文本生成中的解码器方法
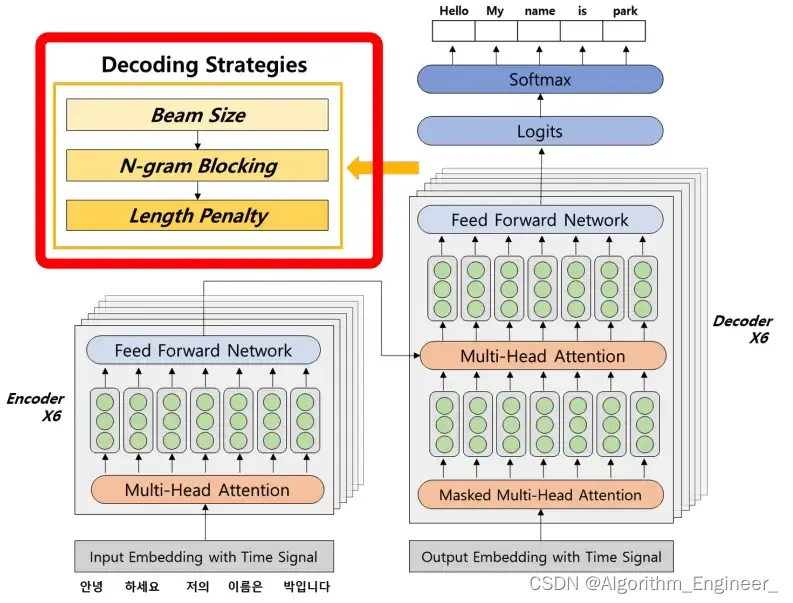
一.解码器的基本介绍
在文本生成任务中,解码器是生成序列的关键组件。解码器的目标是从先前生成的标记或隐藏状态中生成下一个标记。有几种方法用于设计文本生成中的解码器,以下是一些常见的解码器方法:
Teacher Forcing(教师强制):
在训练期间,解码器的输入是实际的目标序列标记。这种方法被称为教师强制,因为它相当于给解码器提供了正确答案。这有助于加速模型的训练,但在生成时可能导致模型对输入序列的错误估计。
Greedy Decoding(贪婪解码):
在生成时,选择每个时间步骤上概率最高的标记作为下一个标记。贪婪解码是一种简单而直观的方法,但可能导致生成的序列不够多样化。
Beam Search(束搜索):
与贪婪解码不同,束搜索考虑多个备选标记。它保留多个潜在的生成序列,然后选择整体概率最高的序列。束搜索有助于生成更多样化和更准确的序列,但也增加了计算开销。
Sampling-based Methods(基于抽样的方法):
使用随机抽样来选择下一个标记,其中每个标记的概率由模型输出的概率分布决定。这包括贪婪抽样、温度调整抽样等方法。这样的方法可以生成更多样化的序列,但可能会导致不确定性和不稳定性。
Top-k Sampling:
在每个时间步上,从概率分布中选择概率最高的前k个标记作为备选。然后,从这些备选中进行抽样。这有助于平衡生成的多样性和模型的准确性。
Top-p Sampling(Nucleus Sampling):
与Top-k Sampling类似,但是选择概率累积超过某个阈值(p)的标记。这种方法被称为Nucleus Sampling,可以在不同场景下控制生成的多样性。
这些方法可以单独使用,也可以结合使用,根据任务的要求和性能的平衡选择合适的解码策略。不同的解码方法在生成文本时有不同的影响,选择合适的方法取决于具体的应用场景。
二.基于搜索的解码方法
2.1贪心搜索
贪心搜索(Greedy Search)是一种基于局部最优选择的搜索策略,它在每一步选择当前状态下最好的选项,而不考虑全局的最优解。贪心搜索通常适用于优化问题,其中每一步的决策都是为了在当前状态下取得最大的即时收益。
以下是贪心搜索的基本原理和特点:
局部最优选择: 贪心搜索每次都选择在当前状态下看起来最有利的选项,而不考虑这个选择可能导致的全局最优解。它假定通过一系列局部最优选择能够达到全局最优。
没有回溯: 贪心搜索通常不进行回溯,即一旦做出了某个决策,就不再考虑之前的决策。这使得算法简单,但也可能错过全局最优解。
适用性: 贪心搜索适用于一些问题,如最短路径、最小生成树等,其中每一步的决策都可以通过贪心地选择当前最优解来达到全局最优。
不一定得到最优解: 由于贪心搜索只考虑当前状态下的最优选择,它并不保证能够得到全局最优解。在某些情况下,贪心算法可能陷入局部最优,导致无法达到最优解。
适用场景: 贪心搜索在一些问题中表现良好,特别是当问题具有贪心选择性质,并且每一步的选择不会影响之后的决策时。但在一些问题中,贪心算法可能不够有效。
例子: 最短路径问题中的Dijkstra算法、最小生成树问题中的Prim和Kruskal算法等都是贪心搜索的经典应用。
总体而言,贪心搜索是一种简单而有效的搜索策略,适用于特定类型的问题。然而,对于一些复杂的优化问题,贪心搜索可能并不是最佳选择,需要考虑其他更复杂的搜索算法。
2.2集束搜索
集束搜索(Beam Search)是一种用于在搜索空间中找到最优解的启发式搜索算法。它通常用于在自然语言处理领域中的序列生成任务,例如机器翻译或语音识别。与贪心搜索不同,集束搜索考虑了多个可能的解,并尝试保留最有希望的解。
