【GNN】经典GNN的数学原理之美
?
目录
引言
本文将流行的图神经网络及其数学细微差别的进行详细的梳理和解释,图深度学习背后的思想是学习具有节点和边的图的结构和空间特征,这些节点和边表示实体及其交互。
背景?
图深度学习(Graph Deep Learning) 多年来一直在加速发展。许多现实生活问题使GDL成为万能工具:在社交媒体、药物发现、芯片植入、预测、生物信息学等方面都显示出了很大的前景。
本文将流行的图神经网络及其数学细微差别的进行详细的梳理和解释,图深度学习背后的思想是学习具有节点和边的图的结构和空间特征,这些节点和边表示实体及其交互。
?图
在我们进入图神经网络之前,让我们先来探索一下计算机科学中的图是什么。
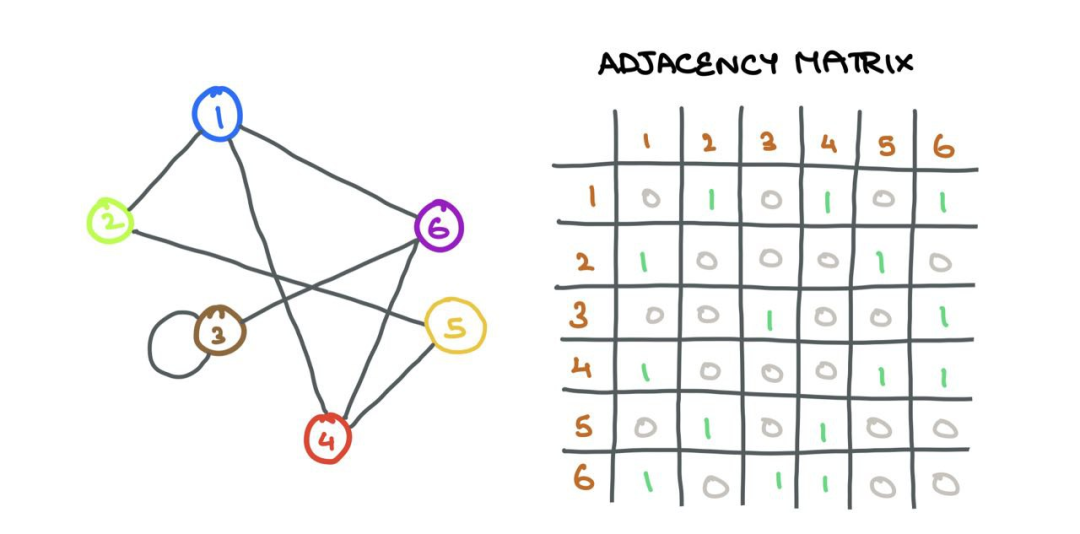
图G(V,E)是包含一组顶点(节点)i∈v和一组连接顶点i和j的边eij∈E的数据结构,如果连接两个节点i和j,则eij=1,否则eij=0。可以将连接信息存储在邻接矩阵A中:
我假设本文中的图是无加权的(没有边权值或距离)和无向的(节点之间没有方向关联),并且假设这些图是同质的(单一类型的节点和边;相反的是“异质”)。
图与常规数据的不同之处在于,它们具有神经网络必须尊重的结构;不利用它就太浪费了。下面的图是一个社交媒体图的例子,节点是用户,边是他们的互动(比如关注/点赞/转发)。

与图像的连接
对于图像来说,图像本身就是一个图!这是一种叫做“网格图”的特殊变体,其中对于所有内部节点和角节点,来自节点的外向边的数量是恒定的。在图像网格图中存在一些一致的结构,允许对其执行简单的类似卷积的操作。
图像可以被认为是一种特殊的图,其中每个像素都是一个节点,并通过虚线与周围的其他像素连接。当然,以这种方式查看图像是不切实际的,因为这意味着需要一个非常大的图。例如,32×32×3的一个简单的CIFAR-10图像会有3072个节点和1984条边。对于224×224×3的较大ImageNet图像,这些数字会更大。
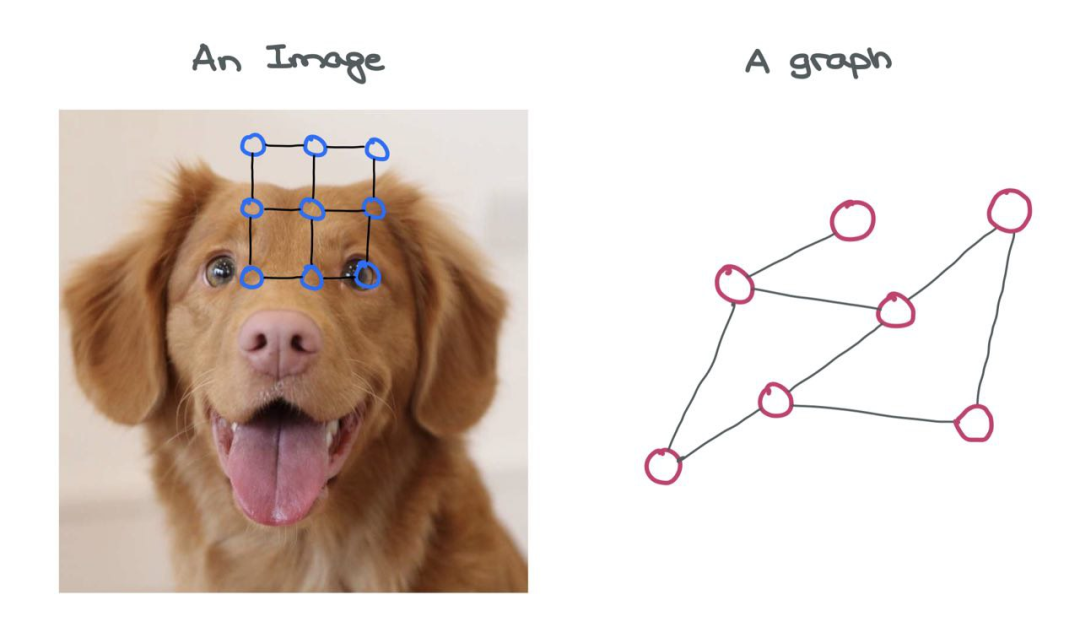
与图片相比,图的不同的节点与其他节点的连接数量不同,并且没有固定的结构,但是就是这种结构为图增加了价值。
图神经网络
单个图神经网络(GNN)层有一堆步骤,在图中的每个节点上会执行:
-
消息传递
-
