JRT核心竞争力
如果说JRT业务脚本化和发部署简单和打印导出客户端都不足以抵挡Spring用的人多的优势的话。那么这一篇让DolerGet给你一个选择JRT的理由,借助JRT自我实现的ORM,JRT有能力完全把控更新数据和删除数据的口径,和能够准确知道哪些是热点数据,进而构建可靠的缓存机制来供多维查询使用。而关系库最大的痛点也就是多维查询不方便。
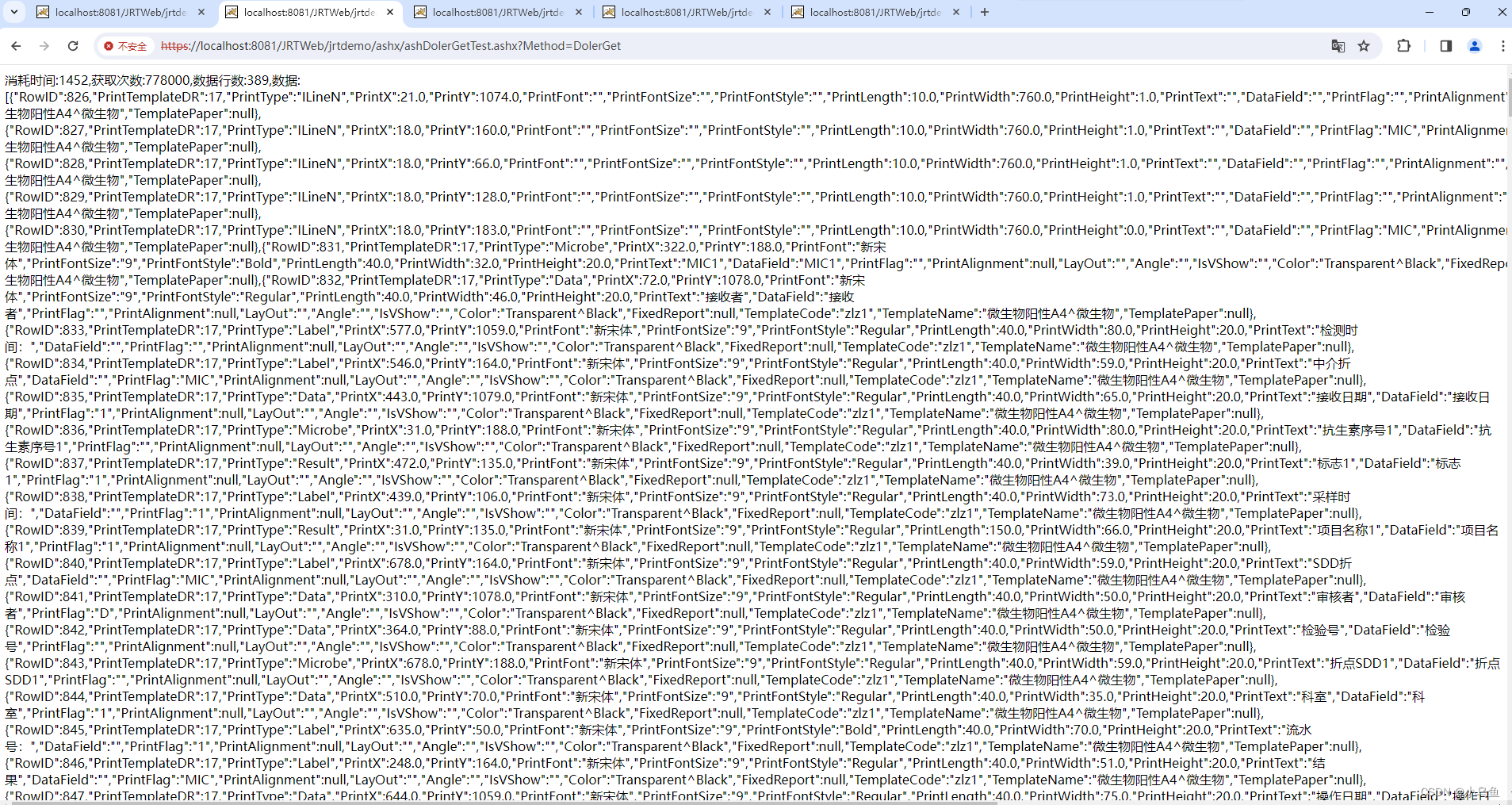
本次测试就是验证DolerGet的性能,相同查询使用DolerGet和不使用能达到上百倍的性能差异,看图和测试代码说话,完全不输Cache的¥get性能,对¥d的效果可以增加字段解决。
不使用DolerGet查询数据
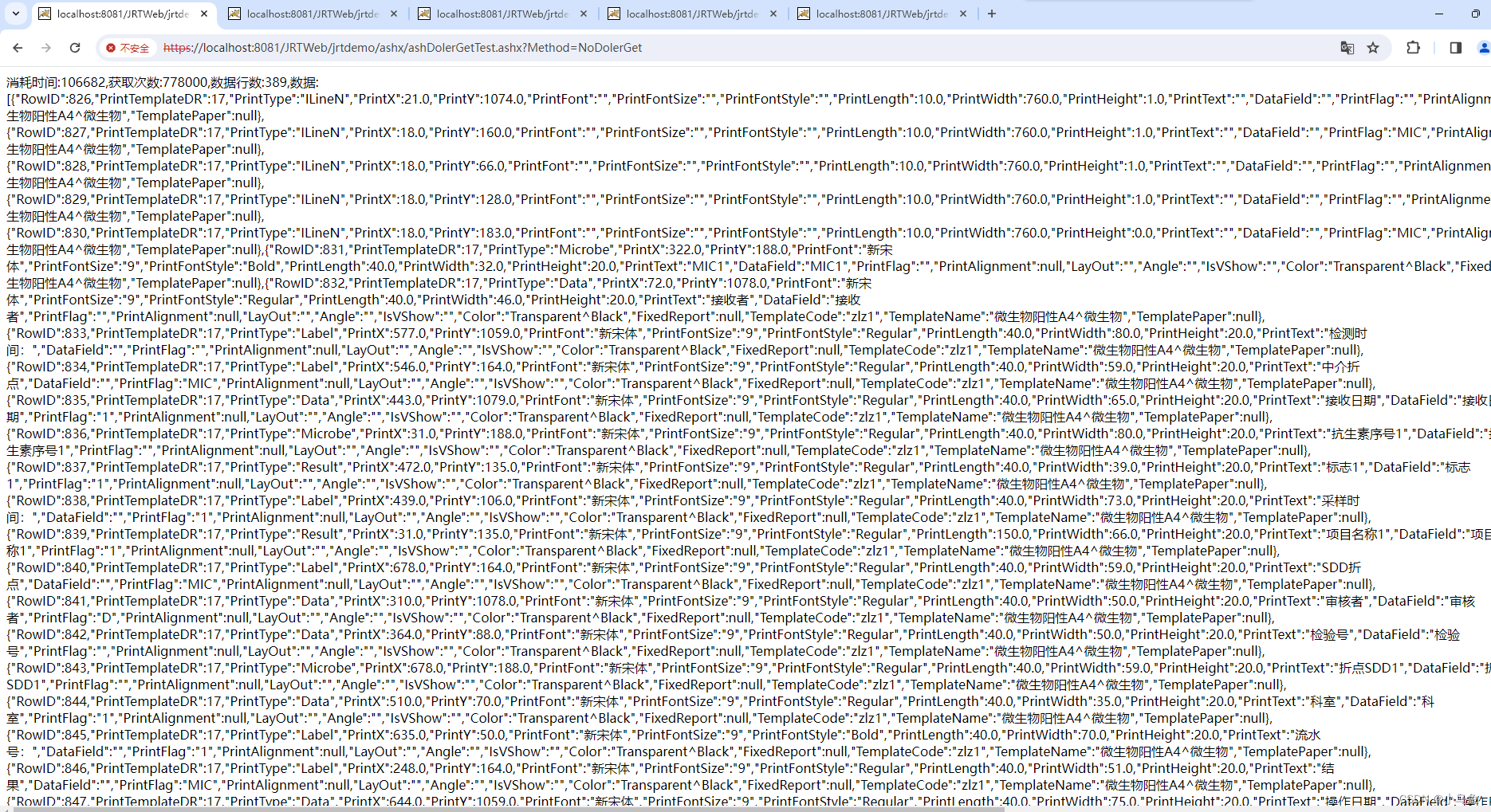
使用DolerGet查询数据
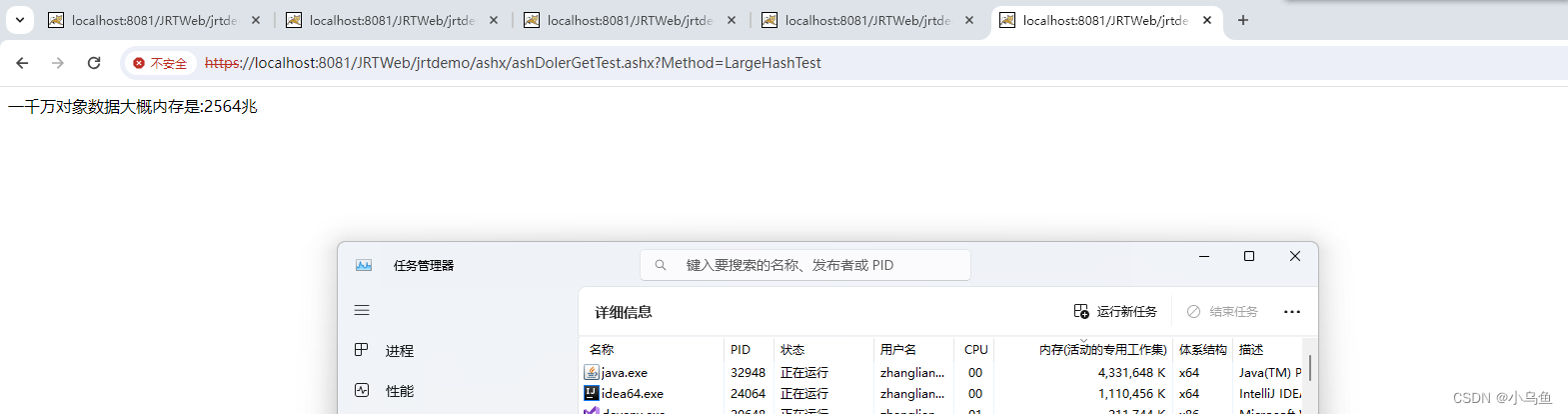
缓存千万个表数据的内存情况,算的可能不那么准,反正整个tomcat占用4G左右,我就是花几个G缓存千万级别的热点数据也毫无压力
测试代码
import JRTBLLBase.BaseHttpHandlerNoSession;
import JRTBLLBase.Helper;
import JRT.Core.Dto.HashParam;
import JRT.Core.Dto.ParamDto;
import JRT.Core.Dto.OutParam;
import JRT.Model.Entity.*;
import JRT.Core.Util.Convert;
import JRT.Core.MultiPlatform.JRTContext;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
/**
* 测试DolerGet和不用DolerGet的性能差别以及在哈希表放千万行数据的内存占用
*
*/
public class ashDolerGetTest extends BaseHttpHandlerNoSession {
/**
* 大哈希内存测试,测试缓存对象的内存占用情况
* @return
*/
public String LargeHashTest() throws Exception
{
ConcurrentHashMap<String, Object> hsData = new ConcurrentHashMap<>();
List<JRTPrintTemplateEleRetDto> eleList=EntityManager().FindAllSimple(JRTPrintTemplateEleRetDto.class,null);
