SQL Server 数据类型
一、文本类型(字母、符号或数字字符的组合)
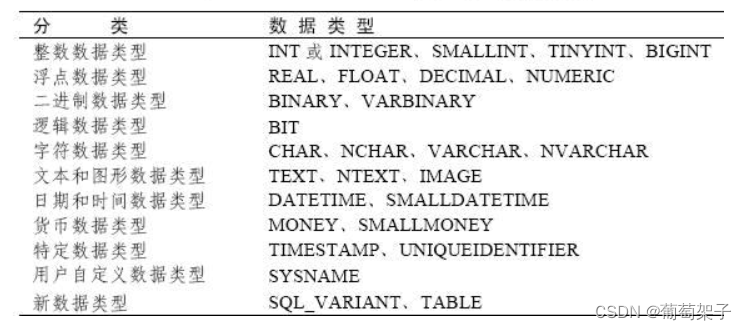
在SQL Server中,用来存储文本数据的数据类型主要有以下几种:
首先注意两点:
//
(1).Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案,是一个国际标准,用于计算机系统中文本的表示和处理。
以下是关于Unicode的一些关键点:
-
编码范围:
Unicode为每一个字符和符号从U+0000到U+10FFFF的范围内分配了一个唯一的代码点(Code Point)。 -
通用性:
Unicode设计的初衷是能够表示全世界所有的书写系统,包括现代文字、历史文字、技术符号、表情符号等。 -
编码方案:
Unicode定义了几种不同的编码方案来存储这些代码点,例如UTF-8、UTF-16和UTF-32。UTF-8是一种变长编码,它可以使用1到4个字节来表示一个字符,适用于网络传输和文本文件存储。UTF-16和UTF-32分别使用2个或4个字节来固定长度表示字符。 -
与ASCII兼容:
Unicode在设计时考虑到了与ASCII编码的兼容性。例如,Unicode中前128个字符的编码与ASCII完全一致。 -
跨平台:
Unicode被广泛支持和使用在各种操作系统、程序语言和应用中,使得跨语言、跨平台的文本处理变得可能。
使用Unicode数据类型可以确保数据库可以存储多种语言的字符,无论是拉丁字母、西里尔字母、汉字、日文假名、韩文字符还是其他任何复杂的文字系统。这对于国际化应用程序尤其重要。
(2):带n的数据类型长度是不带n的两倍。
//
-
char和nchar:char:固定长度的非Unicode字符数据,最多可以存储8000个字符。nchar:固定长度的Unicode字符数据,最多可以存储4000个字符。
-
varchar和nvarchar:varchar:可变长度的非Unicode字符数据,最多可以存储8000个字符。nvarchar:可变长度的Unicode字符数据,最多可以存储4000个字符。
-
text和ntext:text:非Unicode数据,最多可以存储2^31-1 (2,147,483,647)个字符。ntext:Unicode数据,最多可以存储1,073,741,823个字符。这些类型现在被视为遗留的,在最新版本的SQL Server中,官方建议使用VARCHAR(MAX)和NVARCHAR(MAX)代替。
-
varchar(MAX)和nvarchar(MAX):varchar(MAX):可变长度的非Unicode数据,最多可以存储2^31-1个字节。nvarchar(MAX):可变长度的Unicode数据,最多可以存储2^31-1个字节。
需要注意的是:
CHAR和NCHAR存储固定长度的数据,当存储的文本短于指定长度时,会用空格填充至固定长度。VARCHAR和NVARCHAR存储可变长度的数据,只占用实际文本长度所需的空间。它们更加灵活,适用于文本长度不确定的场景。- 使用
NVARCHAR和NCHAR类型可以存储Unicode字符,适合多语言环境,但是它们占用的存储空间是VARCHAR和CHAR的两倍。 TEXT和NTEXT类型在新版SQL Server中已被弃用,不建议使用。应使用VARCHAR(MAX)和NVARCHAR(MAX)代替,因为这些大型值数据类型提供了更好的性能和更多的功能。VARCHAR(MAX)和NVARCHAR(MAX)允许你存储大量数据,但要注意它们可能会影响性能,特别是在执行大量文本操作时。- 使用大型值数据类型时,如果可能,考虑使用文本/字符串数据存储和检索技术,例如全文索引。
二、整数类型
在SQL Server中,用于存储整数的数据类型包括以下几种:
-
tinyint:- 存储范围:0 到 255
- 存储大小:1 字节
-
