spark中Rdd依赖和SparkSQL介绍--学习笔记
1,RDD的依赖
1.1概念
rdd的特性之一
相邻rdd之间存在依赖关系(因果关系)
窄依赖
每个父RDD的一个Partition最多被子RDD的一个Partition所使用
父rdd和子rdd的分区是一对一(多对一)
触发窄依赖的算子
map(),flatMap(),filter()
宽依赖
父RDD的一个partition会被子rdd的多个Partition所使用
父rdd和子rdd的分区是一对多
触发宽依赖的算子:
grouBy(),groupByKey,sortBy(),SortByKey(),reduceByKey,distinct()
1.3DAG图计算
DAG又叫做有向无环图
管理rdd依赖关系,保证rdd按照依赖关系进行数据的顺序计算
会根据rdd的依赖关系将计算过程分成多个计算步骤,每个计算步骤成为一个fasse
在计算的rdd依赖关系中,一旦发生了宽依赖就会进行数据才分生成新的stage
1.4Spark术语
app-应用程序(一个py文件/一个交互式页面)
job->作业(调用action算子时会触发job)
stage->计算步骤,由DAG图根据宽依赖产生新的stage
task->任务,有多少个分区数,就有多少个task任务,task任务是以线程方式执行
1.5为什么划分stage计算步骤
spark的task的任务是以线程方式并行计算
线程方式并行计算会有资源竞争导致计算不准确问题
通过stage来解决计算不准确的问题
同一个stage中数据不会进行shuffle(重新洗牌),多个task是可以并行计算
不同stage之间是需要等待上一个stage执行完成后(获取所有数据),再执行下一个stage
如何划分stage?
对于窄依赖,partition的转换处理在说stage中完成计算,不划分(将窄依赖尽量放在同一个stage中,可以实现流水线计算)
对于宽依赖,只能在父EDD处理完成后,才能开始接下来的计算也就是说需要划分stage
遇到宽依赖就需要划分stage
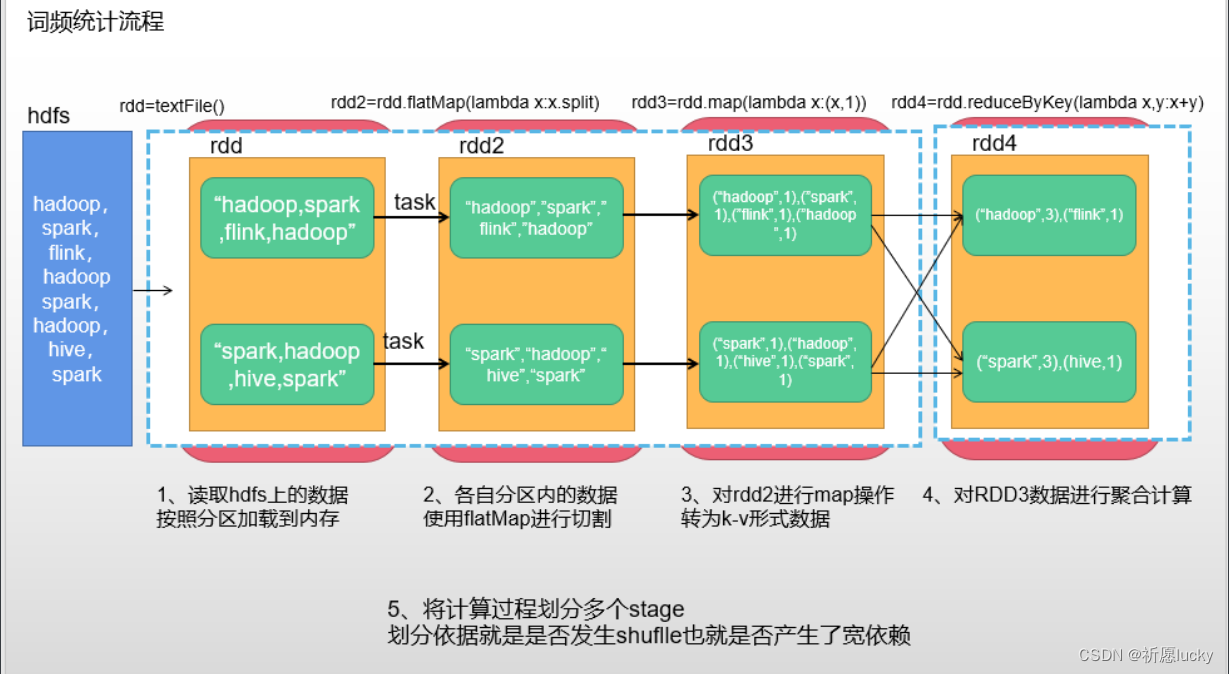
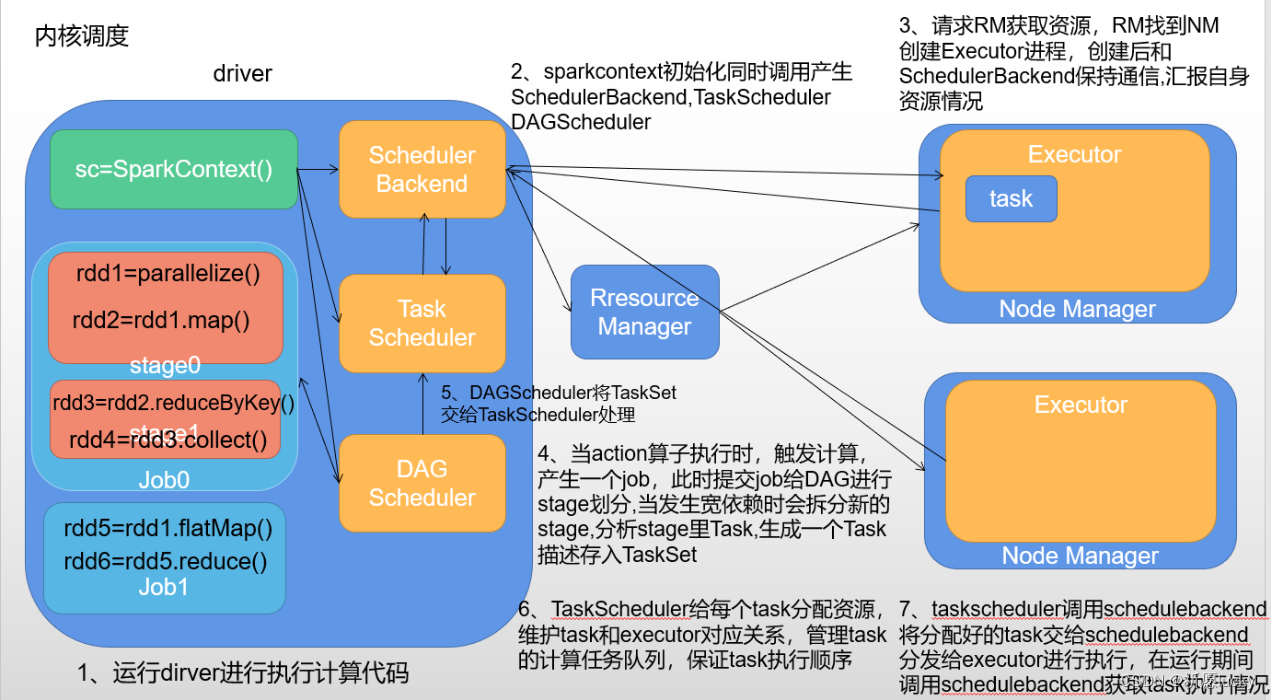
2,Spark的运行流程(内核调度)
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
- DAGScheduler
- 根据rdd间的依赖关系,将提交的job划分成多个stage。
- 对每个stage中的task进行描述(task编号,task执行的rdd算子)
- TaskScheduler
- 获取DAGScheduler提交的task
- 调用SchedulerBackend获取executor的资源信息
- 给task分配资源,维护task和executor对应关系
- 管理task任务队列
- 将task给到SchedulerBackend,然后由SchedulerBackend分发对应的executor执行
- SchedulerBackend
- 向RM申请资源
- 获取executor信息
- 分发task任务
3,Spark的shuffle过程
spark shuffle的两个部分
- shuffle write 写 map阶段,上一个stage得到最后的结果写入
- shuffle read 读 reduce阶段,下一个stage拉取上一个stage进行合并
