从查询到高质量回答:发挥 RAG 和 Rerankers 的潜力

每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号

原文标题:From Queries to Quality Answers: Harnessing the Potentials of RAG and Rerankers
原文地址:https://medium.com/ai-insights-cobet/from-queries-to-quality-answers-harnessing-the-potentials-of-rag-and-rerankers-7826faed4ae6
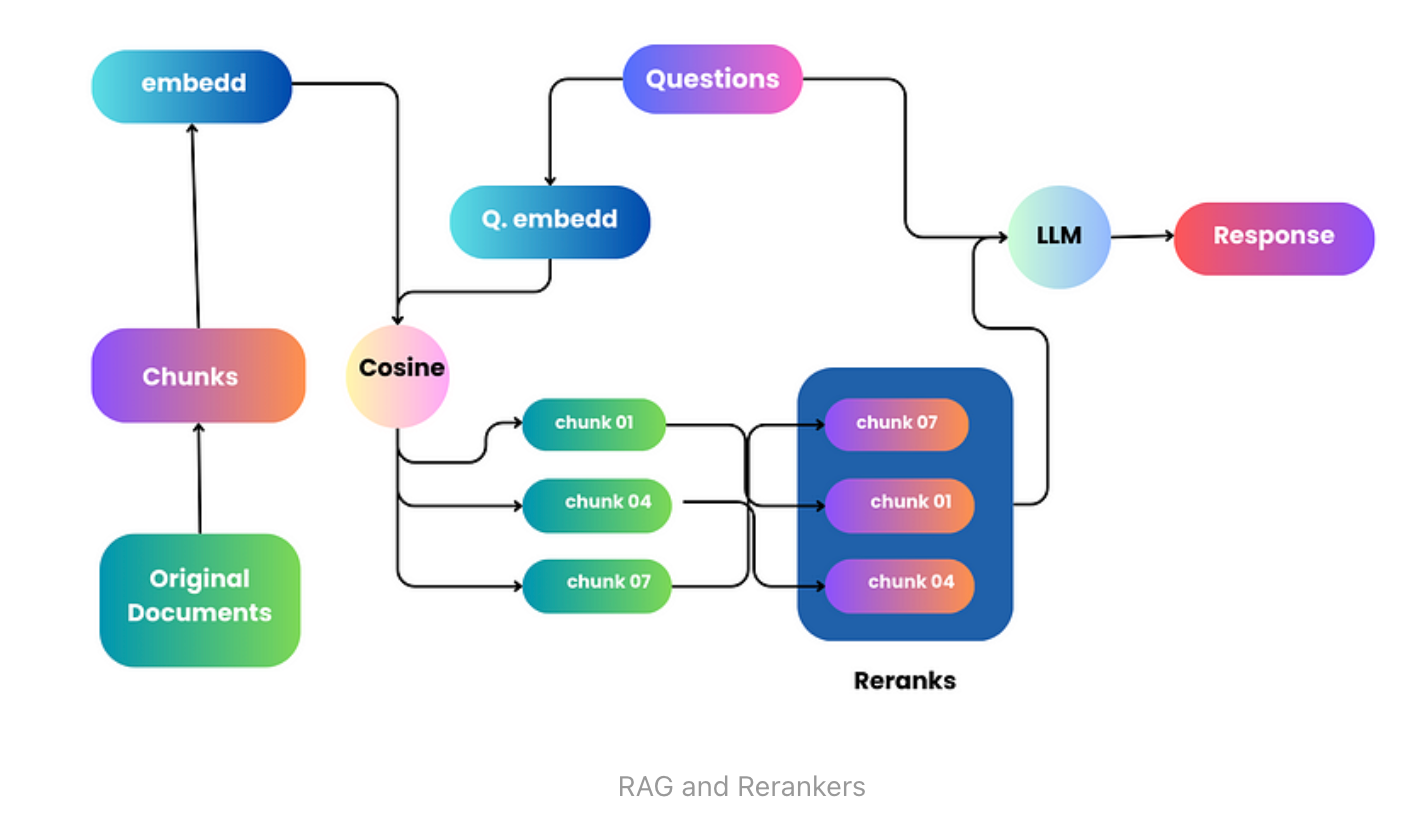
检索增强生成(RAG)是搜索和数据检索领域的一项强大创新,它将传统方法与现代自然语言处理技术相结合,取得了令人瞩目的成果。然而,驾驭 RAG 可能是一项挑战,尤其是对于初学者来说,其中充满了复杂性和高期望值。
本文化繁为简,阐明了 RAG 和 rerankers 的复杂工作原理。我们首先探讨了标准检索方法的基本挑战,强调了改进的必要性。文章的重点是向量和嵌入在微调检索过程中的作用,并解释了它们在管理和解决查询方面的重要意义。
此外,还探讨了重排序器的作用,强调了它们在提高检索结果的相关性和精确性方面的能力。通过讨论,读者将对嵌入模型和重排序器有更深入的了解,理解它们在改进搜索和检索方法方面的基本功能。
充分利用 RAG
接触 RAG(检索增强生成)就像开始一次新的冒险,充满希望和期待。但是,使用 RAG 并不像将文档放入一个特殊的数据库并在需要时将其取回那么简单。它就像一幅拼图,需要不同的拼图块完美地组合在一起,才能展现出它的全貌。要使 RAG 发挥最大作用,需要进行多次改进和微调,就像调整和改进机器的各个部分,使其运行平稳高效。
通过重新排名提高 RAG
重新排名就像一个帮手,让 RAG 系统更好地工作。把它想象成帮助你分类和选择最佳选项的朋友。通过重排,RAG 系统可以给出更好、更准确的答案。它是改进 RAG 工作方式的重要部分,帮助 RAG 发挥最佳性能。
当我们试图查找和获取信息时,就像是在进行一场充满挑战的冒险。探险的一个主要部分就是使用一种叫做 "矢量搜索 "的方法。想象一下,把文本变成特殊的代码(矢量),然后把它们放在我们以后可以找到它们的空间里。当我们有问题(查询)时,系统会查找与我们的问题最匹配的代码,并将它们显示给我们。