以下是集束搜索的基本原理和特点:
搜索空间: 集束搜索在搜索空间中保留多个假设或候选解,而不仅仅是单一的假设。这些假设构成了一个集束(beam),其中包含了若干个可能的解。
宽度优先搜索: 集束搜索在搜索空间中进行宽度优先的探索。它考虑多个假设,逐步扩展每个假设的可能性,直到找到最终的解。
集束宽度: 集束搜索的一个重要参数是集束宽度(beam width),它决定了在每一步选择中保留多少个候选解。较大的集束宽度可以增加搜索的广度,但也会增加计算成本。
得分计算: 在每一步,集束搜索根据某种得分函数对每个候选解进行评估,并选择得分最高的一部分作为下一步的候选。得分函数通常综合考虑了模型生成的概率、长度惩罚等因素。
长度惩罚: 为了避免生成过长的序列,通常会引入长度惩罚,使得长度较短的序列在得分计算中更有优势。
终止条件: 集束搜索会继续进行直到满足某个终止条件,例如生成了特定数量的候选解或达到了最大步数。
多模态应用: 集束搜索不仅适用于文本生成,还可以应用于其他序列生成任务,如图像描述生成等。
贪心性: 尽管集束搜索考虑了多个假设,但在每一步仍然是贪心的选择当前最优解,以确保计算效率。
集束搜索通过在搜索空间中保留多个假设,克服了贪心搜索可能陷入局部最优解的问题。然而,由于计算成本的增加,集束搜索也需要在计算效率和搜索广度之间做出权衡。
三.基于采样的解码方法
3.1随机采样
随机采样是一种在搜索空间中随机选择候选解的方法,通常用于生成序列或样本的任务。与贪心搜索和集束搜索不同,随机采样不依赖于得分或概率,而是通过纯随机的方式生成可能的解。
以下是随机采样的基本原理和特点:
随机性: 随机采样是一种完全随机的选择方法。在每一步,它从可能的选择中随机挑选一个,而不考虑概率分布或得分。
无偏性: 由于是纯随机选择,随机采样具有无偏性,即每个可能的解被选择的概率是相等的。
不受约束: 随机采样不受任何约束,不考虑搜索空间中的得分或其他启发式信息。因此,它可以生成各种可能的解,包括不太可能的或不合理的解。
适用性: 随机采样适用于一些探索性任务,其中不需要依赖于概率分布或启发式信息,而是希望通过纯随机的方式探索解空间。
无回溯: 与集束搜索不同,随机采样通常不进行回溯。每一步的选择都是独立的,不受之前选择的影响。
用途: 随机采样在一些生成任务中用于生成多样化的输出,例如在语言模型中用于生成新文本、在图像生成中用于生成多样的图像等。
样本数量: 随机采样的结果取决于采样的次数,样本数量越多,生成的样本多样性越大。
缺点: 由于是完全随机的选择,随机采样可能导致生成的结果不够稳定或不符合特定的要求。因此,在一些需要精准或有特定要求的任务中,随机采样可能不是首选的方法。
随机采样适用于一些探索性的生成任务,但在一些需要稳定性和控制的场景中,可能需要考虑其他更加有针对性的搜索方法。
3.2temperature的随机采样
在随机采样的过程中,温度(temperature)是一个调控样本生成的参数。它影响了生成过程中概率分布的平滑程度,进而影响了生成的样本的多样性。较高的温度会增加样本的多样性,而较低的温度会减少样本的多样性。
在语言模型等生成任务中,通常使用 softmax 函数来计算下一个词的概率分布。生成过程中,对这个概率分布进行采样以获得下一个词。温度参数(通常用 τ 表示)用来调节 softmax 函数的输出,较高的温度会增大概率分布中较大的概率,减小概率分布中较小的概率,使得选择次优选项的可能性增加,从而生成更多样性的样本。反之,较低的温度会加强概率分布中较大的概率,减小概率分布中较小的概率,使得选择优势选项的可能性增加,从而生成更加确定性的样本。在实际应用中,可以通过调整温度参数来平衡生成样本的多样性和确定性。
