10-高并发-应用级缓存
缓存简介
缓存,是让数据更接近于使用者,目的是让访问速度更快。
工作机制是先从缓存中读取数据,如果没有,再从慢速设备上读取实际数据并同步到缓存。
那些经常读取的数据、频繁访问的数据、热点数据、I/O瓶颈数据、计算昂贵的数据、符合5分钟法则和局部性原理的数据都可以进行缓存。
如CPU→L1/L2/L3→内存→磁盘就是一个典型的例子,CPU需要数据时先从L1读取,如果没有找到,则查找L2/L3读取,如果没有,则到内存中查找,如果还没有,会到磁盘中查找。
还有比如用过Maven的读者都应该知道,加载依赖的时候,先从本机仓库找,再从本地服务器仓库找,最后到远程仓库服务器找。
另外还有京东的物流为什么那么快?他们在各地都有分仓库,如果该仓库有货物,那么送货的速度是非常快的。
缓存命中率
缓存命中率是从缓存中读取数据的次数与总读取次数的比率,命中率越高越好。
缓存命中率=从缓存中读取次数/〔总读取次数(从缓存中读取次数+从慢速设备上读取次数)〕。这是一个非常重要的监控指标,如果做缓存,则应通过监控这个指标来看缓存是否工作良好。
缓存回收策略
基于空间
基于空间指缓存设置了存储空间,如设置为10MB,当达到存储空间上限时,按照一定的策略移除数据。
基于容量
基于容量指缓存设置了最大大小,当缓存的条目超过最大大小时,按照一定的策略移除旧数据。
基于时间
TTL(Time To Live):存活期,即缓存数据从创建开始直到到期的一个时间段(不管在这个时间段内有没有被访问,缓存数据都将过期)。
TTI(Time To Idle):空闲期,即缓存数据多久没被访问后移除缓存的时间。
基于Java对象引用
- 软引用:如果一个对象是软引用,那么当JVM堆内存不足时,垃圾回收器可以回收这些对象。
软引用适合用来做缓存,从而当JVM堆内存不足时,可以回收这些对象腾出一些空间供强引用对象使用,从而避免OOM。 - 弱引用:当垃圾回收器回收内存时,如果发现弱引用,则将它立即回收。相对于软引用,弱引用有更短的生命周期。
注意:只有在没有其他强引用对象引用弱引用/软引用对象时,垃圾回收时才回收该引用。
即如果有一个对象(不是弱引用/软引用对象)引用了弱引用/软引用对象,那么垃圾回收时不会回收该弱引用/软引用对象。
回收算法
使用基于空间和基于容量的缓存会使用一定的策略移除旧数据,常见的如下。FIFO(First In First Out):先进先出算法,即先放入缓存的先被移除。
LRU(Least Recently Used):最近最少使用算法,使用时间距离现在最久的那个被移除。
LFU(Least Frequently Used):最不常用算法,一定时间段内使用次数(频率)最少的那个被移除。
实际应用中基于LRU的缓存居多,如Guava Cache、Ehcache支持LRU。
Java缓存类型
堆缓存
