使用残差网络识别手写数字及MNIST 数据集介绍
MNIST 数据集已经是一个几乎每个初学者都会接触的数据集, 很多实验、很多模型都会以MNIST 数据集作为训练对象, 不过有些人可能对它还不是很了解, 那么今天我们一起来学习一下MNIST 数据集。
1.MNIST 介绍
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
MNIST 数据集包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
Size: 28×28 灰度手写数字图像
Num: 训练集 60000 和 测试集 10000,一共70000张图片
Classes: 0,1,2,3,4,5,6,7,8,9
2.数据集读取
2.1官网下载MNIST 数据集
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取
注意:不要直接点连接,复制连接粘贴到新的浏览器标签页搜索,就不需要账号密码了!!!
2.2 博主分享
同时:博主已将MNIST公开数据集上传至百度网盘,大家可以直接下载学习:
链接: https://pan.baidu.com/s/1-rurbkWdv_veQD8QcQWcRw 提取码: 0213
2.3 直接下载
如果数据集没有下载,修改参数:download=True,直接去下载数据集:
from torchvision import datasets, transforms
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=transforms.ToTensor(),
download=True)
print(train_data)
print(test_data)
如果出现这种错误:
SyntaxError: Non-UTF-8 code starting with \xca in fileD:\PycharmProjects\model-fuxian\data set\MNIST t.py on line 2, but noencoding declared; see http://python.org/dev/peps/pep-0263/ fordetails
大概率是你没加:# coding:gbk,为什么呢?由于 Python 默认使用 ASCII 编码来解析源代码,因此如果源文件中包含了非 ASCII 编码的字符(比如中文字符),那么解释器就可能会抛出 SyntaxError 异常。加上# -- coding: gbk --这样的注释语句可以告诉解释器当前源文件的字符编码格式是 GBK,从而避免源文件中文字符被错误地解析。
如果成功运行会出现这种结果,表示已经开始下载了:
输出结果:
Dataset MNIST
Number of datapoints: 60000
Root location: ./MNIST
Split: Train
StandardTransform
Transform: ToTensor()
Dataset MNIST
Number of datapoints: 10000
Root location: ./MNIST
Split: Test
StandardTransform
Transform: ToTensor()
3.数据集可视化
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
train_data = datasets.MNIST(root="model-fuxian/data set/MNIST/MNIST/raw/MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
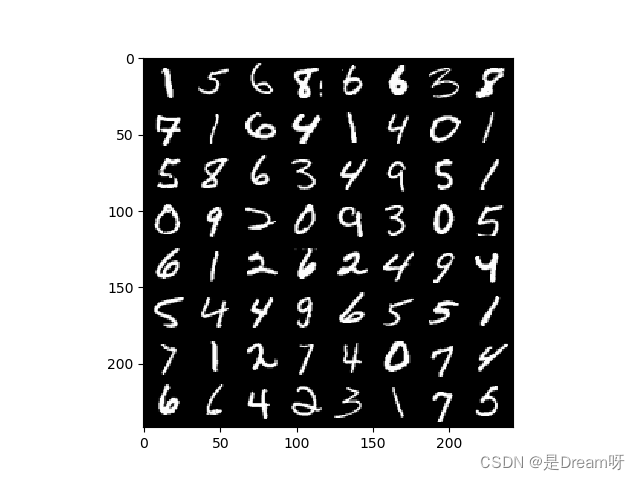
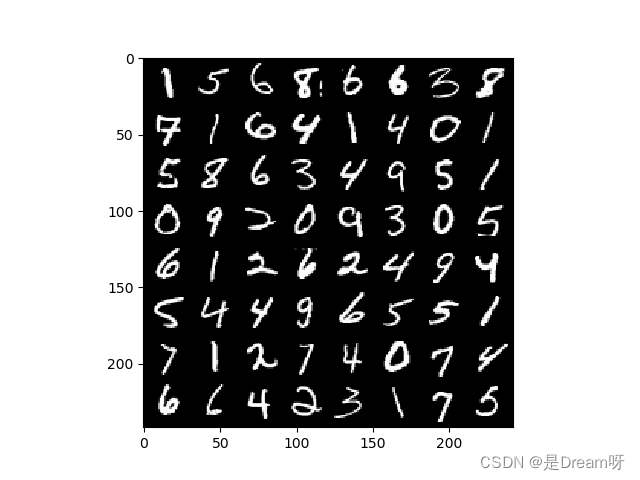
