K-最近邻算法(KNN)是什么算法?
K-最近邻算法(K-Nearest Neighbor,KNN)是一种经典的有监督学习方法,也可以被归为懒惰学习(Lazy Learning)方法。它基于“物以类聚”的原理,假设样本之间的类别距离越近则它们越有可能是同一类别。
KNN算法的工作原理简单且直观,当需要将一个测试样本分类时,它首先会计算测试样本与所有训练样本之间的距离,然后根据距离的递增关系进行排序。接着,它会选择距离最小的前K个样本,并统计这K个最近邻样本中每个样本出现的次数。最后,它会选择出现频率最高的类标号作为未知样本的类标号。
在KNN算法中,K值的选择是关键。如果K值较小,只有当需要进行预测的样本和训练的样本较接近时,才能有较好的效果。如果K值较大,则算法分类的近似误差增大,与输入样本距离较远的样本也会对结果产生作用。
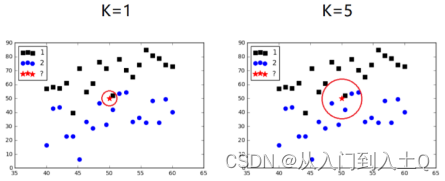
KNN算法的工作过程如下:
1.计算待分类样本与训练集中所有样本之间的距离,常用的距离度量方法包括欧氏距离、曼哈顿距离等。
2.选择K个距离最近的样本,即K个最近邻。
3.对于分类问题,统计K个最近邻中不同类别的样本数量,并将待分类样本归为数量最多的那个类别。
4.对于回归问题,计算K个最近邻的平均值或加权平均值,并将其作为待分类样本的预测值。
KNN算法的优点是简单易理解、实现容易,并且对于非线性问题具有较好的表现。此外,KNN算法可以适应新的训练数据,不需要重新训练模型。KNN算法既能够用来解决分类问题,也能够用来解决回归问题。在处理分类问题时,KNN通过扫描训练样本集找到与测试样本最相似的训练样本,并依据该样本的类别进行投票确定测试样本的类别。在处理回归问题时,KNN则通过计算训练样本与测试样本的相似程度进行加权投票。
然而,KNN算法的缺点包括计算复杂度高,需要存储全部训练样本,对于大规模数据集会消耗较多的内存和时间。此外,KNN算法对于样本分布不平衡的情况可能产生偏见,并且对于高维数据和噪声数据的处理能力相对较弱。
需要注意的是,由于KNN算法需要计算所有训练样本与测试样本之间的距离,因此当训练样本集较大时,其计算成本会较高。为了解决这个问题,可以考虑使用一些优化的距离计算方法,如树结构算法等。同时,KNN算法的方差(Variance)往往较高,容易受到训练集大小和噪声的影响,因此在使用时需要注意过拟合和欠拟合的问题。
在应用方面,KNN算法常用于推荐系统、图像识别、医学诊断等领域。
喜欢点赞收藏,如有疑问,点击链接加入群聊【信创技术交流群】:http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=EjDhISXNgJlMMemn85viUFgIqzkDY3OC&authKey=2SKLwlmvTpbqlaQtJ%2FtFXJgHVgltewcfvbIpzdA7BMjIjt2YM1h71qlJoIuWxp7K&noverify=0&group_code=721096495
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一个关于自动化工具开发思路
- windows系统中,通过LOAD到入csv格式的文件到neo4j中,如何写文件路径
- 长宁区科协常务副主席张正行一行到访深兰科技
- vulnhub靶场之DC-7
- 深度学习入门——卷积神经网络CNN基本原理+实战
- QT+OSG/osgEarth编译之五十九:ac+Qt编译(一套代码、一套框架,跨平台编译,版本:OSG-3.6.5插件库osgdb_ac)
- 用C语言实现简单的三子棋游戏
- 运动员最佳匹配问题
- Nacos与Eureka
- 一文带你掌握ThinkPHP6中的数据验证技巧,提升开发效率!