python实现搜索爬取酷狗音乐(歌曲、歌词、图片)
一、爬虫流程
(一)、数据来源分析
????????1、明确需求
????????2、抓包分析(使用开发者工具)
? ? ? ? ????????(1)、找到音频播放链接
????????????????(2)、找到并分析音频链接信息数据包
(二)、代码实现步骤
? ? ? ? 1、发送请求
? ? ? ? 2、获取数据
????????3、解析数据
? ? ? ? 4、保存数据
二、网站分析
1、音频播放链接
打开酷狗音乐网页版,随便点击一首歌曲,然后打开开发者工具,点击媒体(Media),刷新浏览器就可以看到歌曲的数据包,红色方框圈起来的就是歌曲的播放链接,通过复制绿色方框的字符串,使用开发者工具的搜索功能去找到歌曲链接的来源数据包。

?2、歌曲链接的来源数据包

?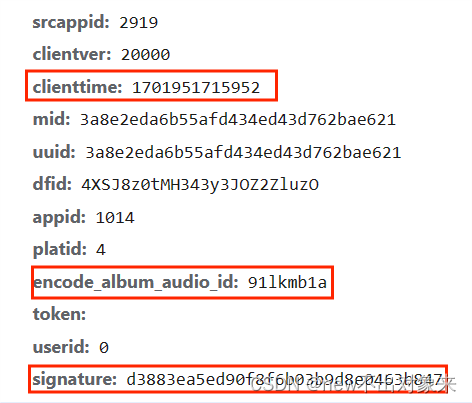

?这个数据包的请求URL问号(?)之前是请求链接,问号(?)之后的字符串是请求参数拼接起来的,在同一首歌曲中会发生变化的参数有两个,分别是clienttime(时间戳)、signature(加密参数),其中时间戳可以导入time时间模块进行处理,加密参数需要另外进行分析进行处理。不同的歌曲,歌曲id也会发生变化,所以要实现搜索爬取歌曲,时间戳、歌曲id、加密模块都需要设置变量去接收字符串。这时候对url发送请求,对参数进行处理,解析并保存数据(图片/音频/视频/特定格式文件获得链接,对于链接发送请求,获得二进制数据进行保存,但是这里面歌词并不是链接,可以使用正则表达式去进行匹配替换),就可以获得需要的歌曲名字(album_name)、歌曲id(encode_ablum_audio_id)、图片链接(img)、歌词(lyrics)、播放链接(play_url)。
3、分析加密参数
3.1、单曲加密参数
?
?
?经过观察,这好像是一个MD5的加密,那么我们可以通过在源面板中打断点继续进行分析。
?
?单曲加密参数对比:
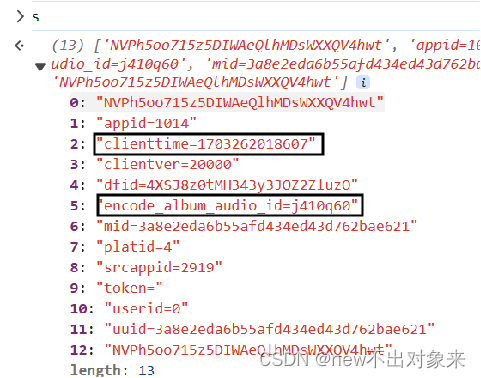
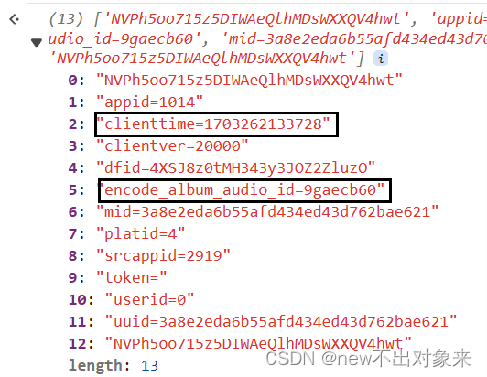
?对比发现两首歌曲的参数时间戳和歌曲id是不一样的,其他参数都是不变的。
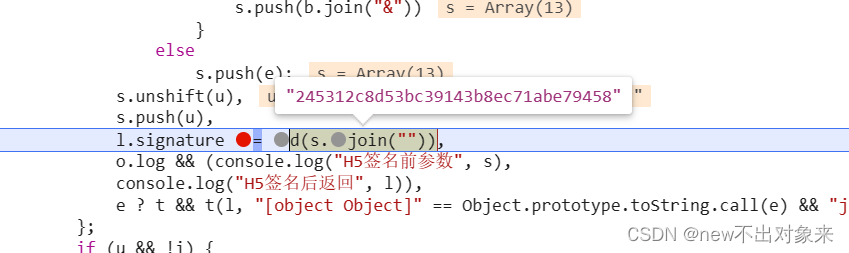
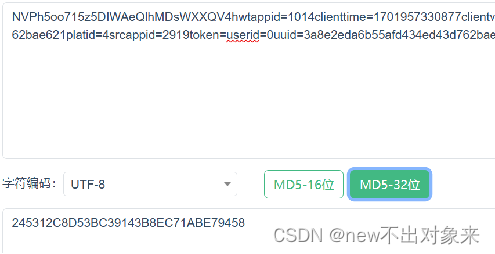
通过打断点,我们可以得到d(s.join(“”))传出来的字符串,我们可以复制s.join(“”)的参数在网上找一个MD5工具去进行验证,然后得到的结果是一样的,这时候就可以确定是MD5的加密。观察后不难发现,这个加密参数就是使用join()函数对s的参数进行处理,再进行MD5加密。MD5就是设置字符编码为UTF-8,32位 MD5就是32个十六进制数,即 16 个字节。所以我们可以模仿它去进行处理,首先使用join()函数去s进行处理,用string去接受,再使用解密模块hashlib:MD5 = hashlib.md5(),接着将得到的字符串设置为UTF-8更新到字典MD5中,再调用hexdigest()函数将它转化为16进制数,这样就可以得到单曲的加密参数了。
