【Spark精讲】Spark作业执行原理
目录
基本流程
用户编写的Spark应用程序最开始都要初始化SparkContext。
用户编写的应用程序中,每执行一个action操作,就会触发一个job的执行,一个应用程序中可能会生成多个job执行。一个job如果存在宽依赖,会将shuffle前后划分成两个stage,前一个stage会将计算结果临时进行存储,后一个stage则进行读取,完成数据交换。
每个stage中,需要执行的计算过程会被划分成多个逻辑相同的一组Task,每个Task会被提交到Executor中运行。当Task运行完成后,会将运行结果返回至Driver中。?
主要组件
Driver端
- DAGScheduler:负责将Job划分为Stage,再将Stage划分为TaskSet;
- TaskScheduler:负责任务的调度;
- SchedulerBackend:负责资源的分配,并把Task提交给Executor中执行。
Executor端
- BlockManager:缓存RDD、缓存Task运行结果。
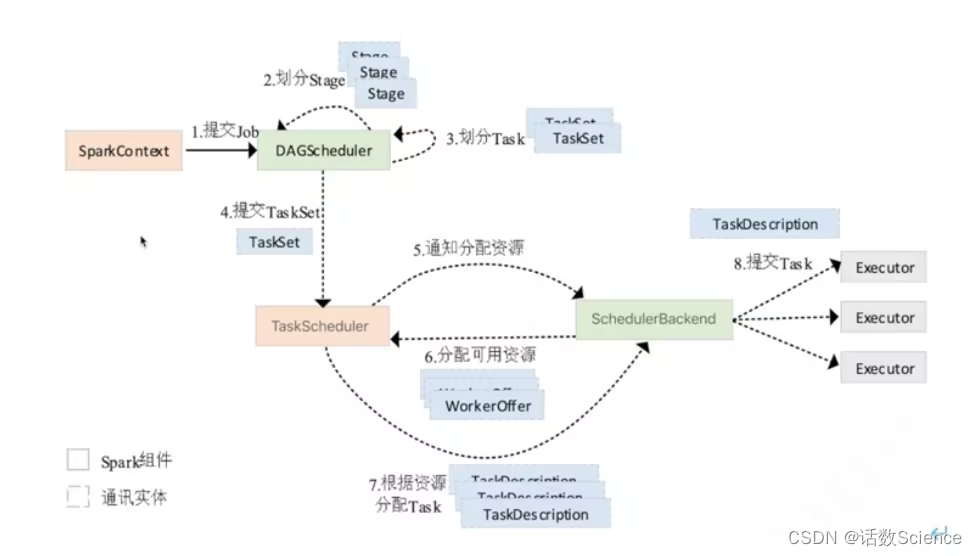
Job提交执行流程
Task提交
SparkContext将RDD的action操作转化为Job,并将Job交给DAGScheduler做进一步处理。
DAGScheduler首选根据shuffle划分stage,根据stage中分区的数量,生成一组Task(即TaskSet),生成Task时还会计算Task的最佳执行位置。DAGScheduler会根据RDD是否进行了缓存来确定是否具有最佳运行位置。
DAGScheduler将Stage生成TaskSet以后,会将TaskSet交给TaskScheduler进行处理,TaskScheduler负责将Task提交到集群中运行,并负责失败重试,为DAGScheduler返回事件信息等。
当有任务提交至TaskScheduler中时,TaskScheduler会通知SchedulerBackend分配计算资源。SchedulerBackend将所有可用的Executor的资源信息转换为WorkerOffer交给TaskScheduler。TaskScheduler负责根据这些WorkerOffer在相应的Executor分配TaskSet中的Task。
SchedulerBackend中通过使用Map结构记录每一个ExecutorData的映射,即可管理所有Executor的CPU使用的情况。为计算任务分配计算资源时,只需要遍历所有的ExecutorData,分配可用的资源即可。
TaskScheduler在接受到DAGScheduler提交的TaskSet以后,会为每个TaskSet创建一个TaskSetManager,用于管理该TaskSet中所有任务的运行。TaskSetManager会根据Task中的最佳运行位置计算TaskSet的所有本地运行级别,本地运行的级别决定了Task最终在哪个Executor中运行。Spark中本地运行级别从小到大可分为进程本地化、节点本地化、无优先位置、机架本地化、任意节点。
Task执行
Executor接收到SchedulerBackend提交的LaunchTask消息后,即可运行该消息中包含的Task。Executor将接收到的Task封装到TaskRunner中,TaskRunner是一个Runnable接口,从而可以将该任务提交到线程池中运行。
当在一个Executor中同时运行多个Task时,多个Task共享Executor中SparkEnv的所有组件,共用Executor中分配的内存。如使用Spark广播变量时,每个Executor中会存在一份,Executor中所有的任务会共享这一份变量。当Executor中的BlockManager缓存了某rdd某分区的数据时,在该Executor上调度使用这个RDD的这个分区的数据的Task执行,可以有效减少网络加载数据的过程,减少网络传输。
当Executor中Task运行完成时,需要将Task的运行结果返回Driver程序,Driver程序根据结果判断该Stage是否计算完成,或者该Job是否计算完成。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 条件风险价值CVaR内容介绍(MATLAB例程)
- MES管理系统电子看板的注意事项
- Cisco Unified Communications Manager (CallManager) 15.0 - 统一通信与协作
- PTA——计算火车运行时间
- 商品评论API接口商品分析接口竞品分析接口代码接入示例
- ValueError: operands could not be broadcast together with shapes (2,) (3,)
- 数据库云平台新数科技完成B轮融资,打造全链路智能化数据库云平台
- 微信商家0.2费率如何申请
- QT学习(19):读写设备抽象类QIODevice
- Unity填坑-灯光烘焙相关