2、数据类型
目录
# 7. 设置值的同时,指定生存时间(每次向Redis中添加数据时,尽量设置生存时间)
# 8. 设置值,如果当前key不存在的话(存在的话,什么也不做,如果不存在,同set命令)
# 9. 在key对应的value后,追加内容(相当于字符串拼接)
# 5. 设置值(如果可以-field不存在,就正常添加,存在,什么也不做)
# 8. 获取当前hash结构中全部的field和value
# 3. 修改数据(在存储数据时,指定好你的索引位置,覆盖之前索引位置的数据,index超出整个列表的长度会失败)
# 5. 获取指定索引范围内的数据(start从0开始,stop输入-1,代表最后一个数,-2代表倒数第二个数)
# 9. 保留列表中的数据(保留你指定索引范围内的数据,超过索引范围被移除掉)
# 10. 将一个列表中的最后一个数据,插入到另外一个列表的头部位置
# 3. 随机获取一个数据(获取的同时,移除数据,count默认为1,代表弹出的数据
# 1. 添加数据(score必须是数值。member不允许重复)
# 3. 查看当前数据库中有多少key,返回的是key的数量。
# 1. 查看Redis中的全部的key (pattern: *,xxx*,*xxx)
# 2. 查看某一个key是否存在(1 - 存在,0 - 不存在)
# 4. 设置key的生存时间,单位秒,单位毫秒,设置过期时间
# 5. 设置key的生存时间,单位为秒,单位为毫秒,设置能活到啥时候
# 7 移除key的生存时间(1 - 移除成功, 0 - key不存在生存时间,key不存在)
内存数据库,
Reds是一个key-value型的数据库(相比较之下,MySQL是关联数据库),也就是说,
一个key对应一个value,这是保证高效的手段之一。另外,Redis的所有数据在使用时都存放在内存中。
这包含了两层含义:
单台Redis能存放多少数据,取决于其内存的大小(假设所有内存都给Redis用)。如果需要存放更多数据,可以增加内存或做集群。
Redis支持将数据持久化到磁盘中。但是,不会直接对磁盘进行读写。这种持久化,一般是用于在服务器重启时,先把数据持久化,重启后再从磁盘中读取到内存。
1、string类型
string常用的命令
# 1. 添加值
set key value
eg:set mykey myvalue

# 2. 取值
get key
eg:get mykey
![]()
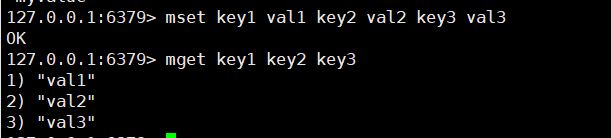
# 3. 批量操作
mset key value [key value ...]
mget key [key ...]
# 4. 自增命令(自增1)
incr key

注意:Incr 命令将 key 中储存的数字值增一。
如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。
如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
本操作的值限制在 64 位(bit)有符号数字表示之内。
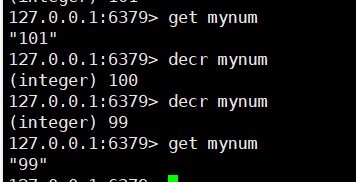
# 5. 自减命令(自减1)
decr key
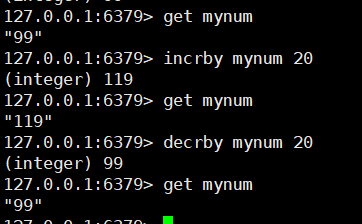
# 6. 自增|自减指定数量
incrby key increment
decrby key increment
eg:incrby mynum 20
# 7. 设置值的同时,指定生存时间(每次向Redis中添加数据时,尽量设置生存时间)
Setex 命令为指定的 key 设置值及其过期时间。如果 key 已经存在, SETEX 命令将会替换旧的值。
setex key second value
eg: setex mykey 60 myval

