一文详解Cookie以及Selenium自动获取Cookie
前言
以后数据获取途径以及数据资产绝对会是未来核心要素生产工具和资源之一,每个大模型都离不开更加精细化数据的二次喂养训练。不过现在来看收集大量数据的方法还是有很多途径的,有些垂直领域的专业数据是很难获取得到的,靠人力去搜寻相当费时费力,而且处理起来也很麻烦,关键是不能准确的获取强相关数据就对项目开展妹太大帮助。之前本人一直从事的是大数据算法工作,对数据获取和收集这方面也有不错的技术开展,目前将开展新的技术专栏,将把深耕到数据收集和获取这方面的技术展现复盘。
1.什么是Cookie
很多时候我们发现如果我们这网页上面登录过账号,下次再访问该网站就会发现不用再输入密码账号就能登录了。想象一下你去一家咖啡店。第一次去,你告诉店员你的名字和你喜欢的咖啡类型。店员记住了这些信息。下次你再去,店员看到你就知道你叫什么名字,也知道你喜欢什么咖啡,于是直接为你准备了你喜欢的咖啡。
在这个例子中,咖啡店就像一个网站,你就像是访问网站的用户。你提供的名字和咖啡偏好就像是你在网站上输入的信息。咖啡店员记住你的信息,这就像网站在你的电脑上存储Cookie一样。所以,Cookie就是网站为了记住用户的偏好或者身份信息而存储在用户电脑上的小型数据文件。这样,下次你访问同一个网站时,它可以快速地识别你,并根据存储的信息定制内容,就不用再次账号登录了。
在了解到了cookie具有什么样的功能以后,我们再来对cookie更加深入的了解。
2.Cookie的作用和数据形式
有时候浏览网站会出现:

的弹窗提示,根据弹窗提示其实我们就能够看出cookie的一些作用:能够发现我们的需求,还能分析我们的流量和网站使用情况,也就是监视我们用户的浏览习惯和活动。广告商还能使用Cookie来收集关于我们的信息,以显示更相关的广告。这是基于你的浏览历史和其他在线行为,所以这就是为什么我们之前搜了某某用品,某宝某东就直接开始推送了,还有视频网站某书和某站也会陆续推送相关视频。当然如果你开了无痕模式,那么浏览器也不会保存cookie。
总结一下cookie的作用,有以下几点:
- 身份认证和会话管理:当你登录一个网站后,该网站会使用Cookie来记住你的登录状态,这样你就不必在每次访问新页面时都重新登录。
- 个性化设置:网站利用Cookie存储个性化设置,比如语言偏好、主题选择等,以便在你下次访问时提供相同的定制体验。
- 追踪和分析:网站使用Cookie来追踪用户的浏览习惯和活动。这对于网站改进其内容和结构、提供更加个性化的体验非常有用。
- 广告定位:广告商使用Cookie来收集关于你的信息,以显示更相关的广告。这是基于你的浏览历史和其他在线行为的。
- 过期时间:Cookie可以设置不同的过期时间。有些在关闭浏览器时就会消失(会话Cookie),而另一些则会在特定日期后才会消失(持久性Cookie)。
- 隐私和安全:虽然Cookie对提升网站体验很重要,但它们也引发了隐私和安全上的担忧。用户通常可以在浏览器设置中管理Cookie,包括删除和禁用它们。
- 第三方Cookie:除了由网站直接设置的Cookie(第一方Cookie)外,还有第三方Cookie,通常由广告商和分析服务提供商设置,用于跨网站追踪用户行为。
了解以上几点之后,我们再来看看cookie具体存储的数据格式是怎么样的。每个浏览器对于cookie的存储和设置都不一样,以火狐浏览器为例,直接在浏览器搜索设置就可以看到:
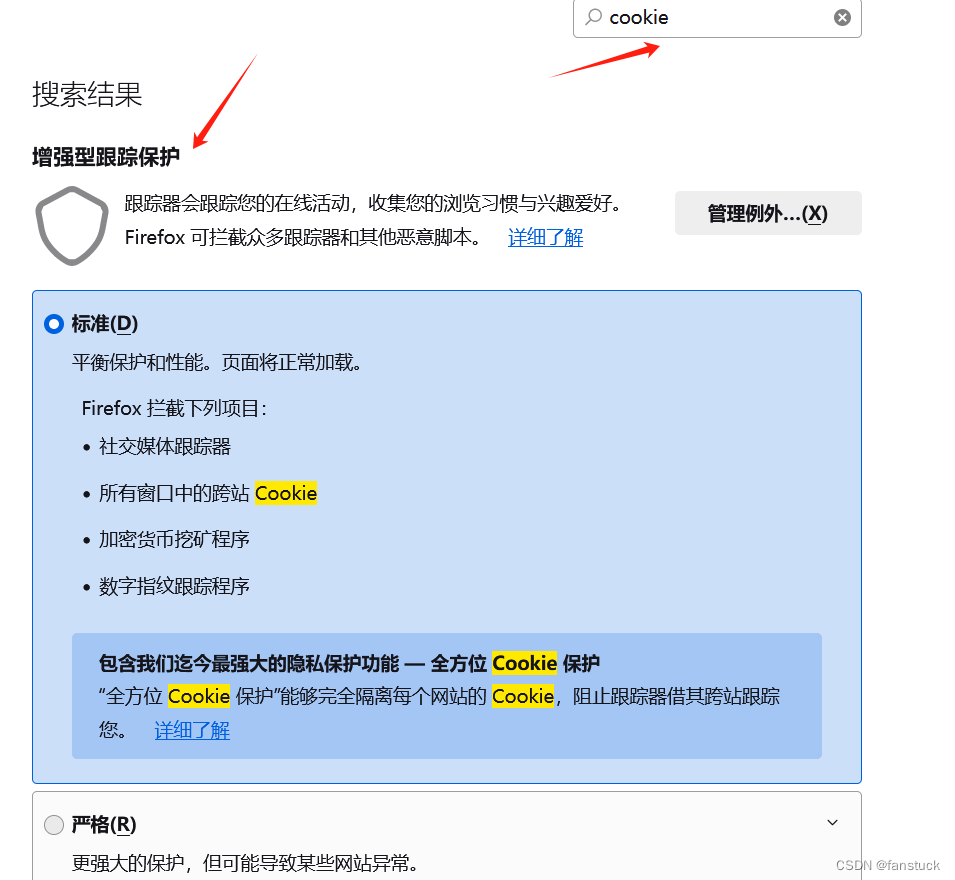
在下方可以看到浏览器存储的cookie:

点击管理数据

如果经常浏览某个网站,我这里是bilibili,就会发现存储的cookie占用内存特别多,也就是存储你的个性行为特别多。那么如何查看一个cookie呢?