?3.2、搜索加密参数

?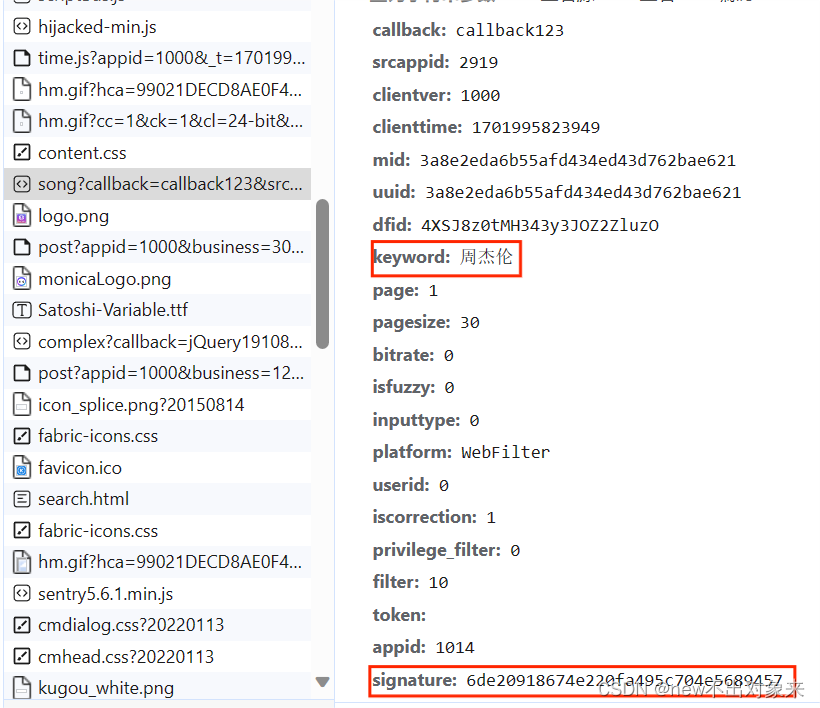
?过搜索就可以发现搜索的关键字和加密参数是会变的,其他参数是不变的,所以要实现搜索功能就要对它们进行处理。搜索加密参数的处理与单曲加密参数的处理是一样的,处理完之后就可以对url发送请求,对参数进行处理,解析数据,得到这个数据包里面我们想要的内容。最后再把搜索得到的歌曲id、时间戳调用单曲加密参数处理模块进行处理,得到新的加密参数,这样搜索爬取歌曲下载就可以实现了。
三、完整代码
# 导入数据请求模块
import requests
# 导入时间模块
import time
# 导入解密模块
import hashlib
# 导入正则表达式模块
import re
# 导入json模块
import json
# 导入制表模块
import prettytable as pt
# 模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 '
'Safari/537.36 Edg/119.0.0.0',
'Cookie': 'kg_mid=3a8e2eda6b55afd434ed43d762bae621; kg_dfid=4XSJ8z0tMH343y3JOZ2ZluzO; '
'kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1701158152,'
'1701163020,1701180349,1701337969; kg_mid_temp=3a8e2eda6b55afd434ed43d762bae621; '
'Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1701337996'
}
def Hash_md5(audio_id, date_time):
# audio_id = '9gaecb60'
s = [
"NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt",
"appid=1014",
# 时间戳
f"clienttime={date_time}",
"clientver=20000",
"dfid=4XSJ8z0tMH343y3JOZ2ZluzO",
# 歌曲id
f"encode_album_audio_id={audio_id}",
"mid=3a8e2eda6b55afd434ed43d762bae621",
"platid=4",
"srcappid=2919",
"token=",
"userid=0",