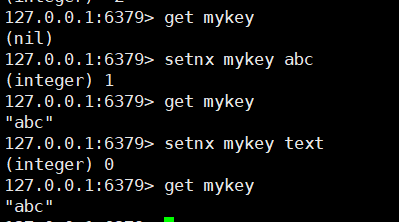
# 8. 设置值,如果当前key不存在的话(存在的话,什么也不做,如果不存在,同set命令)
setnx key value
eg:
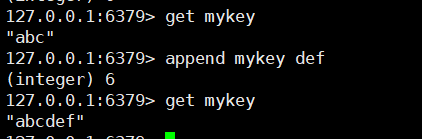
# 9. 在key对应的value后,追加内容(相当于字符串拼接)
append key value
eg:
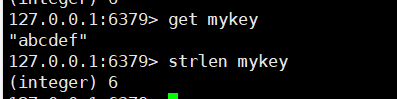
# 10. 查看value字符串的长度
strlen key
String 类型的应用场景:缓存对象、常规计数、分布式锁、共享session信息等。
增加:set key
删除:del key
修改:rename key keynew
查询:get key
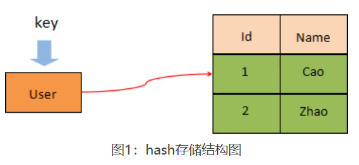
2、hash类型
hash常用类型,hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表
# 1. 存储数据
hset key field value
Hset 命令用于为哈希表中的字段赋值 。
如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。
如果字段已经存在于哈希表中,旧值将被覆盖。
eg:hset website gogle "www.g.cn"

# 2. 获取数据
hget key field
eg: hget website gogle

# 3. 批量操作
hmset key field value [field value ...]
hmget key field [field]


# 4. 自增(指定自增的值)
hincrby key field increment
Hincrby 命令用于为哈希表中的字段值加上指定增量值。
增量也可以为负数,相当于对指定字段进行减法操作。
如果哈希表的 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。
如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。
对一个储存字符串值的字段执行 HINCRBY 命令将造成一个错误。
本操作的值被限制在 64 位(bit)有符号数字表示之内。
eg:
# 5. 设置值(如果可以-field不存在,就正常添加,存在,什么也不做)
hsetnx key field value
eg:
# 6. 检查filed是否存在
hexists key field
eg:
# 7. 删除key对应的field,可以删除多个
hdel key field [field ...]
# 8. 获取当前hash结构中全部的field和value
hgetall key
eg:
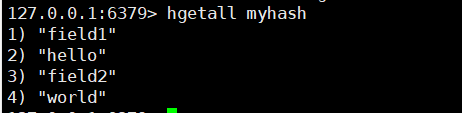
# 9. 获取当前hash结构汇总全部的field
hkeys key