但这并不总是那么容易。当我们把文本转换成这些特殊代码时,我们必须简化它们,有时我们会丢失一些细节。尽管我们不得不做出这种妥协,但矢量搜索仍然是一个很好的工具。它能帮助我们更高效地查找和获取所需的信息。
通过重新排序使搜索效果更佳
想象一下,你在搜索某样东西时,会得到很多答案。重新排序就像有一个帮手为你整理这些答案。帮手(排序者)会仔细查看所有答案,并将最好的答案放在最前面。这样,您就能首先看到最有用的信息。它可以确保系统在查看答案以更好地理解和使用这些答案时,将重点放在最重要的答案上,从而使整个搜索过程更加有效,更快地为您提供所需的信息。
我们真的需要搜索排名器吗?
在我们改进搜索的过程中,出现了一个大问题:是否真的有必要使用排序器(我们对答案进行排序的助手)?我们是否可以只改进原有的搜索方法,而不使用排名器?我们可以这样做,改进搜索的基本方法是我们要进一步探索的问题。但是,排序器有一项特殊的工作,这使它变得非常重要。它有自己的方法让搜索工作做得更好,做一些仅仅改进基本搜索可能做不到的事情。今后,我们将进一步讨论为什么排名器是改进信息搜索方式的一个独特而强大的部分。
想象您正在寻宝,在广袤的丛林中寻找隐藏的宝藏。您的目标是找到最有价值的宝藏,而无需花费太多时间四处搜寻。
1.使用编码器进行初始筛选:
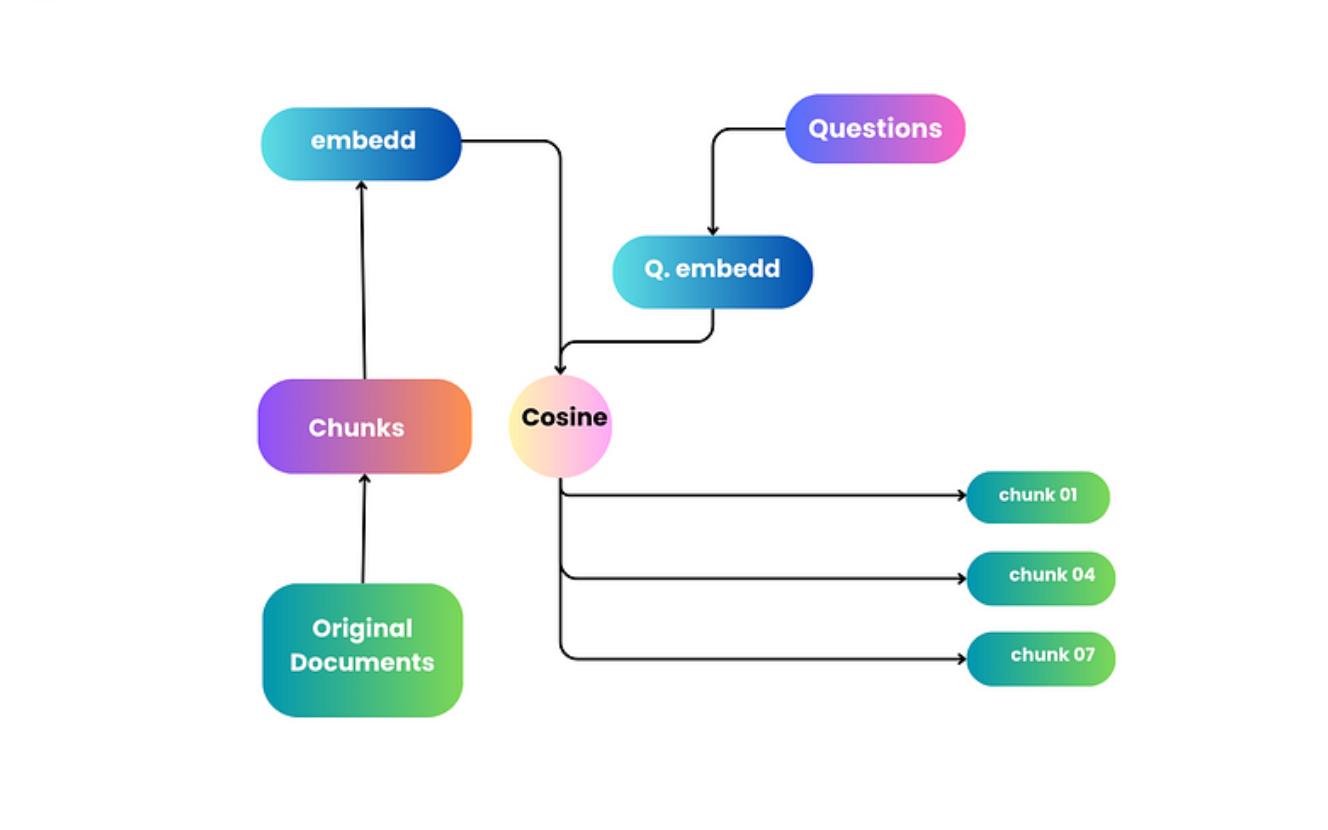
首先,你有一张地图(编码器模型),它能指引你找到最有可能藏有宝藏的地方。与其探索整个丛林,不如利用地图快速找到几个可能埋藏宝藏的地方。这张地图可以帮助你忽略不那么有希望的区域,从而节省时间和精力。在信息检索领域,编码器模型可以迅速筛选出大量文件,并为您提供一份更易于管理、范围更窄的潜在宝藏(相关文件)列表。
2.使用重排器进行提炼:
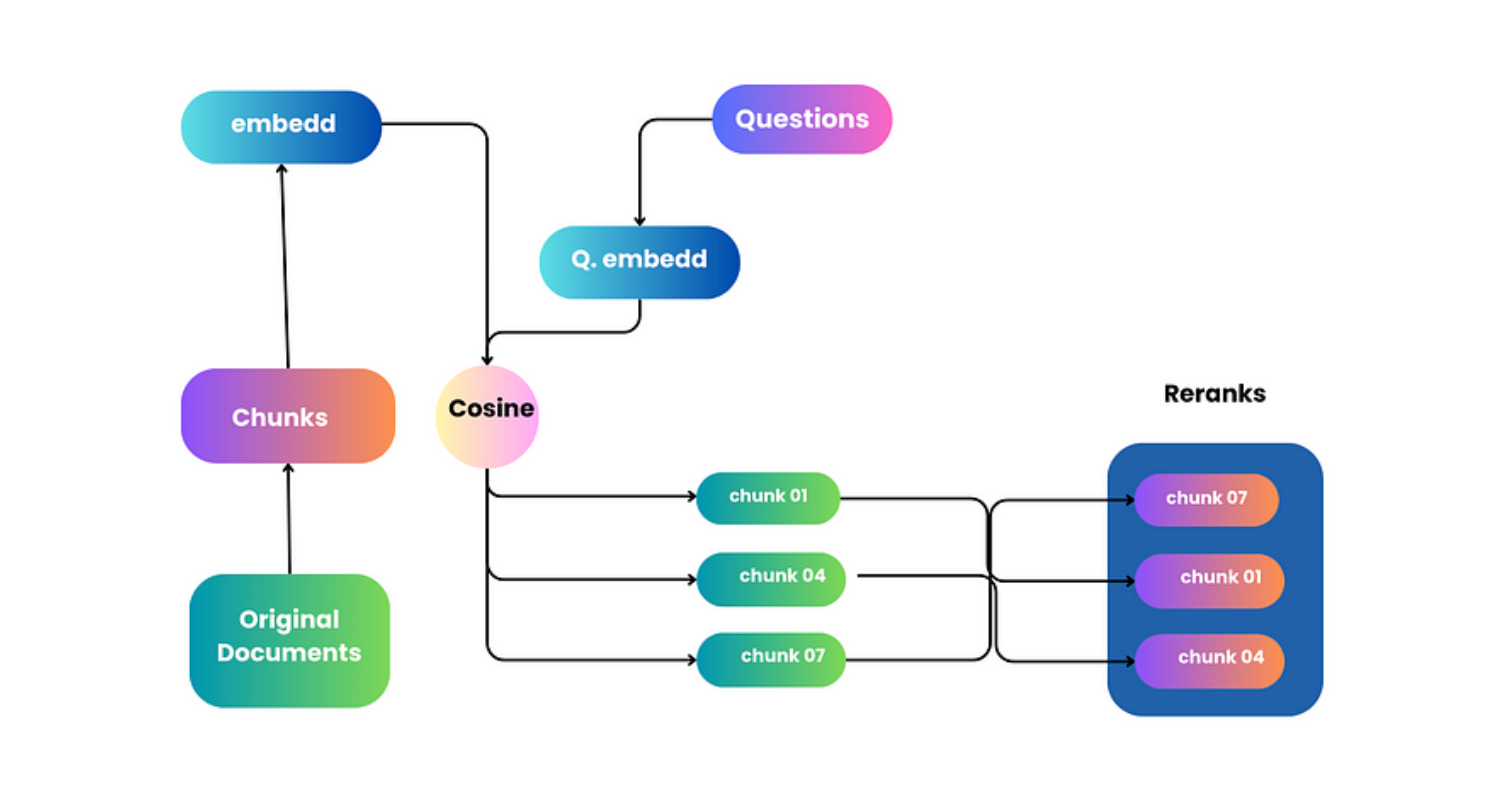
现在,您请来一位寻宝专家(reranker),对您找到的宝藏进行更仔细的检查。专家会仔细评估每一件物品,评估其价值和相关性。凭借他们的专业知识,他们会帮助您从一堆宝藏中找出最有价值、最相关的宝藏,确保您能带走最好的发现(最相关、最精确的文件)。
战略部署:
