计算机组成原理第4章-(Cache)【下】
高速缓冲存储器
我们首先要搞清楚,为什么要引入高速缓冲存储器呢?
首先,在多体并行存储系统中,I/O设备对于主存的使用权大于CPU对于主存的使用权,这也就造
成了CPU可能在一段时间内不能使用主存,从而浪费CPU资源。
其次,主存速度永远跟不上CPU的速度,因此可以说主存是遏制cpu高速计算的“罪魁祸首”。
为此,我们需要在CPU->主存之间引入高速缓冲存储器【Cache】来解决上述问题。
Cache的工作原理
块的基本概念
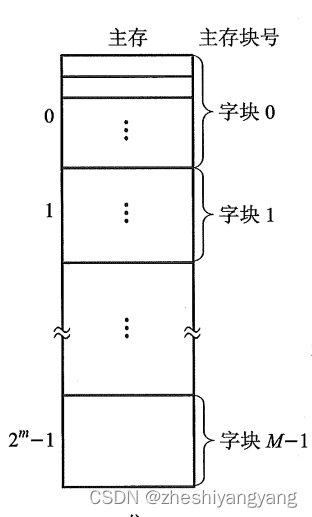
主存由个“可编址”的“字”组成,每个字有唯一的n位地址。
为了与Cache映射,将主存和Cache都分成若干块,每块又包含若干字,并且块大小相同。(块大
小就是块内字数)。
同时我们将主存的地址分成两段:
高m位表示主存的块地址,低b位表示块内地址。
则 ?= M表示主存的块数(从第0块->
块共
块)。

同时,我们还将Cache的地址也分成两段:
高c位表示缓存的块号,低b位表示块内字数,即C?=?表示缓存块数。
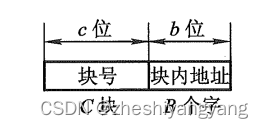
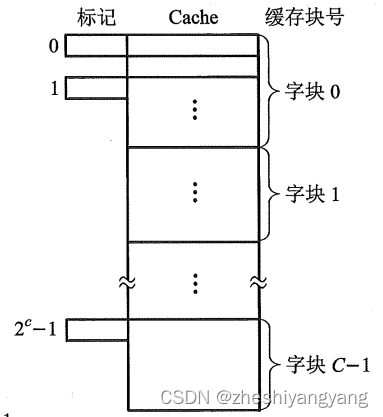
而主存与缓存地址中都用b位表示其块内字数,即B = 反映了块的大小,称B为块长。
CPU与Cache工作原理
任何时刻都有一些主存块处在缓存块中。
CPU欲读取主存某字时,有两种可能,一种是所需要的字已在缓存中,即可直接访问Cache(CPU
与Cache之间通常每次传送一个字的数据),这种可能被叫做“CPU访问命中”。
另一种可能是,当所需要的字不在Cache中,需要先将需要的字从主存一次调入Cache中(Cache
与主存之间是字块传送,即一次传送一个字块的数据),这种可能被叫做:“CPU访问未命中”。
一旦主存块成功调入进缓存中,那么就称该主存块与缓存块建立了对应关系。
附加
值得注意的是,由于缓存块块数C远小于主存块块数M,因此一个缓存块不能“唯一地”、“永久地”只
对应一个主存块,因此还需要在缓存块中设置一个标记,用来区分当前存放的是哪一个主存块。
当CPU读信息时,要先将主存地址的高m位(或m位中的一部分)与缓存块的标记进行比较,以判
断所读信息是否在缓存中。
Cache效率衡量标准
因为Cache的容量与块长是影响Cache效率的重要因素。
因此,我们给出一种衡量Cache效率的名词:“命中率”。
命中率是指CPU要访问的信息是否已在Cache内的比率。
我们假设为访问Cache的总命中次数,
为访问Cache的总次数,则命中率h为:
h =??/?
?+?