smallint:- 存储范围:-32,768 到 32,767
- 存储大小:2 字节
-
int:- 存储范围:-2,147,483,648 到 2,147,483,647
- 存储大小:4 字节
-
bigint:- 存储范围:-9,223,372,036,854,775,808 到 9,223,372,036,854,775,807
- 存储大小:8 字节
在选择适合的整数类型时,需要注意以下几点:
-
存储要求:选择一个与我们期望存储值的范围相匹配的数据类型,可以节省存储空间。例如,当我们知道一个列永远不会超过255,那么使用
tinyint会比使用INT更节省空间。 -
性能:一般来说,较小的数据类型(如
tintint和smallint)可以提供更好的性能,因为它们使用的内存更少,索引也更紧凑。 -
溢出:要小心确保所选的数据类型不会因为值太大而溢出。一旦发生溢出,可能会得到错误或不正确的结果。
-
自动增长:如果在设计如主键列时使用自动增长(IDENTITY)属性,确保数据类型足够大,以防在长时间运行后达到最大值。
-
应用兼容性:有时客户端应用程序的数据类型可能会限制在SQL Server中使用的数据类型。确保选择的数据类型与客户端应用程序兼容。
-
标准化:在进行数据库设计时,应考虑数据的标准化形式。相同的数据类型可以使得后期数据维护、比较和索引更加高效。
三、精确数字类型
在SQL Server中,精确数字类型指的是能够存储精确数值的数据类型,通常用于需要精确计算的财务和数学运算。以下是SQL Server中的精确数字类型:
-
bit:- 存储范围:0 或 1
- 存储大小:1、2、4、8字节,取决于列中的比特数(1-8、9-16、17-32、33-64)
-
decimal和numeric(这两种类型在SQL Server中是同义的):- 存储范围:-10^38 +1 到 10^38 -1
- 存储大小:5-17 字节,取决于指定的精度(总位数)
- 可以指定小数点左侧和右侧的精度,即精度(数字总位数)和小数位数(小数点后的位数)。
-
money和smallmoney:money:-922,337,203,685,477.5808 到 922,337,203,685,477.5807,存储大小为 8 字节smallmoney:-214,748.3648 到 214,748.3647,存储大小为 4 字节
要注意:
-
选择合适的大小:根据需要存储的数据的大小和精度选择合适的数据类型。例如,如果不需要很大或很精确的数值,使用
INT或SMALLINT可能比BIGINT或DECIMAL更合适。 -
注意
DECIMAL和NUMERIC的精度和小数位数:DECIMAL和NUMERIC数据类型允许指定精度和小数位数,这对于保持数值计算的准确性非常重要。选择合适的精度可以确保数据的准确性,同时避免不必要的存储浪费。 -
MONEY和SMALLMONEY类型特别适用于存储货币值,但它们的计算精度可能不如DECIMAL和NUMERIC。当涉及到非常精确的财务计算时,通常建议使用DECIMAL或NUMERIC。 -
考虑性能:更大的数据类型(如
BIGINT和DECIMAL)可能会导致性能略微下降,因为它们需要更多的存储空间和计算资源。在不牺牲必要精度的情况下,选择最小的数据类型可以提高性能。
四、近似数字(浮点)类型
在SQL Server中,近似数字(浮点)类型主要是指能够存储近似数值的数据类型,用于科学计数和那些不要求精确小数值的情况。SQL Server提供了两种浮点数据类型:
-
float[(n)]:- 存储范围:由-1.79E+308到-2.23E-308,0以及从2.23E-308到1.79E+308。
- 存储大小:4或8字节,具体取决于n的值。如果n的值是24到53,存储大小是8字节。如果n的值是1到23,存储大小是4字节。
-
real:- 存储范围:由-3.40E+38到-1.18E-38,0以及从1.18E-38到3.40E+38。