long startMemorySize = Runtime.getRuntime().totalMemory()-Runtime.getRuntime().freeMemory();
for(int i=0;i<10000000;i++)
{
hsData.put(i+"",JRT.Core.Util.ReflectUtil.CloneObject(eleList.get(0)));
}
long endMemorySize = Runtime.getRuntime().totalMemory()-Runtime.getRuntime().freeMemory();
long useSize=(endMemorySize-startMemorySize)/ (1024 * 1024);
hsData.clear();
hsData=null;
return "一千万对象数据大概内存是:"+useSize+"兆";
}
/**
* 不用DolerGet查询数据
* @return
*/
public String NoDolerGet() throws Exception
{
long start=JRT.Core.Util.TimeParser.GetTimeInMillis();
//查询所有表里面的元素
List<JRTPrintTemplateEleRetDto> eleList=EntityManager().FindAllSimple(JRTPrintTemplateEleRetDto.class,null);
int getNum=0;
for(JRTPrintTemplateEleRetDto ele:eleList)
{
for(int i=0;i<2000;i++) {
//取模板信息
JRTPrintTemplate tmp = EntityManager().GetById(JRTPrintTemplate.class, ele.PrintTemplateDR);
ele.TemplateCode=tmp.Code;
ele.TemplateName=tmp.CName;
//取纸张信息
if(tmp.JRTPrintPaperDR!=null)
{
JRTPrintPaper paper=EntityManager().GetById(JRTPrintPaper.class,tmp.JRTPrintPaperDR);
ele.TemplatePaper=paper.CName;
getNum++;
}
getNum++;
}
}
long end=JRT.Core.Util.TimeParser.GetTimeInMillis();
