python_selenium&零基础爬虫学习案例_知网文献信息
案例最终效果说明:
????????去做这个案例的话是因为看到那个博主的分享,最后通过努力,我基本实现了进行主题、关键词、更新时间的三个筛选条件去获取数据,并且遍历数据将其导出到一个CSV文件中,代码是很简单的,没有太多的逻辑去判断,但是作为一个小白来说,如果刚刚学完selenium的朋友们可以做这个案例,那这个案例的话我就是用selenium的基本知识去完成的。同时所用到的python的基本知识也是比较简单的。
目录
学习笔记,根据这篇文章学习的,讲的很细致。
Python爬虫实战(5) | 爬取知网文献信息(已优化代码) - 知乎 (zhihu.com)
这个博主是利用selenium来爬取的,关于selenium的学习可以参考之前的笔记。
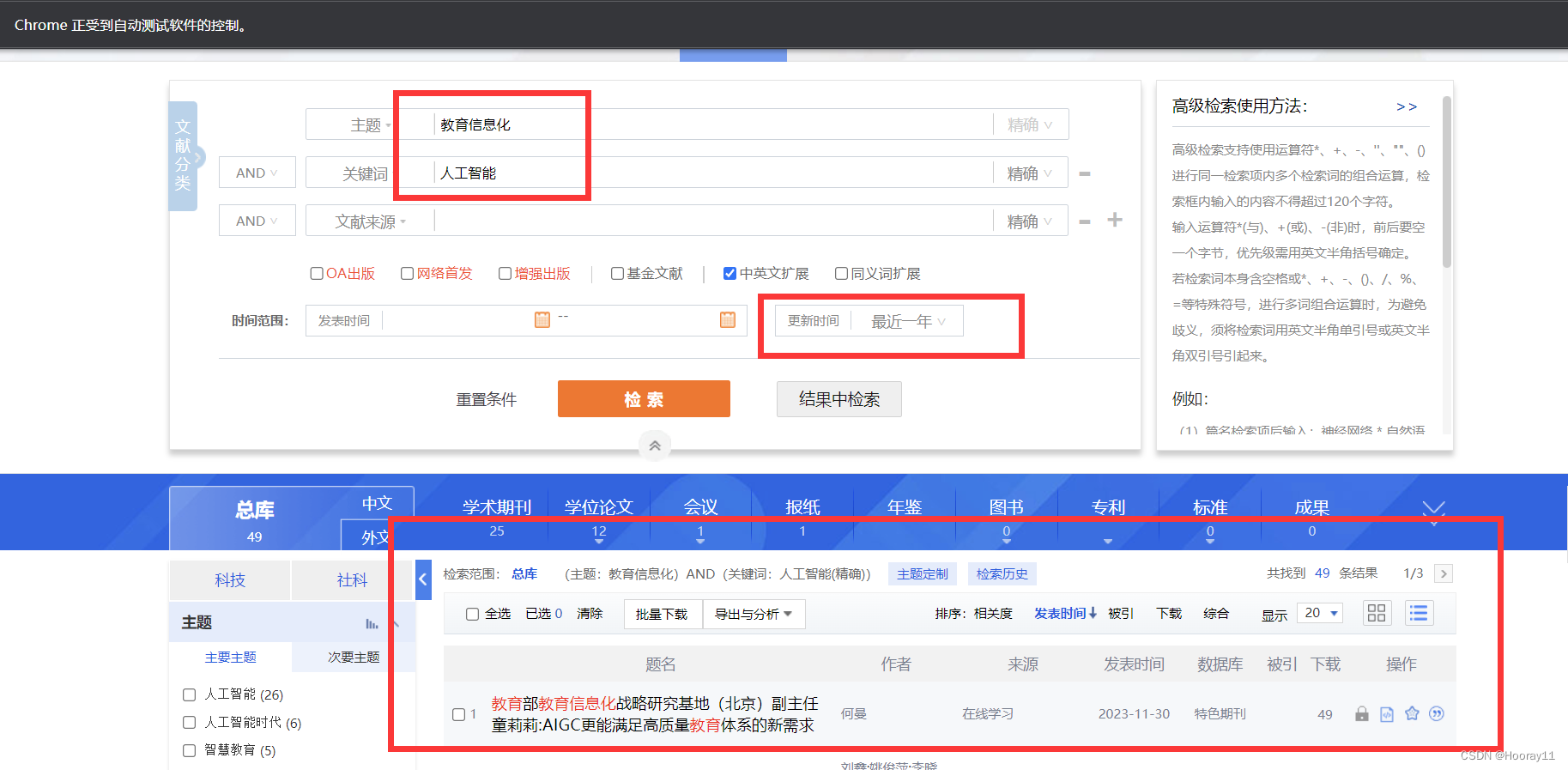
1.网页分析
目标网站:中国知网官网中国知网 (cnki.net)
需求分析:高级检索——>输入查询信息——>点击检索
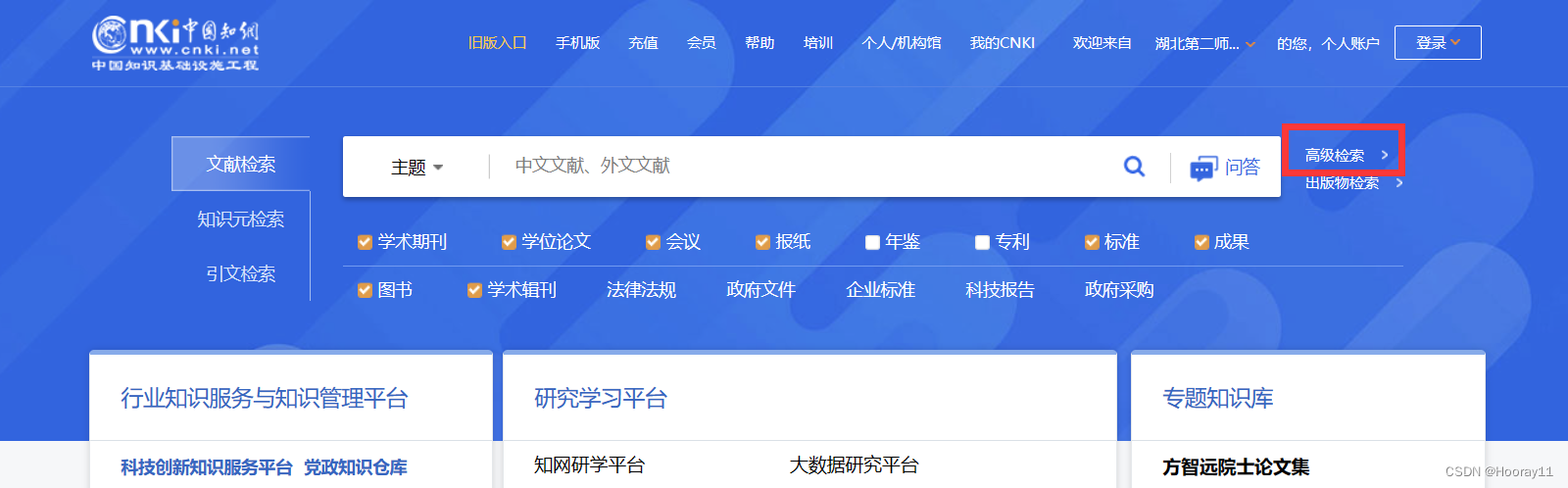

2.selenium元素定位&实现