聚合
-
更新
这些组成了对图形进行学习的构建块,GDL的创新都是在这3个步骤的进行的改变。
节点
节点表示一个实体或对象,如用户或原子。因此节点具有所表示实体的一系列属性。这些节点属性形成了节点的特征(即“节点特征”或“节点嵌入”)。
通常,这些特征可以用Rd中的向量表示. 这个向量要么是潜维嵌入,要么是以每个条目都是实体的不同属性的方式构造的。
例如,在社交媒体图中,用户节点具有可以用数字表示的年龄、性别、政治倾向、关系状态等属性。在分子图中,原子节点可能具有化学性质,如对水的亲和力、力、能量等,也可以用数字表示。
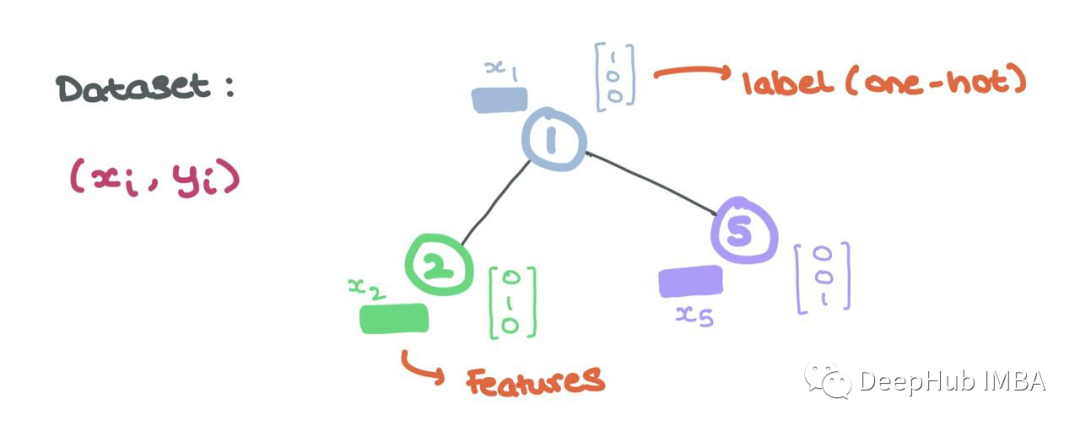
这些节点特征是GNN的输入,每个节点i具有关联的节点特征xi∈Rd和标签yi(可以是连续的,也可以是离散的,就像单独编码一样)。
边
边也可以有特征aij∈Rd '例如,在边缘有意义的情况下(如原子之间的化学键)。我们可以把下面的分子想象成一个图,其中原子是节点,键是边。虽然原子节点本身有各自的特征向量,但边可以有不同的边特征,编码不同类型的键(单键、双键、三键)。不过为了简单起见,在本文中我将省略边的特性。
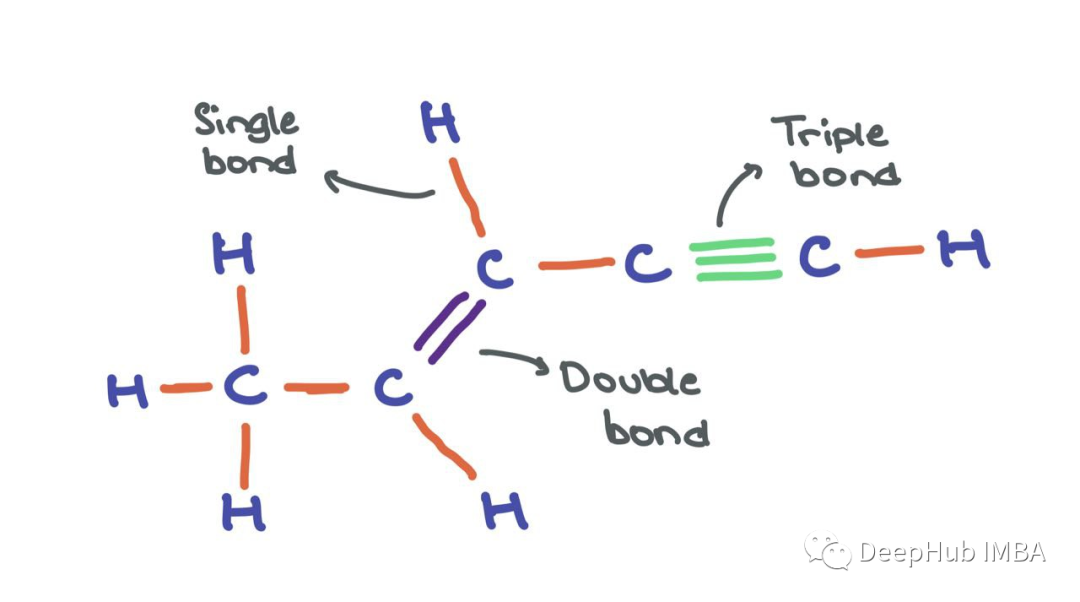
现在我们知道了如何在图中表示节点和边,让我们从一个具有一堆节点(具有节点特征)和边的简单图开始。
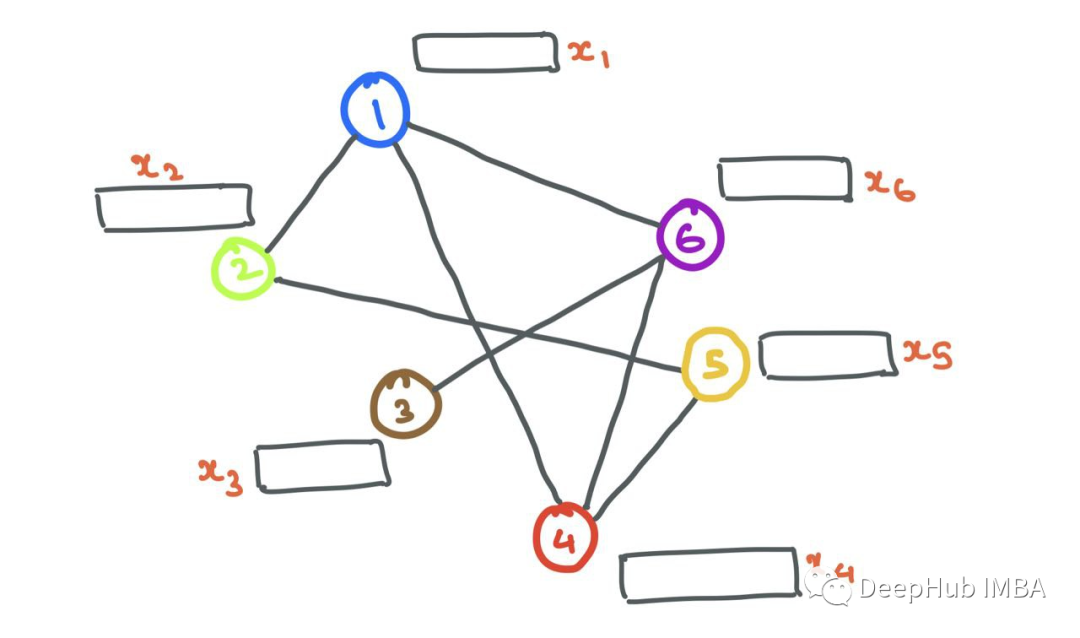
消息传递
gnn以其学习结构信息的能力而闻名。通常,具有相似特征或属性的节点相互连接(比如在社交媒体中)。GNN利用学习特定节点如何以及为什么相互连接,GNN会查看节点的邻域。
邻居Ni,节点I的集合定义为通过边与I相连的节点j的集合。形式为Ni={j: eij∈E}。
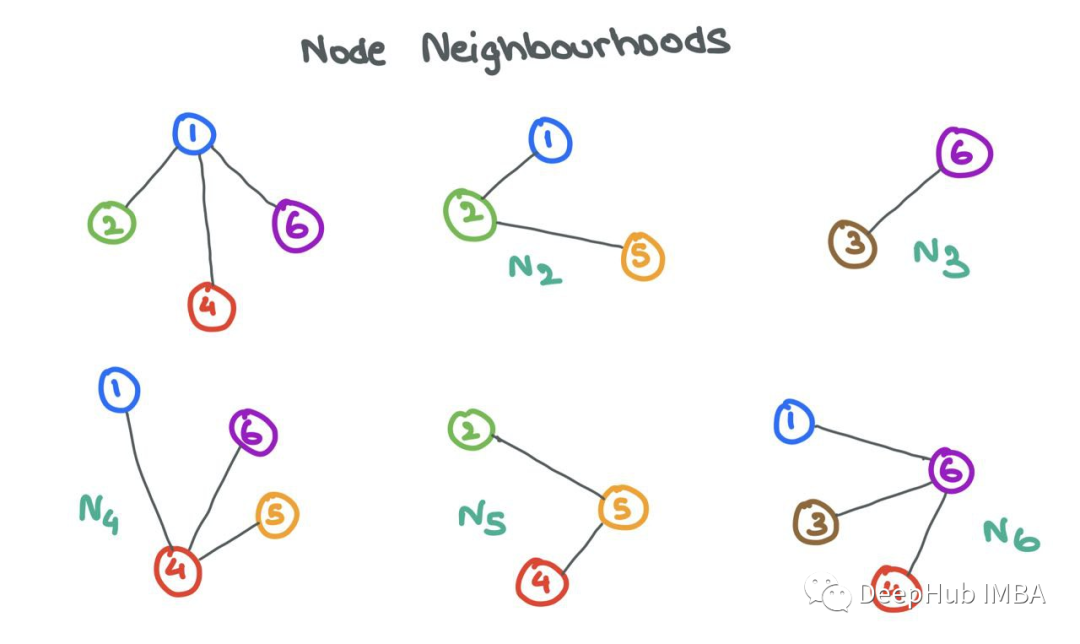
一个人被他所处的圈子所影响。类似地GNN可以通过查看其邻居Ni中的节点i来了解很多关于节点i的信息。为了在源节点i和它的邻居节点j之间实现这种信息共享,gnn进行消息传递。
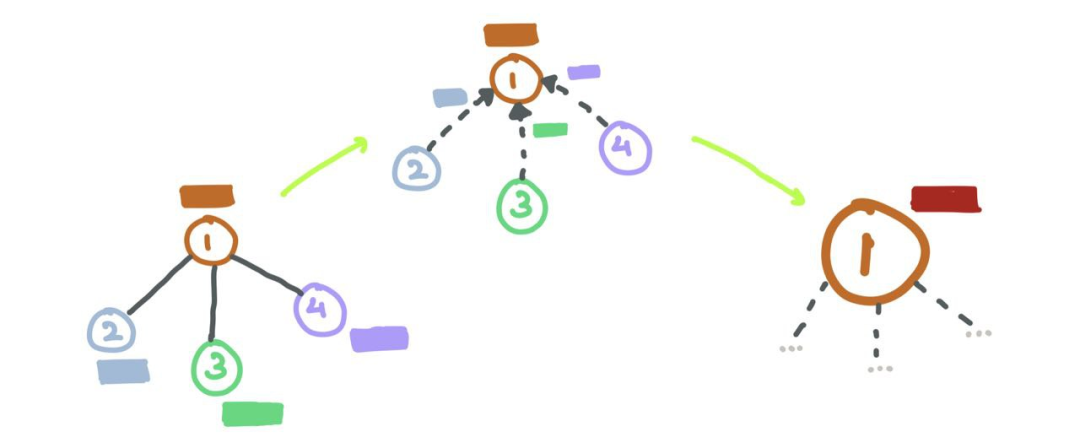
对于GNN层,消息传递被定义为获取邻居的节点特征,转换它们并将它们“传递”给源节点的过程。对于图中的所有节点,并行地重复这个过程。这样,在这一步结束时,所有的邻域都将被检查。