- 存储大小:4字节。
在使用这些近似数字类型时,需要注意以下几点:
-
存储大小和精度:
float类型可以指定精度n(有效位数)。如果指定了1到24之间的n值,将使用4字节存储(REAL类型相似)。如果指定了25到53之间的n值,将使用8字节存储。不指定n时,默认为53(即float(53))。 -
舍入错误:由于舍入错误,
float和real类型可能无法精确表示非常大或非常小的数值。在比较这些类型的值时,可能需要使用一定的容差。 -
性能:浮点运算通常比整数运算慢,但
float和real类型可以存储极宽的数值范围,对于某些应用而言这是必要的(如科学计算)。 -
运算结果:浮点数的数学运算可能会产生不稳定的结果,因此在执行数学运算时,结果可能会略有不同,这是由于二进制浮点数在内部是如何表示和计算的。
-
数据转换:将
float或real类型转换成整数类型时,SQL Server会将数值四舍五入到最近的整数。 -
移植性:由于不同的系统可能会使用不同的方法来实现浮点数的舍入,所以在不同的系统之间迁移数据时,涉及到
FLOAT和REAL类型的数据可能会导致不一致。
五、日期类型
在SQL Server中,日期和时间数据类型用于存储日期和时间值。以下是SQL Server中的日期和时间数据类型:
-
data:- 存储范围:0001-01-01 到 9999-12-31
- 存储大小:3字节
- 仅包含日期部分,没有时间部分。
-
time:- 存储范围:00:00:00.0000000 到 23:59:59.9999999
- 存储大小:3到5字节,具体取决于秒的精度。
- 仅包含时间部分,没有日期部分。
-
datatime:- 存储范围:1753-01-01 到 9999-12-31
- 存储大小:8字节
- 包括日期和时间,精度为3.33毫秒。
-
smalldatatime:- 存储范围:1900-01-01 到 2079-06-06
- 存储大小:4字节
- 包括日期和时间,精度为1分钟。
-
datatime2:- 存储范围:0001-01-01 到 9999-12-31
- 存储大小:6到8字节,具体取决于秒的精度。
- 与
DATETIME类似,但更大的日期范围和可定制的精度。
-
datatimeoffset:- 存储范围:0001-01-01 到 9999-12-31
- 存储大小:8到10字节,具体取决于秒的精度。
- 包括日期和时间,以及相对于UTC的时区偏移。
在使用这些日期和时间类型时,需要注意以下几点:
-
时区:如果需要考虑时区信息,使用
DATETIMEOFFSET可以存储时区偏移量。 -
默认值:当没有提供时间部分时,
TIME的默认值为00:00:00。对于日期部分,默认值是1900-01-01。
六、货币类型
在SQL Server中,专门用于存储货币值的数据类型主要有两种:
-
money:- 存储范围:-922,337,203,685,477.5808 到 922,337,203,685,477.5807
- 存储大小:8 字节
- 精度:小数点后四位
-
smallmoney:- 存储范围:-214,748.3648 到 214,748.3647
- 存储大小:4 字节
- 精度:小数点后四位
使用这些货币类型时,以下是一些需要注意的事项:
-
精度要求:
money和smallmoney数据类型提供固定的四位小数精度。如果你的应用需要不同的精度或者超出这些范围的值,可能需要使用decimal或numeric类型。 -
性能:
money和smallmoney类型被优化用于货币计算,可能提供比decimal更好的性能。但是,如果需要超过四位小数的精度,还是应该使用decimal。 -
计算和舍入:在涉及货币的计算时,需要考虑舍入规则。SQL Server在进行货币类型数据的四舍五入时是自动进行的,但是如果需要更特殊的舍入逻辑,可能需要自定义。
