IO流(二)
发布时间:2023年12月19日
目录
一.文件拷贝
1.小文件拷贝
//输入流就是原文件
FileInputStream fis=new FileInputStream("a.txt");
//输出流就是目的地
FileOutputStream fos=new FileOutputStream("b.txt");
int b;
while((b=fis.read())!=-1){
fos.write(b);
}
//先打开的流后关闭
fos.close();
fis.close();2.FileInputStream的读取问题
如果文件过大,速度就会很慢,因为一次只拷贝一个字节.
FileInputStream fis=new FileInputStream("a.txt");
//创建数组
byte [] bytes=new byte[1024*1024*5];
//一般数组一次读取的是1024的整数倍,这里面就是5兆的数据
FileOutputStream fos=new FileOutputStream("b.txt");
int b;
while((b=fis.read(bytes))!=-1){
fos.write(bytes,0,b);
//一次写入数组大小的数据,从0开始,长度是b个
}
fis.close();
fos.close();注意:数组一次又一次的读取,里面的字节数据是被覆盖的
二.捕获异常
FileInputStream fis=null;
FileOutputStream fos=null;
//需要初始化
try {
fis=new FileInputStream("a.txt");
//创建数组
byte [] bytes=new byte[1024*1024*5];
//一般数组一次读取的是1024的整数倍,这里面就是5兆的数据
fos=new FileOutputStream("b.txt");
int b;
while((b=fis.read(bytes))!=-1){
fos.write(bytes,0,b);
//一次写入数组大小的数据,从0开始,长度是b个
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
//finally永远会运行,除非JVM停止
try {
fis.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
try {
fos.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}三.字符集
在计算的存储中,任意数据都是用二进制的形式存储的(0.1)
一个0或者一个1就叫做一个bit? 也叫做比特位
八个bit作为一组 存储256个数据 叫做一个字节
计算机存储英文只需要一个字节
1.GBK
英文存储(单字节)

中文存储(双字节)
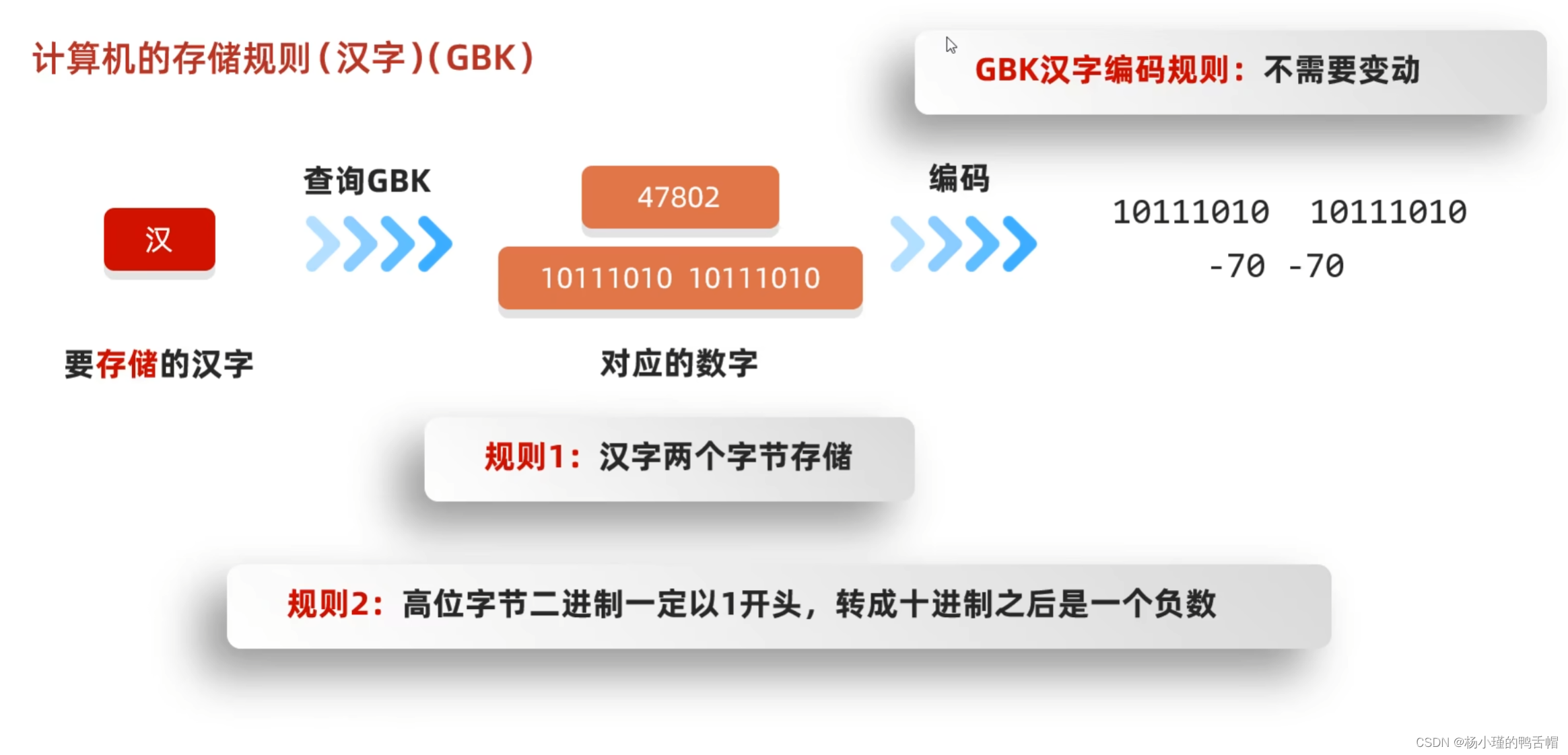
规则二的目的就是为了和英文进行区分
只要是以1开头的就是中文
2.Unicode
统一码 可以让世界绝对大多数国家使用 都会兼容ASCII


