交叉熵在机器学习里做损失的意义
发布时间:2023年12月18日
交叉熵是机器学习中常用的损失函数之一,特别适用于分类任务。其背后的核心思想是衡量两个概率分布之间的差异。在分类问题中,通常有一个真实分布(ground truth distribution)和一个模型预测的分布(predicted distribution)。
对于一个具体的样本,设真实标签为 y,真实分布可以表示为一个概率分布 P,其中 P(y)?表示样本属于类别 y?的概率。模型的预测输出可以表示为另一个概率分布 Q,其中 Q(y)?表示模型预测样本属于类别y?的概率。
交叉熵损失的定义如下:
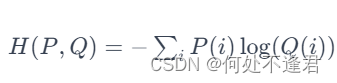
其中 i表示类别的索引。这个损失值衡量了两个概率分布之间的差异,具体来说:
1. 如果模型的预测概率分布 Q?能够准确地拟合真实分布 P,那么交叉熵损失将趋近于零。
2. 如果模型的预测概率分布与真实分布有差异,交叉熵损失将增大。
因此,通过最小化交叉熵损失,模型的预测分布将更接近真实分布,从而提高模型的分类性能。
在深度学习中,交叉熵损失常用于多类别分类问题,包括图像分类、自然语言处理中的文本分类等任务。在训练神经网络时,通过梯度下降等优化算法最小化交叉熵损失,使得模型学到的参数能够使预测分布更好地与真实分布一致。
文章来源:https://blog.csdn.net/danger2/article/details/135045820
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!