"uuid=3a8e2eda6b55afd434ed43d762bae621",
"NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt"
]
# 把列表拼接成字符串
string = ''.join(s)
MD5 = hashlib.md5()
MD5.update(string.encode('utf-8'))
signature = MD5.hexdigest()
# print(signature)
return signature
def search_MD5(world, date_time):
search_s = [
"NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt",
"appid=1014",
"bitrate=0",
"callback=callback123",
f"clienttime={date_time}",
"clientver=1000",
"dfid=4XSJ8z0tMH343y3JOZ2ZluzO",
"filter=10",
"inputtype=0",
"iscorrection=1",
"isfuzzy=0",
f"keyword={world}",
"mid=3a8e2eda6b55afd434ed43d762bae621",
"page=1",
"pagesize=30",
"platform=WebFilter",
"privilege_filter=0",
"srcappid=2919",
"token=",
"userid=0",
"uuid=3a8e2eda6b55afd434ed43d762bae621",
"NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt"
]
search_string = ''.join(search_s)
MD5 = hashlib.md5()
MD5.update(search_string.encode('utf-8'))
search_signature = MD5.hexdigest()
# print(signature)
return search_signature
# audio_id = '9gaecb60'
# 获取当前时间的毫秒数
# 时间戳13位,所以是到毫秒的,所以我们要*1000,因为我们获取当前时间只精确到秒
date_time = int(time.time() * 1000)
# signature = Hash_md5(audio_id, date_time)
# key = '周杰伦'
key = input('请输入歌名或歌手:')
# 获取加密参数
search_signature = search_MD5(key, date_time)
# 搜索链接
search_url = 'https://complexsearch.kugou.com/v2/search/song?'