Cache-主存地址映射【极其重要】
将主存地址映射到Cache地址称为地址映射。
而地址映射的方式有三种:“直接映射”、“全相连映射”、“组相连映射”。
直接映射
下图给出了直接映射的对应关系:
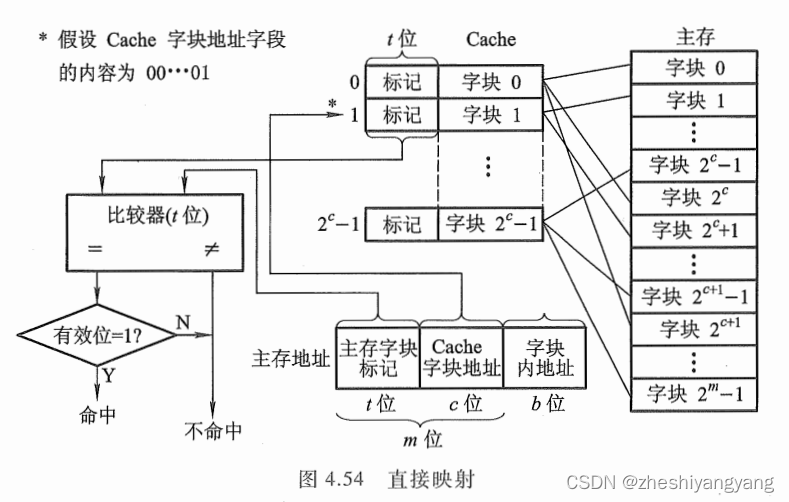
图中每个主存块只与一个缓存块相对应,映射关系式为:
i = j mod C,其中i为缓存块号,j为主存块号,C为缓存块数。

直接映射的工作过程
主存地址的高m位被分成了两部分,低c位表示的是Cache的字块地址,高t位表示主存字块标记。
当缓存接收到CPU送来的主存地址后,只需根据中间c位字段(假蛇为00...1)找到Cache字块1,
然后根于缓存字块1的标记是否与主存地址的高t位是否相符来判断,若符合则表示已建立对应关
系。
优点
直接映射的优点是:实现简单,只需利用主存地址的某些位直接判断,即可确定所需字块是否在缓
存中。
缺点
直接映射的缺点是:不够灵活,因为每个主存块只能固定地对应某个缓存块,即使缓存内还空着许
多位置也不能占用吗,使缓存的存储空间得不到充分的利用。
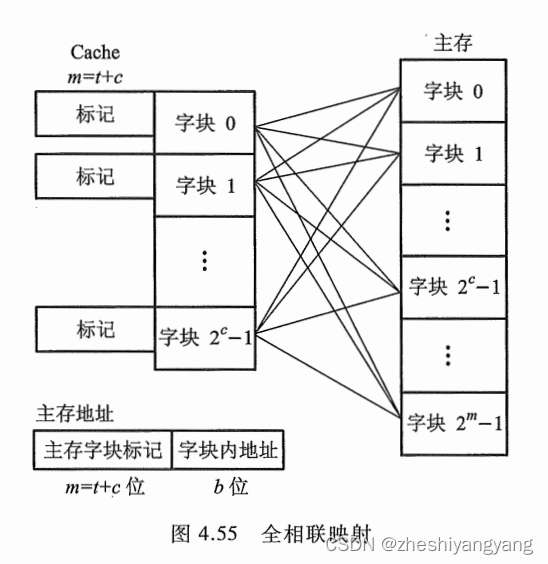
全相连映射
全相连映射允许主存中每一字段映射到Cache的任意位置上。
这种方式可以从已被占满的Cache中替换出任一旧字块。
优点
全相连映射的优点是:方式灵活,命中率更高,块冲突率更小。
缺点
成本较高,时间较慢
全相连映射的主存字块标记从t位增加到t+c位,并且访问Cache时,主存字块标记需要和Cache的
全部“标记”位进行比较,才能判断吹所访问主存地址是否已在Cache内。
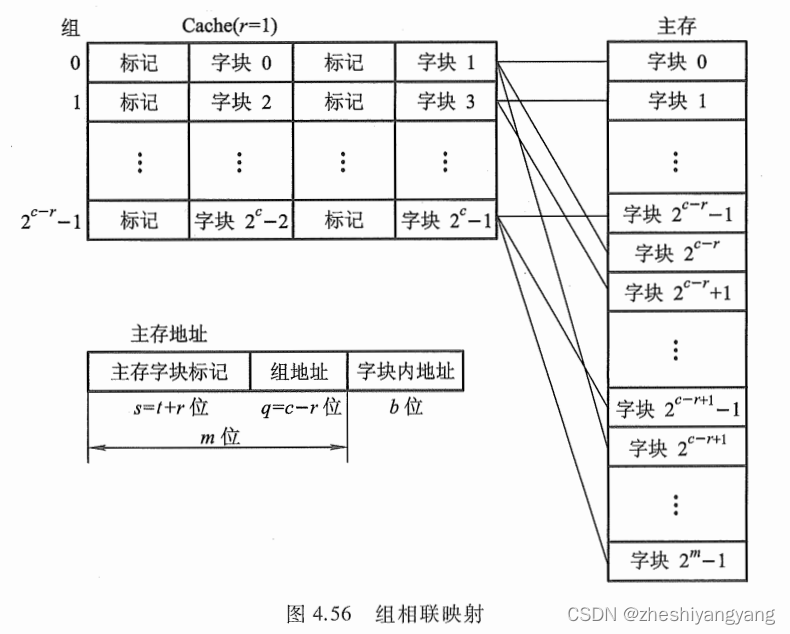
组相连映射
组相连映射是直接映射和全相连映射的一种折中。
它把Cache分为Q组,每组有R块,并有以下关系:
i = j mod Q,i是缓存的组号,j是主存的块号,Q是组数。
组相连映射的工作过程
表示Cache的总块数,
表示Cache的分组个数,
表示组内包含的块数。
我们假设c = 5,q = 4,那么r =?c -?q = 1。
其实际含义为:“Cache共有32个字块,共分成了16组,每组有2个字块。”
组内有2块的被称为:“二路组相连映射”,组内有4块的被称为:“四路组相连映射”。
此时我们注意到,主存的第j块会映射到Cache的第i组,两者之间一一对应,这体现了直接映射关
系。
另外,主存的第j块可以映射到Cache的第i组中任意一块,这又体现出全相连映射关系。
那么,我们可以得出一个结论:“当r=0时,是直接映射方式。当r=c时,是全相连映射方式。”
例题
在这里,我们给出几道例题。
1.假设主存容量为512KB,Cache容量为4KB,每个字块为16个字,每个字32位。
(1):Cache地址有几位?可容纳多少块?