让我们放大节点6并检查邻域N6={1,3,4}。我们取每个节点特征x1、x3和x4,用函数F对它们进行变换,函数F可以是一个简单的神经网络(MLP或RNN),也可以是仿射变换F(xj)=Wj?xj+b。简单地说,“消息”是来自源节点的转换后的节点特征。

F 可以是简单的仿射变换或神经网络。现在我们设F(xj)=Wj?xj为了方便计算 ? 表示简单的矩阵乘法。
聚合
现在我们有了转换后的消息{F(x1),F(x3),F(x4)}传递给节点6,下面就必须以某种方式聚合(“组合”)它们。有很多方法可以将它们结合起来。常用的聚合函数包括:
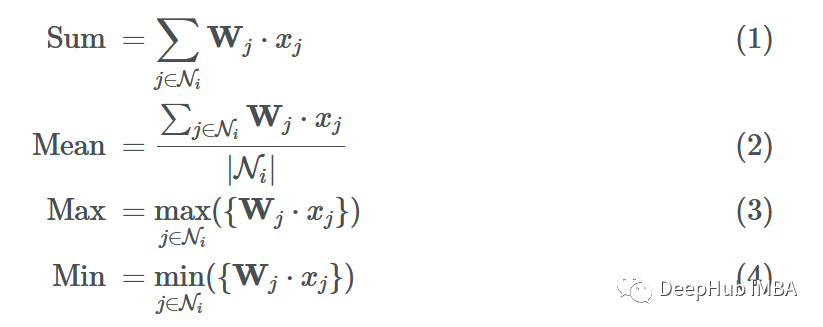
假设我们使用函数G来聚合邻居的消息(使用sum、mean、max或min)。最终聚合的消息可以表示为:
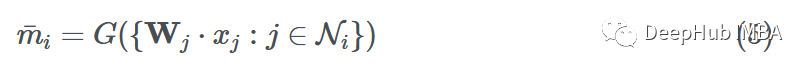
更新
使用这些聚合消息,GNN层就要更新源节点i的特性。在这个更新步骤的最后,节点不仅应该知道自己,还应该知道它的邻居。这是通过获取节点i的特征向量并将其与聚合的消息相结合来操作的,一个简单的加法或连接操作就可以解决这个问题。
使用加法:

其中σ是一个激活函数(ReLU, ELU, Tanh), H是一个简单的神经网络(MLP)或仿射变换,K是另一个MLP,将加法的向量投影到另一个维度。
使用连接:
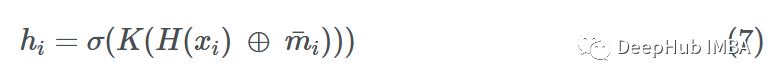
为了进一步抽象这个更新步骤,我们可以将K看作某个投影函数,它将消息和源节点嵌入一起转换:

初始节点特征称为xi,在经过第一GNN层后,我们将节点特征变为hi。假设我们有更多的GNN层,我们可以用hli表示节点特征,其中l是当前GNN层索引。同样,显然h0i=xi(即GNN的输入)。
整合在一起
现在我们已经完成了消息传递、聚合和更新步骤,让我们把它们放在一起,在单个节点i上形成单个GNN层:

这里我们使用求和聚合和一个简单的前馈层作为函数F和H。设hi∈Rd, W1,W2?Rd ' ×d其中d '为嵌入维数。
使用邻接矩阵
到目前为止,我们通过单个节点i的视角观察了整个GNN正向传递,当给定整个邻接矩阵a和X?RN×d中所有N=∥V∥节点特征时,知道如何实现GNN正向传递也很重要。