for num, (image, label) in enumerate(train_loader):
image_batch = torchvision.utils.make_grid(image, padding=2)
plt.imshow(np.transpose(image_batch.numpy(), (1, 2, 0)), vmin=0, vmax=255)
plt.show()
print(label)
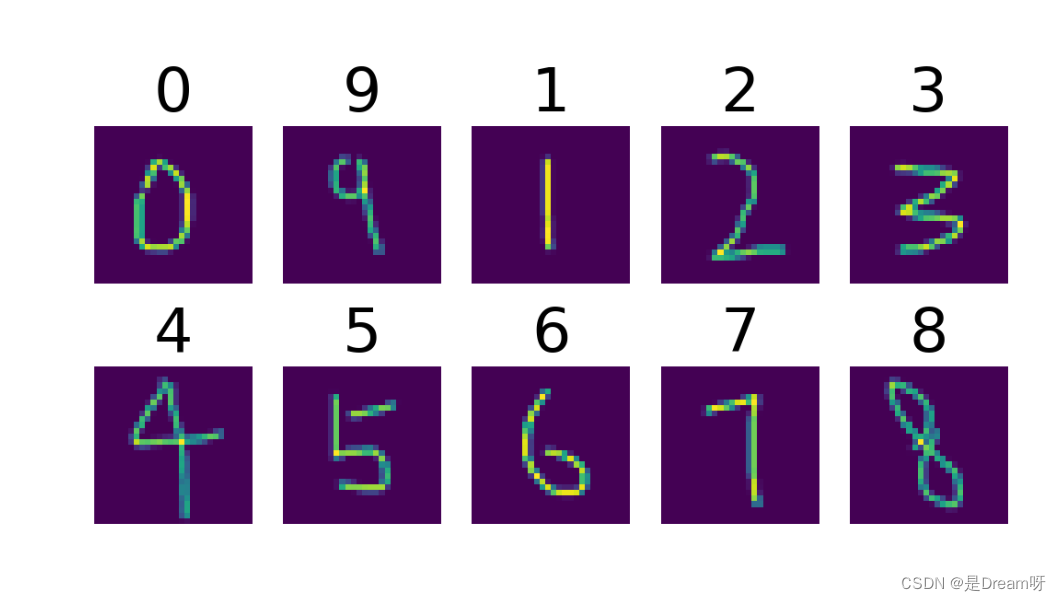
得到图片:


这是标签:
tensor([2, 1, 7, 7, 2, 4, 2, 2, 0, 1, 7, 1, 5, 7, 9, 0, 2, 7, 4, 7, 0, 2, 7, 1,
6, 9, 1, 1, 1, 5, 4, 3, 8, 0, 1, 0, 1, 3, 8, 0, 1, 4, 5, 1, 8, 4, 7, 3,
8, 3, 2, 2, 0, 0, 4, 0, 2, 9, 7, 1, 8, 3, 2, 3])
tensor([6, 6, 7, 2, 5, 4, 0, 3, 4, 6, 1, 4, 1, 9, 2, 2, 8, 7, 5, 7, 9, 6, 6, 7,
1, 9, 9, 5, 5, 6, 9, 6, 8, 5, 5, 7, 8, 9, 8, 3, 1, 0, 1, 4, 6, 1, 8, 6,
1, 4, 6, 7, 1, 9, 5, 4, 3, 4, 6, 1, 7, 3, 7, 6])
tensor([7, 1, 5, 1, 4, 0, 9, 2, 2, 0, 1, 5, 2, 3, 6, 4, 6, 9, 3, 3, 2, 8, 1, 5,
8, 0, 1, 4, 5, 6, 2, 6, 4, 9, 2, 0, 7, 2, 0, 1, 2, 4, 4, 6, 5, 9, 1, 2,
5, 3, 3, 8, 8, 3, 4, 5, 2, 6, 0, 0, 8, 7, 1, 7])
4.使用残差网络RESNET识别手写数字
没有GPU的可以使用CPU,不过速度会大打折扣:DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu"),最好是可以使用GPU,这样速度会快很多: torch.device("cuda")#使用GPU
# coding=gbk
# 1.加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
import argparse
# 2.超参数
BATCH_SIZE = 32#每批处理的数据 一次性多少个
DEVICE = torch.device("cuda")#使用GPU
# DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")#使用GPU
EPOCHS =4 #训练数据集的轮次
# 3.图像处理
pipeline = transforms.Compose([transforms.ToTensor(), #将图片转换为Tensor
])
# 4.下载,加载数据
from torch.utils.data import DataLoader
#下载
train_set = datasets.MNIST("data",train=True,download=True,transform=pipeline)
test_set = datasets.MNIST("data",train=False,download=True,transform=pipeline)
#加载 一次性加载BATCH_SIZE个打乱顺序的数据
train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True)
test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True)
