pyspark 笔记:窗口函数window
发布时间:2024年01月18日
窗口函数相关的概念和基本规范可以见:pyspark笔记:over-CSDN博客
1 创建Pyspark dataFrame
from pyspark.sql.window import Window
import pyspark.sql.functions as Femployee_salary = [
("Ali", "Sales", 8000),
("Bob", "Sales", 7000),
("Cindy", "Sales", 7500),
("Davd", "Finance", 10000),
("Elena", "Sales", 8000),
("Fancy", "Finance", 12000),
("George", "Finance", 11000),
("Haffman", "Marketing", 7000),
("Ilaja", "Marketing", 8000),
("Joey", "Sales", 9000)]
columns= ["name", "department", "salary"]
df = spark.createDataFrame(data = employee_salary, schema = columns)
df.show(truncate=False) ?
?
2?定义窗口规范
以?partitionBy?作为分组条件,orderBy?对?Window?分组内的数据进行排序
# 以 department 字段进行分组,以 salary 倒序排序
# 按照部门对薪水排名,薪水最低的为第一名
windowSpec = Window.partitionBy("department").orderBy(F.asc("salary"))后面的示例如无特殊说明,都是使用这个窗口规范?
3 排名相关
3.1?row_number()
用于给出从1开始到每个窗口分区的结果的连续行号
df_part = df.withColumn(
"row_number",
F.row_number().over(windowSpec)
)
df_part.show()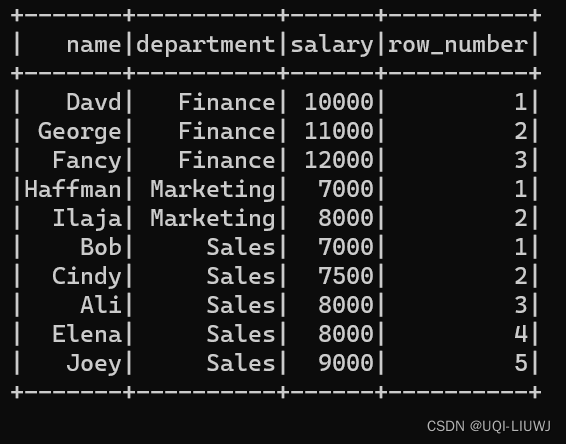 ?
?
[观察上面的数据,发现同样的薪水会有不同的排名(比如Ali和Elena,都是8000的薪水,但一个第三一个第四),这是因为row_number()是按照行来给定序号,其不关注实际数值的大小。
3.1.1 应用举例:
找出每个department 薪水第二低的:
df_part.where(F.col('row_number')==2).show()
'''
+------+----------+------+----------+
| name|department|salary|row_number|
+------+----------+------+----------+
|George| Finance| 11000| 2|
| Ilaja| Marketing| 8000| 2|
| Cindy| Sales| 7500| 2|
+------+----------+------+----------+
'''3.2 rank
不同于row_number,相同value的给相同值
df_part = df.withColumn('rank_number',F.rank().over(windowSpec))
df_part.show()
'''
+-------+----------+------+-----------+
| name|department|salary|rank_number|
+-------+----------+------+-----------+
| Davd| Finance| 10000| 1|
| George| Finance| 11000| 2|
| Fancy| Finance| 12000| 3|
|Haffman| Marketing| 7000| 1|
| Ilaja| Marketing| 8000| 2|
| Bob| Sales| 7000| 1|
| Cindy| Sales| 7500| 2|
| Ali| Sales| 8000| 3|
| Elena| Sales| 8000| 3|
| Joey| Sales| 9000| 5|
+-------+----------+------+-----------+
'''可以看到在rank下,Ali和Elena的rank_number是一样的了?