根据步骤来,以CSDN为例,输入F12进入开发者模式,点击存储,在界面左边都能看到存储的Cookie:
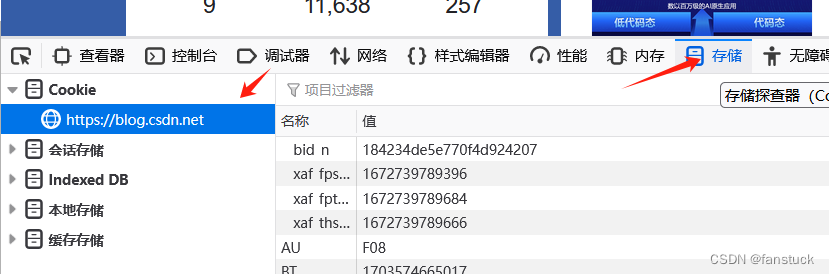
一般cookie是一段不超过4KB的小型文本数据,由一个名称(Name)、一个值(Value)和其它几个用于控制Cookie有效期、安全性、使用范围的可选属性组成。有些服务端设置都cookie很复杂,关键字段就很多,有些就非常简单。
3.cookie属性
我们现了解cookie保存的数据都有哪些属性
(1)Name/Value:名称和值设置Cookie的名称及相对应的值,对于认证Cookie,Value值包括Web服务器所提供的访问令牌。
(2)Domain属性:指定了可以访问该 Cookie 的 Web 站点或域。Cookie 机制并未遵循严格的同源策略,允许一个子域可以设置或获取其父域的 Cookie。当需要实现单点登录方案时,Cookie 的上述特性非常有用,然而也增加了 Cookie受攻击的危险,比如攻击者可以借此发动会话定置攻击。因而,浏览器禁止在Domain属性中设置.org、.com 等通用顶级域名、以及在国家及地区顶级域下注册的二级域名,以减小攻击发生的范围。
(3)Path属性:定义了Web站点上可以访问该Cookie的目录,一般csrToken就有此属性。
(4)Expires属性:设置Cookie的生存期。有两种存储类型的Cookie:会话性与持久性。Expires属性缺省时,为会话性Cookie,仅保存在客户端内存中,并在用户关闭浏览器时失效;持久性Cookie会保存在用户的硬盘中,直至生存期到或用户直接在网页中单击“注销”等按钮结束会话时才会失效。
(5)Secure属性:指定是否使用HTTPS安全协议发送Cookie。使用HTTPS安全协议,可以保护Cookie在浏览器和Web服务器间的传输过程中不被窃取和篡改。该方法也可用于Web站点的身份鉴别,即在HTTPS的连接建立阶段,浏览器会检查Web网站的[证书的有效性。但是基于兼容性的原因(比如有些网站使用自签署的证书)在检测到SSL证书无效时,浏览器并不会立即终止用户的连接请求,而是显示安全风险信息,用户仍可以选择继续访问该站点。由于许多用户缺乏安全意识,因而仍可能连接到Pharming攻击所伪造的网站
(6)HTTPOnly 属性 :用于防止客户端脚本通过document.cookie属性访问Cookie,有助于保护Cookie不被跨站脚本攻击窃取或篡改。但是,HTTPOnly的应用仍存在局限性,一些浏览器可以阻止客户端脚本对Cookie的读操作,但允许写操作;此外大多数浏览器仍允许通过XMLHTTP对象读取HTTP响应中的Set-Cookie头
这都是每一条cookie元素所自带的属性,那么我们再聚焦于cookie的名称一般都有哪些含义。
4.Cookie名称

Cookie的名称(Name)是用来唯一标识不同的Cookie。名称可以根据Cookie的用途来命名,以下是一些常见的Cookie名称和它们的用途:
| 名称(Name) | 用途 |
|---|---|
| session_id/PHPSESSID | 用于标识用户的会话。这种类型的Cookie通常用于登录后保持用户状态。 |
| user_id /uid | 用来标识特定用户,可能用于跟踪或个性化。 |
| remember_me | 通常与长期登录功能有关,用于记住用户的登录状态。 |
| token /auth_token | 用于存储身份验证令牌,通常用于API调用或维持登录状态。 |
| preferences /settings | 保存用户设置和偏好,例如界面主题、语言设置等。 |
| cart/shopping_cart | 对于电商网站,用来跟踪用户的购物车内容。 |