在 MLP 前向传递中,我们想要对特征向量 xi 中的项目进行加权。这可以看作是节点特征向量 xi∈Rd 和参数矩阵 W?Rd′×d 的点积,其中 d′ 是嵌入维度:

如果我们想对数据集中的所有样本(矢量化)这样做,我们只需将参数矩阵和特征矩阵相乘,就可以得到转换后的节点特征(消息):
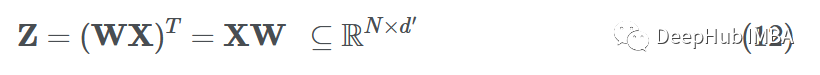
在gnn中,对于每个节点i,消息聚合操作包括获取相邻节点特征向量,转换它们,并将它们相加(在和聚合的情况下)。
单行Ai对于Aij=1的每个指标j,我们知道节点i和j是相连的→eij∈E。例如,如果A2=[1,0,1,1,0],我们知道节点2与节点1、3和4连接。因此,当我们将A2与Z=XW相乘时,我们只考虑列1、3和4,而忽略列2和5:
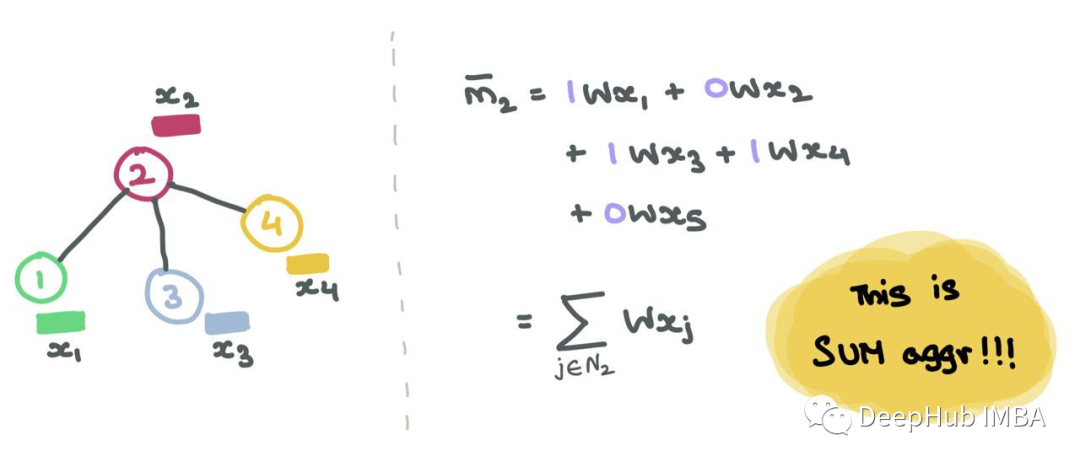
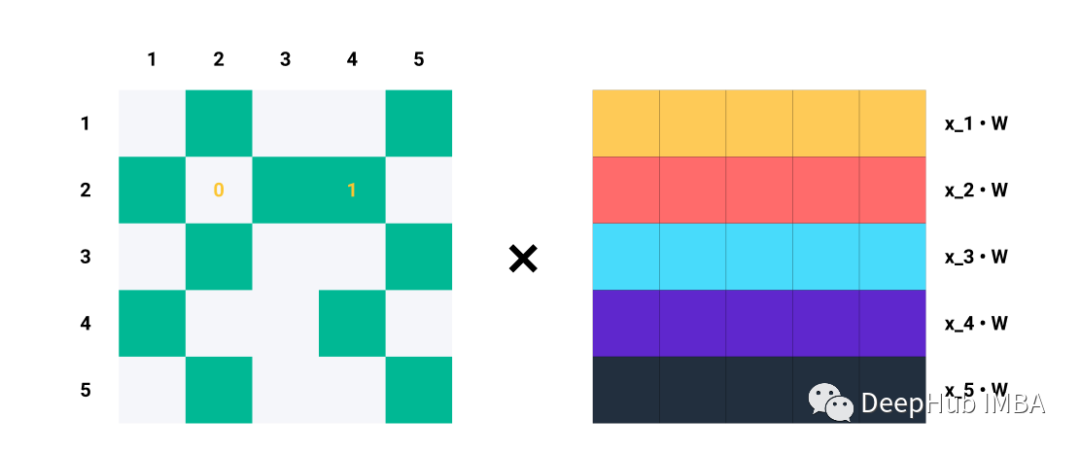
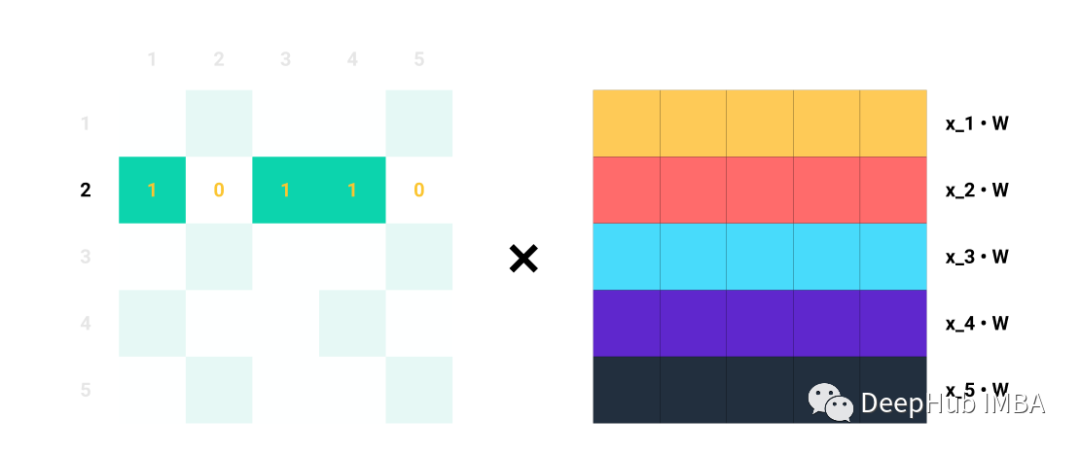
比如说A的第二行。
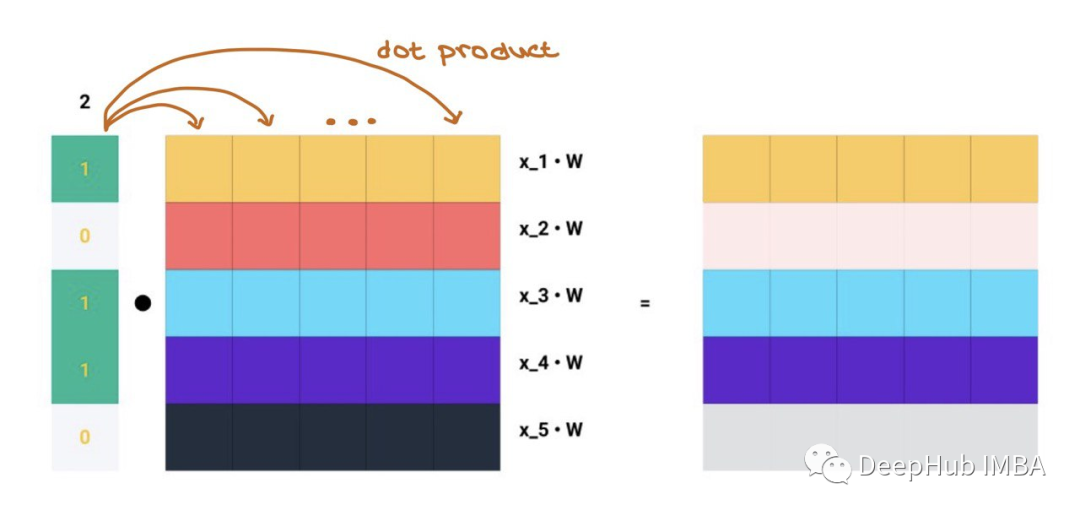
矩阵乘法就是A中的每一行与Z中的每一列的点积,这就是消息聚合的含义!!
获取所有N的聚合消息,根据图中节点之间的连接,将整个邻接矩阵A与转换后的节点特征进行矩阵乘法:

但是这里有一个小问题:观察到聚合的消息没有考虑节点i自己的特征向量(正如我们上面所做的那样)。所以我们将自循环添加到A(每个节点i连接到自身)。
这意味着对角线的而数值需要进行修改,用一些线性代数,我们可以用单位矩阵来做这个!


添加自循环可以允许GNN将源节点的特征与其邻居节点的特征一起聚合!!
有了这些,你就可以用矩阵而不是单节点来实现GNN的传递。
?要执行平均值聚合(mean),我们可以简单地将总和除以1,对于上面的例子,由于A2=[1,0,0,1,1]中有三个1,我们可以将∑j∈N2Wxj除以3,但是用gnn的邻接矩阵公式来实现最大(max)和最小聚合(min)是不可能的。
GNN层堆叠
上面我们已经介绍了单个GNN层是如何工作的,那么我们如何使用这些层构建整个“网络”呢?信息如何在层之间流动,GNN如何细化节点(和/或边)的嵌入/表示?