return "消耗时间:"+(end-start)+",获取次数:"+getNum+",数据行数:"+eleList.size()+",数据:"+Helper.Object2Json(eleList);
}
/**
* 用DolerGet查询数据
* @return
*/
public String DolerGet() throws Exception
{
long start=JRT.Core.Util.TimeParser.GetTimeInMillis();
//查询所有表里面的元素
List<JRTPrintTemplateEleRetDto> eleList=EntityManager().FindAllSimple(JRTPrintTemplateEleRetDto.class,null);
int getNum=0;
for(JRTPrintTemplateEleRetDto ele:eleList)
{
for(int i=0;i<2000;i++) {
//取模板信息
JRTPrintTemplate tmp = EntityManager().DolerGet(JRTPrintTemplate.class, ele.PrintTemplateDR);
ele.TemplateCode=tmp.Code;
ele.TemplateName=tmp.CName;
//取纸张信息
if(tmp.JRTPrintPaperDR!=null)
{
JRTPrintPaper paper=EntityManager().DolerGet(JRTPrintPaper.class,tmp.JRTPrintPaperDR);
ele.TemplatePaper=paper.CName;
getNum++;
}
getNum++;
}
}
long end=JRT.Core.Util.TimeParser.GetTimeInMillis();
return "消耗时间:"+(end-start)+",获取次数:"+getNum+",数据行数:"+eleList.size()+",数据:"+Helper.Object2Json(eleList);
}
/**
* 查看缓存数据
* @return
* @throws Exception
*/
public String View() throws Exception
{
return JRT.DAL.ORM.Global.GlobalManager.ViewGlobalJson();
}
/**
* 查看缓存队列数据
* @return
* @throws Exception
*/
public String ViewQuen() throws Exception
{
return JRT.DAL.ORM.Global.GlobalManager.ViewGlobalTaskQuenDate();