# 5.构建网络模型
class ResBlk(nn.Module): # 定义Resnet Block模块
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1): # 进入网络前先得知道传入层数和传出层数的设定
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__() # 初始化
# we add stride support for resbok, which is distinct from tutorials.
# 根据resnet网络结构构建2个(block)块结构 第一层卷积 卷积核大小3*3,步长为1,边缘加1
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 将第一层卷积处理的信息通过BatchNorm2d
self.bn1 = nn.BatchNorm2d(ch_out)
# 第二块卷积接收第一块的输出,操作一样
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
# 确保输入维度等于输出维度
self.extra = nn.Sequential() # 先建一个空的extra
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x): # 定义局部向前传播函数
out = F.relu(self.bn1(self.conv1(x))) # 对第一块卷积后的数据再经过relu操作
out = self.bn2(self.conv2(out)) # 第二块卷积后的数据输出
out = self.extra(x) + out # 将x传入extra经过2块(block)输出后与原始值进行相加
out = F.relu(out) # 调用relu
return out
class ResNet18(nn.Module): # 构建resnet18层
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential( # 首先定义一个卷积层
nn.Conv2d(1, 32, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(32)
)
# followed 4 blocks 调用4次resnet网络结构,输出都是输入的2倍
self.blk1 = ResBlk(32, 64, stride=1)
self.blk2 = ResBlk(64, 128, stride=1)
self.blk3 = ResBlk(128, 256, stride=1)
self.blk4 = ResBlk(256, 256, stride=1)
self.outlayer = nn.Linear(256 * 1 * 1, 10) # 最后是全连接层
def forward(self, x): # 定义整个向前传播
x = F.relu(self.conv1(x)) # 先经过第一层卷积
x = self.blk1(x) # 然后通过4次resnet网络结构
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1) # 平铺一维值
x = self.outlayer(x) # 全连接层
return x
# 6.定义优化器
model = ResNet18().to(DEVICE)#创建模型并将模型加载到指定设备上
optimizer = optim.Adam(model.parameters(),lr=0.001)#优化函数
criterion = nn.CrossEntropyLoss()
# 7.训练
def train_model(model,device,train_loader,optimizer,epoch):
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
model.train()#模型训练
for batch_index,(data ,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device)#部署到DEVICE上去
optimizer.zero_grad()#梯度初始化为0
output = model(data)#训练后的结果
loss = criterion(output,target)#多分类计算损失
loss.backward()#反向传播 得到参数的梯度值
optimizer.step()#参数优化
if batch_index % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_index * len(data), len(train_loader.dataset),
100. * batch_index / len(train_loader), loss.item()))
if args.dry_run:
break
# 8.测试
def test_model(model,device,text_loader):
model.eval()#模型验证
correct = 0.0#正确率
global Accuracy
text_loss = 0.0
with torch.no_grad():#不会计算梯度,也不会进行反向传播
for data,target in text_loader:
data,target = data.to(device),target.to(device)#部署到device上
output = model(data)#处理后的结果
text_loss += criterion(output,target).item()#计算测试损失
pred = output.argmax(dim=1)#找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()#累计正确的值
text_loss /= len(test_loader.dataset)#损失和/加载的数据集的总数
Accuracy = 100.0*correct / len(text_loader.dataset)
print("Test__Average loss: {:4f},Accuracy: {:.3f}\n".format(text_loss,Accuracy))
# 9.调用
for epoch in range(1,EPOCHS+1):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)
torch.save(model.state_dict(),'model.ckpt')
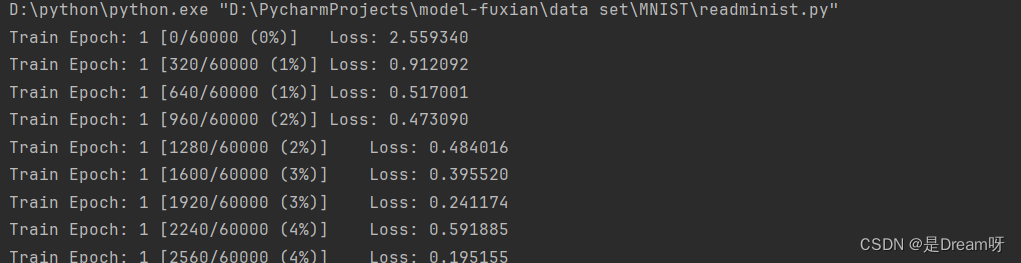
精确度
Test__Average loss: 0.000808,Accuracy: 99.150
最后可以发现准确度达到了99%还高,可以看出来残差网络识别手写数字的准确性还是很高的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java 深入理解 AQS 和 CAS 原理
- Ascend C算子开发常见问题案例
- 【性能优化】EFCore性能优化(二)-禁用实体跟踪
- 73应急响应-Web分析php&javaWeb&自动化工具
- [设计模式 Go实现] 结构型~代理模式
- 白盒测试(超详细总结)
- 编程笔记 html5&css&js 032 HTML Canvas
- React.Children.map 和 js 的 map 有什么区别?
- 24/76AlexNet
- muduo网络库剖析——线程Thread类