- 会进行文件的读写,影响spark的计算速度
sortshuffle
- 进行的是排序计算
- bypass模式版本和普通模式版本
- bypass模式版本不会排序,会进行hash操作
- 普通模式版本会进行排序
- 可以通过配置指定按照哪种模式执行
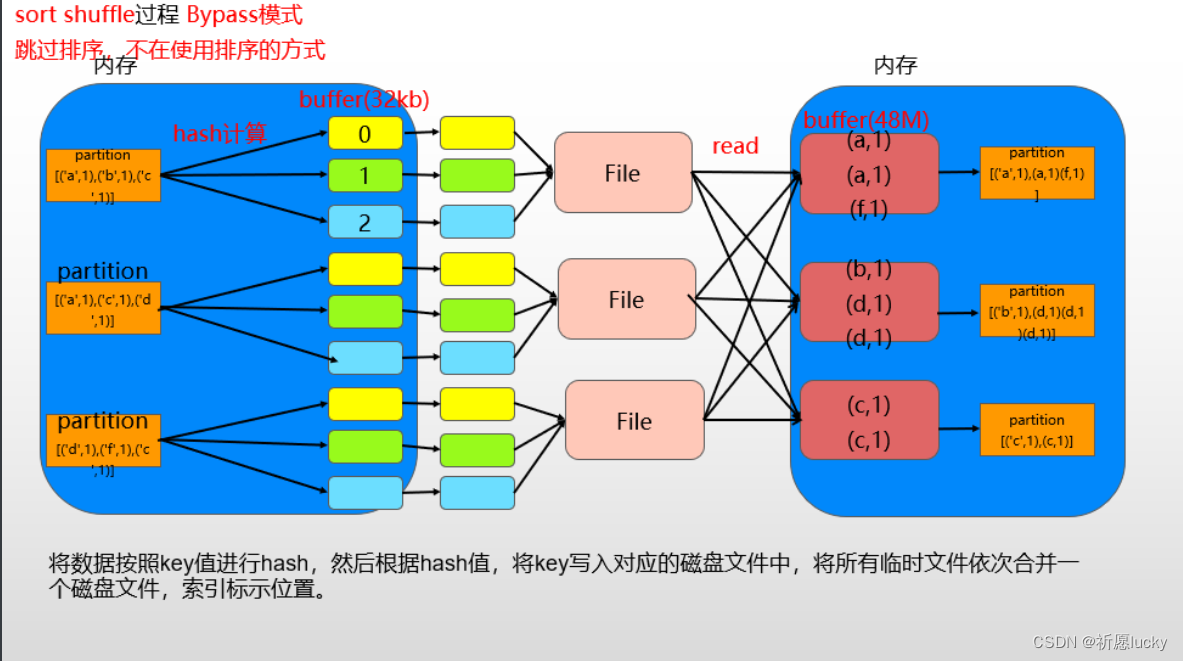
无论是hash还是排序都是将相同key值放在一起处理
- [(‘a’,1),(‘b’,2),(‘a’,1)]
- hash(key)%分区数,相同的key数据余数是相同的,会放一起,交给同一个分区进行处理
- 按照key排序,相同key的数据也会放在一起 ,然后交给同一分区处理
3.1 sparkShuffle配置
spark.shuffle.file.buffer
(默认是32K)。将数据写到磁盘文件之前会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。 可以将其调整为原来的2倍 3倍
spark.reducer.maxSizeInFlight
如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m,默认48M),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
spark.shuffle.io.maxRetries :
shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。(默认是3次)
spark.shuffle.io.retryWait:
该参数代表了每次重试拉取数据的等待间隔。(默认为5s)
调优建议:一般的调优都是将重试次数调高,不调整时间间隔。
spark.shuffle.memoryFraction=10
该参数代表了Executor 1G内存中,分配给shuffle read task进行聚合操作内存比例。
spark.shuffle.manager
参数说明:该参数用于设置shufflemanager的类型(默认为sort)
Hash:spark1.x版本的默认值,HashShuffleManager
Sort:spark2.x版本的默认值,普通机制。当shuffle read task 的数量小于等于200采用bypass机制
spark.shuffle.sort.bypassMergeThreshold=200
- 根据task数量决定sortshuffle的模式
- task数量小于等于200 就采用bypass task大于200就采用普通模式
当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些
pyspark --master yarn --name shuffle_demo --conf 'spark.shuffle.sort.bypassMergeThreshold=300'
代码中配置
SparkConf().set('spark.shuffle.sort.bypassMergeThreshold','300')
# 将配置添加到sparkcontext中
# appName 就是计算任务名称指定和--name作用一样
# conf 参数就算是指定配置信息的
sc = SparkContext(master='yarn',appName='shuffle_demo',conf=conf)