使用Java堆内存来存储缓存对象。使用堆缓存的好处是没有序列化/反序列化,是最快的缓存。缺点也很明显,当缓存的数据量很大时,GC(垃圾回收)暂停时间会变长,存储容量受限于堆空间大小。一般通过软引用/弱引用来存储缓存对象,即当堆内存不足时,可以强制回收这部分内存释放堆内存空间。一般使用堆缓存存储较热的数据。可以使用Guava Cache、Ehcache 3.x、MapDB实现。
堆外缓存
即缓存数据存储在堆外内存,可以减少GC暂停时间(堆对象转移到堆外,GC扫描和移动的对象变少了),可以支持更大的缓存空间(只受机器内存大小限制,不受堆空间的影响)。但是,读取数据时需要序列化/反序列化,因此会比堆缓存慢很多。
磁盘缓存
即缓存数据存储在磁盘上,在JVM重启时数据还是存在的,而堆缓存/堆外缓存数据会丢失,需要重新加载。可以使用Ehcache 3.x、MapDB实现。
分布式缓存
上文提到的缓存是进程内缓存和磁盘缓存,在多JVM实例的情况下。会存在两个问题:
- 单机容量问题;
- 数据一致性问题(多台JVM实例的缓存数据不一致怎么办?),不过,这个问题不用太纠结,既然数据允许缓存,则表示允许一定时间内的不一致,因此可以设置缓存数据的过期时间来定期更新数据;
- 缓存不命中时,需要回源到DB/服务请求多变问题:每个实例在缓存不命中的情况下都会回源到DB加载数据,因此,多实例后DB整体的访问量就变多了,解决办法是可以使用如一致性哈希分片算法。
这些情况可以考虑使用分布式缓存来解决。可以使用ehcache-clustered(配合Terracotta server)实现Java进程间分布式缓存。
当然也可以使用如Redis实现分布式缓存。
- 单机时:存储最热的数据到堆缓存,相对热的数据到堆外缓存,不热的数据到磁盘缓存。
- 集群时:存储最热的数据到堆缓存,相对热的数据到堆外缓存,全量数据到分布式缓存。
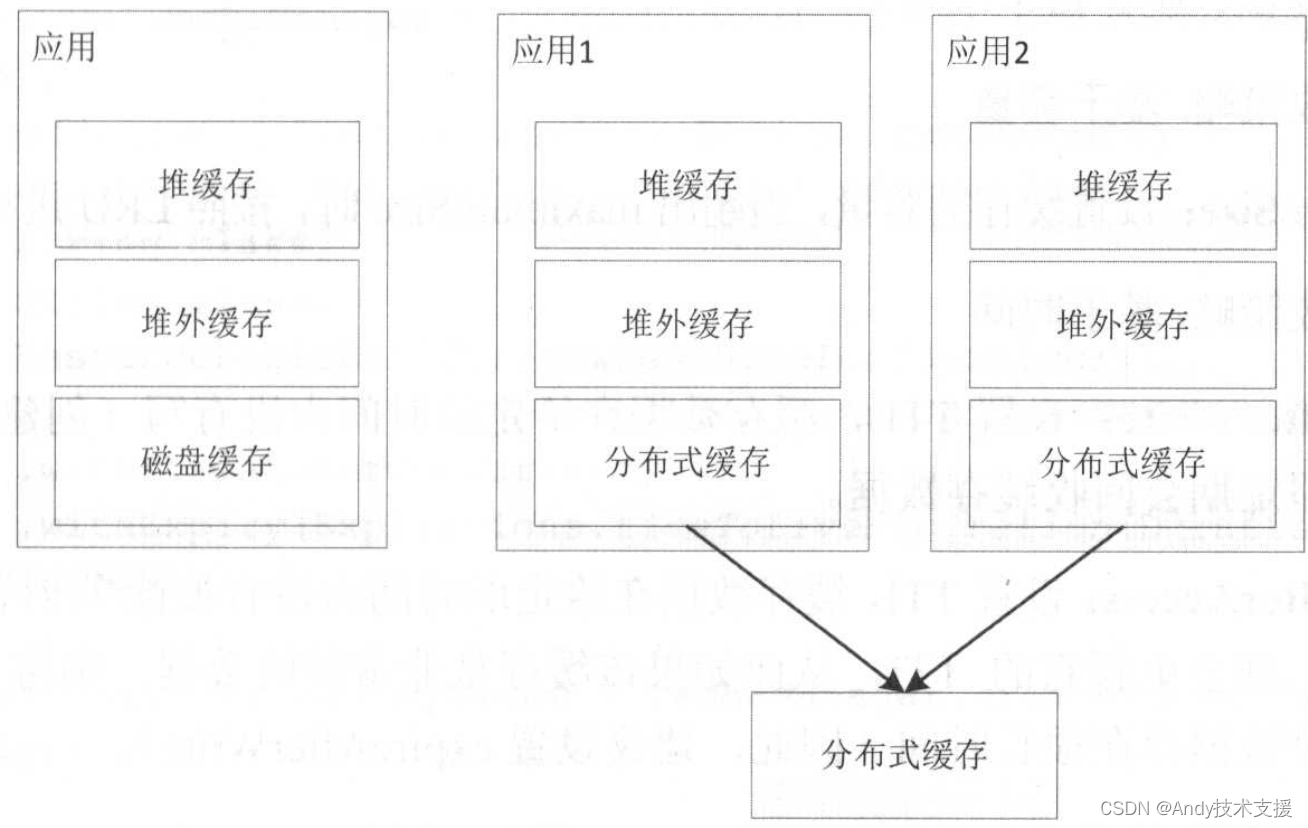
Guava Cache只提供堆缓存,小巧灵活,性能最好,如果只使用堆缓存,那么使用它就够了。
Ehcache 3.x提供了堆缓存、堆外缓存、磁盘缓存、分布式缓存。但是,其代码注释比较少,API还不完善(比如,2.x支持LRU、LFU、FIFO,而3.x目前还没有API设置),功能还不完善(比如,集群情况下,个人测试结果是暂时不可以在生产环境使用),如果需要较稳定的API和功能,则请考虑使用Ehcache 2.x(不支持堆外缓存)。
MapDB是一款嵌入式Java数据库引擎和集合框架。提供了Maps、Sets、Lists、Queues、Bitmaps的支持,还支持ACID事务、增量备份。支持堆缓存、堆外缓存、磁盘缓存。
缓存使用模式
有人已总结出一些缓存使用模式/模板,我们在使用时直接照搬模式即可。确实已经有总结好的模式,主要分两大类:Cache-Aside和Cache-As-SoR(Read-through、Write-through、Write-behind)。
介绍三个名词:
- SoR(system-of-record):记录系统,或者可以叫做数据源,即实际存储原始数据的系统。
- Cache:缓存,是SoR的快照数据,Cache的访问速度比SoR要快,放入Cache的目的是提升访问速度,减少回源到SoR的次数。
