翻译: LLM构建 GitHub 提交记录的聊天机器人一 使用 Timescale Vector、pgvector 和 LlamaIndex
1. 检索增强生成 (RAG Retrieval Augmented Generation)
检索增强生成 (RAG Retrieval Augmented Generation) 对于增强应用程序开发中的大型语言模型 (LLM) 至关重要。它用外部数据源补充 LLM,通过减少错误或幻觉来帮助获得更相关的响应。RAG 通过语义搜索确定哪些信息与用户的查询相关,语义搜索按含义搜索数据(而不仅仅是查找搜索词的文字匹配项)。RAG 对于需要访问特定领域或专有数据的 LLM 应用程序特别有效。
然而,仅靠 RAG 并不总是足以构建强大的、上下文感知的 LLM 应用程序。使用时间感知检索time-aware retrieval来增强 RAG,在特定时间和日期范围内查找语义相关的向量,可以显着提高其有效性。
2. 不使用和使用时间感知检索time-aware retrieval得区别
在处理日期繁重的知识库时,时间感知 RAG 可以帮助您构建 LLM 应用程序,这些应用程序擅长为用户查询生成相关答案。
在此示例中,了解时间感知检索如何提高 LLM 响应的质量:
Alice 是一名开发人员,她想要了解对 GitHub 存储库(在本例中为 TimescaleDB 存储库)的特定更改。她没有手动检查代码或提交历史记录,而是找到了一个“与我的 GitHub 存储库聊天”应用程序,并使用它来加快她的研究速度。Alice 想要了解名为“连续聚合”的功能的最新更改,并于 2023 年 11 月 29 日提出以下问题:
What’s new with the continuous aggregates feature in the past 6 months?
2.1 没有时间感知 RAG 👎 的 LLM 响应
名为“连续聚合continuous aggregates”的功能发生了一些变化。最近的更改是由 Sven Klemm 于 2020 年 1 月 24 日进行的。此更改添加了一种称为实时聚合的新模式,该模式将具体化数据与上次刷新后接收的新数据相结合。此新模式现在是新创建的连续聚合的默认行为。要将现有连续聚合升级到新行为,需要运行特定命令。
2.2 具有时间感知 RAG ? 的 LLM 响应
在过去的 6 个月中,对名为连续聚合continuous aggregates的功能进行了两项更改。第一次更改是在 2023 年 8 月 7 日由 Fabrízio de Royes Mello 进行的。此更改放宽了刷新连续聚合时的强表锁定,从而允许在多个会话中以更少的锁执行刷新过程。第二个更改是在 2023 年 8 月 29 日由 Jan Nidzwetzki 进行的。此更改通过向 post.continuous_aggs.v3.sql 中的两个查询添加 ORDER BY 规范,使上/降级测试具有确定性。
使用时间感知 RAG 的响应更有用——它在 Alice 指定的时间段内,并且与主题相关。两个响应之间的区别在于检索步骤。
3 教程:构建有关 GitHub 提交历史记录的聊天机器人