# 10. 获取当前hash结构中全部的value
hvals key
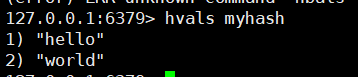
# 11. 获取当前hash结构中field的数量
hlen key
Hash 类型:缓存对象、购物车等。
3、list类型
列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
list常用命令
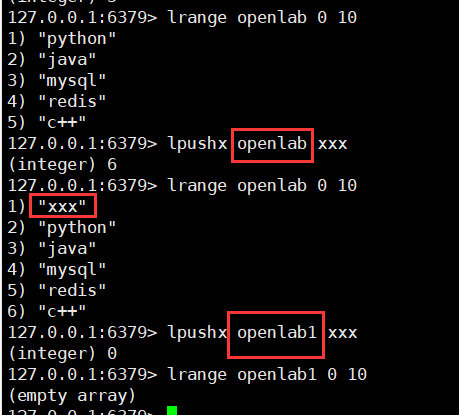
# 1. 存储数据
# 左插入
lpush key value [value ...]
eg: LPUSH openlab redis
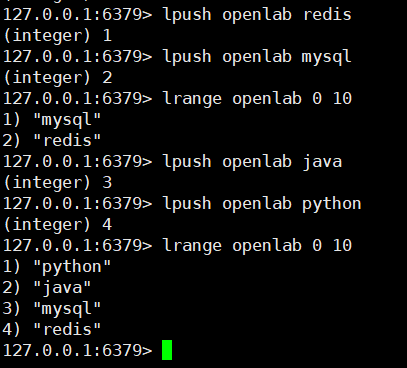
# 右插入
rpush key value [value ...]
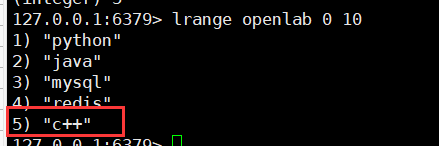
# 2. 存储数据
(如果key不存在,什么事都不做,如果key存在,是list结构就类似lpush操作,但不是list结构,什么也不做)
lpushx key value
rpushx key value
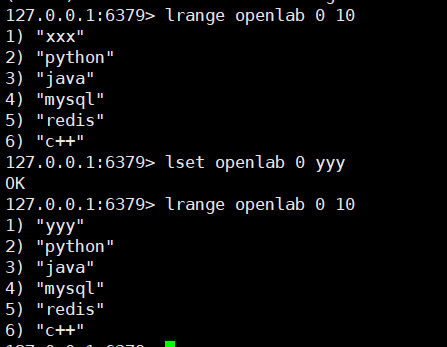
# 3. 修改数据(在存储数据时,指定好你的索引位置,覆盖之前索引位置的数据,index超出整个列表的长度会失败)
lset key index value
# 4. 出栈方式获取数据(左侧出栈,右侧出栈)
lpop key
rpop key
# 5. 获取指定索引范围内的数据(start从0开始,stop输入-1,代表最后一个数,-2代表倒数第二个数)
lrange key start stop
# 6. 获取指定索引位置的数据
lindex key index
# 7. 获取整个列表的长度
llen key
# 8.删除列表中的数据
(他是删除当前列表中的count个value值,count > 0从左侧向右删除,count < 0 从右向左删除,count == 0 删除全部的value)
lrem key count value
# 9. 保留列表中的数据(保留你指定索引范围内的数据,超过索引范围被移除掉)
ltrim key start stop
# 10. 将一个列表中的最后一个数据,插入到另外一个列表的头部位置
rpoplpush list1 list2
List 类型的应用场景:
消息队列(有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
4、set类型
Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
据。
集合对象的编码可以是 intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
set常用命令
# 1. 存储数据
sadd key member [member ...]
# 2. 获取数据(获取全部数据)
smembers key
# 3. 随机获取一个数据(获取的同时,移除数据,count默认为1,代表弹出的数据
量)
spop key [count]
# 4. 交集(获取多个set集合交集)
sinter set1 set2
# 5. 并集(获取全部集合中的数据)
sunion set1 set2
# 6. 差集(获取多个集合中不一样的数据)
sdiff set1 set2
# 7. 删除数据
srem key member [member ...]
# 8. 查看当前set集合中是否包含此值
sismember key member
Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
5、zset类型
有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行 从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
zset的常用命令
# 1. 添加数据(score必须是数值。member不允许重复)
zadd key score member [score member]
# 2. 修改member的分数
(如果member是存在于key中的,正常增加分数,如果 member不存在, 这个命令就相当于zadd)
zincrby key increment member
# 3. 查看指定的member的分数
zscore key member
# 4. 获取zset中数据的数量
zcard key
# 5. 根据score的范围查询member数量
zcount key min max
# 6. 删除zset中的成员
zrem key member [member ...]
# 7. 根据分数从小到大排序,获取指定范围内的数据
(withscores如果添加这个参数,那么就会返回member对应的分数)
zrang key start stop [withscores]
# 8. 根据分数从大到小排序,获取指定范围内的数据
(withscores如果添加这个参数,那么就会返回member对应的分数)
zrevrange key start stop [withscores]
# 9. 根据分数的返回去获取member
(withscores代表同时返回score,添加limit,和MySQL中一样,如果不希望等于min或者max的值被查出来可以采用‘(分数’相当于 < 但是不等于的方式,最大值和最小值使用 +inf 和 -inf来表示)
zrangebyscore key min max [withscores] [limit offset count]
# 显示整个有序集
# 显示整个有序集及成员的 score 值
# 显示score <3 的所有成员
# 10. 根据分数的返回去获取member
(withscores代表同时返回score,添加limit,就和mysql中一样)
zrangbyscore key max min[withscores] [limit offset count]
Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
6、其他命令
客户端与 Redis 建立连接后,默认会选择 0 号数据库即 db0,但可以使用 select 命令更换存储的数据库。
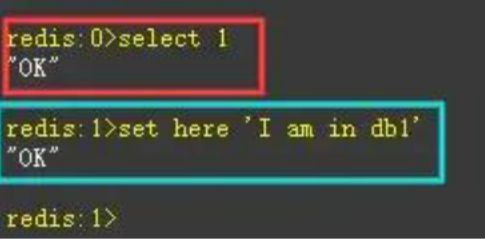
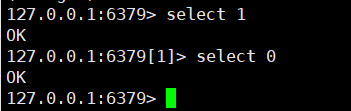
也可以通过修改配置文件的方式选择默认数据库。