先把要用到的包准备好,创建浏览器对象去访问网站,这里就直接展示代码了。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://www.cnki.net/'
browser.get(url)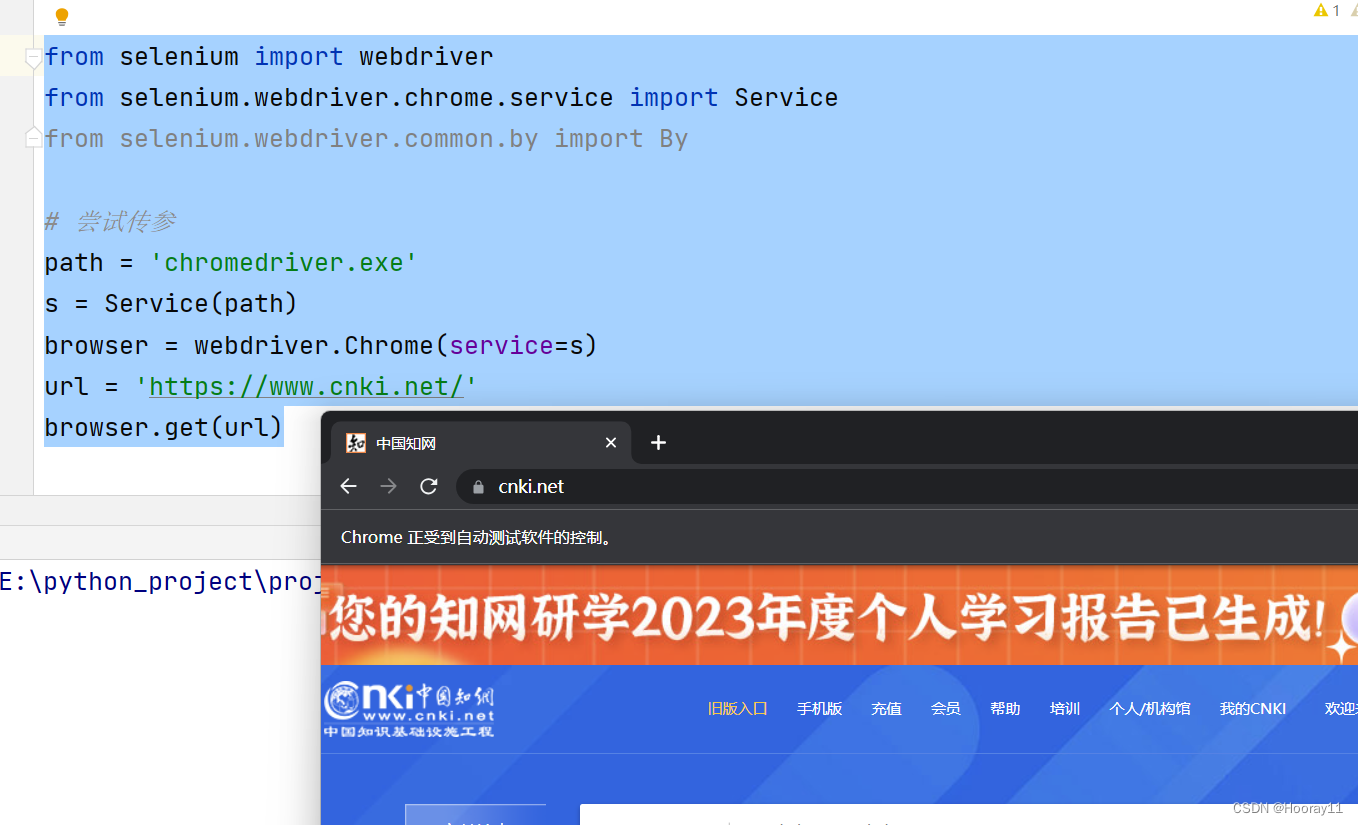
2.1找【高级检索】
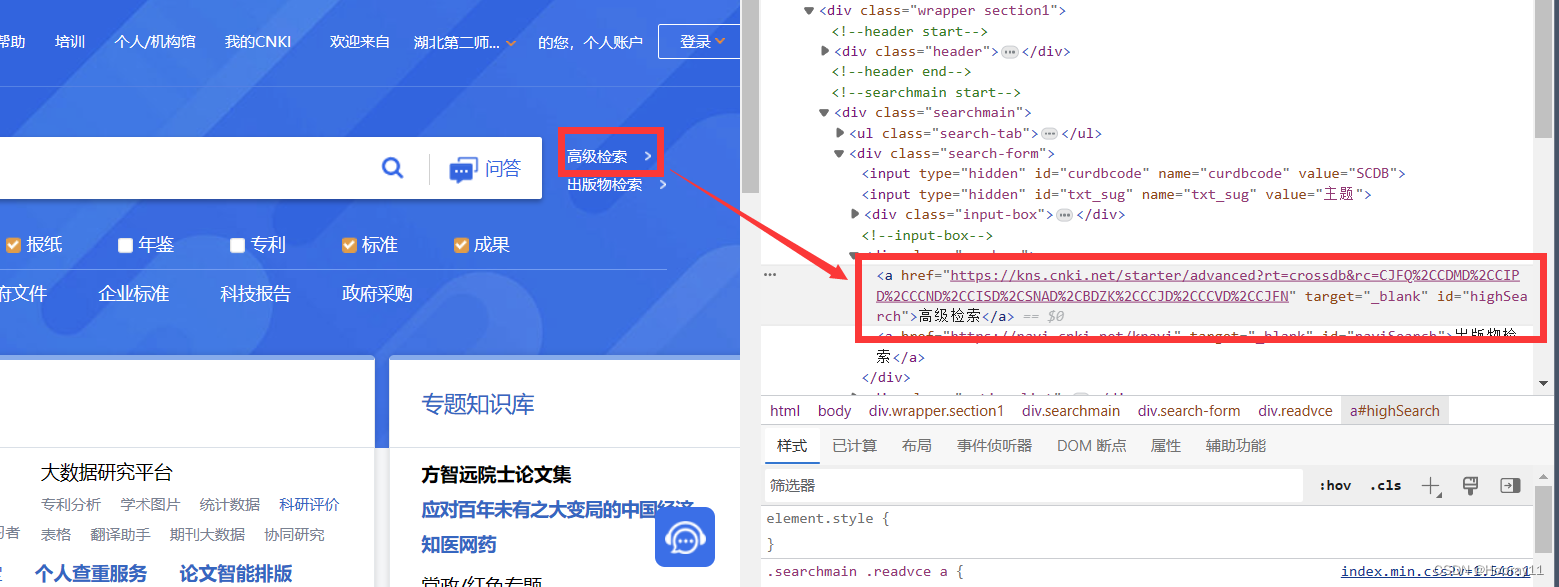
?这里可以直接复制到完整的xpath,就不用我们自己去寻找了了。
# 找高级检索
highSearch = browser.find_element(by='xpath',value='//*[@id="highSearch"]')
print(highSearch)2.2找【输入框】
注意:找输入框的时候我遇到了困难,因为点击高级检索之后,url变了,所以用之前的url对象不行,然后仔细看了那个作者发现,他的url直接就是高级检索的页面,所以这里我就也全部改了。
所以从这里开始,后面是新的,前面的是有问题的。
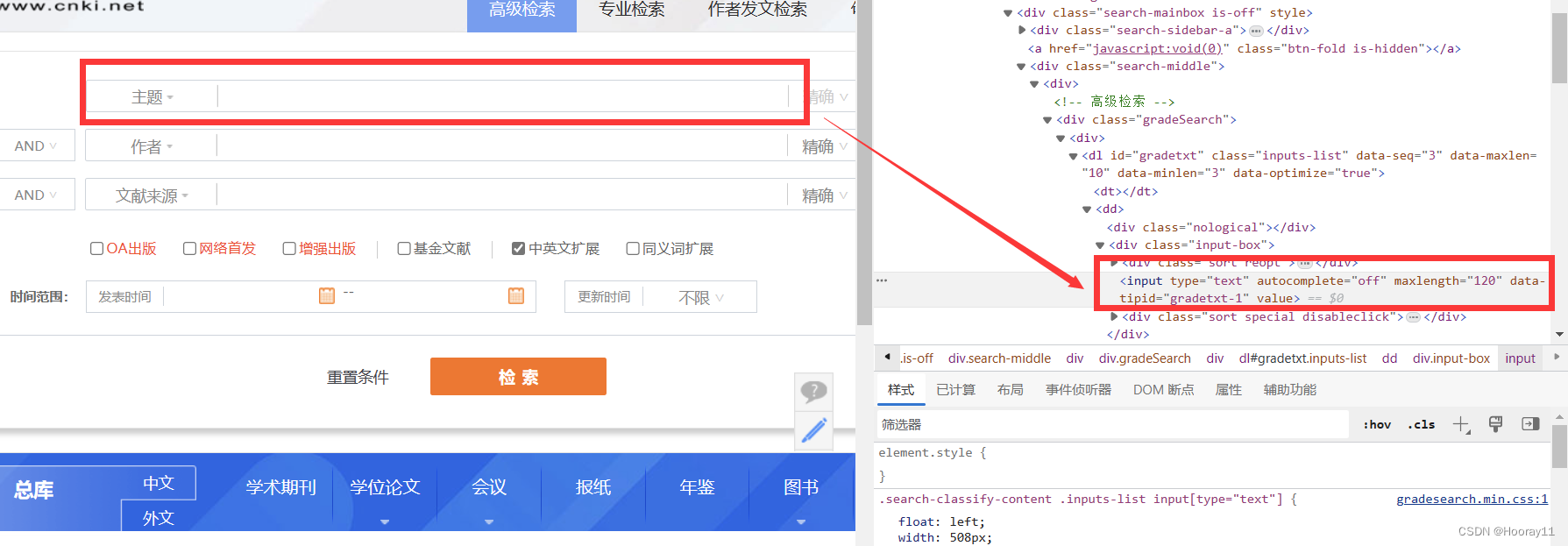
input = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[1]/div[2]/input')2.3找【检索】