4,spark并行度
4.1 资源并行度(物理并行)
资源并行度调整只能通过交互式,不能通过脚本,由executors节点数和cores核数决定
spark中cpu核心数据设置
- –num-executors=2 设置executors数量
- –executor-cores=2 设置每个executors中的cpu核心数,不能超过服务器cpu核心数
4.2数据并行度(逻辑并行)
由task数量决定,task由分区数决定。
为了保证task能充分利用cpu资源,实现并行计算,需要设置的task数量应该和资源并行度(cpu核心数)一致
-
task = cpu core 这样会导致计算快的task执行结束后,一些资源就会处于等待状态,浪费资源
在实际公司中就要根据公司资源并行度设置分区数
-
有的场景下公司会要求数据并行度大于资源并行度
-
建议task数量是cpu core的2~3倍
-
只有task足够多才能更好的利用资源,但是如果task很多的话,资源少,那么就会先执行一批后再执行下一批
4.3并行度设置
交互式模式
pyspark --master yarn --num-executors=3 --executor-cores=2
开发模式设置
spark-submit --master yarn --num-executors=3 --executor-cores=2 /root/python_spark/a.py
4.1spark调优
- 并行度
- 调整集群节点数和核心数
- 调整数据分区数
- shuffle
- 调整缓冲区的大小 32kb 32M
- 调整shuffle模式
- 调整分配给read的过程聚合操作的内存大小
- cache和checkpoint
- 提升计算效率
- 容错性
- sql代码编写调优
5,sparkSql介绍
5.1什么是sparksql
是spark的一个模块
是Apache Spark用于处理数据结构化数据的模块
结构化数据
表数据 包含行,列字段
python ->DataFrame数据类型
java/scala - >Dataset数据类型
1.2特点
融合性
可以使用纯sql进行数据计算
可以使用DSL方式进行数据计算->将sql中的关键字替换成方法进行使用
统一数据访问
read->读取mysql/hdfs/es/kafka/hbase/文件数据转换成DataFrame数据类型
write->将计算结果保存到mysql/hdfs/es/kafka/hbase/文件兼容Hive
支持Hivesql转换成spark计算任务
标准化数据连接
可以使用三方工具(pycharm/datagrip)通过jdbc或odbc方式连接Spark Sql
5.2数据类型
三种数据类型
RDD:spark中最基础的数据类型,所有的组件的代码都是要转换成rdd任务进行执行,只是存储的数据值
Dataframe
sparksql中数据类型,结构化数据类型。
存储了数据值行数据,row对象
存储了表结构(schema)->schema对象
一条数据就是rdd中的一个元素
dataset类型->java/scale
一条数据就是一个dataframe
5.3DataFrame基本使用
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
