人工智能原理实验4(2)——贝叶斯、决策求解汽车评估数据集
🧡🧡实验内容🧡🧡
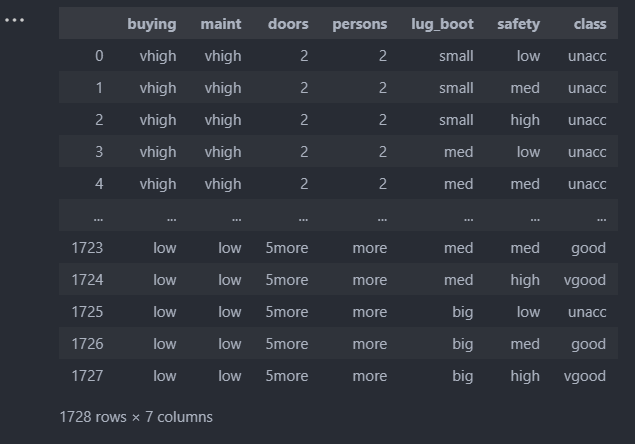
汽车数据集
车子具有 buying,maint,doors,persons,lug_boot and safety六种属性,而车子的好坏分为uncc,ucc,good and vgood四种。
🧡🧡贝叶斯求解🧡🧡
数据预处理
1.转为数字编码
将数据集中的中文分类编码转为数字编码,以便更好地训练。这里采用sklearn的LabelEncoder库进行快速转换。
2.拆分数据集
按7:3的比例拆出训练集和测试集,这里也采用sklearn的train_test_split快速拆分,比手动拆分能更具随机性
3.将dataframe对象转为array
在手动实现的贝叶斯算法类中,通过numpy可以很方便的操纵和计算矩阵格式的数据,因此通过dataframe对象导入数据后,通过df.values将其转为array
朴素贝叶斯原理
- 核心公式:
对于二分类问题,在已知样本特征的情况下,分别求出两个分类的后验概率:P(类别1 | 特征集),P(类别2 | 特征集),选择后验概率最大的分类作为最终预测结果。- 为何需要等式右边?
对于某一特定样本,很难直接计算它的后验概率(左边部分),而根据贝叶斯公式即可转为等式右边的先验概率(P(特征)、P(类别))和条件概率(P(特征 | 类别)),这些可以直接从原有训练样本中求得,其次,由于最后只比较相对大小,因此分母P(特征)在计算过程中可以忽略。- 右边P(特征 | 类别)和P(特征)如何求?
例如,对于car-evalution这个数据集,假设特征只有doors、persons、safety,目标为class。
对于某个样本,它的特征是doors=2、persons=3、safety=low。
则它是unacc的概率是
P(unacc | doors=2、persons=3、safety=low) =
P(doors=2、persons=3、safety=low | unacc) * P(unacc) / P(doors=2、persons=3、safety=low)
对于P(unacc),即原训练样本集中的unacc的频率。
对于P(doors=2、persons=3、safety=low | unacc),并不是直接求原训练样本集中满足unacc条件下,同时为doors=2、persons=3、safety=low的概率,这样由于数据的稀疏性,很容易导致统计频率为0, 因此朴素贝叶斯算法就假设各个特征直接相互独立,即
P(doors=2、persons=3、safety=low | >unacc) = P(doors=2 | unacc)*P(persons=3 |unacc)*P(safety=low | unacc),朴素一词由此而来。