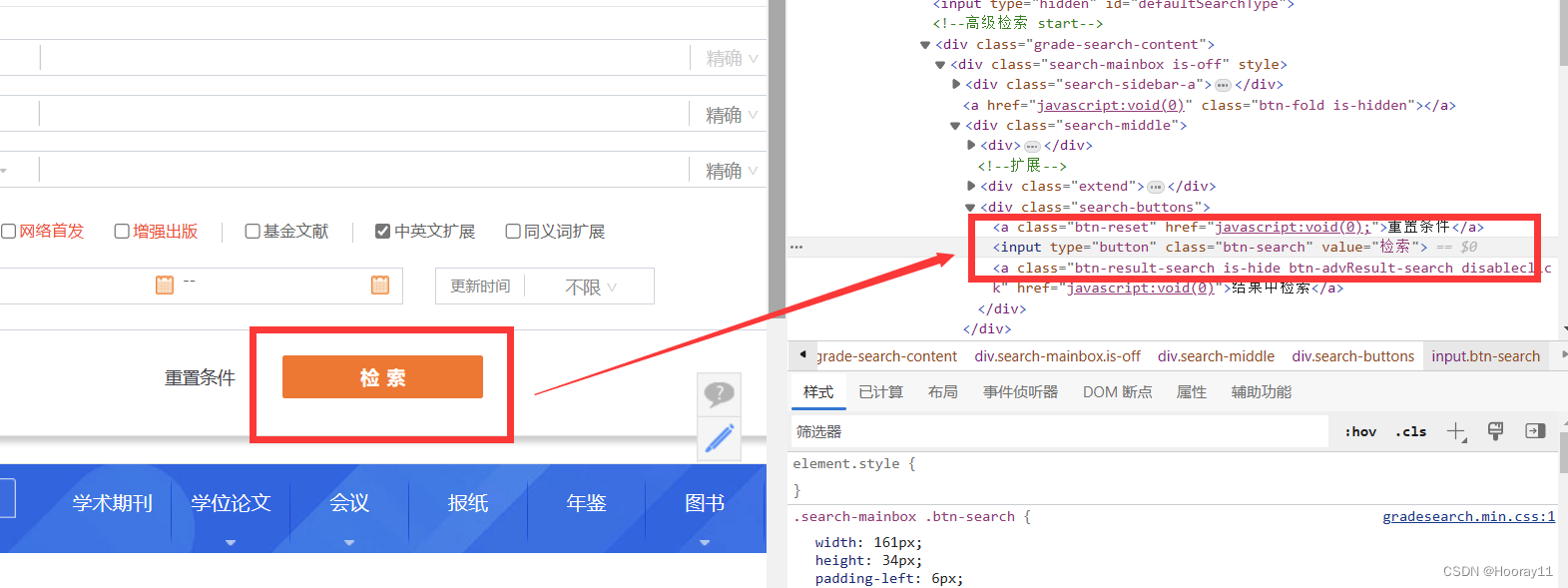
2.4汇总一
那截止到现在的话,我总共是写了这么多的代码。
那基本实现的就是在主题输入框内输入【教育信息化】,然后点击检索这样的功能。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://kns.cnki.net/kns8s/AdvSearch'
browser.get(url)
import time
time.sleep(2)
#找输入框
input = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')
print(input)
time.sleep(2)
# 输入查询内容
input.send_keys('教育信息化')
time.sleep(2)
# 找检索
search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')
time.sleep(2)
# 点击检索
search.click()
time.sleep(2)
2.5附加筛选条件
有时候做文献综述的时候,会要求有主题、关键词、篇文摘等要求,有时候要求的是近十年的文章,这种应该怎么办。