在这一过程中使用重排序器就像选择何时请来寻宝专家一样。你不想太早请他们来,因为评估丛林中每一个可能的藏宝地点都会耗费大量的精力和时间。因此,您首先要战略性地使用地图来缩小选择范围,然后再请专家来进行最后的精选。
简而言之,这种策略可以提高检索效率,确保您获得最准确、最有价值的结果,而无需在浩如烟海的文件中逐一梳理每一条信息。
Reranker 代码示例:
from sentence_transformers import SentenceTransformer, util
import numpy as np
# Load the Sentence Transformer model
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# Sample documents
documents = ["The cat is on the roof",
"Dogs are in the garden",
"Birds are in the sky"]
# Embed the documents using Sentence Transformer
doc_embeddings = model.encode(documents)
def retrieve_and_rerank(query):
# Step 1: Initial Filtering with Sentence Transformers
query_embedding = model.encode(query)
similarities = util.pytorch_cos_sim(query_embedding, doc_embeddings)[0]
similar_docs = np.argsort(-similarities)
# Step 2: Rerank the filtered documents (you can use a more sophisticated reranker here)
reranked_docs = similar_docs # In this case, no further reranking is applied
# Printing the most similar documents
print("Most similar documents to the query:")
for i, idx in enumerate(reranked_docs[:3]): # Let's say we want the top 3 documents
print(f"Rank {i+1}: Document '{documents[idx]}' with similarity score of {similarities[idx]:.4f}")
# Test the retrieval and reranking with a query
retrieve_and_rerank("Where are the animals?")
结论
RAG 和 rerankers 是信息检索领域的强大工具,各自在优化和增强检索结果方面发挥着至关重要的作用。RAG 擅于在广阔的信息环境中穿梭,能带来相关的信息碎片,确保生成的回复具有丰富的上下文和连贯性。另一方面,Rerankers 对这些结果进行微调,确保输出结果不仅相关,而且与用户的查询精确一致。
它们共同组成了一个强大的联盟,简化了检索流程,提高了效率和效益。它们使系统能够提供有意义的准确回复,确保用户收到的信息不仅有用,而且具有洞察力。通过利用 RAG 和 rerankers 的协作优势,我们为实现更细致、更完善的信息检索方法铺平了道路。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java 中用于格式化文本消息的工具类MessageFormat.format
- 线程间的通信方式
- C++ 包装器—function
- 99年师弟,揭露华为工作的残酷真相
- pro create xxx报错,pro : 无法加载文件 E:\WORK\Node_Global\pro.ps1,因为在此系统上禁止运行脚本。
- C //练习 6-2 编写一个程序,用以读入一个C语言程序,并按字母表顺序分组打印变量名,要求每一组内各变量名的前6个字符相同,其余字符不同。字符串和注释中的单词不予考虑。请将6作为一个可在命令行
- 【CISSP学习笔记】5. 安全架构和工程
- 一天一个设计模式---适配器模式
- 【英特尔人工智能创新应用大赛】57万元+大赛奖金池!更享CSDN专属激励!
- 人工智能_机器学习078_聚类算法_概念介绍_聚类升维_降维_各类聚类算法_有监督机器学习_无监督机器学习---人工智能工作笔记0118