wav2lip中文语音驱动人脸训练
1 Wav2Lip介绍
1.1 Wav2Lip概述
2020年,来自印度海德拉巴大学和英国巴斯大学的团队,在ACM MM2020发表了的一篇论文《A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild 》,在文章中,他们提出一个叫做Wav2Lip的AI模型,只需要一段人物视频和一段目标语音,就能够让音频和视频合二为一,人物嘴型与音频完全匹配。
对口型的技术,此前其实已经有很多,甚至在基于深度学习的技术出现之前,就有一些技术使角色的嘴唇形状与实际的语音信号相匹配。但这Wav2Lip 在目前的众多方法中,显示出了绝对优势。现有的其它方法,主要是基于静态图像,来输出与目标语音匹配的唇形同步视频,但对于动态的、在讲话的人物,唇形同步往往效果不佳。而 Wav2Lip 则可以直接将动态的视频,进行唇形转换,输出与目标语音相匹配的视频结果。
论文地址:论文地址
代码地址:GitHub - Rudrabha/Wav2Lip
1.2 Wav2Lip模型结构

Wav2Lip模型是一个两阶段模型。
- 第一阶段是:训练一个能够判别声音与嘴型是否同步的判别器;
- 第二阶段是:采用编码-解码模型结构(一个生成器 ,两个判别器);
也可基于GAN的训练方式,在一定程度上会影响同步性,但整体视觉效果稍好。

在模型训练阶段,作者提出了两个新指标, “Lip-Sync Error-Distance”(越低越好)和 “Lip-Sync Error-Confidence”(越高越好),这两个指标可以测量视频的中的唇语同步精度。结果发现,使用Wav2Lip生成的视频几乎和真实的同步视频一样好。
需要注意的是,这个模型只在LRS2上的训练集上进行了训练,在对其他数据集的训练时需要对代码进行少量修改。
生成效果如下所示

1.3 论文内容
在这项工作中,我们研究了语音驱动任意人脸唇部的运动,使得语音与说话运动同步。当前的工作擅长在训练期间看到的特定人物的静态图像或视频上产生准确的嘴唇运动。然而,它们无法准确地改变动态、不受约束的说话面部视频中任意身份的嘴唇运动,导致视频的重要部分与新音频不同步。我们确定了与此相关的关键原因,并通过向强大的口型同步鉴别器学习来解决这些问题。接下来,我们提出新的、严格的评估基准和指标,以准确测量无约束视频中的唇同步。对我们具有挑战性的基准进行的广泛定量评估表明,我们的 Wav2Lip 模型生成的视频的口型同步精度几乎与真实同步视频一样好。
随着视听内容消费的指数级增长,快速视频内容创作已成为一种基本需求。与此同时,以不同语言翻译这些视频也是一个关键挑战。例如,深度学习系列讲座、一部著名电影或向全国发表的公开演讲,如果翻译成所需的目标语言,就可以供数百万新观众观看。翻译此类会说话的面部视频的一个关键方面是校正唇形以同步匹配所需的目标语音。因此,对人脸视频进行口型同步以匹配给定的输入音频流已经在研究界受到了相当多的关注。在这个领域深度学习的早期工作使用单个说话者的几个小时视频学习了从语音表示到唇部标志的映射。这方面最近的工作能够直接从语音表示生成图像,并在他们经过训练的特定说话人上展示了卓越的生成质量。然而,许多实际应用需要能够轻松用于通用身份和语音输入的模型,这种模型经过数千种身份和声音的训练。它们可以在任何声音中的任何身份的单个静态图像上生成准确的嘴唇运动,包括由文本到语音系统生成的合成语音。然而,要用于翻译讲座/电视剧等应用,对这些模型的要求就不仅仅需要运行在静态图像上。我们的工作建立在后一类通用说话者的工作之上,这些工作希望对任何身份和声音的说话面部视频进行口型同步。我们发现,这些适用于静态图像的模型无法准确地应用在视频内容中的各种嘴唇形状中。我们的主要贡献如下:
- 我们提出了一种新颖的口型同步网络,Wav2Lip,它比以前的作品更加准确,可以在任意语音对任意说话的脸部视频进行口型同步。
- 我们提出了一个新的评估框架,其中包括新的基准和指标,以实现对不受约束的视频中的口型同步的公平判断。
- 我们收集并发布了ReSyncED,这是一个真实的口型同步评估数据集,用于在完全未见过的视频上对口型同步模型的性能进行基准测试。
- Wav2Lip 是第一个通用说话者的模型,可生成与真实同步视频相匹配的口型同步精度的视频。人类评估表明,在超过 90% 的情况下,Wav2Lip 生成的视频优于现有方法。
2 Wav2Lip部署及使用
2.1 项目下载:
git clone https://github.com/Rudrabha/Wav2Lip2.2 运行环境构建
conda环境准备详见:annoconda安装与使用
修改requirements.txt如下:
librosa==0.9.1
numpy==1.22.0
opencv-contrib-python>=4.2.0.34
opencv-python==4.6.0.66
torch==1.13.0