# 搜索请求参数
search_data = {
'callback': 'callback123',
'srcappid': '2919',
'clientver': '1000',
'clienttime': date_time,
'mid': '3a8e2eda6b55afd434ed43d762bae621',
'uuid': '3a8e2eda6b55afd434ed43d762bae621',
'dfid': '4XSJ8z0tMH343y3JOZ2ZluzO',
'keyword': key,
'page': '1',
'pagesize': '30',
'bitrate': '0',
'isfuzzy': '0',
'inputtype': '0',
'platform': 'WebFilter',
'userid': '0',
'iscorrection': '1',
'privilege_filter': '0',
'filter': '10',
'token': '',
'appid': '1014',
'signature': search_signature
}
# 发送请求
response = requests.get(url=search_url, params=search_data, headers=headers)
"""" 获取数据 """
search_data = response.text
html_data = re.findall('callback123\((.*)', search_data)[0].replace(')', '')
# 把json字符串,转成字典数据
json_data = json.loads(html_data)
# print(json_data)
tb = pt.PrettyTable()
tb.field_names = ['序号', '歌名', '歌手', '专辑', 'id']
lis = []
num = 1
# for循坏遍历
for index in json_data['data']['lists']:
dit = {
'歌名': index['SongName'],
'歌手': index['SingerName'],
'专辑': index['AlbumName'],
'id': index['EMixSongID']
}
lis.append(dit)
tb.add_row([num, index['SongName'], index['SingerName'], index['AlbumName'], index['EMixSongID']])
num += 1
# print(dit)
# print(audio_id)
print(tb)
# audio_id = input('请输入歌曲id:')
# signature = Hash_md5(audio_id, date_time)
def save(audio_id):
signature = Hash_md5(audio_id, date_time)
"""" 发送请求 """
# 请求链接
url = 'https://wwwapi.kugou.com/play/songinfo?'
# 请求参数
data = {
'srcappid': '2919',
'clientver': '20000',
'clienttime': date_time,
'mid': '3a8e2eda6b55afd434ed43d762bae621',
'uuid': '3a8e2eda6b55afd434ed43d762bae621',
'dfid': '4XSJ8z0tMH343y3JOZ2ZluzO',
'appid': '1014',
'platid': '4',
'encode_album_audio_id': audio_id,
'token': '',
'userid': '0',
'signature': signature
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
"""" 获取数据 """
json_data = response.json()
print(json_data)
"""" 解析数据 """
# 歌名
audio_name = json_data['data']['audio_name']
# 音频链接
play_url = json_data['data']['play_url']
# 歌词
lyrics = json_data['data']['lyrics']
# 匹配歌曲信息中的列表部分并替换为空字符串
song_info_cleaned = re.sub("\[(.*?)\]", "", lyrics)
# 图片
img = json_data['data']['img']
music_img = requests.get(url=img, headers=headers).content
#print(img)
"""
保存数据
图片/音频/视频/特定格式的文件 <获得链接>
对于链接发送请求,获得二进制数据进行保存
"""
print(audio_name,play_url)
# 对于音频发送请求,获取二进制数据
music_content = requests.get(url=play_url, headers=headers).content
with open('酷狗音乐\\' + audio_name + '.mp3', mode='wb+') as f:
# 写入保存数据
f.write(music_content)
# print(response.json())
print(f'{audio_name}.mp3下载完成')
# print('下载完成')
# 歌词
with open(f'酷狗音乐\\{audio_name}.txt', 'w+', encoding="utf-8") as f:
f.write(song_info_cleaned)
print(f'{audio_name}.txt下载完成')
# 图片
with open('酷狗音乐\\' + audio_name + '.jpg', mode='wb+') as f:
# 写入保存数据
f.write(music_img)
# print(response.json())
print(f'{audio_name}.jpg下载完成')
if __name__ == '__main__':
# save(audio_id)
page = input('请输入你要下载的歌曲序号 / 全部下载<0>:')
try:
if page == '0':
for li in lis:
save(audio_id=li['id'])
else:
save(audio_id=lis[int(page) - 1]['id'])
except Exception as e:
print('你可能输入有误', e)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第二十章 调用Callout Library函数 - 使用 $ZF(-6) 按用户索引访问库
- 3.Java设计模式-创建型模式-单例模式-饿汉式
- 【C++】结构体案例
- QT+OSG/osgEarth编译之五十一:ColladaDom编译(一套代码、一套框架,跨平台编译,版本:ColladaDom-2.4)
- 探索无限:山海鲸可视化搭建的地理展览馆的奇幻之旅
- 并发编程(四)
- 计算机毕业设计-----SSM自习室图书馆座位预约管理系统
- 计算机专业毕业生,找工作学C++还是Java?
- ubuntu22: nvtop no gpu to monitor.
- 线程池介绍