}
/**
* 返回模板元素数据实体
*/
public static class JRTPrintTemplateEleRetDto extends JRTPrintTemplateEle {
/**
* 模板代码
*/
public String TemplateCode;
/**
* 模板名称
*/
public String TemplateName;
/**
* 模板纸张
*/
public String TemplatePaper;
}
}
DolerGet来源于Cache数据库的¥get命令,使用了十年Cache库,既用了SQL模式的ORM,也用了M的代码,我深知M的强大优势。通过使用过程我发现Cache也不是那么神奇,在ECP上一直¥d不存在的global,他的性能是指数级下降。这个现象说明了什么?
说明Cache没有缓存不存在的global,他的¥g和¥d也是在内存缓存的,只是他是数据库一体的,所以他能得到更新和删除数据操作来保证缓存可靠。所以$g能达到极高的多维爬行效果。那么我把控ORM的修改和删除API,也能实现可靠的多维爬行效果。
我22年深入学习了FreeRTOS,并且参照着撸了一版简化OS,实现了线程调度。对OS的理解从来那么深入过,我深知在OS和硬件层面没什么特殊路子。就是c比较字符串就得一个个字符比,不会因为语言低级而得到简化。所以Cache的M爬数据块肯定不是什么特异功能,应该是来自M和数据库在一体带来的优势。
基于此基础,已经可以做到不输Cache的效果;超低的学习成本、超低的开发和部署成本、很高的开发效率、完全信创的客户端程序、可靠高性能的多维查询、BS的打印设计器、基于关系库开发一套优秀的系统已经依稀可见,要么不做,要做就得奔着最优秀的做。
保持自己的主见,不人云亦云,人用亦用,多问几个为什么,深入理解业务场景,为业务做框架,不为框架而框架。从量变到质变我走了十年,从C#到JAVA,我走了两个月。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第10章_多线程扩展练习(Thread类中的方法,线程创建,线程通信)
- easyExcel 获取多个sheet中复杂表头的数据
- kylin3集群问题和思考(单机转集群)
- 怎么做图文排版类型的二维码?扫码展现多种内容的制作步骤
- 盘古信息IMS-MOM制造运营管理系统,构建生产现场管理信息系统的最佳选择
- c语言 文件与文件操作
- k8s节点not ready
- JavaScript对数据进行分组、根据数据值分组、只针对数组、普通函数变为高阶函数、参数归一化
- modbus 通信协议介绍与我的测试经验分享
- 03 decision tree(决策树)