3.3 dense rank
先看结果,再看和rank的区别
df_part = df.withColumn('dense_rank_number',F.dense_rank().over(windowSpec))
df_part.show()
+-------+----------+------+-----------------+
| name|department|salary|dense_rank_number|
+-------+----------+------+-----------------+
| Davd| Finance| 10000| 1|
| George| Finance| 11000| 2|
| Fancy| Finance| 12000| 3|
|Haffman| Marketing| 7000| 1|
| Ilaja| Marketing| 8000| 2|
| Bob| Sales| 7000| 1|
| Cindy| Sales| 7500| 2|
| Ali| Sales| 8000| 3|
| Elena| Sales| 8000| 3|
| Joey| Sales| 9000| 4|
+-------+----------+------+-----------------+我们重点看Joey(最后一行),rank中Ali和Elena并列第三后,身后的Joey排名第五;dense_rank中,Joey紧跟着排第四?
3.4 percent_rank
百分位排名
df_part = df.withColumn('percent_rank_number',F.percent_rank().over(windowSpec))
df_part.show()
'''
+-------+----------+------+-------------------+
| name|department|salary|percent_rank_number|
+-------+----------+------+-------------------+
| Davd| Finance| 10000| 0.0|
| George| Finance| 11000| 0.5|
| Fancy| Finance| 12000| 1.0|
|Haffman| Marketing| 7000| 0.0|
| Ilaja| Marketing| 8000| 1.0|
| Bob| Sales| 7000| 0.0|
| Cindy| Sales| 7500| 0.25|
| Ali| Sales| 8000| 0.5|
| Elena| Sales| 8000| 0.5|
| Joey| Sales| 9000| 1.0|
+-------+----------+------+-------------------+
'''3.5 ntile
- ?
ntile()可将分组的数据按照指定数值n切分为n个部分, 每一部分按照行的先后给定相同的序数。 - 例如n指定为2,则将组内数据分为两个部分, 第一部分序号为1,第二部分序号为2。
- 理论上两部分数据行数是均等的, 但当数据为奇数行时,中间的那一行归到前一部分。
df_part = df.withColumn('ntile(2)',F.ntile(2).over(windowSpec))
df_part.show()
'''
+-------+----------+------+--------+
| name|department|salary|ntile(2)|
+-------+----------+------+--------+
| Davd| Finance| 10000| 1|
| George| Finance| 11000| 1|
| Fancy| Finance| 12000| 2|
|Haffman| Marketing| 7000| 1|
| Ilaja| Marketing| 8000| 2|
| Bob| Sales| 7000| 1|
| Cindy| Sales| 7500| 1|
| Ali| Sales| 8000| 1|
| Elena| Sales| 8000| 2|
| Joey| Sales| 9000| 2|
+-------+----------+------+--------+
'''4? 分析相关函数
4.1?cume_dist
数值的累进分布值
df.withColumn('cum_dist',F.cume_dist().over(windowSpec)).show()
'''
+-------+----------+------+------------------+
| name|department|salary| cum_dist|
+-------+----------+------+------------------+
| Davd| Finance| 10000|0.3333333333333333|
| George| Finance| 11000|0.6666666666666666|
| Fancy| Finance| 12000| 1.0|
|Haffman| Marketing| 7000| 0.5|
| Ilaja| Marketing| 8000| 1.0|
| Bob| Sales| 7000| 0.2|
| Cindy| Sales| 7500| 0.4|
| Ali| Sales| 8000| 0.8|
| Elena| Sales| 8000| 0.8|
| Joey| Sales| 9000| 1.0|
+-------+----------+------+------------------+
'''这个表怎么解读呢?以Sales为例,薪资小于等于7000的占比0.2,薪资小于等于7500的占比0.4,以此类推
?4.2 lag
照指定列排好序的分组内每个数值的上一个数值
df.withColumn('lag',F.lag('name').over(windowSpec)).show()
'''
+-------+----------+------+-------+
| name|department|salary| lag|
+-------+----------+------+-------+
| Davd| Finance| 10000| null|
| George| Finance| 11000| Davd|
