大文件上传
发布时间:2024年01月17日
1. 分片上传前言
- 分片上传解决的问题
- 上传时间比较久
- 中间一旦出错就需要重新上传
- 一般服务端会对文件的大小进行限制
- 秒传
- 原理
分片上传的原理就像是把一个大的视频文件切成多个小视频片段。每个小块大小相同,比如每块大小为2MB(最好不要大于5MB)。然后,逐个上传这些小块到服务器。上传的时候,可以同时上传多个小块,也可以一个一个地上传。上传每个小块后,服务器会保存这些小块,并记录它们的顺序和位置信息。所有小块上传完成后,服务器会把这些小块按照正确的顺序拼接起来,还原成完整的大文件。
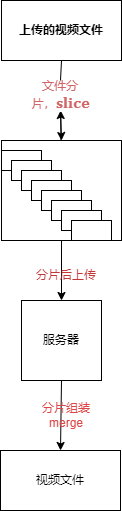
2. 文件分片
分片的核心就是用Blob对象的slice方法,在上传时获取的文件是一个File对象,它是继承于Blob,所以可以用slice方法对文件进行分片
let blob = instanceOfBlob.slice([start [, end [, contentType]]]};
start和end代表 Blob 里的下标,表示被拷贝进新的 Blob 的字节的起始位置和结束位置。
const CHUNK_SIZE = 1024 * 1024
const createFileChunks = (file: File) => {
let cur = 0
const chunks = []
while (cur < file.size) {
chunks.push(file.slice(cur, cur + CHUNK_SIZE))
cur += CHUNK_SIZE
}
return chunks
}
2.1 文件分片hash计算
- 在切片后必须去区分不同的文件,这时可以根据文件内容生产一个唯一的
hash值,文件内容变化,hash值就会跟着发生变化。 - 使用工具
npm i spark-md5
// 配置TS declare module 'spark-md5'
/**利用hash 区分文件
* 1. 第一个和最后一个切片的内容全部参与计算
* 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算
* 文件秒传原理:在文件发送请求时,判断hash值有没有被记录,记录直接使用当前hash值相同的文件
*/
const calcuteHash = (chunks: Array<Blob>) => {
return new Promise(resolve => {
const targets: Blob[] = []
const spark = new SparkMD5.ArrayBuffer()
// 1. 第一个和最后一个切片全部参与计算
// 2. 中间的切片只有前两个字节、中间两个字节、后面两个字节参与计算
chunks.forEach((chunk, index) => {
if (index === 0 || index === chunks.length - 1) {
targets.push(chunk)
} else {
targets.push(chunk.slice(0, 2)) // 前两个字节
targets.push(chunk.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2)) // 中间两个字节
targets.push(chunk.slice(CHUNK_SIZE - 2, CHUNK_SIZE)) // 后面两个字节
}
})
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(new Blob(targets))
fileReader.onload = (e) => {
spark.append((e.target as FileReader).result);
resolve(spark.end());
}
})
}
2.2文件上传并发
- 对于1G的大文件来说,假如每个分片的大小为2M,那么总的分片数将会是2048个,如果同时发送这2048个分片,浏览器肯定处理不了(
默认的并发数量只有 6),原因是切片文件过多,游览器处理不了,因此必要限制前端请求个数。 - 创建最大并发数的请求6个,那么同一时刻允许浏览器只发送6个请求,以此类推
上传文件时一般还要用到FormData对象,需要将要传递的文件还有额外信息放到这个FormData对象里面。(切片的hash,大文件的hash,文件名等)
const uploadChunks = async (fileChunks: Array<{file: Blob}>) => {
const data = fileChunks.map(({ file }, index) => ({
fileHash: fileHash.value,
index,
chunkHash: `${fileHash.value}-${index}`,
chunk: file,
size: file.size,
}))
const formDatas = data
.map(({ chunk, chunkHash }) => {
const formData = new FormData()
// 切片文件
formData.append('chunk', chunk)
// 切片文件hash
formData.append('chunkHash', chunkHash)
// 大文件的文件名
formData.append('fileName', fileName.value)
// 大文件hash
formData.append('fileHash', fileHash.value)
return formData
})
let index = 0;
const max = 6; // 并发请求数量
const taskPool: any = [] // 请求队列
while(index < formDatas.length) {
const task = fetch('http://127.0.0.1:3000/upload', {
method: 'POST',
body: formDatas[index],
})
task.then(() => {
taskPool.splice(taskPool.findIndex((item: any) => item === task))
})
taskPool.push(task);
if (taskPool.length === max) {
// 当请求队列中的请求数达到最大并行请求数的时候,得等之前的请求完成再循环下一个
await Promise.race(taskPool)
}
index ++
percentage.value = (index / formDatas.length * 100).toFixed(0)
}
await Promise.all(taskPool)
}
- 后端实现
在处理每个上传的分片的时候,应该先将它们临时存放到服务器的一个地方,方便合并的时候再去读取。为了区分不同文件的分片,就用文件对应的那个hash为文件夹的名称,将这个文件的所有分片放到这个文件夹中。