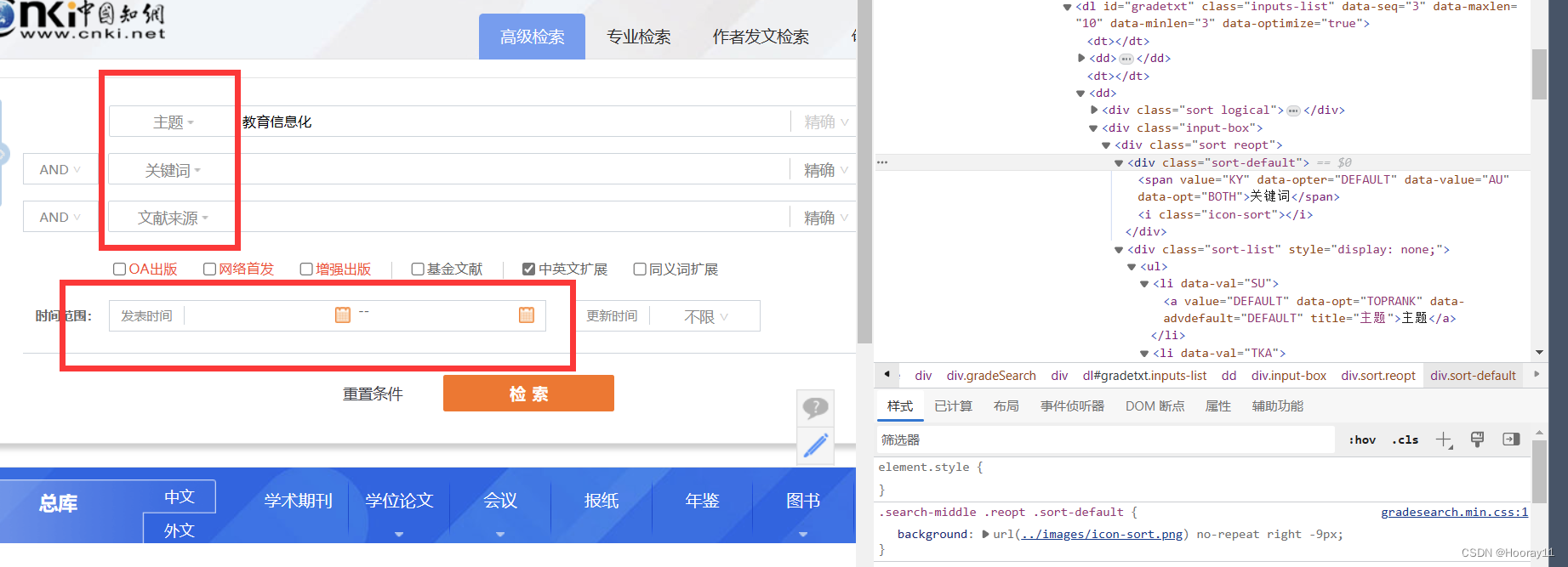
首先对于图中主题、关键词、文献来源这种看起来像下拉选择框的,通过仔细分析源码才发现其实不是下拉选择,而是对其他的选线进行了隐藏,只要点击其所在的盒子就可以出现选项。
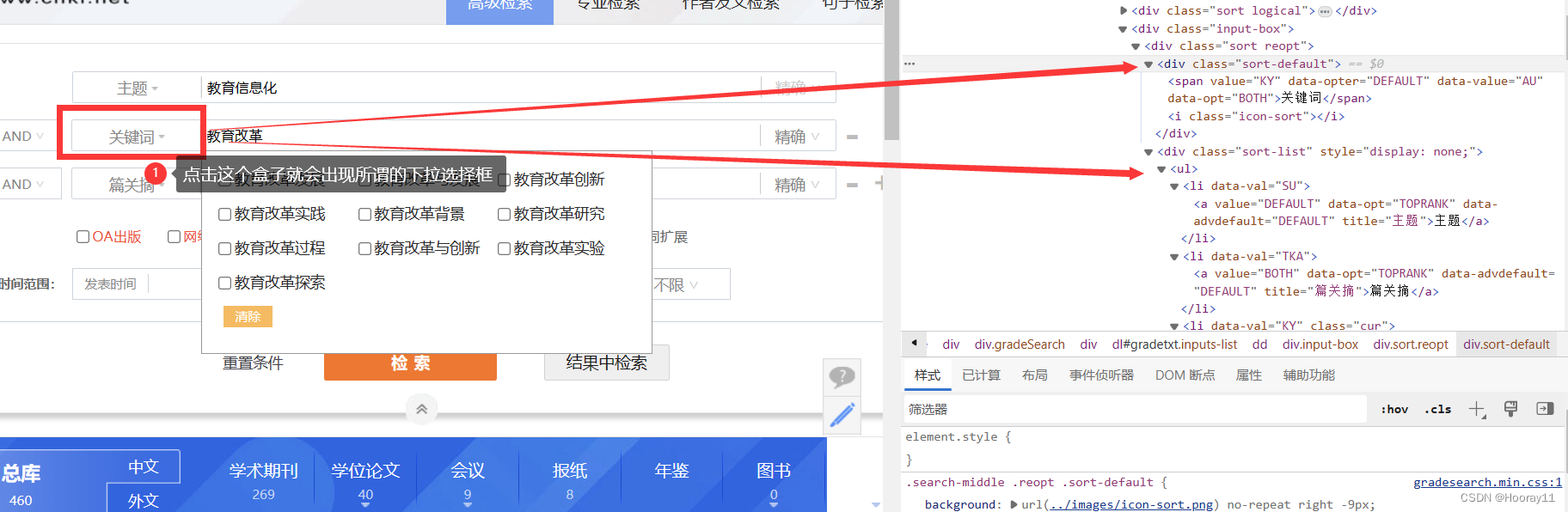
然后我就发现了一个特别有意思的现象。下面的两种情况,第一种的检索是可以点击的,也就是我们可以看到这个检索按钮,第二种情况,检索按钮被遮挡了,那后面运行点击检索按钮的时候就会报错,但是其实元素定位是没有问题的,就是运行click有问题。
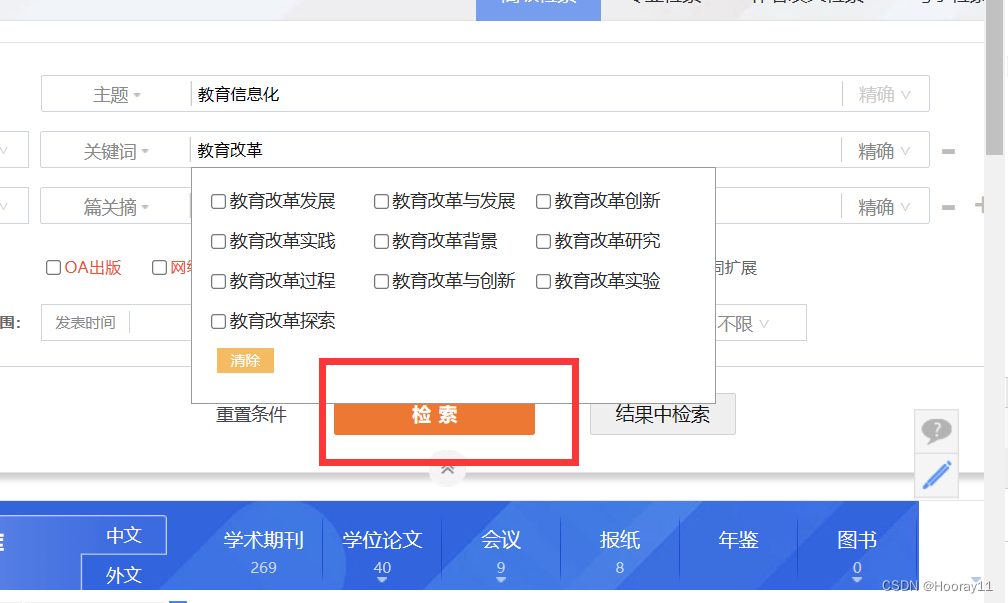
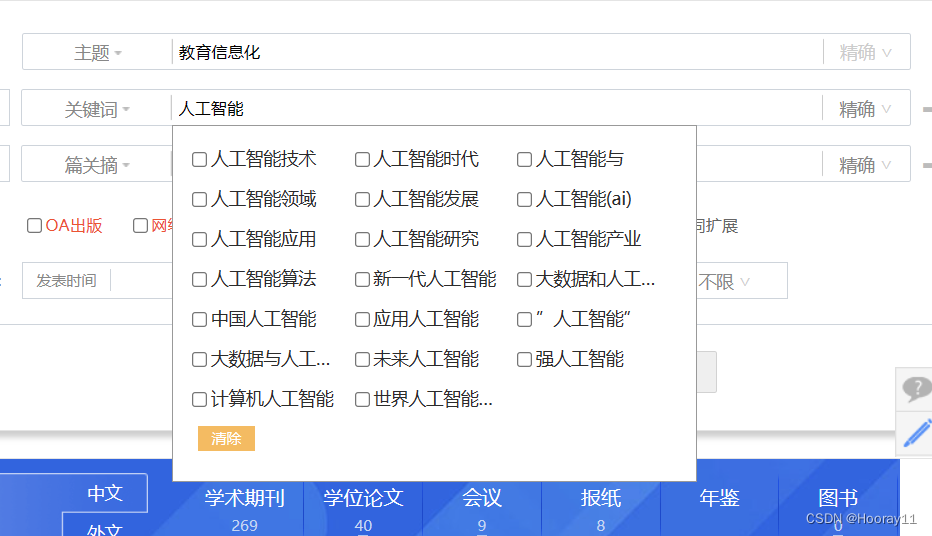
最后具体原因我也不知道,总之后面换成了运行javaScript的代码时没问题的。
到现在的话就是增加了可以更改选项多条件检索的。
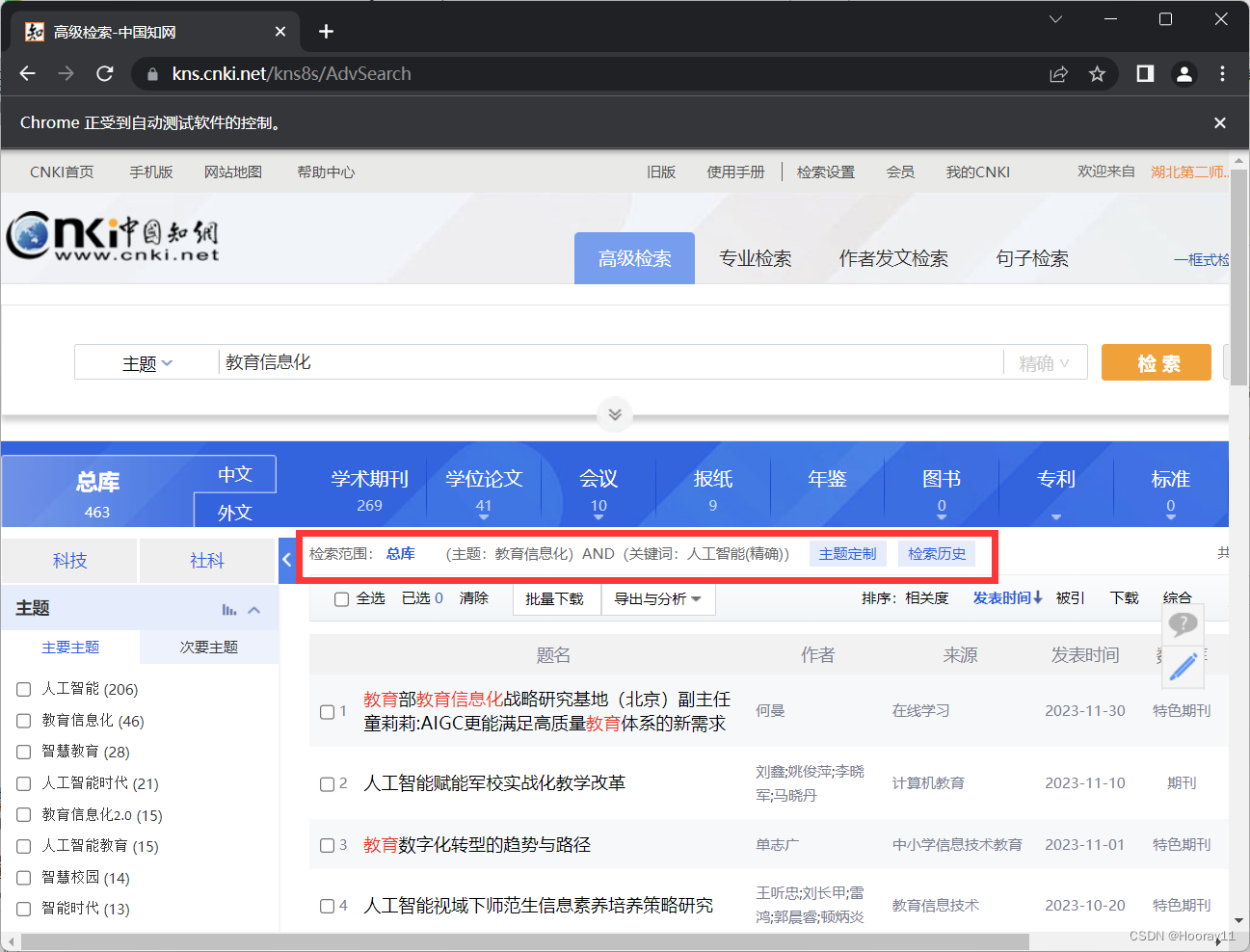
现在就来到了时间的板块,关于这个发表时间的日历选择方法,我不知道怎么解决。如果后面解决了就来更新吧。
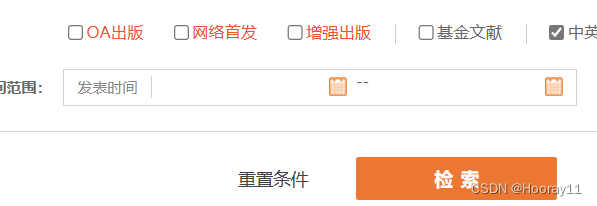
那我只能尝试解决这个,这一个它是由多种选择的.
