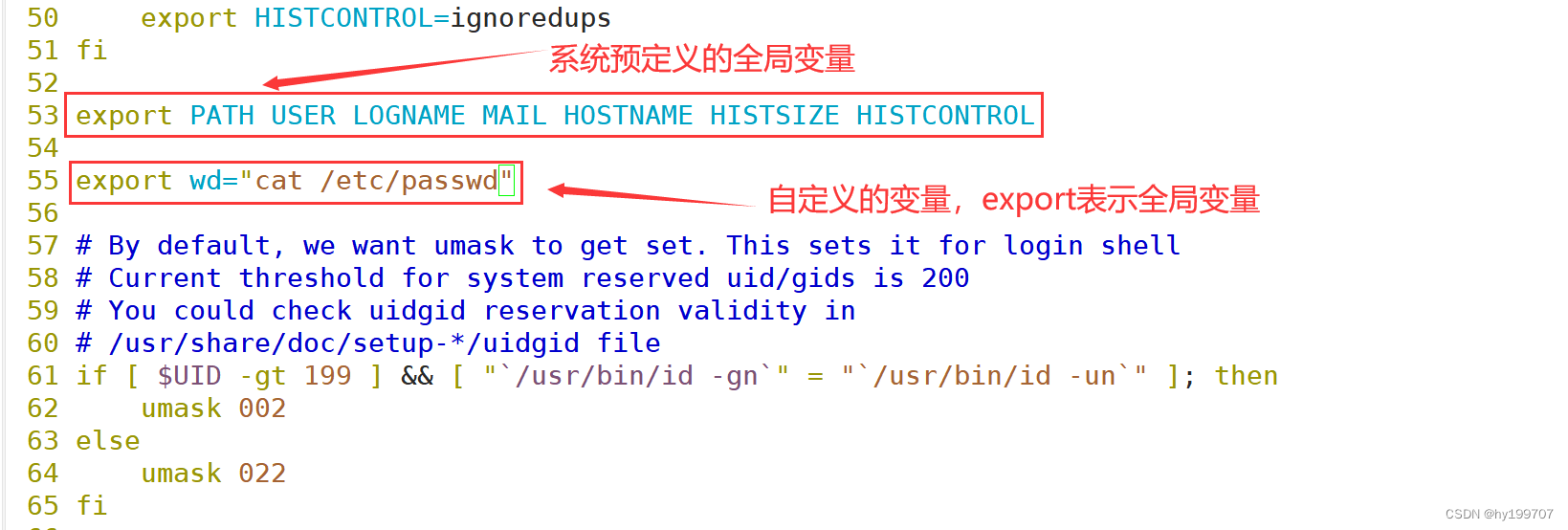
添加完之后重新执行以下文件就可以使用了

还有一种就是交互式定义变量:read -p
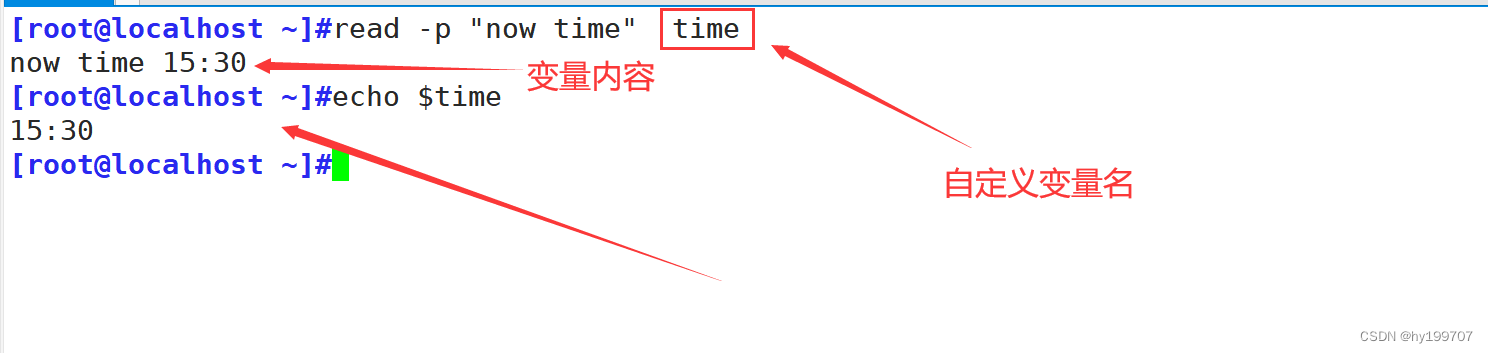
可以通过交互的方式自定义变量
2.只读变量
只读变量在声明后不能更改其值。在Bash shell中,通过readonly?命令来声明位置变量