#SparkSession类型
#SparkSession.builder 类名.属性名 -》返回builser类的对象
ss = SparkSession.builder.getOrCreate()
#row对象
row1 = Row(id = 1,name = '小明',age = 22)
row2 = Row(id = 2,name = '小红',age = 22)
#创建schema对象(指定数据类型,方式一)
schemal1 = StructType().add('id',IntegerType(),True).\
add('name',StringType(),False).\
add(field='age',data_type=IntegerType(),nullable=True)
#创建dataframe数据df对象
#data:接受的是一个结构化数据类型,二维数据类型[[],[]],[(),()],[{},{}]等都可以
df1 = ss.createDataFrame(data=[row1,row2],schema=schemal1)
df1.show()
# 结果
# +---+----+---+
# | id|name|age|
# +---+----+---+
# | 1|小明| 22|
# | 2|小红| 22|
# +---+----+---+
df1.printSchema()
# 结果
# root
# |-- id: integer (nullable = true)
# |-- name: string (nullable = false)
# |-- age: integer (nullable = true)
#指定数据类型(方式二)
schemal2 = 'id int ,name string,age int'
data_list = [(1,'张三',20),(2,'李四',30)]
df2 = ss.createDataFrame(data=data_list,schema=schemal2)
df2.show()
data_list2 = [{'id':1,'name':'阿三','age':5},{'id':2,'name':'王六','age':80}]
#不指定数据类型会自动创建
df3 = ss.createDataFrame(data_list2)
df3.show()
# 结果
# +---+---+----+
# |age| id|name|
# +---+---+----+
# | 5| 1|阿三|
# | 80| 2|王六|
# +---+---+----+
df3.printSchema()
# 结果
# root
# |-- age: long (nullable = true)
# |-- id: long (nullable = true)
# |-- name: string (nullable = true)
5.4Rdd和Dataframe的相互转换
from pyspark.sql import SparkSession
from pyspark.sql.types import *
#创建ss对象
ss = SparkSession.builder.getOrCreate()
#创建sc对象(ss可以通过sparkContext方法将自己转化为sc对象)
#@property装饰器可以实现调用方法时通过属性方式来调用