(2):主存地址有几位,可容纳多少块?
(3):在直接映射方式下,主存的第几块映射到Cache中的第5块(设起始字块为第1块)。
(4):画出直接映射方式下主存地址字段中各段的位数。
答:
(1):Cache容量4KB可以得到Cache存储单元个数为:个。
即Cache地址就有12位。
每个字块16个字,每个字32位,那么Cache共可以容纳的块数为:
?/ 32 / 16?=?
块。【
/32表示:“容量/每字位数=字数”】
(2):主存容量为512KB可以得到主存的存储单元个数为:个。
即主存地址就有19位。
每个字块16个字,每个字32位,那么主存共可以容纳的块数为:
? / 32 /16 =?
块。
(3):列数学式子:
N %??== 5,解得:N = 5 +64n,N <=?
故第5、64+5....块可以映射到Cache的第5块。
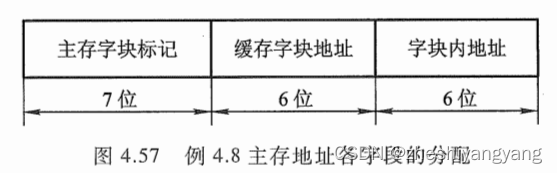
(4):
b =?每块的字节数,因此b = 6位()。
c = Cache字块地址,Cache共块,因此c = 6位。
t =?总长度-b-t,总长度为主存的容量,因此,t = 19 - 6 - 6 = 7位。
2.假设主存容量为512K * 16位,Cache容量为4096 * 16位,块长为4个16位的字,访存地址为字地
址。
(1):在直接映射方式下,设计主存的地址格式。
(2):在全相连映射方式下,设计主存的地址格式。
(3):在二路组相连映射方式下,设计主存的地址格式。
(4):若主存容量为512K * 32位,块长不变,在四路组相连映射方式下,设计主存的地址格式。
答:
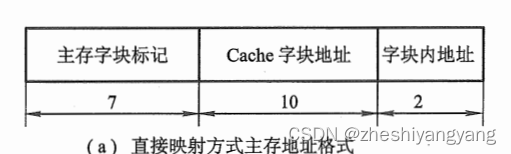
(1):主存容量512K,则主存总长度为,即19位。
Cache容量4096,则Cache长度为,即12位。
同时块长为4,即b = 2()。
c = Cache容量 /?位数 = 4096 / 4 =?,则c = 10位。
t = 19 - 10 - 2 = 7。
(2):m =?n -?b = 19 - 2 = 17

(3):因为是二路组相连,则每组有两块,因此r = 1
同时,可以得到Cache共分:
Cache块数 / 2 = Q(组数),Q= 9。
q = Q = 9
s = t +?r或者(s = N -?q -?b) = 8。
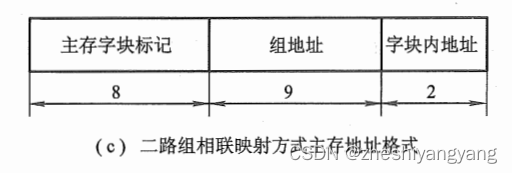
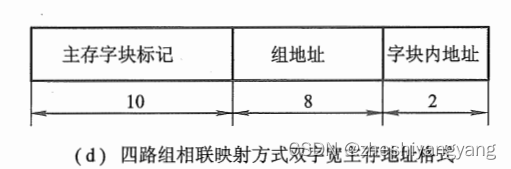
(4):主存改为512K * 32位,那么主存共位,即主存长度为20位。
又因为是四路组相连映射,因此
Q = 1024 / 4 =?
r = 2
q = Q = 8
s = N -?q -?b = 20 - 8 - 2 = 10
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 实战讲解Linux进程内存空间
- Autosar通信实战系列07-Com模块要点及其配置介绍(二)
- Redis高可用
- 为什么通配符SSL证书这么受欢迎?
- JavaScript介绍,特点及组成(详解)
- 大事务问题场景与应对之策
- JavaScript库jquery的使用方法
- 运筹说 第107期 | 排队论创始人——阿格纳·克拉鲁普·爱尔朗
- 全网最详细的vue2实现暗黑模式(深色主题与浅色主题切换)入门级即可学会@非常简单
- 【算法题】40. 组合总和 II