一旦建立后,无法进行追加和删除

只能重启shell环境来进行删除
3.预定义变量
预定义变量是Shell在启动时就已经存在的变量,它们由系统自动初始化,并且具有特定含义和用途。例如
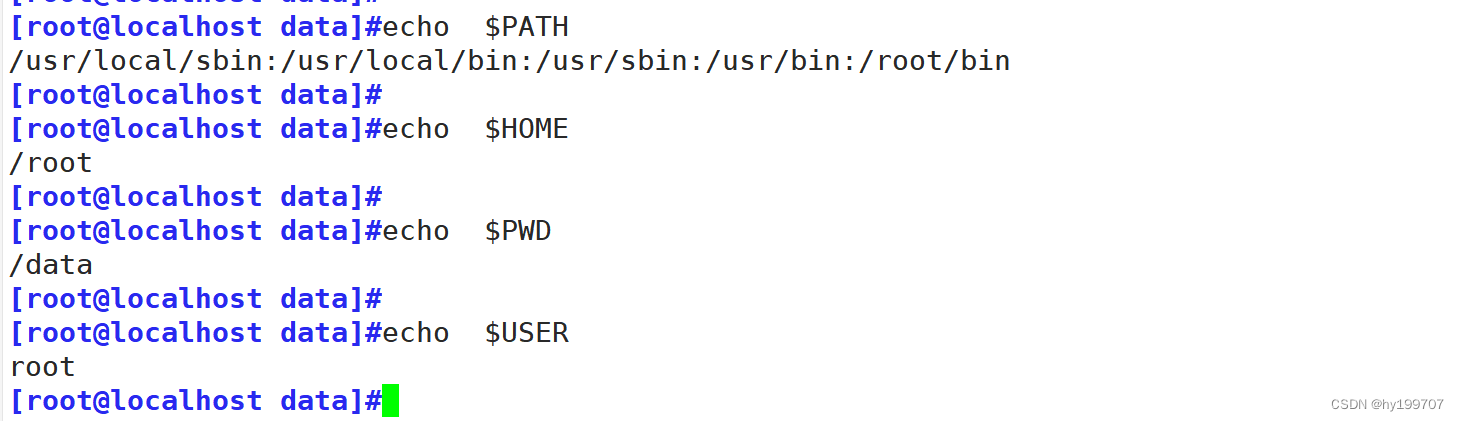
$HOME #当前用户的家目录路径。
$USER?或?$LOGNAME #当前用户的用户名。
$PATH #用于查找可执行文件的路径列表。
$PWD #当前工作目录(Present Working Directory)可以同过env命令进行查看当前系统有哪预定义变量
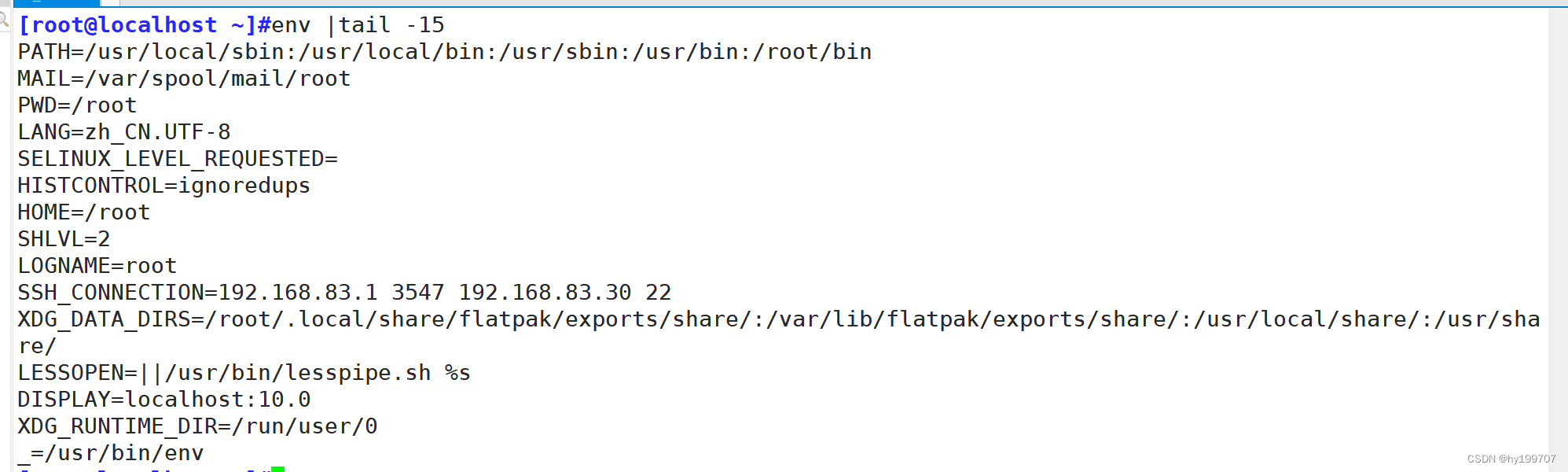
4.环境变量
环境变量是一种特殊的预定义变量,不仅在当前Shell会话中可用,还会被所有子进程继承。
在当前shell环境中定义的变量是无法自动被其它子进程继承的,需要通过export命令去赋予
 使用export会将自定义变量设置为全局变量:export? 变量名
使用export会将自定义变量设置为全局变量:export? 变量名