torchvision==0.14.0
tqdm==4.45.0
numba==0.58conda create -n wav2lip python==3.9
conda activate wav2lip
conda install ffmpeg
cd Wav2lip
pip install -r requirements.txt2.3 预训练模型获取
预训练模型下载:预训练模型地址
下载完成后解压,并按如下目录方式存放
- wav2lip.pth存放到checkpoints目录下
- wav2lip_gan.pth存放到checkpoints目录下
- lipsync_expert.pth存放到checkpoints目录下
- visual_quality_disc.pth存放到checkpoints目录下
- s3fd.pth存放到
face_detection/detection/sfd/目录下
2.4 视频合成
- 通过视频和音频进行合成
python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face data/demo.mp4 --audio data/demo.wav - 通过图片和音频进行合成
python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face data/demo.png --audio data/demo.wav 最后,生成的新视频文件保存在 results/result_voice.mp4 ,生成的中间文件存放在 temp 下
3 Wav2Lip模型微调
训练注意事项:
-
可能无法通过在单个人的几分钟视频训练/微调来获得良好的结果。
-
在训练wav2lip之前,需要用你自己的数据集训练expert discriminator
-
如果是您自己从Web下载的数据集,则在大多数情况下需要sync-corrected同步校正。
-
FPS的更改将需要重大的代码更改,所以训练之前,所有视频数据要调整为25fps
-
expert discriminator的评估损失应降至约0.25,wav2lip评估同步损失应降至?0.2,以获得良好的结果。
?如果想要自己训练一个syncnet模型的话, 简单的从网上拉一些看似音视频已经对齐的资源是不够的, 有可能仍存在<100 ms的非同步, 所以需要干净的经过检查的数据. 作者的做法是先拿未筛选的数据训练一版模型, 然后通过卡阈值把训练集中一部分false positive (即假对齐)给抛弃掉, 从而达到非人工筛选的目的。?
3.1 数据集准备
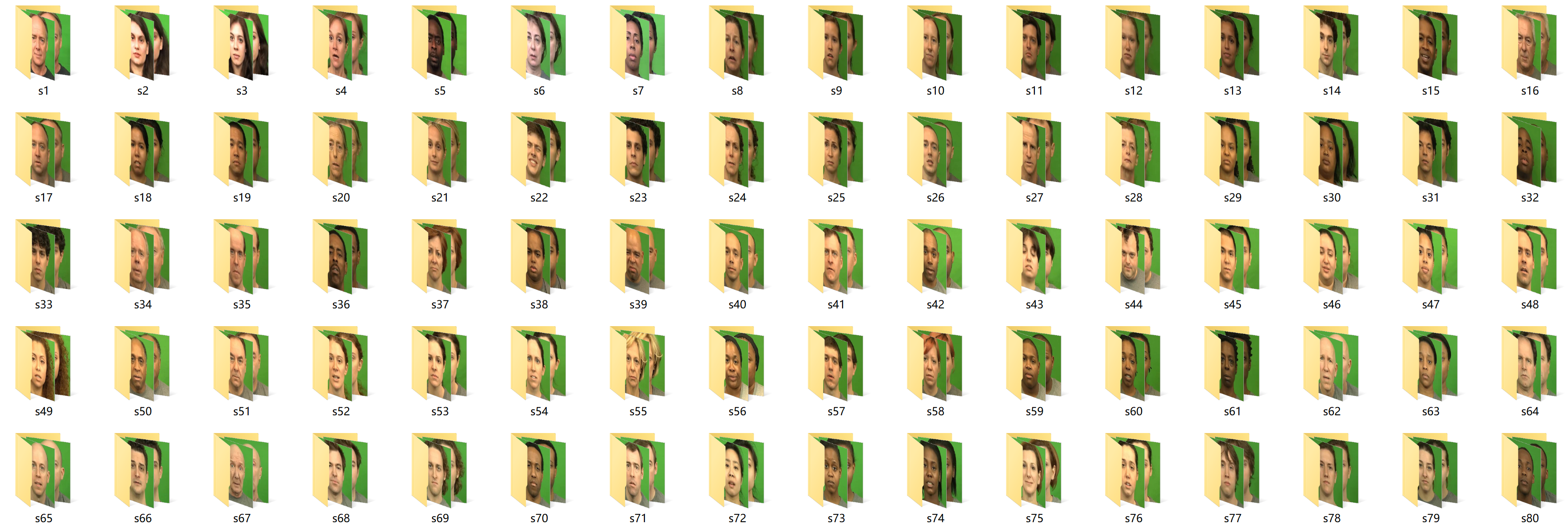
3.2 数据预处理
python preprocess.py --data_root /opt/data/25fps/ --preprocessed_root /opt/data/25fps_preprocessed3.3 同步判别器训练
python color_syncnet_train.py --data_root /opt/data/25fps_preprocessed/ --checkpoint_dir syncnet_checkpoints/ --checkpoint_path checkpoints/lipsync_expert.pth3.4 Wav2Lip训练
python wav2lip_train.py --data_root /opt/data/25fps_preprocessed/ --checkpoint_dir checkpoints/ --syncnet_checkpoint_path syncnet_checkpoints/checkpoint_step001880000.pth --checkpoint_path checkpoints/wav2lip.pth3.5 带视频质量判别器的Wav2Lip训练
python hq_wav2lip_train.py --data_root /opt/data/lrs2_preprocessed/ --checkpoint_dir hq_wav2lip_checkpoints/ --syncnet_checkpoint_path syncnet_checkpoints/checkpoint_step001880000.pth --checkpoint_path checkpoints/wav2lip_gan.pth --disc_checkpoint_path checkpoints/visual_quality_disc.pth4 注意事项
windows下训练,需要更改预处理preprocess.py的代码
def process_video_file(vfile, args, gpu_id):
video_stream = cv2.VideoCapture(vfile)