-
第一个GNN层的输入是节点特征X?RN×d。输出是中间节点嵌入H1?RN×d1,其中d1是第一个嵌入维度。H1由h1i: 1→N∈Rd1组成。
-
H1是第二层的输入。下一个输出是H2?RN×d2,其中d2是第二层的嵌入维度。同理,H2由h2i: 1→N∈Rd2组成。
-
经过几层之后,在输出层L,输出是HL?RN×dL。最后,HL由hLi: 1→N∈RdL构成。
这里的{d1,d2,…,dL}的选择完全取决于我们,可以看作是GNN的超参数。把这些看作是为MLP层选择单位(“神经元”的数量)。
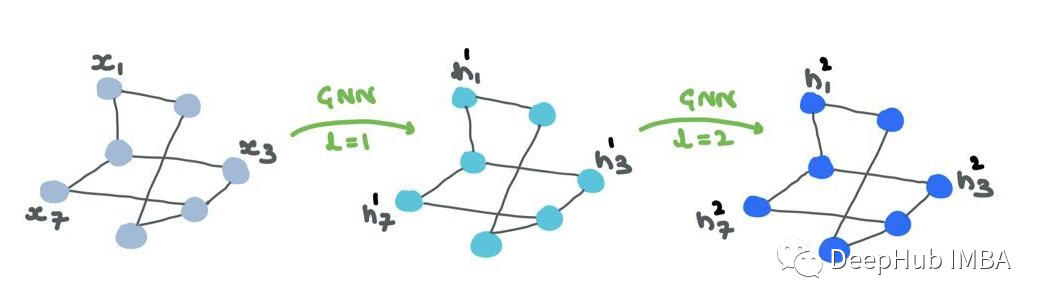
节点特征/嵌入(“表示”)通过GNN传递。虽然结构保持不变,但节点表示在各个层中不断变化。边表示也将改变,但不会改变连接或方向。
HL也可以做一些事情:
我们可以沿着第一个轴(即∑Nk=1hLk)将其相加,得到RdL中的向量。这个向量是整个图的最新维度表示。它可以用于图形分类(例如:这是什么分子?)
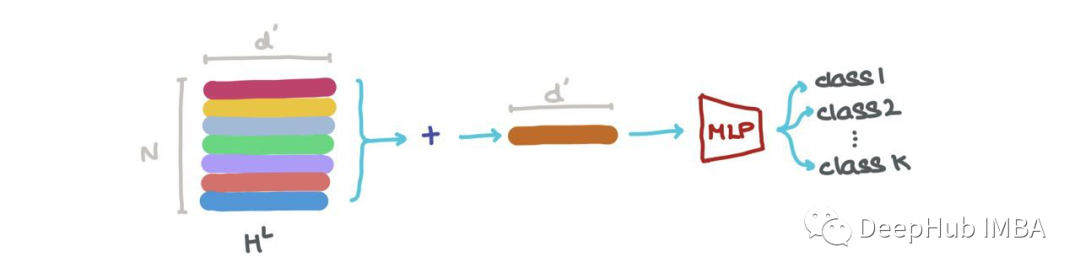
我们可以在HL中连接向量(即?Nk=1hk,其中⊕是向量连接操作),并将其传递给一个Graph Autoencoder。当输入图有噪声或损坏,而我们想要重建去噪图时,就需要这个操作。
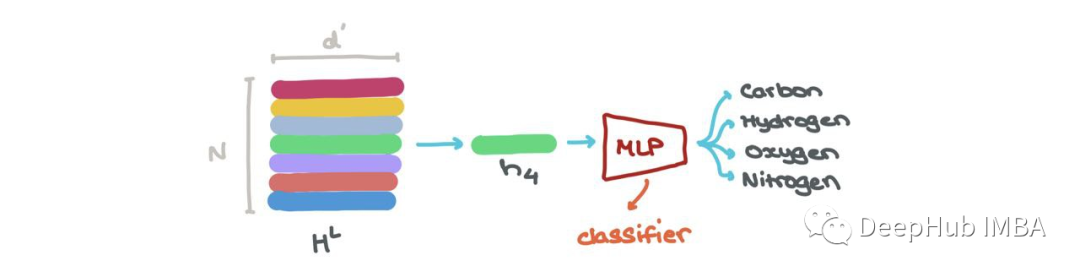
我们可以做节点分类→这个节点属于什么类?在特定索引hLi (i:1→N)处嵌入的节点可以通过分类器(如MLP)分为K个类(例如:这是碳原子、氢原子还是氧原子?)
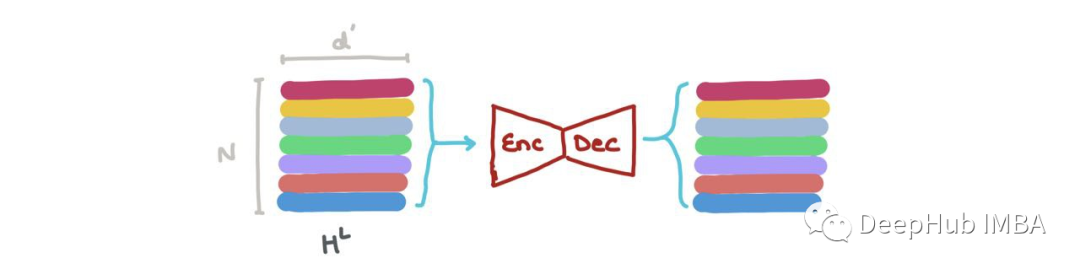
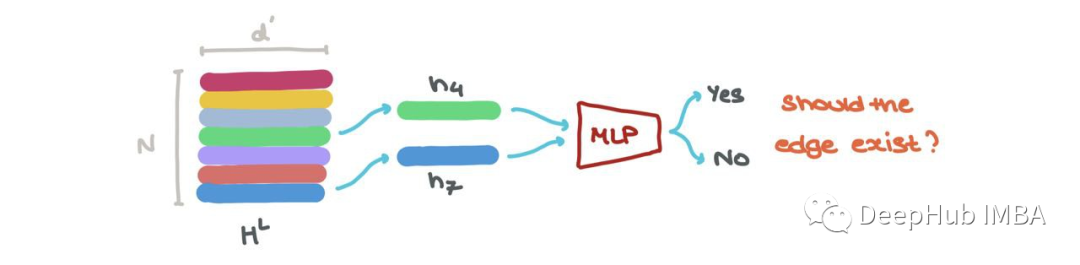
我们还可以进行链接预测→某个节点i和j之间是否存在链接?hLi和hLj的节点嵌入可以被输入到另一个基于sigmoid的MLP中,该MLP输出这些节点之间存在边的概率。
这些就是GNN在不同的应用中所进行的操作,无论哪种方式,每个h1→N∈HL都可以被堆叠,并被视为一批样本。我们可以很容易地将其视为批处理。
对于给定的节点i, GNN聚合的第l层具有节点i的l跳邻域。节点看到它的近邻,并深入到网络中,它与邻居的邻居交互。
这就是为什么对于非常小、稀疏(很少边)的图,大量的GNN层通常会导致性能下降:因为节点嵌入都收敛到一个向量,因为每个节点都看到了许多跳之外的节点。对于小的图,这是没有任何作用的。
这也解释了为什么大多数GNN论文在实验中经常使用≤4层来防止网络出现问题。