同步过后,无论打开多少子进程都可以使用,删除或退出后就会自定消失? ? ?
5.位置变量
指的是从命令行传递给脚本或函数的参数。每个参数都有一个编号,从 $0 开始,其中 $0 是脚本本身的名字,而 $1、$2、$3 等依次对应第一个、第二个、第三个参数等。
我们先来写一个脚本

#!/bin/bash
echo "脚本的文件名 $0" #会打印出脚本的文件名
echo "$1" #脚本后面的第一个参数
echo "$2" #脚本后面的第二个参数
echo "$3" #脚本后面的第三个参数
echo "${10}" #脚本后面的第十个参数注释:
①:$0是一个特殊变量,它代表脚本的文件名
②:${10}必须用大括号括起来,否则将$看成变量,在后面加0

(三)特殊变量与符号
1.符号
在变量中,有一些特殊符号,需要我们去掌握
| 符号 | 名称 | 作用 |
| "? ? ? ?" | 双引号 | 弱引用 可以识别变量 |
| ‘? ? ? ? ’ | 单引号 | 强引用 不能识别变量 |
| {? ? ? ?} | 大括号 | 定义变量名的范围 |
| `? ? ? ?` | 反撇 | 调用命令的执行结果 |
①双引号与单引号
双引号可以识别变量的值,而单引号会直接引用引号中的内容作为参数

②大括号
大括号是将变量的字符串长度,定义在括号的范围内,比如想在变量后面跟上指定的内容,直接输入$dizhi30,系统会人为dizhi30是一个变量,无法识别,需要写为{dizhi}30才可以识别

③反撇
这个字符的意思是调用命令的执行结果,可以将符号中的内容当作参数去执行
比如说,我想建立一个以今天日期命名的文件,可以使用touch? `date`去创建

2.特殊变量
在预定义变量中,还存在一些特殊变量,比如在之前说到的$0就是一种特殊变量
| $* | 代表一个整体,把所有位置参数当成整体返回 |
| $@ | 代表独立个体,把所有位置参数当成个体返回 |
| $? | 上一条命令的执行结果是否成功。正确为0,返回任何非0值为异常 |
| $#? | 代表位置参数个数 |
| $0? | 代表当前脚本的名称 |
| $$? | 当前bash的pid |
①$*与$@
这两个特殊变量会将所有位置的参数都打印出来

虽然显示的都是一样的,但是还是有一些区别

b.sh脚本的作用
bash? c.sh? "$*":是将c.sh脚本放在b.sh脚本里面运行,运行b.sh脚本时其本身并不能打印任何参数,运行c.sh脚本时,后面的参数就是运行b.sh时后面跟的参数,c.sh脚本只能打印一个参数。$*就表示所有变量,也就是说,不论运行b.sh脚本时后面跟多少参数,都会当成一个整体
a.sh脚本中$@所表示的含义就是将参数按单个返回,虽然能返回所有,但是在c.sh脚本中定义了,只打印第一个参数,所以$@只能返回第一个参数,如果$@变成$2,那么就会将第二个参数当作执行c.sh脚本时的第一个参数