对于P(doors=2、persons=3、safety=low) ,同上述,其等于P(doors=2)*P(persons=3)*P(safety=low)
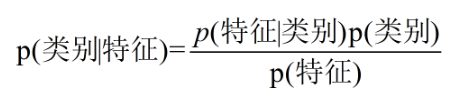
代码
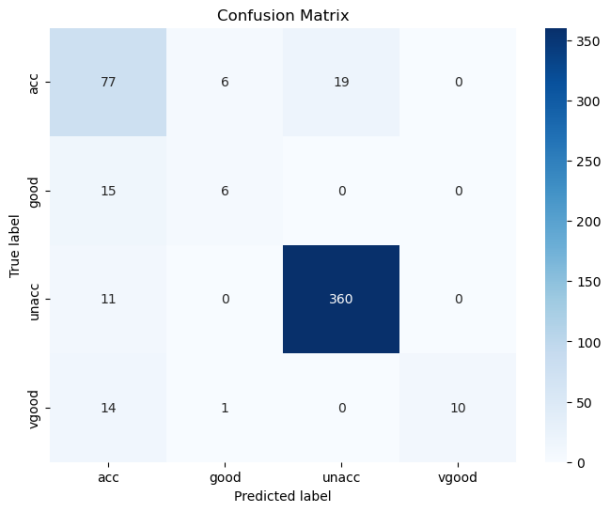
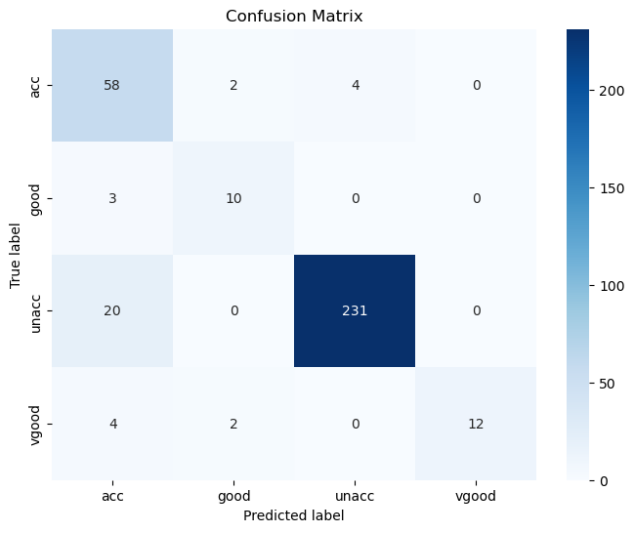
结果
🧡🧡决策树算法求解🧡🧡
数据预处理:
和上述贝叶斯算法中的数据预处理基本一致,这里因为计算信息熵时,要根据信息熵的收敛精度才决定是否跳出递归,经过几次尝试,选择将训练集和测试集8:2的比例拆分,并且random_state=10,避免随机性导致程序死循环。
决策树原理
决策树的决策流程就是从所有输入特征中选择一个特征做为决策的依据,找出一个阈值来决定将其划分到哪一类。
也就是说,创建一个决策树的主要问题在于:
1.决策树中每个节点在哪个维度的特征上面进行划分?
2.被选中的维度的特征具体在哪个值上进行划分?
信息熵的计算公式:
其中n是指数据中一共有n类信息,pi就是指第i类数据所占的比例。
信息熵简单的来说就是表示随机变量不确定度的度量。
熵越大,数据的不确定性就越大。
熵越小,数据的不确定性就越小,也就是越确定。
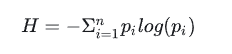
举个例子
假设我们的数据中一共有三类。每一类所占比例为1/3,那么信息熵就是:
假设我们数据一共有三类,每类所占比例是0,0,1,那么信息熵就是:
(实际上log(0)是不能计算的,定义上不允许,程序中直接置为inf即可)
很显然第二组数据比第一组数据信息熵小,也就是不确定性要少,换句话讲就是更为确定。
我们希望决策树每次划分数据都能让信息熵降低,当划分到最后一个叶子节点里面只有一类数据的时候,信息熵就自然的降为了0,所属的类别就完全确定了。
那么怎样找到一个这样的划分使得划分后的信息熵会降低?对着所有维度的特征来一次搜索就行了。
代码
结果

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一、基础数据结构——1.链表——1.动态链表
- 软件工程--设计工程--学习笔记(软件设计原则、软件质量属性设计、架构风格......)
- 计算机报错x3daudio1_7.dll怎么修复,其实很简单
- vue3+ts+vite配置项目引入@surely-vue/table less报错
- Spring Security介绍
- 源码解析:mybatis调用链之XMLStatementBuilder解析解析sql语句节点
- 汪林望教授将于每周三以互动问答直播形式教您如何用龙讯旷腾计算软件PWmat计算不同材料性质
- 主线程退出后子线程是否还会正常运行?
- 如何发布自定义 npm 组件包
- uni-app如何在小程序上预览pdf文件。