干货教学--基于Resnet50实现猫狗分类【附源码】
猫狗分类的应用解决了宠物图像自动分类,宠场社交媒体搜索和组织、宠物领养和寄养平台的匹配准确性以及宠场智能识别没备的分类和行为检测等问题。
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题。
ResNet是残差网络(Residual Network)的缩写,该系列网络广泛用于目标分类等领域以及作为计算机视觉任务主干经典神经网络的一部分,典型的网络有resnet50, resnet101等。ResNet网络的证明网络能够向更深(包含更多隐藏层)的方向发展。
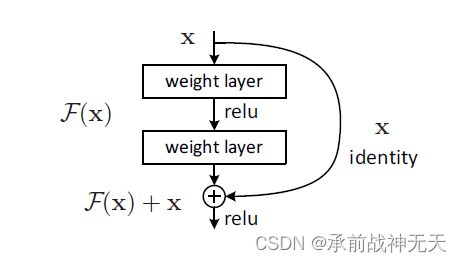
深度残差网络的设计是为了克服由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。
ResNet50网络
通过残差学习的概念解决了梯度消失问题,它引入了跳过连接,将输出直接添加某些层的输出上,使得网络可以更轻地学习残差,ResNet50过堆叠多个残差块来构建网络,并使用全局平均池化将特征图转换为定长向量,最后,通过全连接层进行分类预测。
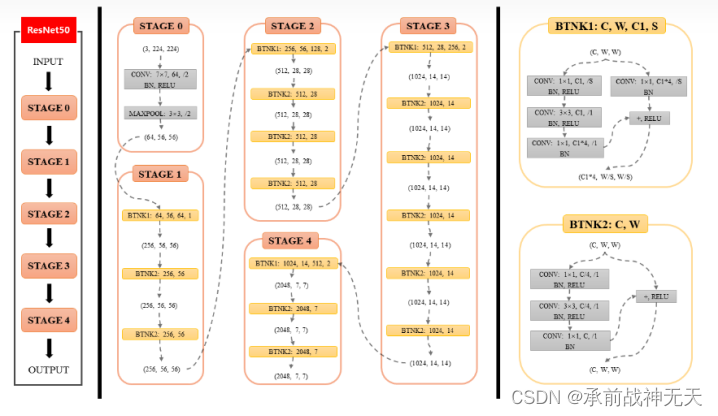
整体结构如下

大体框架:Layer->Block->Stage->Network
左边是ResNet50整体结构,中间部分是ResNet50各个Stage具体结构,右边是Bottleneck具体结构。
数据集有20000多张图片

定义ResNet50网络模型,先定义残差块,再定义ResNet50模型
# 定义Residual Block
class ResidualBlock(nn.Module):
? ? def __init__(self, in_channels, out_channels, stride=1, downsample=None):
? ? ? ? super(ResidualBlock, self).__init__()
? ? ? ? self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)
? ? ? ? self.bn1 = nn.BatchNorm2d(out_channels)
? ? ? ? self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
? ? ? ? self.bn2 = nn.BatchNorm2d(out_channels)
? ? ? ? self.conv3 = nn.Conv2d(out_channels, out_channels * 4, kernel_size=1, stride=1, bias=False)
? ? ? ? self.bn3 = nn.BatchNorm2d(out_channels * 4)
? ? ? ? self.relu = nn.ReLU(inplace=True)
? ? ? ? self.downsample = downsample
? ? def forward(self, x):
? ? ? ? residual = x
? ? ? ? out = self.conv1(x)
? ? ? ? out = self.bn1(out)
? ? ? ? out = self.relu(out)
? ? ? ? out = self.conv2(out)
? ? ? ? out = self.bn2(out)
? ? ? ? out = self.relu(out)
? ? ? ? out = self.conv3(out)
? ? ? ? out = self.bn3(out)
? ? ? ? if self.downsample is not None:
? ? ? ? ? ? residual = self.downsample(x)
? ? ? ? out += residual
? ? ? ? out = self.relu(out)
? ? ? ? return out
# 定义ResNet50模型
class ResNet50(nn.Module):
? ? def __init__(self, num_classes=2):
? ? ? ? super(ResNet50, self).__init__()
? ? ? ? self.in_channels = 64
? ? ? ? self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
? ? ? ? self.bn1 = nn.BatchNorm2d(64)
? ? ? ? self.relu = nn.ReLU(inplace=True)
? ? ? ? self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
? ? ? ? self.layer1 = self._make_layer(ResidualBlock, 64, 3, stride=1)
? ? ? ? self.layer2 = self._make_layer(ResidualBlock, 128, 4, stride=2)
? ? ? ? self.layer3 = self._make_layer(ResidualBlock, 256, 6, stride=2)
? ? ? ? self.layer4 = self._make_layer(ResidualBlock, 512, 3, stride=2)
? ? ? ? self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
? ? ? ? self.fc = nn.Linear(512 * 4, num_classes)
? ? ? ? # 添加Dropout层
? ? ? ? self.dropout = nn.Dropout(0.5)
? ? def _make_layer(self, block, channels, num_blocks, stride):
? ? ? ? downsample = None
? ? ? ? if stride != 1 or self.in_channels != channels * 4:
? ? ? ? ? ? downsample = nn.Sequential(
? ? ? ? ? ? ? ? nn.Conv2d(self.in_channels, channels * 4, kernel_size=1, stride=stride, bias=False),
? ? ? ? ? ? ? ? nn.BatchNorm2d(channels * 4),
? ? ? ? ? ? )
? ? ? ? layers = []
? ? ? ? layers.append(block(self.in_channels, channels, stride, downsample))
? ? ? ? self.in_channels = channels * 4
? ? ? ? for _ in range(1, num_blocks):
? ? ? ? ? ? layers.append(block(self.in_channels, channels))
? ? ? ? return nn.Sequential(*layers)
? ? def forward(self, x):
? ? ? ? out = self.conv1(x)
? ? ? ? out = self.bn1(out)
? ? ? ? out = self.relu(out)
? ? ? ? out = self.maxpool(out)
? ? ? ? out = self.layer1(out)
? ? ? ? out = self.layer2(out)
? ? ? ? out = self.layer3(out)
? ? ? ? out = self.layer4(out)
? ? ? ? out = self.avgpool(out)
? ? ? ? out = torch.flatten(out, 1)
? ? ? ? # 添加Dropout层
? ? ? ? out = self.dropout(out)
? ? ? ? out = self.fc(out)
? ? ? ? return out
最终识别输出的结果准确率特别高,90%-100%

有需要源码的宝子们可以后台私信我哦,可以一起学习交流,创作不易,不完全免费哦
可以动动你们的小手指点个小爱心吗,你们的鼓励是我前进的最大动力
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Docker 安装Nginx与配置Nginx
- 四、C++运算符(4)比较运算符
- 计算机毕业设计选题分享-Springboot在线问诊系统00211(赠送源码数据库)JAVA、PHP,node.js,C++、python,大屏数据可视化等
- 【餐饮创业系列】阳光小厨把子肉
- 这些流行的K8S工具,你都用上了吗
- 【算法】二分法
- linux 内存映射
- 文化传媒企业网站建设的效果如何
- FreeRTOS——优先级翻转
- RabbitMQ消息顺序性保障