现在轮到你了!在本文的其余部分,我们将介绍构建 TSV Time Machine 的过程:一个时间感知的 RAG 聊天机器人,使您能够回到过去并与任何 GitHub 存储库的提交历史记录聊天。
每个 Git 提交都有一个关联的时间戳、自然语言消息和其他元数据,这意味着需要语义搜索和基于时间的搜索来回答有关提交历史记录的问题。
👩?💻👩?💻想直接跳进去吗?查看应用程序和github代码。

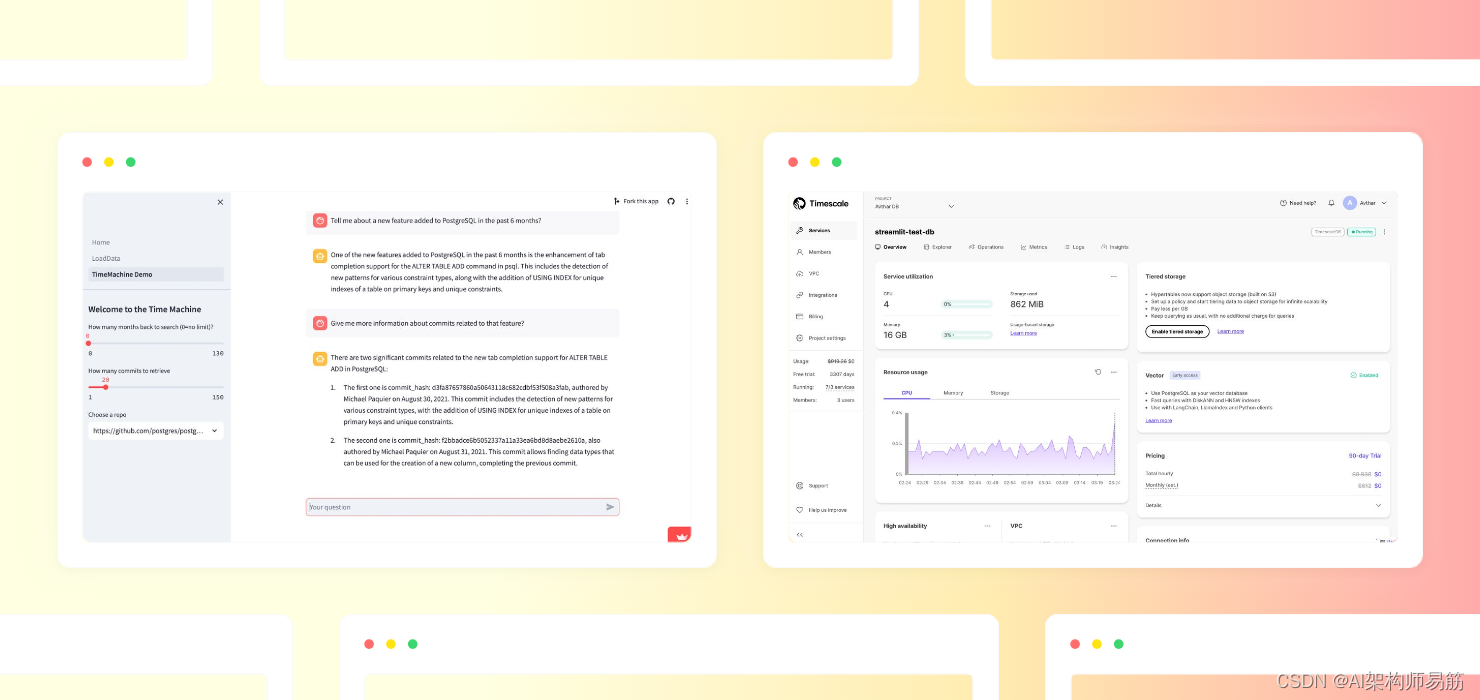
TSV Time Machine 应用的屏幕截图,显示用户与 PostgreSQL 项目 GitHub 提交历史记录聊天。
4. TSV Time Machine 应用程序概述
为了给增强 TSV Time Machine ,我们使用以下方法:
- LlamaIndex 是一个强大的 LLM 数据框架,用于 RAG 应用程序。LlamaIndex 引入、处理和检索数据。我们将使用 LlamaIndex 自动检索器来推断要在矢量数据库上运行的正确查询,包括查询字符串和元数据筛选器。
- Timescale Vector 是我们的矢量数据库。Timescale Vector 针对相似性和基于时间的搜索进行了优化,使其成为支持时间感知 RAG 的理想选择。它通过自动表分区来隔离特定时间范围的数据来实现这一点。我们将通过 LlamaIndex 的 Timescale Vector Store 访问它。
TSV Time Machine 示例应用有三个页面:
- Home主页:提供应用程序使用说明的应用程序主页。
- Load Data加载数据:页面以加载所选存储库的 Git 提交历史记录。
- Time Machine Demo:与加载的任何 GitHub 存储库聊天的界面。
由于该应用程序是 ~600 行代码,我们不会逐行解压(尽管您可以要求 ChatGPT 向您解释任何棘手的部分!让我们看一下其中涉及的关键代码片段:
- 从要与之聊天的 GitHub 存储库加载数据
- 通过时间感知检索time-aware retrieval augmented generation增强聊天效果
参考
https://blog.streamlit.io/using-time-based-rag-llm-apps-with-timescale-vector/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 谷歌浏览器安装插件提示无法从该网站添加怎么办?
- Debian在升级过程中报错
- 猫头虎分享已解决Bug || Go Error: cannot use str (type string) as type int in assignment
- docker离线安装redis
- 二叉树与堆的深度解析:数据结构中的关键概念及应用
- 专访李虹佳丨弯道超车,从员工成为合作商
- 从人工管理的繁琐到高效,体验固定资产管理系统带来的转变
- python小项目:学生管理系统(可以让你满分的期末设计作业)
- 2023:生成式AI与存储最新发展和趋势分析(下)
- 【前后端的那些事】解放前端!10min快速上手人人代码生成器(前端篇)