sc = ss.sparkContext
#sc对象才能创建rdd对象
#rdd数据结构时列表嵌套->二位数据结构
rdd1 = sc.parallelize([[1,'张三',20],[2,'李四',34]])
df1 = ss.createDataFrame(data=rdd1)
df1.show()
# +---+----+---+
# | _1| _2| _3|
# +---+----+---+
# | 1|张三| 20|
# | 2|李四| 34|
# +---+----+---+
df1.printSchema()
#创建schema对象(指定数据类型,方式一)
schemal1 = StructType().add('id',IntegerType(),True).\
add('name',StringType(),False).\
add(field='age',data_type=IntegerType(),nullable=True)
#将rdd结构的数据转换为dataFrame
df2 = ss.createDataFrame(data=rdd1,schema=schemal1)
print(type(df2))
#结果<class 'pyspark.sql.dataframe.DataFrame'>
df2.show()
rdd1 = df2.rdd
print(type(rdd1))
#结果<class 'pyspark.rdd.RDD'>
######################
schemal2 = 'id int ,name string,age int'
df3 = ss.createDataFrame(data=rdd1,schema=schemal2)
df3.show()
#schema:后面只需要传入列名列表不需要类型
df4 = rdd1.toDF(schema=['id' ,'name','age'])
print(type(df4))
#<class 'pyspark.sql.dataframe.DataFrame'>
df4.show()
#结果
# +---+----+---+
# | id|name|age|
# +---+----+---+
# | 1|张三| 20|
# | 2|李四| 34|
# +---+----+---+
new_rdd = df3.rdd
print(type(new_rdd))
#结果<class 'pyspark.rdd.RDD'>
print(new_rdd.collect())
#获取rdd中每个row对象元素中的id列的值
#x->
rdd_map = new_rdd.map(lambda x:x.id)
print(rdd_map.collect())
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python超详细基础文件操作【建议收藏】
- Python实现Excel切片删除功能(附源码)
- 邦芒忠告:千万远离这四大倒霉离职事件
- RGB图像转换为HIS彩色模型的python实现——数字图像处理
- 螺旋矩阵算法(leetcode第885题)
- 单机开机无感全自动进入B\S架构系统
- npm 和 Yarn:一场关于包管理的战争(上)
- 矩阵微分笔记(1)
- 金蝶二次开发插件:第一章-第一个插件
- 抓包工具Fiddler的下载、安装、配置、基本使用