以节点分类为例训练GNN。
在训练期间,对节点、边或整个图的预测可以使用损失函数(例如:交叉熵)与来自数据集的ground-truth标签进行比较。也就是说gnn能够使用反向传播和梯度下降以端到端方式进行训练。
训练和测试数据
与常规ML一样,图数据也可以分为训练和测试。这有两种方法:
1、Transductive
训练数据和测试数据都在同一个图中。每个集合中的节点相互连接。只是在训练期间,测试节点的标签是隐藏的,而训练节点的标签是可见的。但所有节点的特征对于GNN都是可见的。
我们可以对所有节点进行二进制掩码(如果一个训练节点i连接到一个测试节点j,只需在邻接矩阵中设置Aij=0)。
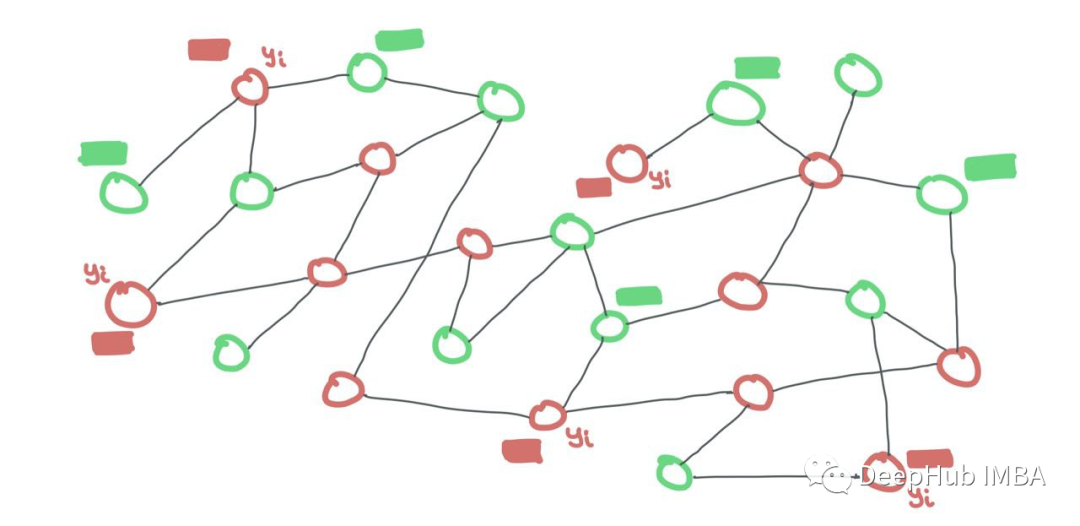
训练节点和测试节点都是同一个图的一部分。训练节点暴露它们的特征和标签,而测试节点只暴露它们的特征。测试标签对模型隐藏。二进制掩码需要告诉GNN什么是训练节点,什么是测试节点。
2、Inductive
另外一种方法是单独的训练图和测试图。这类似于常规的ML,其中模型在训练期间只看到特征和标签,并且只看到用于测试的特征。训练和测试在两个独立的图上进行。这些测试图分布在外,可以检查训练期间的泛化质量。
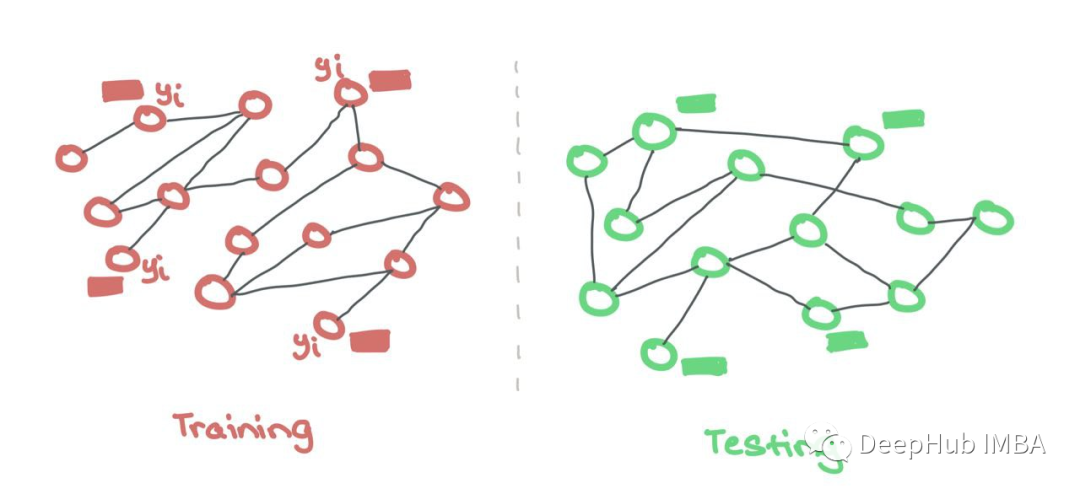
与常规ML一样,训练数据和测试数据是分开保存的。GNN只使用来自训练节点的特征和标签。这里不需要二进制掩码来隐藏测试节点,因为它们来自不同的集合。
反向传播和梯度下降
在训练过程中,一旦我们向前通过GNN,我们就得到了最终的节点表示hLi∈HL, 为了以端到端方式训练,可以做以下工作:
-
将每个hLi输入MLP分类器,得到预测^yi;
-
使用ground-truth yi和预测yi→J(yi,yi)计算损失;
-
使用反向传播来计算?J/?Wl,其中Wl是来自l层的参数矩阵;
-
使用优化器更新GNN中每一层的参数Wl;
-
(如果需要)还可以微调分类器(MLP)网络的权重。
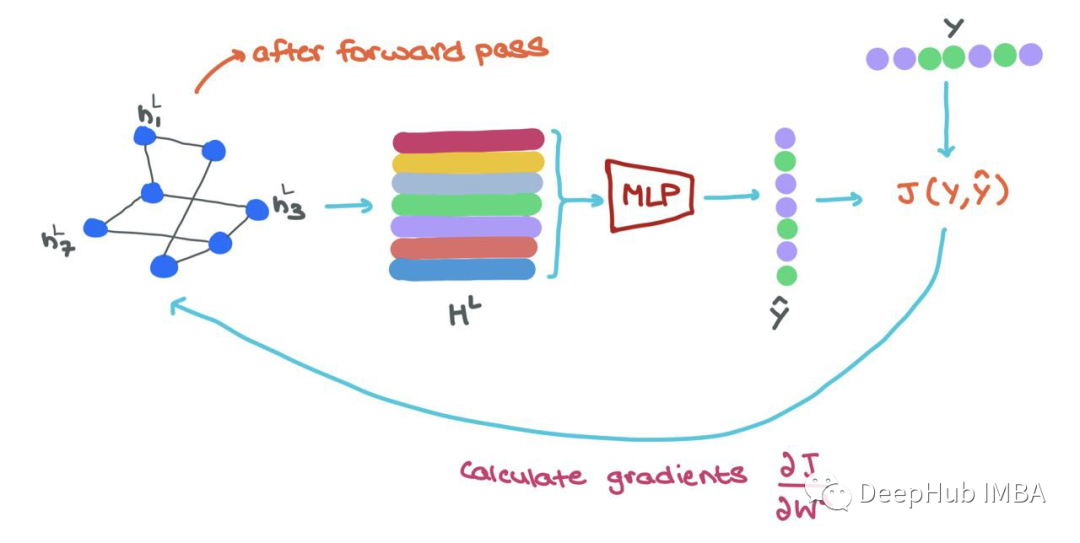
🥳这意味着gnn在消息传递和训练方面都很容易并行。整个过程可以矢量化(如上所示),并在gpu上执行!!
流行图神经网络总结
上面我们介绍完了古神经网络的基本流程,下面我们总结一下流行图神经网络,并将它们的方程和数学分为上面提到的3个GNN步骤。许多体系结构将消息传递和聚合步骤合并到一起执行的一个函数中,而不是显式地一个接一个执行,但为了数学上的方便,我们将尝试分解它们并将它们视为一个单一的操作!