那这个的基本原理跟之前的一样,看似是一个下拉选择框其实也是隐藏的一个盒子。
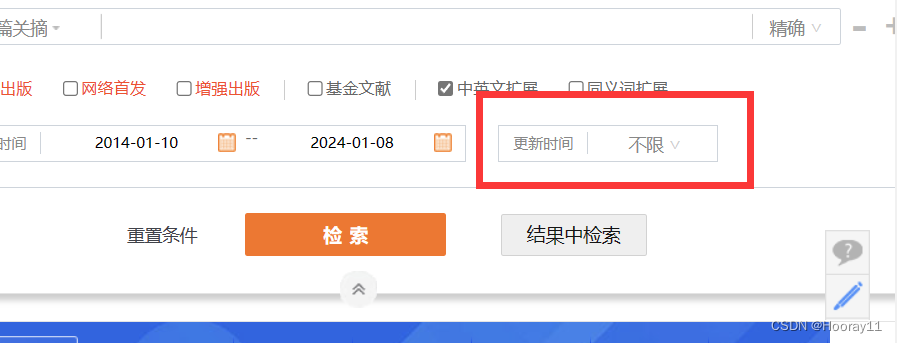
然后就基本附加了一些筛选条件进行检索。
2.6汇总二
纯属小白写的代码哈哈哈哈。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://kns.cnki.net/kns8s/AdvSearch'
browser.get(url)
import time
time.sleep(2)
#找输入框
input1 = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')
time.sleep(2)
# 输入查询内容
input1.send_keys('教育信息化')
time.sleep(2)
# 更改选项——关键词
select = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')
select.click()
time.sleep(2)
key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')
key_word.click()
time.sleep(2)
# 输入查询内容
input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')
input2.send_keys('人工智能')
time.sleep(2)
# 更改时间
time_change = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')
time_change.click()
time.sleep(2)
select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')
select_time.click()
time.sleep(2)
# 找检索
search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')
time.sleep(2)
# 点击检索
# search.click() #这个方法没用
browser.execute_script("arguments[0].click();", search) #这个方法有用
# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用
time.sleep(2)
3.数据解析
3.1网页分析

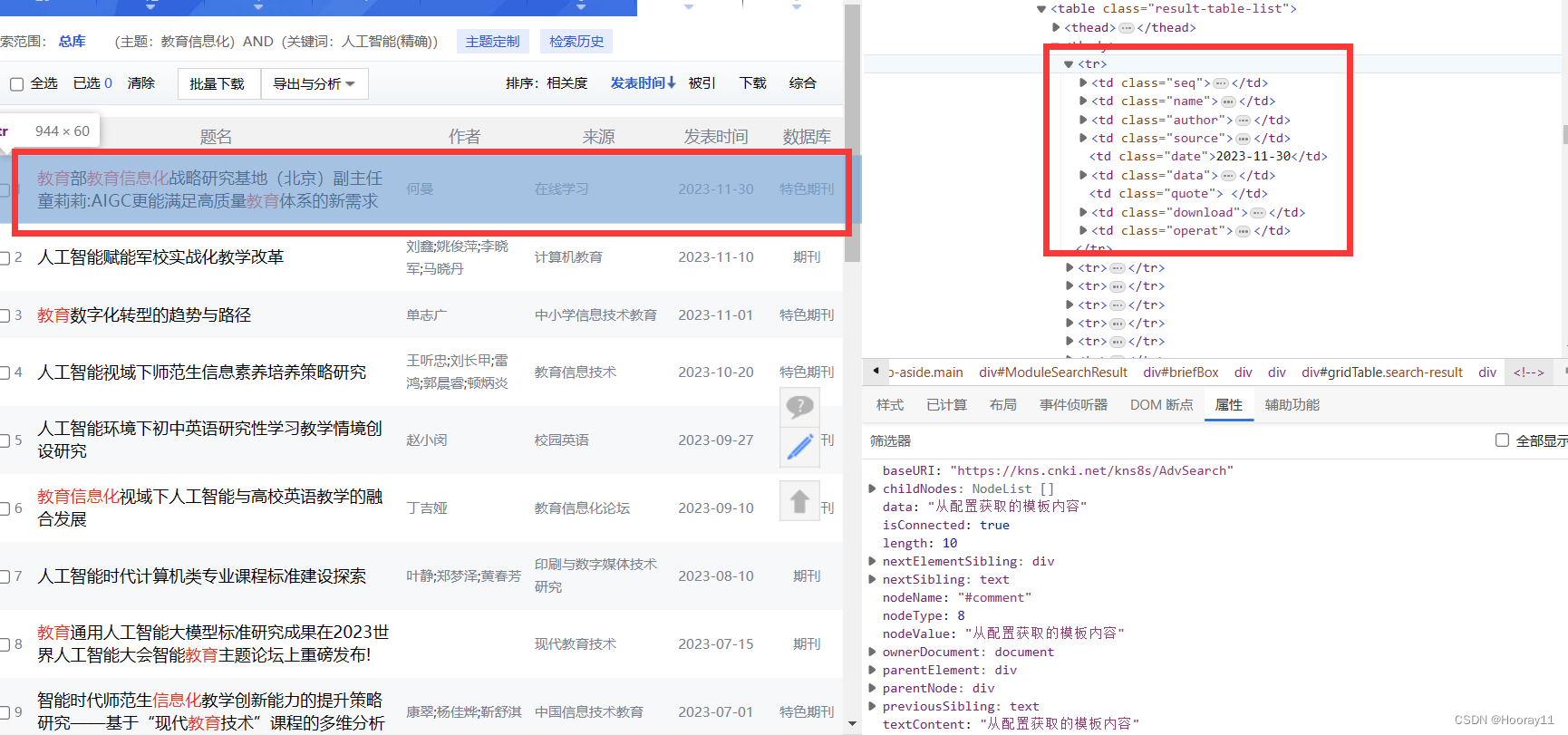
对于一篇文章的xpath我们可以发现:
题名:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]
作者:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[3]
来源:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[4]
可以发现一些规律,td[2]到td[6]都是这篇文献的信息。
但是我们无法获得这篇文献的关键字以及摘要等信息,就需要点进去才可以看到。
对于一整页的每一篇文章我们可以发现:
第一条:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]
第二条:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[2]
第三条:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[3]
那么tr[1]到tr[20]对应的就是每一条信息,这对于我们后面分析xpath路径有关。

title_list = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "fz14")))上面的代码时从原作者那里复制过来的,根据上下文的意思应该就是需要知道每一页有多少条数据,但是我看了好久才知道他这个写的奥妙,一开始我在想怎么去获取表单数据然后将其储存为列表,但是搜了好久都没找到方法,然后我就根据这个博主的代码去结合网页源码看,结果发现其实这个博主就是很简化了这个问题,只要能获取表单数据的条数就可以了。
那这个作者就是根据题名来找到所有类属性为fz14的数据,就可以知道他的表单数据的长度了。
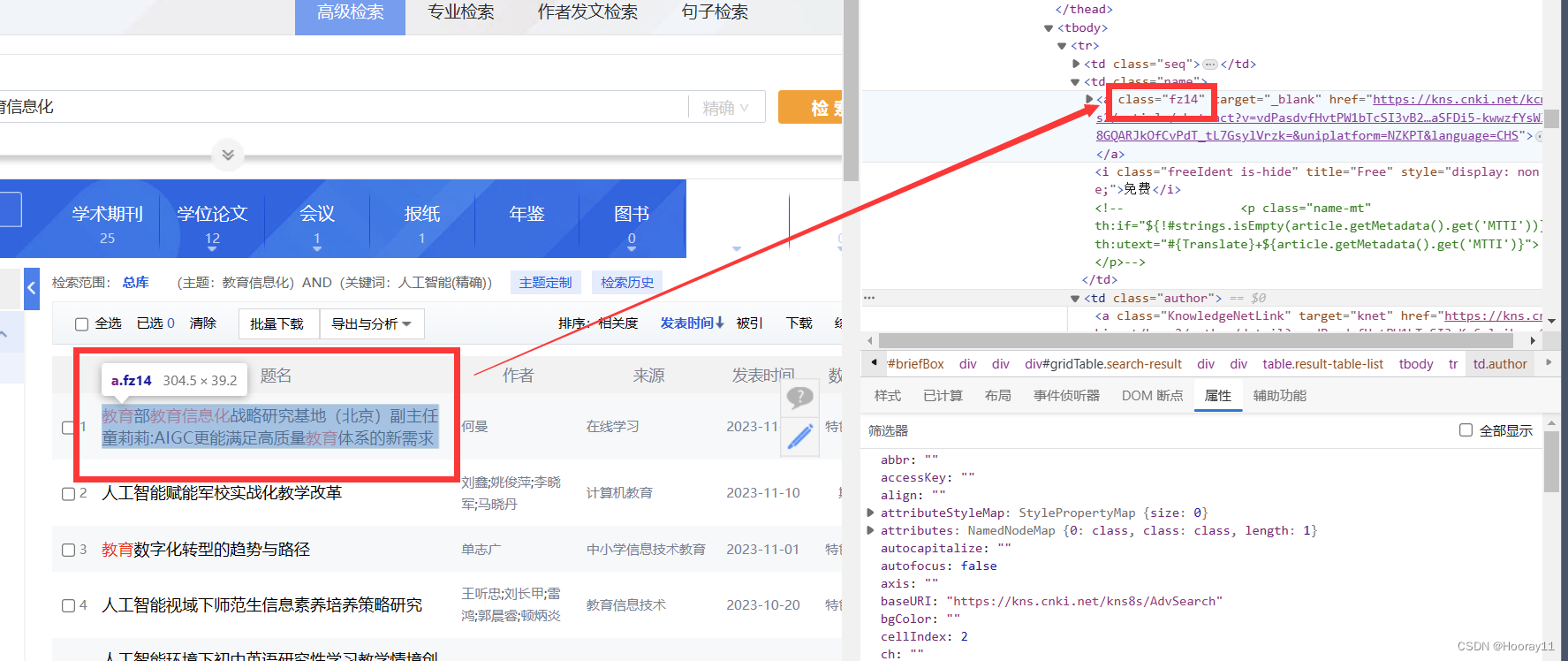
那么现在就是要根据之前所找到的规律去写xpath路径了,同时通过解析得到我们想要的数据。然后再多次的尝试下我终于成功拿到了数据。


3.2储存数据
我是将其存在一个CSV文件里。
简单学习了一下CSV的存储,大家也可以参考这个博主的文章。
?
