大模型训练营Day3 基于 InternLM 和 LangChain 搭建你的知识库
发布时间:2024年01月11日

本次的授课人是一个提示词开发项目的负责人。下面一起进入本期课程吧》
本次课程内容主要如下:

开篇交代了大模型的局限性,然后引出主题:
简单总结,大模型是根据数据集训练,很难使用具有实时性的数据进行重新训练(因为训练成本需要海量资源)。并且,通用模型的专业场景应用很差。而且很难专门定制特定的大模型。

大模型的开发范式呢,主要有以下两种模式:
建立知识库和微调,知识库是传统AI专家系统中就有的概念;微调呢是冻结一定层的参数然后去训练改变其产生分类的少数几层的参数。二种方法都能减少训练成本,但是有一定的差别。
前者不需要算力,可以实时加入新知识,但是基座模型的上限极大程度决定其模型的上限。;而后者无法实时更新,但是由于其是一个改变少数层的新的大模型,仍然具有大模型的广阔知识的优势

RAG建立数据库的具体思路如下:
先将用户输入向量化(用向量表示),然后与数据库中的知识匹配,最后变成提示词传递给大模型。

而LangChain这个开源框架能够比较好地用于RAG这个方面的构建,为MIT一个创业者的发起,目前为大模型领域比较火的框架。
其核心组件为链,而最有代表性的是检索问答链,也是本节课所用。

以下是使用之构建应用的框图和工作步骤:
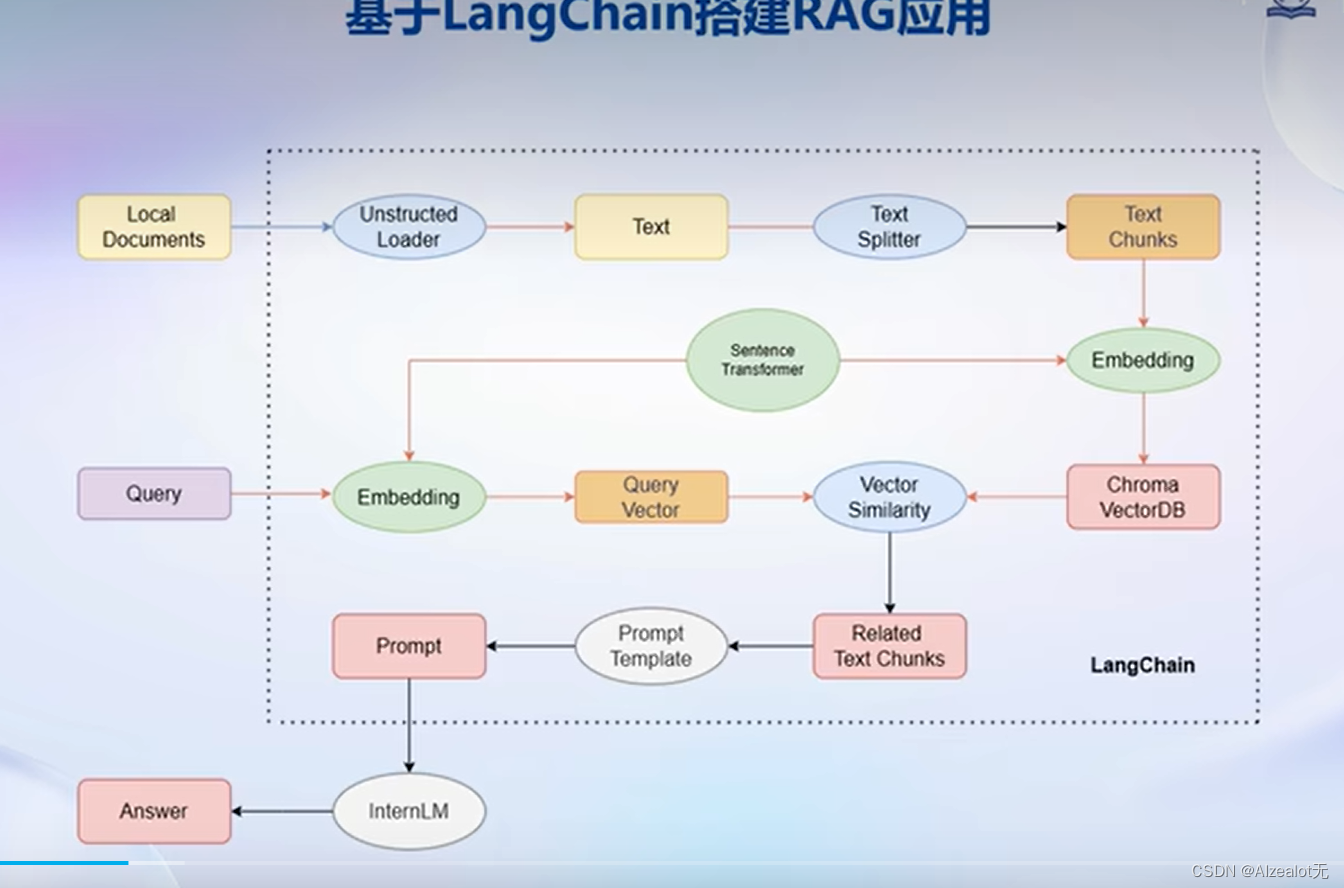
构建向量数据库主要步骤如下:

下面开始介绍知识库助手的搭建:

即调用这个组件,能够实现全部流程:

RAG有以下局限性和可能的优化方案:

以下开始部署Web Demo:
前两次作业的运行自动启动的是streamlit,本次基于Gradio。
按照文档一步步执行,即可。
文章来源:https://blog.csdn.net/m0_72806612/article/details/135538524
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TCP和SSL/TLS 协议通信原理
- SSM PageInfo和PageHelper实现多表分页,xml配置
- web自动化(3)——项目实战之流程用例编写
- 数据加密、端口管控、行为审计、终端安全、整体方案解决提供商
- 大模型ChatGLM下载、安装与使用
- docusaurus简介及使用心得
- 如何禁止员工安装新软件(如何限制员工电脑随意安装程序)
- Linux C语言 44-日志记录
- redis 从0到1完整学习 (十八):阻塞/非阻塞 IO
- 现在还有人使用Excel表格做进销存管理吗?