爬虫从实战入门(第一天),小白入门js逆向教程
发布时间:2024年01月19日
练习具体网址请私信博主,或者博客中有什么不明白的也可以私信博主
第一天
作者学习初衷:在面对ai时代,数据是基础,然而那么多的数据去哪找呢,这个时候就需要用到我们的爬虫,本博客的任何代码都是合法合规,不给源代码,会回答一些问题,读者怎么做,怎么用和本人没有任何关系,宗旨是传播知识
先从简单的网站开始:良好的开始是成功的一半,由于各种原因,没有办法写完整的东西,因此有需要请私信
分析
我们先来看看书上的描述打开网站的开发者工具后,发现网站的数据是通过ajax动态加载的,因此只用勾选这一块的xhr就行:如何确定是xhr断点呢?请自行查找或者后台私信博主

我们先来看看书上的描述然后我们来看接口数据(很明显该接口的返回数据是密文,那为什么在浏览器中用户看到的都是明文呢,那么解密的方法肯定在浏览器里面,那应该在哪呢,这会在js里面,到这里后我们现在要做的就是去跟踪js):
我们现在就启动器里面看看(很明显是异步的,他的加载顺序是混乱的),这就不得不说我们常用的定位方法了,(hook,启动器,dom调试,xhr调试),因为他这个是在返回数据中加密,因此我们直接用hook会快很多。

到这我们分析部分就做完了
扣代码部分
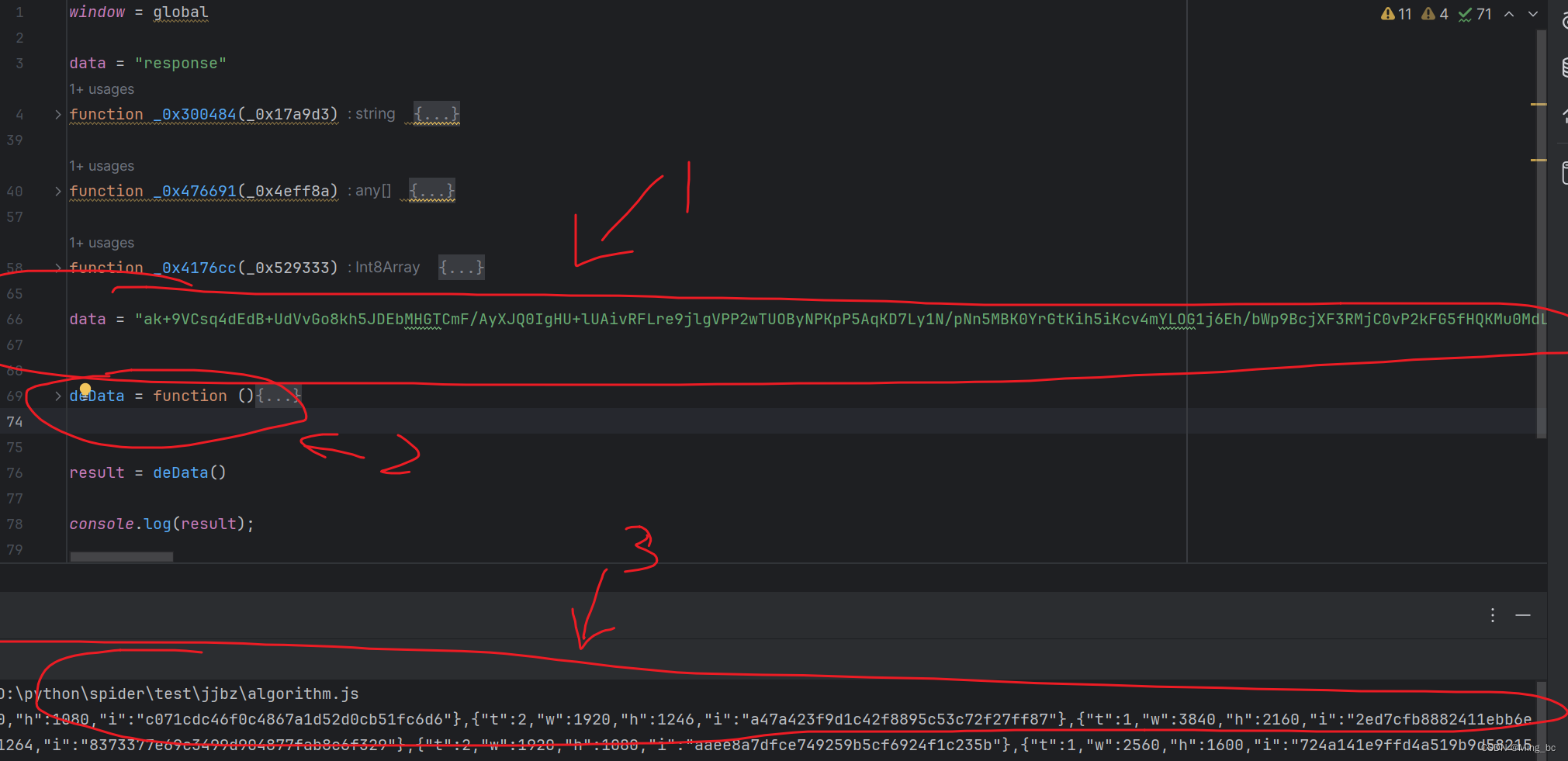
我们可以看到密文是在这加载的:

执行完这个函数后它就变成了明文,因此解密的函数就是这个:_0x1683d3[‘a’][‘decipher’],我们只要解决他就行了 ,我们只要进入它,看他里面的函数是怎么写的就行

运行效果图:
图片中的1是密文,2是解密的位置,3是解密后的明文
创作不易,给作者点个赞吧,球球了
文章来源:https://blog.csdn.net/weixin_50745263/article/details/135643462
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux xxd命令(将文件或标准输入转换为hex(十六进制)和ASCII(美国信息交换标准代码)表示,或者从hex dump(十六进制转储)反向到二进制)
- 米贸搜|facebook加人有限制吗?facebook每天最多加多少人
- 专业洞见:Python中的Statsmodels库高级线性模型
- 探索 Coinbase 二层链 Base 的潜力与风险
- 从 C 到 C++ 编程 — 面向对象编程
- C++类和对象(下)
- 代码随想录刷题笔记(DAY 6)
- 简单实现微信授权登录测试代码
- 【深度学习:Synthetic Training Data 】合成训练数据简介
- 【华为OD机试真题2023C&D卷 JAVA&JS】分配土地