1、消息传递神经网络
https://arxiv.org/abs/1704.01212
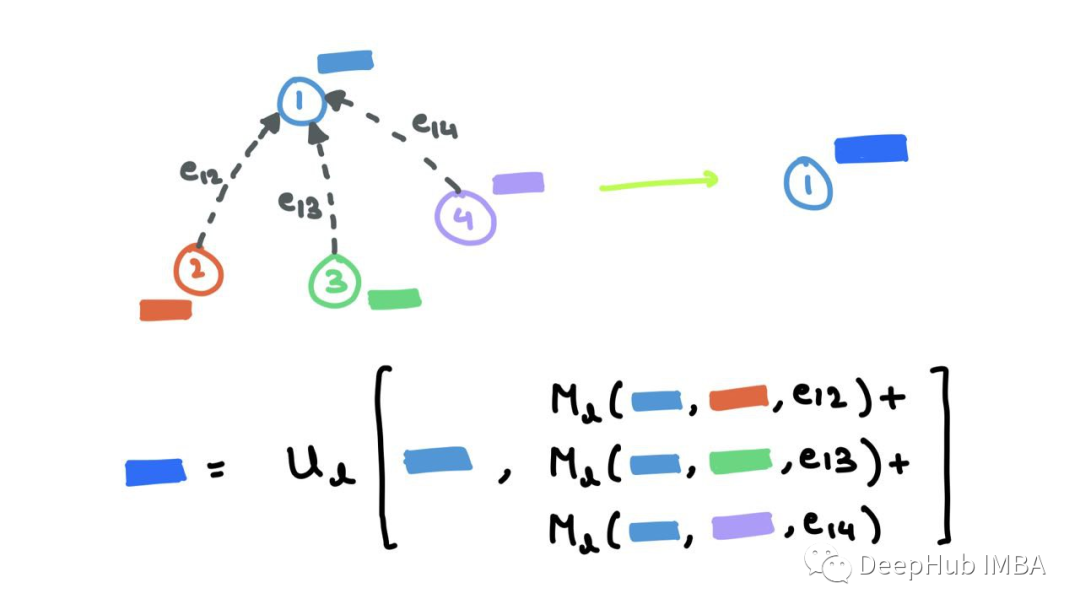
消息传递神经网络(MPNN)将正向传播分解为具有消息函数Ml的消息传递阶段和具有顶点更新函数Ul的读出阶段。
MPNN将消息传递和聚合步骤合并到单个消息传递阶段:
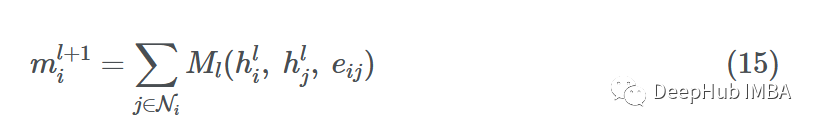
读取阶段是更新步骤:

其中ml+1v是聚合的消息,hl+1v是更新的节点嵌入。这与我上面提到的过程非常相似。消息函数Ml是F和G的混合,函数Ul是k,其中eij表示可能的边缘特征,也可以省略。
2、图卷积
https://arxiv.org/abs/1609.02907
图卷积网络(GCN)论文以邻接矩阵的形式研究整个图。在邻接矩阵中加入自连接,确保所有节点都与自己连接以得到~A。这确保在消息聚合期间考虑源节点的嵌入。合并的消息聚合和更新步骤如下所示:

其中Wl是一个可学习参数矩阵。这里将X改为H,以泛化任意层l上的节点特征,其中H0=X。
由于矩阵乘法的结合律(A(BC)=(AB)C),我们在哪个序列中乘矩阵并不重要(要么是~AHl先乘,然后是Wl后乘,要么是HlWl先乘,然后是~A)。作者Kipf和Welling进一步引入了度矩阵~D作为"renormalisation"的一种形式,以避免数值不稳定和爆炸/消失的梯度:

“renormalisation”是在增广邻接矩阵^A=D?12A~D?12上进行的。新的合并消息传递和更新步骤如下所示:

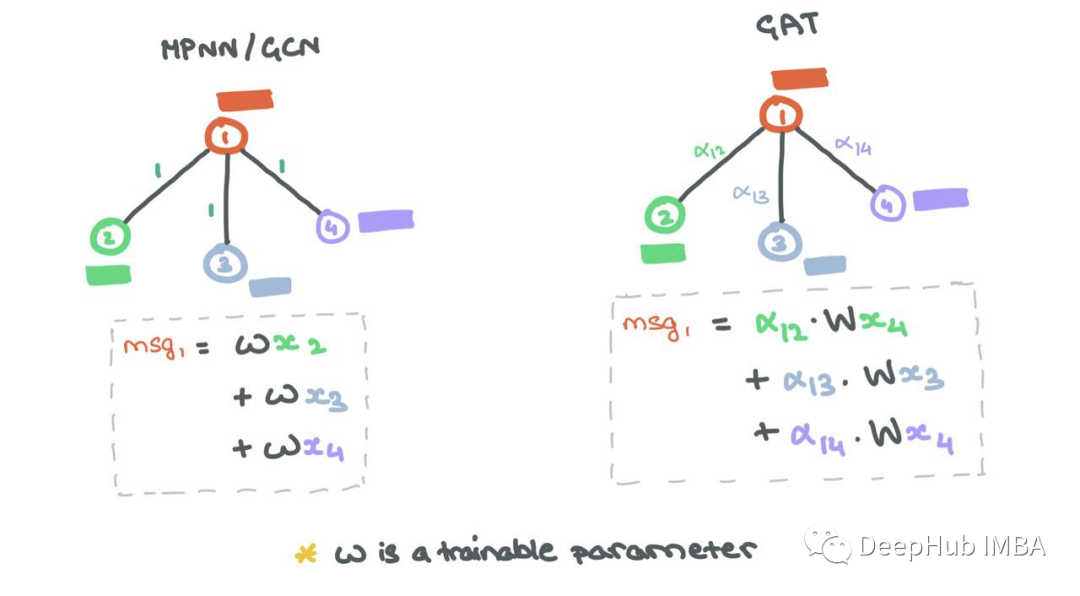
3、图注意力网络
https://arxiv.org/abs/1710.10903
聚合通常涉及在和、均值、最大值和最小值设置中平等对待所有邻居。但是在大多数情况下,一些邻居比其他邻居更重要。图注意力网络(GAT)通过使用Vaswani等人(2017)的Self-Attention对源节点及其邻居之间的边缘进行加权来确保这一点。
边权值αij如下。
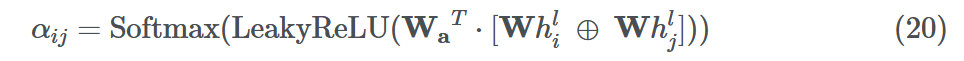
这里的Wa∈R2d '和W?Rd ' ×d为学习参数,d '为嵌入维数,⊕是向量拼接运算。
虽然最初的消息传递步骤与MPNN/GCN相同,但合并的消息聚合和更新步骤是所有邻居和节点本身的加权和:
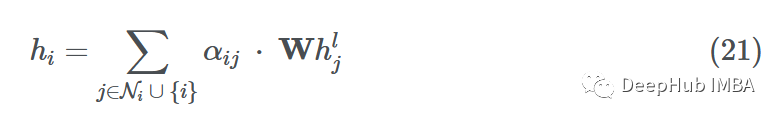
边缘重要性加权有助于了解邻居对源节点的影响程度。与GCN一样,添加了自循环,因此源节点可以将自己的表示形式考虑到未来的表示形式中。
4、GraphSAGE
https://arxiv.org/abs/1706.02216
GraphSAGE:Graph SAmple and AggreGatE。这是一个为大型、非常密集的图形生成节点嵌入的模型。
这项工作在节点的邻域上引入了学习聚合器。不像传统的gat或GCNs考虑邻居中的所有节点,GraphSAGE统一地对邻居进行采样,并对它们使用学习的聚合器。
假设我们在网络(深度)中有L层,每一层L∈{1,…,L}查看一个更大的L跳邻域w.r.t.源节点。然后在通过MLP的F和非线性σ传递之前,通过将节点嵌入与采样消息连接来更新每个源节点。
对于某一层l
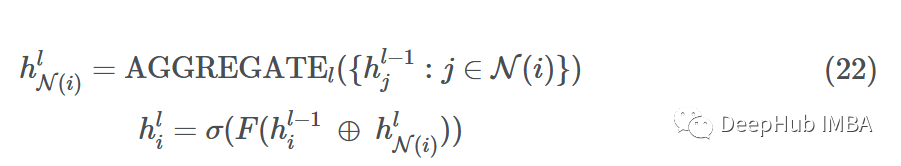
其中⊕是向量拼接运算,N(i)是返回所有邻居的子集的统一抽样函数。如果一个节点有5个邻居{1,2,3,4,5},N(i)可能的输出将是{1,4,5}或{2,5}。