// 所有上传的文件存放到该目录下
const UPLOAD_DIR = path.resolve(__dirname, 'uploads');
// 处理上传的分片
app.post('/upload', async (req, res) => {
const form = new multiparty.Form();
form.parse(req, async function (err, fields, files) {
if (err) {
res.status(401).json({
ok: false,
msg: '上传失败'
});
}
const chunkHash = fields['chunkHash'][0]
const fileName = fields['fileName'][0]
const fileHash = fields['fileHash'][0]
// 存储切片的临时文件夹
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
// 切片目录不存在,则创建切片目录
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir)
}
const oldPath = files.chunk[0].path;
// 把文件切片移动到我们的切片文件夹中
await fse.move(oldPath, path.resolve(chunkDir, chunkHash))
res.status(200).json({
ok: true,
msg: 'received file chunk'
});
});
});
- 在上传后
uploads文件夹下就会多一个文件夹,这个文件夹里面就是存储的所有文件的分片了。
2.3 文件合并
- 文件合并前端只需要向服务器发送一个合并的请求,并且为了区分要合并的文件,需要将文件的
hash值给传过去
const mergeRequest = () => {
// 发送合并请求
fetch('http://127.0.0.1:3000/merge', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
size: CHUNK_SIZE,
fileHash: fileHash.value,
fileName: fileName.value,
}),
})
.then((response) => response.json())
.then(() => {
alert('上传成功')
})
}
后端实现
- 在将所有的切片上传到服务器并存储到对应的目录里面后,合并的时候需要从对应的文件夹中获取所有的切片,然后利用文件的读写操作,就可以实现文件的合并。合并完成之后,将生成的文件以hash值命名存放到对应的位置
// 提取文件后缀名
const extractExt = filename => {
return filename.slice(filename.lastIndexOf('.'), filename.length)
}
const pipeStream = (path, writeStream) => {
return new Promise((resolve, reject) => {
// 创建可读流
const readStream = fse.createReadStream(path)
readStream.on('end', async () => {
fse.unlinkSync(path)
resolve()
})
readStream.pipe(writeStream)
})
}
/**
* 合并文件夹中的切片,生成一个完整的文件
*/
async function mergeFileChunk(filePath, fileHash, size) {
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
const chunkPaths = await fse.readdir(chunkDir)
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => {
return a.split('-')[1] - b.split('-')[1]
})
const list = chunkPaths.map((chunkPath, index) => {
return pipeStream(
path.resolve(chunkDir, chunkPath),
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
)
})
await Promise.all(list)
// 文件合并后删除保存切片的目录
fse.rmdirSync(chunkDir)
}
// 合并文件
app.post('/merge', async (req, res) => {
const { fileHash, fileName, size } = req.body
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)
// 如果大文件已经存在,则直接返回
if (fse.existsSync(filePath)) {
res.status(200).json({
ok: true,
msg: '合并成功'
});
return
}
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
// 切片目录不存在,则无法合并切片,报异常
if (!fse.existsSync(chunkDir)) {
res.status(200).json({
ok: false,
msg: '合并失败,请重新上传'
});
return
}
await mergeFileChunk(filePath, fileHash, size)
res.status(200).json({
ok: true,
msg: '合并成功'
});
});
3. 代码整合
- 前端代码

- 后端代码

文件地址
文章来源:https://blog.csdn.net/weixin_46104934/article/details/135636422
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 文件包含漏洞概述、特征、利用条件、危害、防御、修复方法
- 教师资格证照片分辨率怎么调?教师资格证上传照片要求
- python美食数据分析可视化系统 爬虫+Echarts 可视化 Django框架 大数据 毕业设计(源码+文档)?
- Docker容器命令案例:Nginx容器修改,Redis容器持久化
- 在WIN从零开始在QMUE上添加一块自己的开发板(一)
- 如何使用ubuntu查看内存使用情况
- 前端八股文(js篇 )
- 【无标题】
- react受控组件和非受控组件区别
- 测试工作3年还在基础岗?可能只是因为你的工作能力差