| Fancy| Finance| 12000| George|
|Haffman| Marketing| 7000| null|
| Ilaja| Marketing| 8000|Haffman|
| Bob| Sales| 7000| null|
| Cindy| Sales| 7500| Bob|
| Ali| Sales| 8000| Cindy|
| Elena| Sales| 8000| Ali|
| Joey| Sales| 9000| Elena|
+-------+----------+------+-------+
'''4.3 lead
和lag相反,下一个值
df.withColumn('lead',F.lead('name').over(windowSpec)).show()
'''
+-------+----------+------+------+
| name|department|salary| lead|
+-------+----------+------+------+
| Davd| Finance| 10000|George|
| George| Finance| 11000| Fancy|
| Fancy| Finance| 12000| null|
|Haffman| Marketing| 7000| Ilaja|
| Ilaja| Marketing| 8000| null|
| Bob| Sales| 7000| Cindy|
| Cindy| Sales| 7500| Ali|
| Ali| Sales| 8000| Elena|
| Elena| Sales| 8000| Joey|
| Joey| Sales| 9000| null|
+-------+----------+------+------+
'''?5 聚合函数
此时的聚合样式为:
windowSpecAgg=Window.partitionBy('department')5.1 avg
平均值
df.withColumn('avg',F.avg('salary').over(windowSpecAgg)).show()
'''
+-------+----------+------+-------+
| name|department|salary| avg|
+-------+----------+------+-------+
| Davd| Finance| 10000|11000.0|
| Fancy| Finance| 12000|11000.0|
| George| Finance| 11000|11000.0|
|Haffman| Marketing| 7000| 7500.0|
| Ilaja| Marketing| 8000| 7500.0|
| Ali| Sales| 8000| 7900.0|
| Bob| Sales| 7000| 7900.0|
| Cindy| Sales| 7500| 7900.0|
| Elena| Sales| 8000| 7900.0|
| Joey| Sales| 9000| 7900.0|
+-------+----------+------+-------+
'''?5.2 sum 求和
5.3 min/max 最大最小值
5.4 count 这一个窗口内有多少记录
df.withColumn('count',F.count('salary').over(windowSpecAgg)).show()
'''
+-------+----------+------+-----+
| name|department|salary|count|
+-------+----------+------+-----+
| Davd| Finance| 10000| 3|
| Fancy| Finance| 12000| 3|
| George| Finance| 11000| 3|
|Haffman| Marketing| 7000| 2|
| Ilaja| Marketing| 8000| 2|
| Ali| Sales| 8000| 5|
| Bob| Sales| 7000| 5|
| Cindy| Sales| 7500| 5|
| Elena| Sales| 8000| 5|
| Joey| Sales| 9000| 5|
+-------+----------+------+-----+
'''?5.5?approx_count_distinct 相同的值只记录一次
df.withColumn('ap_count',F.approx_count_distinct('salary').over(windowSpecAgg)).show()
'''
+-------+----------+------+--------+
| name|department|salary|ap_count|
+-------+----------+------+--------+
| Davd| Finance| 10000| 3|
| Fancy| Finance| 12000| 3|
| George| Finance| 11000| 3|
|Haffman| Marketing| 7000| 2|
| Ilaja| Marketing| 8000| 2|
| Ali| Sales| 8000| 4|
| Bob| Sales| 7000| 4|
| Cindy| Sales| 7500| 4|
| Elena| Sales| 8000| 4|
| Joey| Sales| 9000| 4|
+-------+----------+------+--------+
'''
文章来源:https://blog.csdn.net/qq_40206371/article/details/135654854
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 详解Java多线程之循环栅栏技术CyclicBarrier
- LCR 143. 子结构判断
- 嵌入式软件工程师面试题——2025校招社招通用(Linux篇)(二十五)
- 【面试宝典】图解ARP协议、TCP协议、UDP协议
- 【算法Hot100系列】组合总和
- 什么是护网行动?
- Spring Boot依赖版本声明
- 六:Day05_Spring Security01
- 攀登者1 - 华为OD统一考试
- 【二段式状态机】 fsm 输出打一拍写法