Aggregator ?k=1从1-hop邻域聚集采样节点(彩色),而Aggregator k=2从2 -hop邻域聚集采样节点(彩色)
论文中用K和K表示层指数。但在本文中分别使用L和L来表示,这是为了和前面的内容保持一致性。此外,论文用v表示源节点i,用u表示邻居节点j。
5、时间图网络
https://arxiv.org/abs/2006.10637
到目前为止所描述的网络工作在静态图上。大多数实际情况都在动态图上工作,其中节点和边在一段时间内被添加、删除或更新。时间图网络(TGN)致力于连续时间动态图(CTDG),它可以表示为按时间顺序排列的事件列表。
论文将事件分为两种类型:节点级事件和交互事件。节点级事件涉及一个孤立的节点(例如:用户更新他们的个人简介),而交互事件涉及两个可能连接也可能不连接的节点(例如:用户a转发/关注用户B)。
TGN提供了一种模块化的CTDG处理方法,包括以下组件:
-
消息传递函数→孤立节点或交互节点之间的消息传递(对于任何类型的事件)。
-
消息聚合函数→通过查看多个时间步长的时间邻域,而不是在给定时间步长的局部邻域,来使用GAT的聚合。
-
记忆更新→记忆(Memory)允许节点具有长期依赖关系,并表示节点在潜在(“压缩”)空间中的历史。这个模块根据一段时间内发生的交互来更新节点的内存。
-
时间嵌入→一种表示节点的方法,也能捕捉到时间的本质。
-
链接预测→将事件中涉及的节点的时间嵌入通过一些神经网络来计算边缘概率(即,边缘会在未来发生吗?)。在训练过程中,我们知道边的存在,所以边的标签是1,所以需要训练基于sigmoid的网络来像往常一样预测这个。
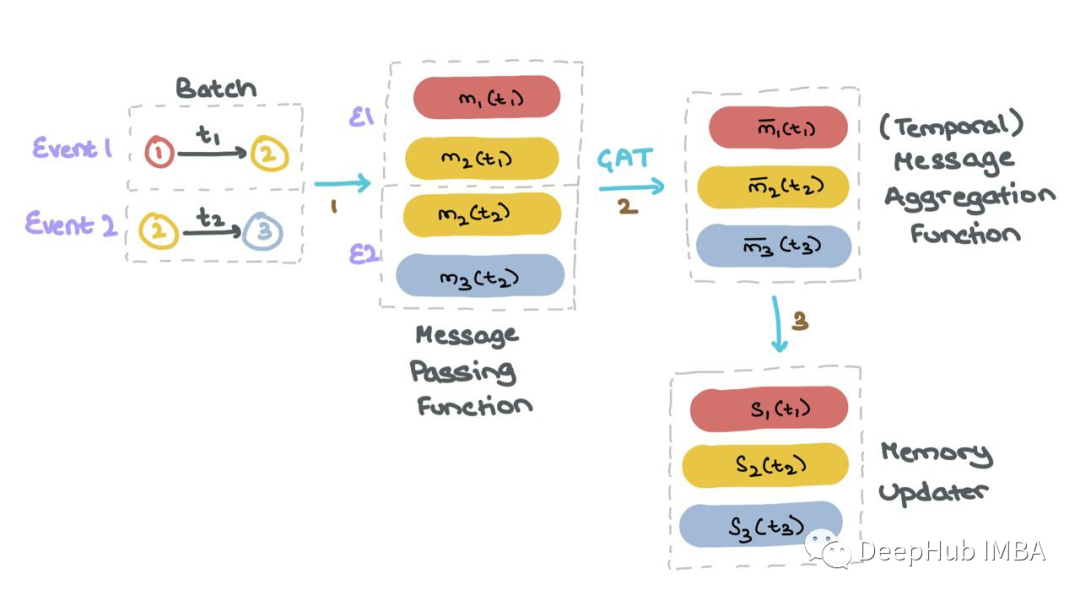
每当一个节点参与一个活动(节点更新或节点间交互)时,记忆就会更新。
对于批处理中的每个事件1和2,TGN为涉及该事件的所有节点生成消息。TGN聚合所有时间步长t的每个节点mi的消息;这被称为节点i的时间邻域。然后TGN使用聚合消息mi(t)来更新每个节点si(t)的记忆。
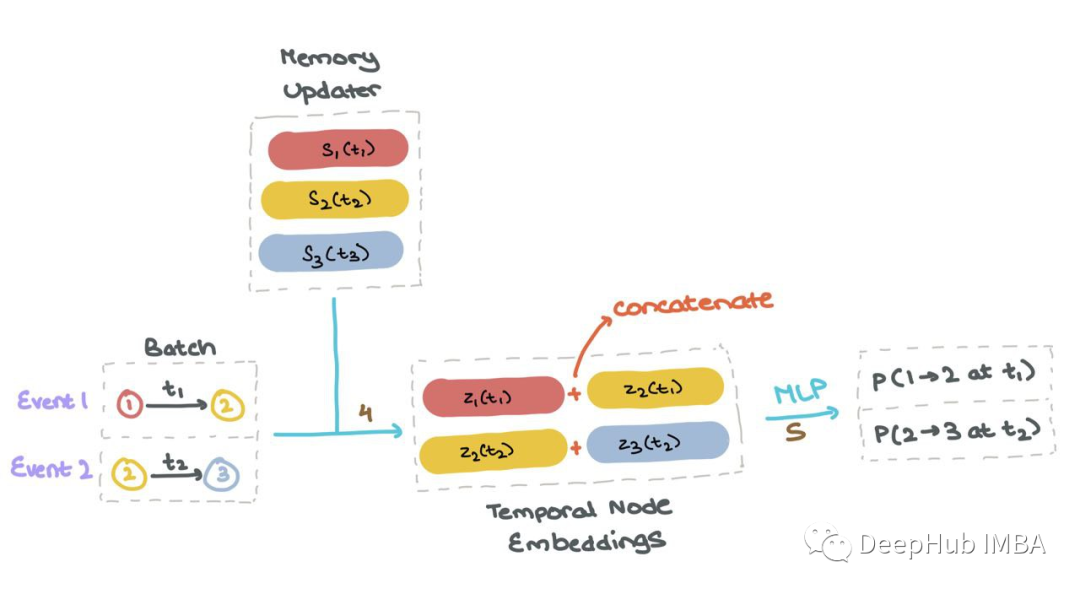
一旦所有节点的内存si(t)是最新的,它就用于计算批处理中特定交互中使用的所有节点的“临时节点嵌入”zi(t)。然后将这些节点嵌入到MLP或神经网络中,获得每个事件发生的概率(使用Sigmoid激活)。这样可以像往常一样使用二进制交叉熵(BCE)计算损失。
总结
上面就是我们对图神经网络的数学总结,图深度学习在处理具有类似网络结构的问题时是一个很好的工具集。它们很容易理解,我们可以使用PyTorch Geometric、spectral、Deep Graph Library、Jraph(jax)以及TensorFlow-gnn来实现。GDL已经显示出前景,并将继续作为一个领域发展。
参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 还在为学MyBatis发愁?史上最全,一篇文章带你学习MyBatis
- Openwrt 下动态路由协议(quagga-OSPF)配置与验证
- 代码随想录算法训练营第四十三天|1049. 最后一块石头的重量 II、 494. 目标和、474.一和零
- 苹果要在iPhone上运行AI大模型?
- 基于ssm的医院交互系统+vue论文
- PADS自动导出Gerber文件 —— 4层板
- C&C++语言控制语句介绍
- 安洵杯 2023 RE 你见过蓝色的小鲸鱼吗 WP
- Termux: 超28k stars,Android终端下的强大Linux环境
- Ubuntu本地快速搭建web小游戏网站,公网用户远程访问