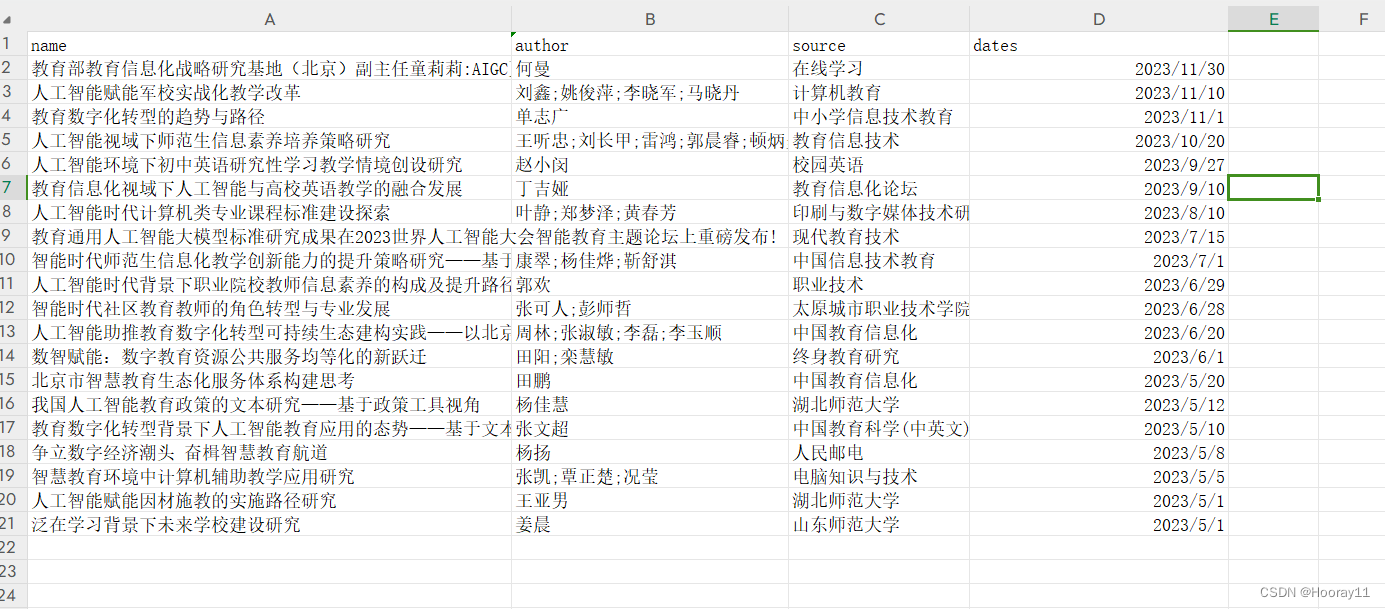
那截止到现在的话,我总共时实现了一个页面的存储,现在的话就是尝试将所有页面进行存储,所以就需要将他们封装成函数方法进行调用,希望我可以成功吧。
3.3第一次尝试(23-01-08)
那今天的尝试,没有实现翻页后继续存储,之后我在看看是咋回事,那现在的话就是我知道最后检索出来的结果是49条数据,总共3页,然后我自己设置了函数方法的调用次数,之后再思考怎么解决这个问题。
当然我写的代码由许多的不足,性能也比较差,也不太稳定,我得再研究研究别人的。今天就到这里吧!
附上我目前的代码。
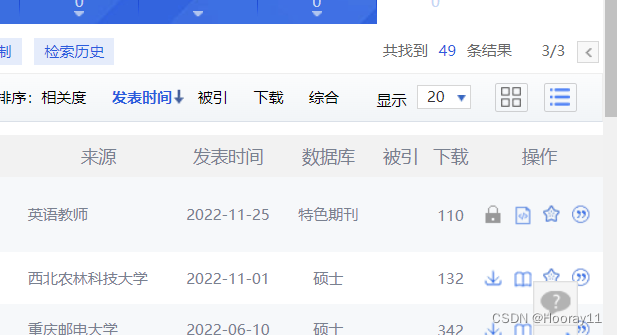
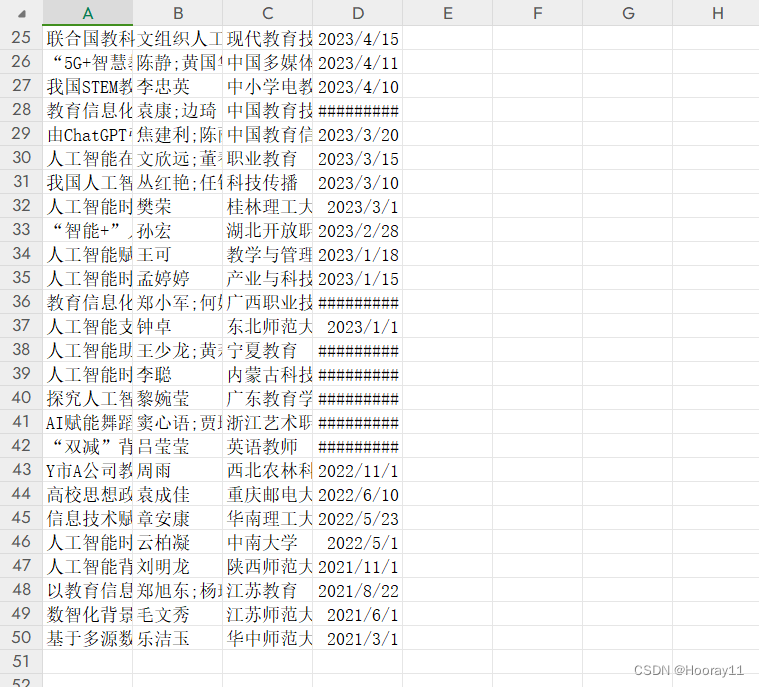
?