这里可能很难理解,需要多花一些时间,也可以理解为
*:将1.txt ?2.txt ?3.txt看做一整个参数,代表$1
@:将每个文件分开返回$1是1.txt? ? $2是2.txt? ? ?$3 是?3.txt,$@本来想返回所有文件,但是因为c.sh脚本限制,只能显示一个
②$?
echo $??在Linux或类Unix系统中用于显示上一条命令执行后的退出状态码(Exit Status)。退出状态码是一个整数值,用来表示前一个命令的执行结果
0:通常表示成功执行。
非零值:通常表示错误或异常。具体的非零值可能根据不同的命令和程序有不同的含义,但一般来说,非零值代表了某种类型的失败

③$#
它代表传递给当前脚本或函数的命令行参数个数

表示有四个参数传递给了这个脚本。这对于判断用户是否提供了足够的参数或者根据参数数量执行不同的逻辑非常有用。
④$0
$0表示当前脚本文件的名称,之前就演示过,如果说将这个脚本创建了一个软链接,使用软链接执行脚本,就是软链接的名称,使用原文件,就是原文件的名称
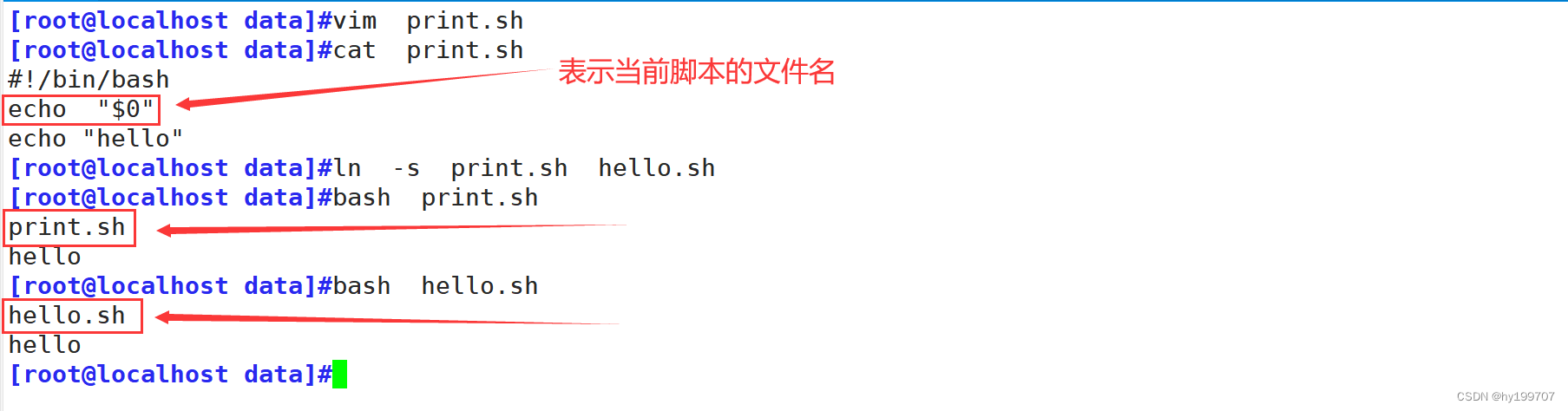
⑤$$
表示当前bash环境的PID号

本章总结
Shell的作用与应用场景
Shell脚本的编写规范与执行方法重定向与管道的作用与使用方法
自定义变量赋值时单引号、双引号、反撇号的使用方法
环境变量、只读变量、位置变量、预定义变量的用途
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 小明和完美序列——map
- 【Linux】磁盘结构 | 文件系统 | 软硬链接
- Git与VScode联合使用详解
- 【实战精选】车牌限行检测识别系统(源码&部署文档)
- [versal ] PS noc interface
- vue v-for循环拖拽排序,实现数组选中的数据拖拽后对应的子数据也进行重新排序
- OpenAI ChatGPT-4开发笔记2024-05:windows下anaconda中设置visual studio code workspace
- 基数(Radix)排序
- 魅族开发者应用认领说明
- 变量和函数提升(js的问题)