3.3top-k采样
Top-k 采样是一种用于生成序列数据的采样策略,特别常用于自然语言处理领域,如语言模型的文本生成任务。该策略的目的是在生成下一个词时,仅考虑概率分布中排名前 k 的最高概率的词,从而控制生成的多样性。
以下是 Top-k 采样的基本原理和特点:
选择概率最高的词: 在每一步生成词的过程中,从概率分布中选择排名前 k 的最高概率的词,而忽略其他概率较小的词。
避免过度随机性: Top-k 采样相比于完全随机的采样,能够在一定程度上避免生成过度随机的输出。通过仅考虑排名前 k 的词,可以限制生成过于多样的情况。
控制多样性: 调整 k 的大小可以控制生成的多样性。较大的 k 会增加考虑的词的数量,生成结果更多样化;而较小的 k 会导致更加集中在高概率的词上,生成结果更加确定性。
与温度参数结合使用: Top-k 采样通常与温度参数结合使用。温度参数可以进一步调整概率分布,平衡高概率和低概率的词之间的关系。
实现方式: 在实际实现中,可以在每一步生成词时,对概率分布进行排序,并选择排名前 k 的词进行采样。
适用场景: Top-k 采样适用于需要在生成过程中平衡多样性和确定性的任务,如生成对话、文章等。
Top-k 采样是在生成任务中控制输出多样性的一种有效方式,它使得生成结果更加可控,适用于需要平衡多样性和确定性的场景。
3.4top-p采样
Top-p 采样,也被称为nucleus采样,是一种用于生成序列数据的采样策略,特别常用于自然语言处理领域,例如语言模型的文本生成任务。该策略的目的是在生成下一个词时,仅考虑概率分布中累积概率排名在前 p% 的词,从而控制生成的多样性。
以下是 Top-p 采样的基本原理和特点:
选择概率累积较高的词: 在每一步生成词的过程中,从概率分布中选择累积概率排名在前 p% 的词,而忽略其他概率较小的词。
避免生成极端随机性: Top-p 采样相比于完全随机的采样,能够在一定程度上避免生成过于极端的随机输出。通过考虑概率分布中累积概率较高的词,可以限制生成结果更加多样化的情况。
控制多样性: 调整 p 的大小可以控制生成的多样性。较大的 p 会增加考虑的词的数量,生成结果更多样化;而较小的 p 会导致更加集中在累积概率较高的词上,生成结果更加确定性。
与温度参数结合使用: Top-p 采样通常与温度参数结合使用。温度参数可以进一步调整概率分布,平衡高概率和低概率的词之间的关系。
实现方式: 在实际实现中,可以在每一步生成词时,对概率分布进行排序,并选择累积概率排名在前 p% 的词进行采样。
适用场景: Top-p 采样适用于需要在生成过程中平衡多样性和确定性的任务,如生成对话、文章等。
Top-p 采样是在生成任务中控制输出多样性的一种有效方式,它使得生成结果更加可控,适用于需要平衡多样性和确定性的场景。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 四. 基于环视Camera的BEV感知算法-PETR
- 按字节长度截取字符串
- Dubbo的服务降级策略剖析
- 京东数据分析-2023年度大家电行业数据分析(含空调、冰箱、洗衣机、平板电视品类)
- android 和 opencv 开发环境搭建
- 基于协同过滤的电影评论数据分析与推荐系统
- 【Python教程】Windows 安装IDE 编辑器Pycharm
- 【PostgreSQL创建索引的锁分析和使用注意】
- 2401--1.8 Linux Day04--温柔破解与远程登陆
- InTouch 历史报表,适用于新型工程或v2012以上版本、系统平台