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import csv
import time
flag = 0
# CSV文件的创建与初始化
header = ['name', 'author ','source', 'dates']
with open('CNKI.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
def open_page():
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://kns.cnki.net/kns8s/AdvSearch'
browser.get(url)
time.sleep(2)
#找输入框
input1 = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')
time.sleep(2)
# 输入查询内容
input1.send_keys('教育信息化')
time.sleep(2)
# 更改选项——关键词
select = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')
select.click()
time.sleep(2)
key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')
key_word.click()
time.sleep(2)
# 输入查询内容
input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')
input2.send_keys('人工智能')
time.sleep(2)
# 更改时间
time_change = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')
time_change.click()
time.sleep(2)
select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')
select_time.click()
time.sleep(2)
# 找检索
search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')
time.sleep(2)
# 点击检索
# search.click() #这个方法没用
browser.execute_script("arguments[0].click();", search) #这个方法有用
# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用
time.sleep(2)
return browser
# name = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]').text
# print(name)
def analyz(browser):
global flag
# 获取每一页的数据长度
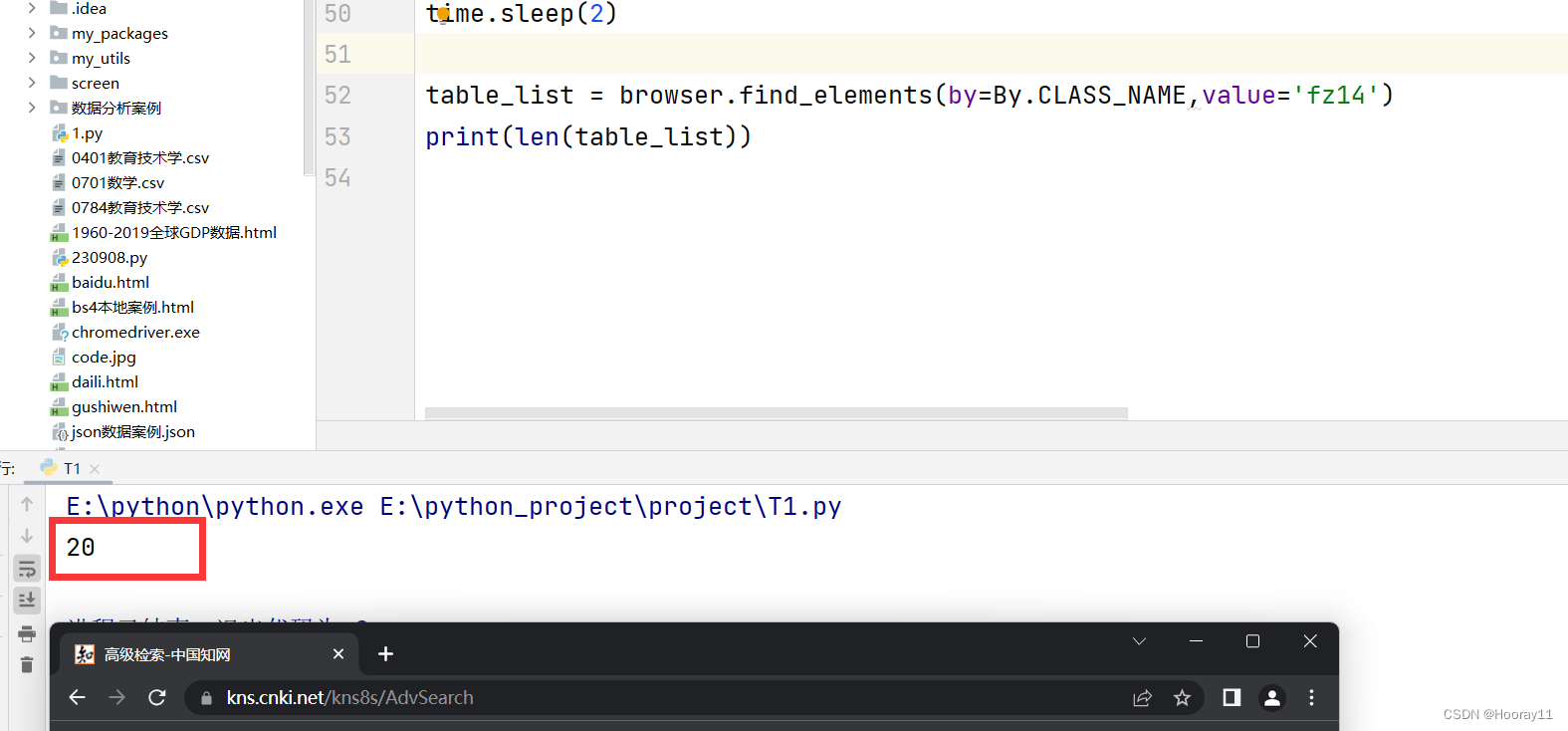
table_list = browser.find_elements(by=By.CLASS_NAME,value='fz14')
# 循环遍历数据
for term in range(1,len(table_list)+1):
# 定义xpath语句
name_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[2]'
author_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[3]'
source_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[4]'
date_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]'
# 获取文本信息
name = browser.find_element(by='xpath',value=name_xpath).text
author = browser.find_element(by='xpath',value=author_xpath).text
source = browser.find_element(by='xpath',value=source_xpath).text
dates = browser.find_element(by='xpath',value=date_xpath).text
print(name,author,source,dates)
# 写入CSV文件
data = [name, author,source,dates]
with open('CNKI.csv', 'a', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(data)
# if term == len(table_list):
# flag = 1
def change_page():
global flag
# 滑倒底部
js = 'window.scrollTo(0,document.body.scrollHeight)'
browser.execute_script(js)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element(by='xpath', value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a')
# 点击下一页
next.click()
time.sleep(2)
if __name__ == "__main__":
browser = open_page()
analyz(browser)
change_page()
analyz(browser)
change_page()
analyz(browser)
3.4第二次尝试(23-01-09)
那这一次的尝试是基于之前的代码做了一些修改。
那这一次的话,我在open_page这个函数方法中去获取检索结果的总共条目以及总共的页数,这两个数据非常重要。
获取总共的结果数目很简单可以直接通过xpath解析可以获得,那总共由多少页,我是通过元素的信息去获取的,因为我发现data-pagenum这个属性刚好就是页数,所以可以直接运用get_attribute方法去获得数据,但是这里需要注意的是,所获取的page_num一定要转成Int,我当时就是没有转成int导致无法从递归中跳出来,真的是搞了好久才发现。
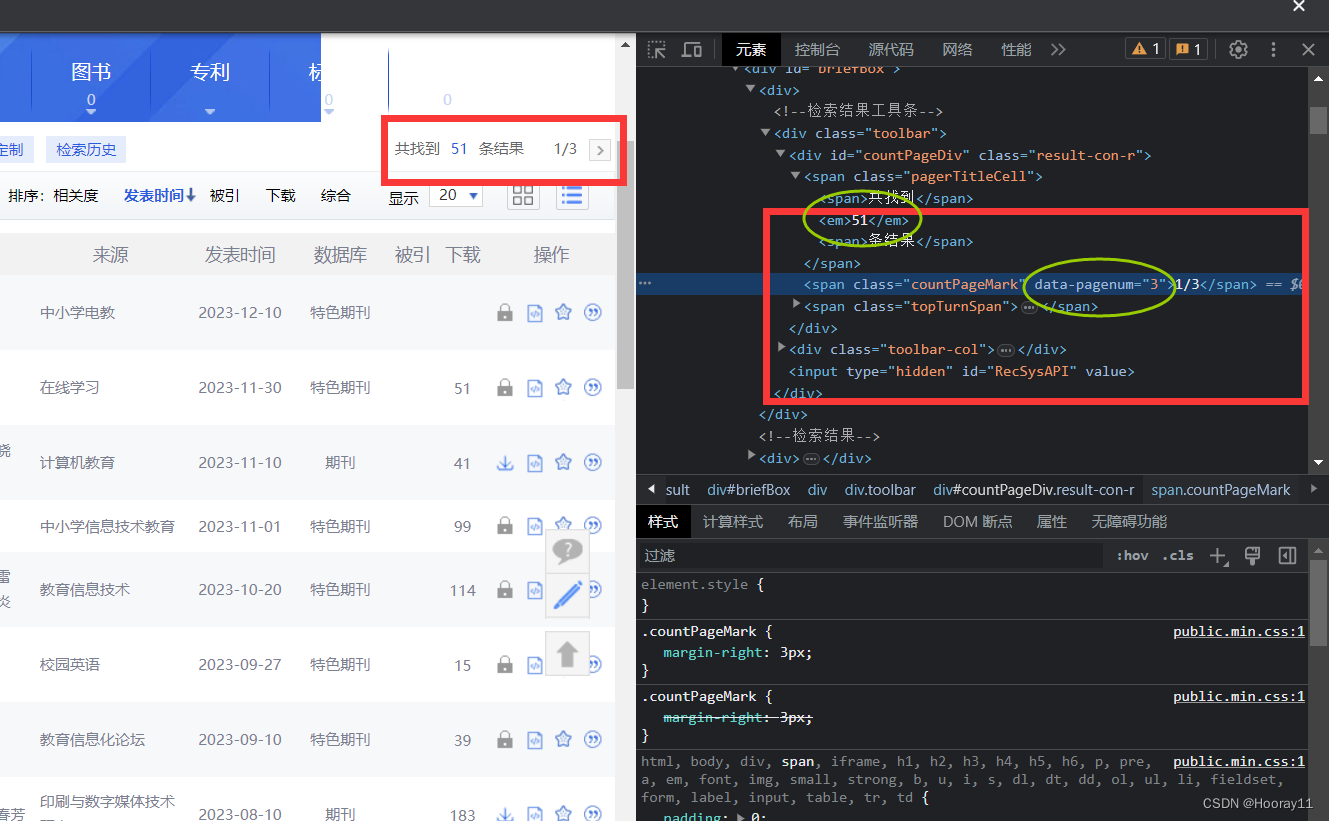
那我就是递归调用analyze这个函数方法,然后设置好递归出口就可以了,递归出口就是统计页数然后当页数等于page_num的时候就跳出来,就可以基本实现功能了。
附上代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import csv
import time
count = 0
# CSV文件的创建与初始化
header = ['name', 'author ','source', 'dates']
with open('CNKI.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
def open_page():
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://kns.cnki.net/kns8s/AdvSearch'
browser.get(url)
time.sleep(2)
#找输入框
input1 = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')
time.sleep(2)
# 输入查询内容
input1.send_keys('教育信息化')
time.sleep(2)
# 更改选项——关键词
select = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')
select.click()
time.sleep(2)
key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')
key_word.click()
time.sleep(2)
# 输入查询内容
input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')
input2.send_keys('人工智能')
time.sleep(2)
# 更改时间
time_change = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')
time_change.click()
time.sleep(2)
select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')
select_time.click()
time.sleep(2)
# 找检索
search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')
time.sleep(2)
# 点击检索
# search.click() #这个方法没用
browser.execute_script("arguments[0].click();", search) #这个方法有用
# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用
time.sleep(2)
# 获得检索出来的所有条目个数
res_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[1]/em').text
# 去除千分位的逗号
res_num = int(res_num.replace(",",""))
# 获取结果页数
page_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[2]')
page_num = page_num.get_attribute('data-pagenum')
# 打印结果
print((f"共找到 {res_num} 条结果,共 {page_num} 页。"))
return browser , page_num
# name = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]').text
# print(name)
def analyz(browser,page_num):
global count
# 获取每一页的数据长度
table_list = browser.find_elements(by=By.CLASS_NAME,value='fz14')
# 循环遍历数据
for term in range(1,len(table_list)+1):
# 定义xpath语句
name_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[2]'
author_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[3]'
source_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[4]'
date_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]'
# 获取文本信息
name = browser.find_element(by='xpath',value=name_xpath).text
author = browser.find_element(by='xpath',value=author_xpath).text
source = browser.find_element(by='xpath',value=source_xpath).text
dates = browser.find_element(by='xpath',value=date_xpath).text
print(name,author,source,dates)
# 写入CSV文件
data = [name, author,source,dates]
with open('CNKI.csv', 'a', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(data)
if term == len(table_list):