| analytics /tracking_id | 用于网站分析和用户跟踪,可能用于统计用户访问行为。 |
| csrftoken/ XSRF-TOKEN | 于跨站请求伪造(CSRF)保护。 |
| ads/ ad_id | 广告相关的跟踪,用于个性化广告显示。 |
| locale/ language | 存储用户的语言偏好。 |
| cookie_consent/ consent | 记录用户对Cookie使用的同意。 |
以上基本是cookie包含的所有标识了,当然也有很多网站的cookie有更多其他的业务或者是其他笔记防范爬虫等机制,下面我们来利用Python Selenium来获取我们当前的cookie。
5.获取Cookie
获取Cookie的方法特别多,可以用Web浏览器中的JavaScript,可以通过document.cookie属性来访问当前页面的Cookie。也可以在HTTP请求头中接收Cookie。例如,在PHP中,可以通过$_COOKIE全局数组访问Cookie;在Node.js中,可以通过HTTP请求对象的headers.cookie属性访问。或者Python的Requests, Node.js的Axios等。这里展示如何用浏览器自动化工具Selenium来提取浏览器的cookie。如果对selenium不了解的推荐去看博主写的selenium详细介绍的博客。
首先引入库:
from selenium import webdriver
cookie登入前和登入后所存储的是不一致的,所以我们可以前后两次获取cookie看哪些值是存在变动的,这次获取的是csdn博客cookie。
def password_login(self):
self.driver = webdriver.Firefox()
self.driver.get("https://blog.csdn.net/")
cookieBefore = self.driver.get_cookies()
time.sleep(2)
self.driver.find_element(By.LINK_TEXT, "登录").click()
#登入后再获取一次cookie
time.sleep(2)
#扫码
time.sleep(20)
print("登录后!")
cookiesAfter = self.driver.get_cookies()
print("cookiesAfter:")
print(cookiesAfter)
大家可以自己运行一遍,因为cookie是隐私内容这里就不作演示了。
点关注,防走丢,如有纰漏之处,请留言指教,非常感
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JMeter 测试脚本编写技巧
- PHP 基础编程 (1)
- 大小鼠行为刺激-ZL-034B大小鼠跳台仪/多通道跳台记录仪
- CEC2013(python):六种算法(RFO、PSO、CSO、WOA、DBO、ABC)求解CEC2013
- 嵌入式培训机构四个月实训课程笔记(完整版)-Linux系统编程第八天-Linux sqlite3数据库(物联技术666)
- Ubuntu20.04 多Python版本共存与Virtualenvwrapper创建虚拟环境
- 《新课程研究》是什么级别的期刊?是正规期刊吗?能评职称吗?
- 案例分析:如何在企业飞速发展、研发团队快速增长中,快速解决研发管理和效率问题?
- springboot整合websocket后启动报错:javax.websocket.server.ServerContainer not available
- 论文阅读笔记AI篇 —— Transformer模型理论+实战 (二)