Redis库常用命令
# 1. 清空当前所在的数据库
flushdb
# 2. 清空全部数据库
flushall
# 3. 查看当前数据库中有多少key,返回的是key的数量。
dbsize
# 4. 查看最后一次操作的时间(返回时间戳)
lastsave
# 5. 实时监控Redis服务接收到的命令
monitor
key的常用命令
# 1. 查看Redis中的全部的key (pattern: *,xxx*,*xxx)
keys pattern
eg: keys *
查看所有key
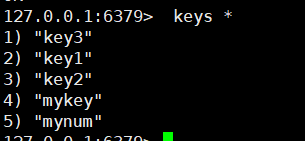
keys mykey
查看指定key
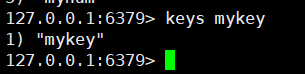
keys mykey* 查看前缀key

# 2. 查看某一个key是否存在(1 - 存在,0 - 不存在)
exists key
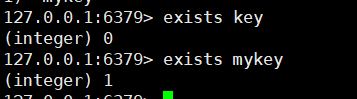
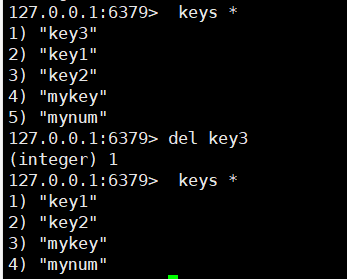
# 3. 删除key
del key [key ...]
# 4. 设置key的生存时间,单位秒,单位毫秒,设置过期时间
expire key second
pexpire key milliseconds
# 5. 设置key的生存时间,单位为秒,单位为毫秒,设置能活到啥时候
expireat key timestamppexpireat key milliseconds
# 6. 查看key的剩余生存时间,单位秒,单位毫秒
(-2 - 可以不存在,-1 - key没有设置生存时间,具体剩余的生存时间)
ttl key
pttl key
# 7 移除key的生存时间(1 - 移除成功, 0 - key不存在生存时间,key不存在)
persist key
# 8. 选择操作的库
select 0~15
# 9. 移动key到另外一个库中
move key db
#10. 用sort命令进行排序
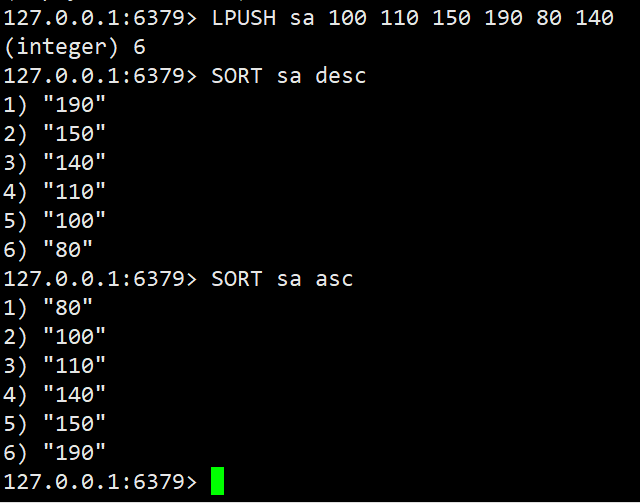
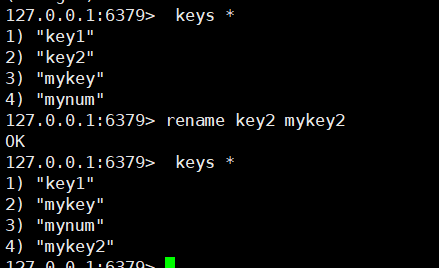
#11. 用rename命令进行修改key
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c语言scanf函数用法
- CTF之Misc杂项干货
- 【谭浩强C程序设计精讲 chap4】选择结构程序设计
- 何时为 SEO 创建本地化文件夹和页面
- office2010安装64位&32位解破版本安装步骤
- 虚幻UE 材质-进阶边界混合之距离场限制PDO范围
- uniapp上传图片功能怎么实现?
- Java异常篇----第二篇
- Github基础入门(2):github打不开?保姆级教程教你流畅使用GIthub
- 用BEVformer来卷自动驾驶-1