frames = []
while 1:
still_reading, frame = video_stream.read()
if not still_reading:
video_stream.release()
break
frames.append(frame)
vidname = os.path.basename(vfile).split('.')[0]
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
batches = [frames[i:i + args.batch_size] for i in range(0, len(frames), args.batch_size)]
i = -1
for fb in batches:
preds = fa[gpu_id].get_detections_for_batch(np.asarray(fb))
for j, f in enumerate(preds):
i += 1
if f is None:
continue
x1, y1, x2, y2 = f
cv2.imwrite(path.join(fulldir, '{}.jpg'.format(i)), fb[j][y1:y2, x1:x2])
修改为:
def process_video_file(vfile, args, gpu_id):
video_stream = cv2.VideoCapture(vfile)
frames = []
while 1:
still_reading, frame = video_stream.read()
if not still_reading:
video_stream.release()
break
frames.append(frame)
vidname = os.path.basename(vfile).split('.')[0]
vfile = vfile.replace('\\', '/')
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
batches = [frames[i:i + args.batch_size] for i in range(0, len(frames), args.batch_size)]
i = -1
for fb in batches:
preds = fa[gpu_id].get_detections_for_batch(np.asarray(fb))
for j, f in enumerate(preds):
i += 1
if f is None:
continue
x1, y1, x2, y2 = f
cv2.imwrite(path.join(fulldir, '{}.jpg'.format(i)), fb[j][y1:y2, x1:x2])def process_audio_file(vfile, args):
vidname = os.path.basename(vfile).split('.')[0]
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
wavpath = path.join(fulldir, 'audio.wav')
command = template.format(vfile, wavpath)
subprocess.call(command, shell=True)
修改为:
def process_audio_file(vfile, args):
vidname = os.path.basename(vfile).split('.')[0]
vfile = vfile.replace('\\', '/')
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
wavpath = path.join(fulldir, 'audio.wav')
command = template.format(vfile, wavpath)
subprocess.call(command, shell=True)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- IPhone、IPad、安卓手机、平板以及鸿蒙系统使用惠普无线打印教程
- 亚马逊近日发布通用产品安全法规一般产品安全法规 (GPSR)
- C++力扣题目700--二叉搜索树中的搜索
- 【C++11】Lambda 表达式
- K8S学习指南(41)-k8s资源管理对象LimitRange
- LeetCode239. 滑动窗口最大值[困难]
- Spring-AOP详解
- 微服务实战系列之ZooKeeper(中)
- JAVA小游戏“飞翔的小鸟”
- 云手机解决Tik Tok运营难题