UTF-8是一种编码方式
3.乱码
原因
1.读取数据未读完整个汉字
2.编码和解码的方式不统一
正确

错误

规避乱码的方式
1.不要用字节流去读取文件
2.编码和解码使用同一个编码方式
四.字符流
字符流的底层就是字节流
字符流=字节流+字符集
特点
输入流:一次读取一个字节,遇到中文时,一次读取多个字节
输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中
使用场景
对纯文本文件进行续写操作

FileReader
1.创建字符输入流的对象
2.读取数据
3.释放资源
无参
//创建对象,并关联本地文件
FileReader fr=new FileReader("a.txt");
//读取数据read()
//字符流的底层也是字节流,默认也是一个字节一个字节的读取的
//如果遇到中文就会一次读取多个,GBK一次读两个字节,UTF-8一次读取三个字节
int ch;
while((ch=fr.read())!=-1){
System.out.println((char)ch);
}
//释放资源
fr.close();有参
char[] chars=new char[2];
int len;
while ((len=fr.read(chars))!=-1){
//把数组的数据变成字符串打印
System.out.println(new String(chars,0,len));
}
//3.释放资源
fr.close();FileWriter
1.创建字符输出流
参数是字符串或者file对象都可以
如果文件不存在就会创建,但是要保证父类文件是存在的
如果文件已经存在,构造方法就会清空文件
2.写入数据
如果write方法参数是整数,但是实际上写到本地文件中的是整数在字符集上对应的字符
3.释放资源
每次使用完流都要释放资源
文章来源:https://blog.csdn.net/Ineedmame/article/details/134979437
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 挂耳式耳机哪个好、百元价位挂耳式耳机推荐
- 如何在 Python3 中使用变量
- 怎么自学Python?没有编程基础需要注意什么?
- 178. 第K短路(A*启发式算法)
- 202349读书笔记|《陈年喜的诗》——杏花岁岁结出青杏 岁月是永恒的 善变的是人类的命运
- 软件测试卷王的自述,我难道真的很卷?
- anaconda创建虚拟环境启动jupyter notebook
- Hive06_基础查询
- Educational Codeforces Round 161 (Rated for Div. 2) | JorbanS
- FreeRTOS学习第7篇--周期性延迟和相对性延迟函数