提升中文文本分析的效率:掌握jieba分词的技巧
发布时间:2024年01月08日
jieba分词
? jieba是一个流行的中文分词库,用于将中文文本切分成词语。它是基于字典和规则的分词工具,具有简单易用、高效准确的特点。jieba可以用于中文文本的分词、关键词提取、词性标注等自然语言处理任务。
拆分句子:
import jieba
text = "我喜欢使用jieba进行中文分词"
seg_list = jieba.cut(text, cut_all=False) # cut_all=False表示采用精确模式进行分词
print("分词结果:")
for word in seg_list:
print(word)

关键词提取
? 可以根据文本中词语的重要程度提取关键词。
import jieba
from jieba import analyse
text = "我喜欢使用jieba进行中文分词"
keywords = jieba.analyse.extract_tags(text, topK=3)
# topK=3`表示提取出现频率最高的前3个关键词
print("关键词提取结果:")
for keyword in keywords:
print(keyword)
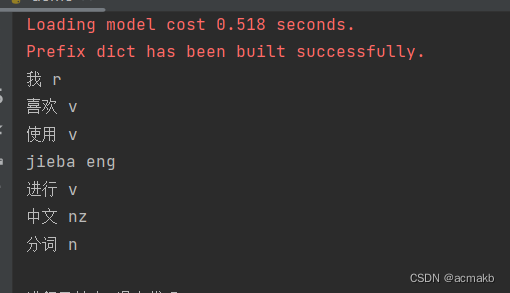
词性标注:
import jieba.posseg as pseg
text = "我喜欢使用jieba进行中文分词"
words = pseg.cut(text)
print("词性标注结果:")
for word, flag in words:
print(word, flag)
停用词处理:
英文处理
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# 下载停用词和分词器的资源(只需要下载一次)
nltk.download('stopwords')
nltk.download('punkt')
# 文本
text = "This is an example sentence for text analysis."
# 分词,得到一个词汇列表 tokens
tokens = word_tokenize(text)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
# 连接处理后的词汇
filtered_text = ' '.join(filtered_tokens)
# 输出分词结果和去除停用词后的结果
print("分词结果:", tokens)
print("去除停用词后的结果:", filtered_tokens)
结果:
分词结果: ['This', 'is', 'an', 'example', 'sentence', 'for', 'text', 'analysis', '.']
去除停用词后的结果: ['This', 'example', 'sentence', 'text', 'analysis', '.']
中文处理:
import nltk
from nltk.corpus import stopwords
import jieba
text = """Python是一种流行的编程语言。
它广泛用于Web开发、数据分析和机器学习。
Python具有简单易读的语法,易于学习和使用。"""
# 去除换行符和特殊符号
text = text.replace('\n', '').replace('、', '').replace('。', '').replace(';','')
# 下载停用词列表
# nltk.download('stopwords')
# 获取中文停用词列表
stop_words = set(stopwords.words('chinese'))
# 使用jieba分词
tokens = list(jieba.cut(text, cut_all=False))
# 去除停用词
filtered_tokens = [word for word in tokens if word not in stop_words]
# 连接处理后的词汇
filtered_text = ' '.join(filtered_tokens)
print(tokens)
print(filtered_text)

总结
在本博客中,我们深入探讨了jieba分词作为一种强大的中文文本处理工具的各个方面。首先,我们学习了如何使用jieba进行句子拆分,将长文本划分为有意义的句子。接下来,我们了解了关键词提取的重要性,并使用jieba.analyse模块提取出关键词。然后,我们介绍了jieba.posseg模块,通过词性标注来理解每个词语的语法角色。最后,我们讨论了停用词的处理,不仅包括中文停用词,还包括英文停用词。通过去除这些常见的无意义词语,我们能够提高文本分析的准确性和效率。
jieba分词作为一种灵活而可靠的工具,为中文文本分析提供了强大的支持。无论是在自然语言处理、信息检索还是文本挖掘领域,jieba分词都能帮助我们更好地理解和处理中文文本数据。通过掌握jieba分词的技巧和功能,我们可以更高效地进行中文文本分析,并获得更准确的结果。
感谢您阅读本博客,希望这些内容对您有所帮助。如果您对jieba分词或其他相关主题有任何疑问,请随时留言或联系我。
文章来源:https://blog.csdn.net/ak_bingbing/article/details/135451640
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 零基础搭建k8s集群(一)- 基础准备
- PEGASUS模型介绍
- CSS从入门到精通(5)
- 达梦数据库的归档模式介绍
- 哪种护眼灯对眼睛好?五款高品质考研台灯推荐
- ATFX汇市:美联储会议纪要虽提及降息,但未公布具体时间表
- echarts——折线图实现不同区间不同颜色+下钻/回钻功能——技能提升
- 今日学习的是mysql-事物
- 分布式链路追踪专栏,Spring Cloud Sleuth:分布式链路追踪之通信模型设计
- Java学习苦旅(二十四)——Java中的内部类