使用bs4 分析html文件
发布时间:2023年12月20日
首先需要 pip install beautifulsoup4安装
然后为了方便学习此插件,随便打开一个网页,然后鼠标右键,打开源网页,如下图片
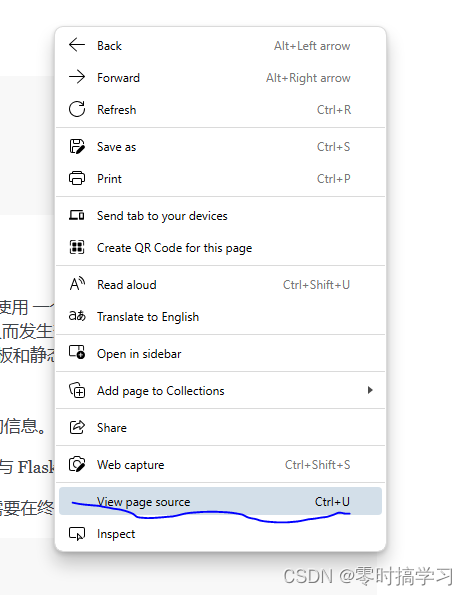
这样就可以获得一个网页源码,全选复制粘贴到本地,存储为 .html
文件,后续的学习以此html文件为模版进行
from bs4 import BeautifulSoup
import os
# html文件放置的路径和名字
filePath = os.path.join(os.getcwd(), "HTML", "1.html")
print(filePath)
# 打开html文件,注意encoding格式
with open(filePath, "r", encoding="UTF-8") as f:
html_content = f.read()
# 把这个html进行解析
soup = BeautifulSoup(html_content, 'html.parser')
# 这里是抓第一个 <h1>标签的文本内容
h1_content = soup.find('h1').get_text()
# 这里是抓第一个<p> 标签的文本内容
p_content = soup.find('p').get_text()
print('h1 content:', h1_content)
print('p content:', p_content)
print("--------------------------")
# 这里是抓取所有<p> 标签
p_content_all = soup.find_all('p')
# 利用for 循环进行逐条解析,获取文本内容
for p_content in p_content_all:
print(p_content.get_text())
如,html文件中含结构
<div class="title_box pd10">
<h1>六年前的今天:湖人退役科比的8号和24号球衣</h1>
<div class="info_box">
<span class="time">2023-12-19</span>
<span class="source">直播吧</span>
</div>
</div>
我使用如下命令:
# 使用此命令获取 <h1>标签的文本内容
soup.find('h1').get_text()
# 结果:
六年前的今天:湖人退役科比的8号和24号球衣
soup.find('span', class_='time')
# 结果
2023-12-19
例二:
html内容含结构如下:
<div class="disZoom bq_bar">
<div class="disZoom bar_info">
<span class="biaoqian">
<a href="/?cateid=1005" class="tags">体育</a>
</span>
<span class="laiyuan">来源:阿希啥都聊</span>
</div>
</div>
使用命令:
# 抓取html中出现的第一个以下结构内的内容
soup.find('a', herf="/?cateid=1005")
# 结果是:
体育
类似的结构还有:
</span>
<p class="tit">早报:华为nova 12价格全曝光 蔚来获22亿美元融资</p>
</a>
soup.find('p', class_="tit")
基本上你想要抓取的内容都可以按照格式进行解析获取,是非常方便的
先行记录:
在之后自己构建网页后,自主进行管理,获取,导出网页内容应该都是非常有帮助的,避免反复使用re工具自己分析,太过于繁琐,结合 requests 库等,可以更加高效进行网页访问及内容获取。
文章来源:https://blog.csdn.net/weixin_44517278/article/details/135087350
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于“Python”的核心知识点整理大全60
- Datawhale 大模型基础理论 Day1 引言
- 苹果iPhone手机微信怎么分身,如何设置微信双开方法!
- oj 1.8编程基础之多维数组 22:神奇的幻方
- oracle19c容器数据库rman备份特性-----性能优化(三)
- 税法相关的基础知识
- Conda python运行的包和环境管理 入门
- QT基础应用:QT设置开机自启动(Linux&windows)
- Gooxi受邀出席操作系统与AI技术应用实践沙龙·OC城市行·深圳站活动
- 【Python机器学习】基于SVD建立商品推荐系统