- 回源:即回到数据源头获取数据,Cache没有命中时,需要从SoR读取数据,这叫做回源。
Cache-Aside
Cache-Aside即业务代码围绕着Cache写,是由业务代码直接维护缓存。
对于Cache-Aside,可能存在并发更新情况,即如果多个应用实例同时更新,那么缓存怎么办?
- 如果是用户维度的数据(如订单数据、用户数据),这种几率非常小,因为并发的情况很少,可以不考虑这个问题,加上过期时间来解决即可。
- 对于如商品这种基础数据,可以考虑使用canal订阅binlog,来进行增量更新分布式缓存,这样不会存在缓存数据不一致的情况。但是,缓存更新会存在延迟。而本地缓存可根据不一致容忍度设置合理的过期时间。
- 读服务场景,可以考虑使用一致性哈希,将相同的操作负载均衡到同一个实例,从而减少并发几率,或者设置比较短的过期时间。
Cache-As-SoR
Cache-As-SoR即把Cache看作为SoR,所有操作都是对Cache进行,然后Cache再委托给SoR进行真实的读/写。
即业务代码中只看到Cache的操作,看不到关于SoR相关的代码。有三种实现:read-through、write-through、write-behind。
Read-Through
Read-Through,业务代码首先调用Cache,如果Cache不命中由Cache回源到SoR,而不是业务代码(即由Cache读SoR)。使用Read-Through模式,需要配置一个CacheLoader组件用来回源到SoR加载源数据。Guava Cache和Ehcache 3.x都支持该模式。
Write-Through
Write-Through,被称为穿透写模式/直写模式——业务代码首先调用Cache写(新增/修改)数据,然后由Cache负责写缓存和写SoR,而不是由业务代码。
使用Write-Through模式需要配置一个CacheWriter组件用来回写SoR。Guava Cache没有提供支持。Ehcache
3.x支持该模式。Ehcache需要配置一个CacheLoaderWriter,CacheLoaderWriter知道如何去写SoR。当Cache需要写(新增/修改)数据时,首先调用CacheLoaderWriter来(立即)同步到SoR,成功后会更新缓存。
Write-Behind
Write-Behind,也叫Write-Back,我们称之为回写模式。
不同于Write-Through是同步写SoR和Cache,Write-Behind是异步写。异步之后可以实现批量写、合并写、延时和限流。
Copy Pattern
有两种Copy Pattern,Copy-On-Read(在读时复制)和Copy-On-Write(在写时复制),在Guava Cache和Ehcache中堆缓存都是基于引用的,这样如果有人拿到缓存数据并修改了它,则可能发生不可预测的问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!