count += 1
print(f"第{count}页已经捕捉完毕")
if count == page_num:
print("全部捕捉完毕")
break
change_page()
time.sleep(2)
analyz(browser,page_num)
time.sleep(2)
def change_page():
global flag
# 滑倒底部
js = 'window.scrollTo(0,document.body.scrollHeight)'
browser.execute_script(js)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element(by='xpath', value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a')
# 点击下一页
next.click()
time.sleep(2)
if __name__ == "__main__":
tuple1 = open_page()
browser = tuple1[0]
page_num = int(tuple1[1])
print(page_num)
analyz(browser,page_num)
browser.quit()

3.5第三次尝试(最终版)(23-01-09)
这一次我改变了一点点的结构,然后怎么优化代码目前只是说让打开网页的时候不去加载图片来提高效率吧。然后其次就是遇到了一些没有考虑到的情况去修改检查,避免报错吧。总之,这个案例的话大致就是完成了,虽然可能不能真正用来去处理爬取真正有用的数据,但是对selenium的学习以及实际的应用中有了更加深刻的认识,算是巩固自己刚刚学习的知识吧。
附上代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
import time
count = 0
# CSV文件的创建与初始化
header = ['name', 'author ', 'source', 'dates']
with open('CNKI.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
# 打开网页获取数据
def open_page(theme,key_words):
# 尝试传参
path = 'chromedriver.exe'
# 设置不加载图片
browser_option = webdriver.ChromeOptions()
browser_option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建对象
s = Service(path)
browser = webdriver.Chrome(service=s,options=browser_option)
url = 'https://kns.cnki.net/kns8s/AdvSearch'
browser.get(url)
time.sleep(2)
# 找输入框
input1 = browser.find_element(by='xpath', value='//*[@id="gradetxt"]/dd[1]/div[2]/input')
time.sleep(2)
# 输入查询内容
input1.send_keys(f'{theme}')
time.sleep(2)
# 更改选项——关键词
select = browser.find_element(by='xpath', value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')
select.click()
time.sleep(2)
key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')
key_word.click()
time.sleep(2)
# 输入查询内容
input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')
input2.send_keys(f'{key_words}')
time.sleep(2)
# 更改时间
time_change = browser.find_element(by='xpath', value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')
time_change.click()
time.sleep(2)
select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')
select_time.click()
time.sleep(2)
# 找检索
search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')
time.sleep(2)
# 点击检索
# search.click() #这个方法没用
browser.execute_script("arguments[0].click();", search) # 这个方法有用
# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用
time.sleep(2)
# 考虑到结果的页数没有或者条目为0的情况
try:
# 获得检索出来的所有条目个数
res_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[1]/em').text
# 去除千分位的逗号
res_num = int(res_num.replace(",", ""))
except:
res_num = 0
try:
# 获取结果页数
page_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[2]')
page_num = page_num.get_attribute('data-pagenum')
except:
page_num = 1
# 打印结果
print((f"共找到 {res_num} 条结果,共 {page_num} 页。"))
return browser, page_num
# name = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]').text
# print(name)
# 数据解析并导出
def analyz(browser, page_num):
global count
# 获取每一页的数据长度
table_list = browser.find_elements(by=By.CLASS_NAME, value='fz14')
# 循环遍历数据
for term in range(1, len(table_list) + 1):
# 定义xpath语句
name_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[2]'
author_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[3]'
source_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[4]'
date_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]'
# 获取文本信息
name = browser.find_element(by='xpath', value=name_xpath).text
author = browser.find_element(by='xpath', value=author_xpath).text
source = browser.find_element(by='xpath', value=source_xpath).text
dates = browser.find_element(by='xpath', value=date_xpath).text
print(name, author, source, dates)
# 写入CSV文件
data = [name, author, source, dates]
with open('CNKI.csv', 'a', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(data)
# 递归捕捉每一页的数据
if term == len(table_list):
count += 1
print(f"第{count}页已经捕捉完毕")
if count == page_num:
print("全部捕捉完毕")
break
change_page()
time.sleep(2)
analyz(browser, page_num)
time.sleep(2)
# 切换页面点击下一页
def change_page():
global flag
# 滑倒底部
js = 'window.scrollTo(0,document.body.scrollHeight)'
browser.execute_script(js)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element(by='xpath', value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a')
# 点击下一页
next.click()
time.sleep(2)
if __name__ == "__main__":
# 设置查找的主题和关键词
theme = '人工智能'
key_words = '教育'
tuple1 = open_page(theme,key_words)
browser = tuple1[0]
page_num = int(tuple1[1])
analyz(browser, page_num)
browser.quit()
4.总结
4.1第一次总结(23-01-08)
????????那这是我初学selenium第一次做的实际案例,体验感还是很不错的。虽然中间的过程也很艰辛,就是在不断地去思考下一步怎么做,虽然是根据别的博主的案例来学习的,但是我也尽量的以自己现在的一个学习状况来完成这些代码,所以跟原博主的还是由很大的差别,感觉别人写得很高级,然而我的水平还没到,我只能用自己现在所学来解决这个问题。
????????当然我觉得案例学习的方法很好,不仅引导自己主动去思考新学的知识,主动查阅资料,自己调试代码,去思考,还可以让自己去接触一些在日常生活中无法系统去学习到的知识。
????????给自己加油吧哈哈哈哈哈哈哈!
4.2第二次总结(23-01-09)
????????那这一次的修改其实很简单,昨天晚上的时候就一直在思考怎么去根据页数来调用,然后就增加了两个变量,在打开网页进行检索的时候就尽可能地去观察有用地信息,当然如果利用信息条目数量去判断地话也是可以的。
????????那现在的话我在尝试去优化代码的性能,因为现在加载的就是比较慢。并且递归调用函数方法这个算法绝对也是不咋行的。还是要去学习学习其他的哈哈哈哈哈。
4.3第三次总结(23-01-09)
????????那关于这一个案例就已经差不多结束了,目前可能比较适合跟我一样刚刚学完selenium来练手的案例吧,做到去真正的实际运用,可能后面只能简单的对这些数据进行一些统计。
????????总之基本的功能是可以实现的。但是关于页面的跳转可能还需要继续学习,比如去点击没一排你文章到里面去获得他的关键词和摘要啊。后面可以根据这个再进行改进。
????????在这里记录一个大佬的分享;selenium 谷歌 火狐 浏览器设置参数_java火狐修改window.navigator.webdriver-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RK3568驱动指南|第十二篇 GPIO子系统-第129章 GPIO控制和操作实验
- 从零学算法46
- Ceph入门到精通-SSL_read() failed SSL: error SSL routines:tls 1_enc:internal error
- pyDAL一个python的ORM(9) pyDAL的嵌套查询
- ES 重建索引
- Rust与python联动进行多线程跑数据
- 代码随想录算法训练营第二十四天 | 回溯算法终于开始了!77. 组合
- 【vCenter Converter】VMware vCenter Converter Standalone 理论, 下载与安装要求
- 像SpringBoot一样使用Flask (文末有源码)
- MacMaster:一款功能强大的高级网络接口管理与监控工具