Pytorch中Dataset和dadaloader的理解
发布时间:2024年01月24日
不同的数据集在形式上千差万别,为了能够统一用于模型的训练,Pytorch框架下定义了一个dataset类和一个dataloader类。
dataset用于获取数据集中的样本,dataloader 用于抽取部分样本用于训练。比如说一个用于分割任务的图像数据集的结构如图1所示,一个样本由原图像和对应的mask组成。
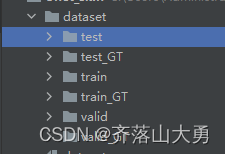
图1 典型数据集的结构
为了获取数据集,典型的代码如下
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
import os
from torchvision import transforms
# 定义数据集
train_data_dir = 'dataset/train'
train_GT_dir = 'dataset/train_GT'
class MyData(Dataset):
def __init__(self, imgdir, maskdir,transform):
self.imgdir = imgdir
self.maskdir = maskdir
self.transform = transform
self.img_list = os.listdir(self.imgdir)
self.mask_list= os.listdir(self.maskdir)
self.img_list.sort()
self.mask_list.sort()
def __getitem__(self, idx):
img_name = self.img_list[idx]
mask_name =self.mask_list[idx]
img_item_path = os.path.join(self.imgdir, img_name)
mask_item_path =os.path.join(self.maskdir,mask_name)
img =Image.open(img_item_path)
mask =Image.open(mask_item_path)
img = self.transform(img)
mask = self.transform(mask)
return img, mask
def __len__(self):
assert len(self.img_list) == len(self.mask_list)
return len(self.img_list)
if __name__ == '__main__':
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
train_data_dir = 'dataset/train'
train_GT_dir = 'dataset/train_GT'
dataset = MyData(train_data_dir, train_GT_dir ,transform)
dataloader = DataLoader(dataset, batch_size=4, num_workers=0)
for step, (img,mask) in enumerate(dataloader):
print(step)
print(img.shape)
print(mask.shape)
if step>0:
break
程序运行的结果如下:
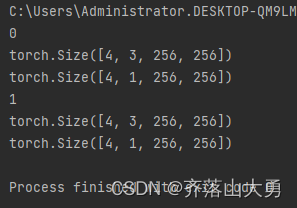
返回了一个batch的img 和mask 的尺寸,说明数据集抽取成功了.
在建立数据集的过程中需用重写__getitem()__和__len()__方法即可。
文章来源:https://blog.csdn.net/qq_42982824/article/details/135827012
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【教3妹学编程-算法题】找出出现至少三次的最长特殊子字符串 II
- 数据在内存中的存储方式
- 个人电脑蓝屏问题的几个解决方法
- 介绍 Apache Spark 的基本概念和在大数据分析中的应用
- Axure之中继器的使用(交互&动作&reperter属性&Item属性)
- 地推拉新任务管理助手程序开发
- D20XB60-ASEMI开关电源桥堆D20XB60
- 工具系列:TensorFlow决策森林_(5)使用文本和神经网络特征
- leetcode 每日一题 2024年01月06日 在链表中插入最大公约数
- 接口自动化测试问题汇总