-
存储大小:
money类型比decimal和numeric类型使用更少的存储空间,但是decimal和numeric可以提供更大的范围和精度。 -
格式化:在将货币类型的数据展现给用户时,通常需要根据用户的区域设置进行适当的格式化。这通常在应用程序层面处理,而不是在数据库层面。
七、位类型
在SQL Server中,用于存储位(Boolean)值的数据类型是 BIT 类型。BIT 类型用于存储布尔值,通常用于表示简单的是/否或真/假状态。
- 存储大小:
bit数据类型的存储大小实际上非常小。每个bit列只占用一位,但是最小的存储单位是字节。因此,一个bit列可以存储在一个字节中,而8个bit列只需1个字节存储。 - 可用范围:
bit类型的值可以是 0、1 或 NULL(如果列允许 NULL 值)。 - 默认值:在没有指定默认值的情况下,
bit类型的列的默认值是 0。
使用 BIT 类型时需要注意的事项:
-
存储效率:当表中有多个
bit列时,SQL Server会尽量将它们存储在同一个字节中以节省空间。最多可以有8个bit列存储在一个字节中。 -
值的解释:尽管
bit数据类型表示布尔值,但在SQL Server中,它实际上是表示整数值0或1。这意味着在执行逻辑运算时,它们可能被转换为整数。 -
转换:当
bit类型与其他数据类型一起使用时,可能会发生隐式或显式转换,这可能会影响性能。 -
NULL 值:如果
bit列被定义为允许 NULL 值,那么除了0和1以外,它还可以包含一个 NULL 值。在逻辑表达式中使用含有 NULL 的bit列需要特别小心,因为 NULL 与任何非 NULL 值的比较都将返回 NULL。 -
默认绑定:在定义表结构时,如果想要
bit列有一个非0的默认值,需要显式地设置一个默认约束,如DEFAULT 1。 -
逻辑操作:
BIT列可以参与逻辑操作,如and、or和not。当用于逻辑操作时,0 表示false,1 表示ture。
八、二进制类型
在SQL Server中,用于存储二进制数据的数据类型主要有以下几种:
-
binary:- 固定长度的二进制数据。
- 存储大小是定义的列长度。
- 长度范围是 1 到 8,000 字节。
-
varbinary:- 可变长度的二进制数据。
- 存储大小是实际数据的长度加上2字节,用于表示长度,但最大不超过定义的长度。
- 长度范围是 1 到 8,000 字节。
-
varbinary(MAX):- 可变长度的二进制数据。
- 存储大小最大可以是 2^31-1 字节。
- 用于存储超过 8,000 字节的大型数据对象,如文件、图像等。
使用这些二进制数据类型时,需要注意以下事项:
-
选择适当类型:当我们知道列将具有固定长度的二进制数据时,使用
binary类型可能会更合适。如果列中的数据项的大小可能会有所不同,那么varbinary或varbinary(MAX)类型可能会更加适用。 -
性能:大型二进制数据可能会影响性能,特别是在涉及到大量数据的检索和更新操作时。
-
存储空间:固定长度的
binary类型可能会浪费存储空间,因为它总是使用定义的最大长度存储数据。相比之下,varbinary类型只存储实际需要的空间加上长度的额外2字节。 -
最大长度限制:对于
binary和varbinary数据类型,当数据超过 8,000 字节时,应该使用varbinary(MAX)类型。 -
数据操作:操作二进制数据通常比操作文本数据更复杂,因为我们需要使用适当的函数和方法来处理它们。
-
使用场景:二进制数据类型通常用于存储图像、文件、音频、视频等非文本数据。
-
备份和迁移:含有大量二进制数据的数据库在备份和迁移时一般需要更多的时间和资源。
-
安全性:存储敏感数据(如加密的字节)时需要考虑安全性和加密策略。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!