机器学习-决策树-异常检测-主成分分析
决策树(Decision Tree)
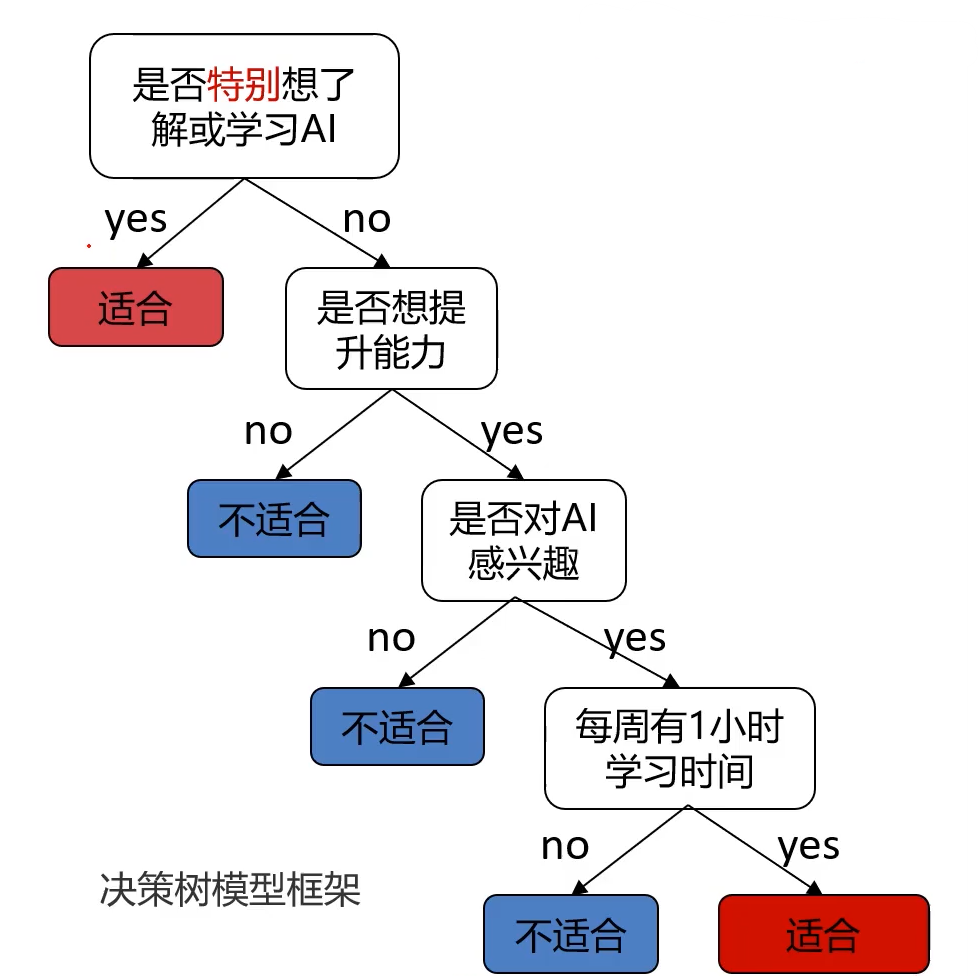
一种对实例进行分类的树形结构,通过多层判断区分目标所属类别
本质:通过多层判断,从训练数据集中归纳出一组分类规则
优点:
- 计算量小,运算速度快
- 易于理解,可清晰查看个属性的重要性
缺点:
- 忽略属性间的相关性
- 样本类别分布不均匀时,容易影响模型表现
决策树求解

问题核心:特征选择,每一个节点,应该选用哪个特征
三种求解方法:
- ID3
- C4.5
- CART
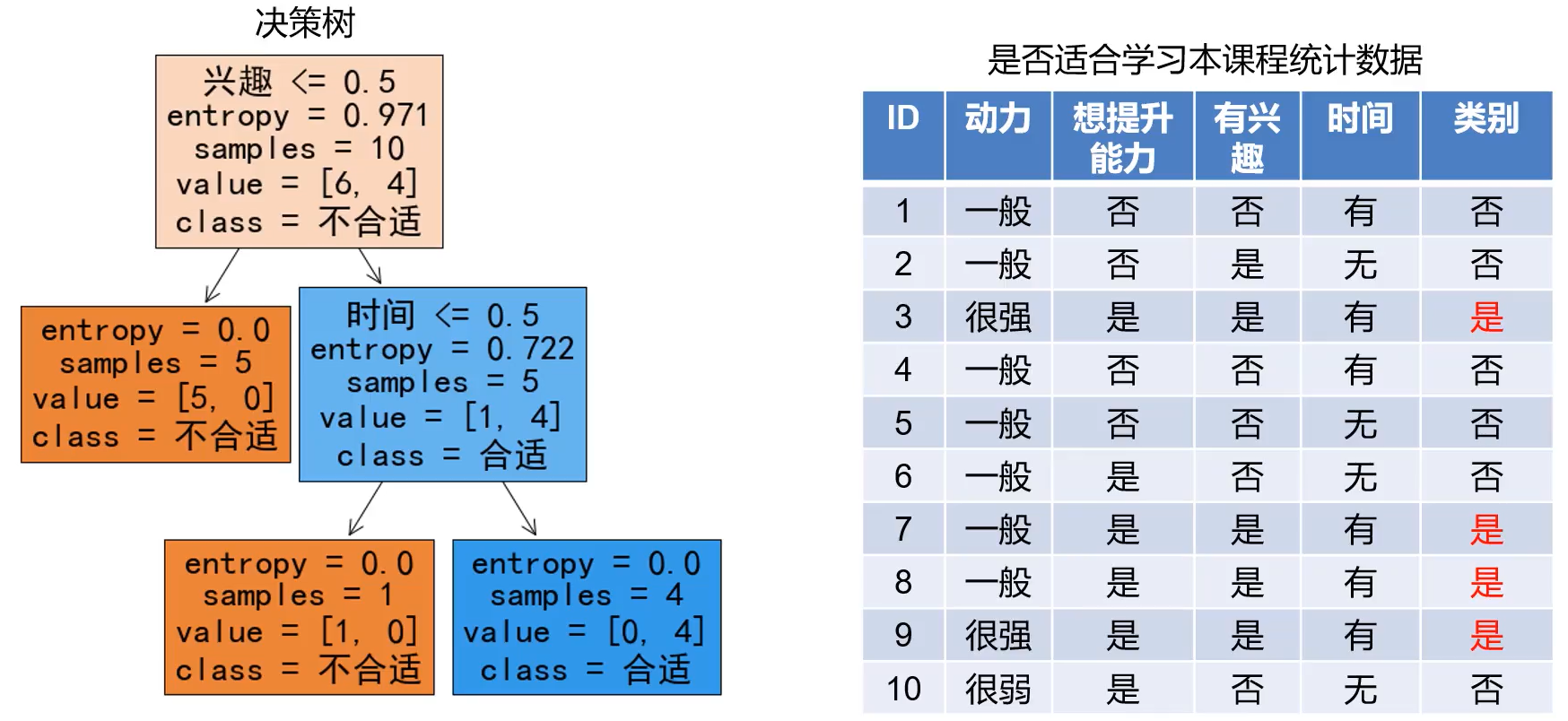
ID3:利用信息熵原理选择信息增益最大的属性作为分类属性,递归地拓展决策树的分枝,完成决策树的构造



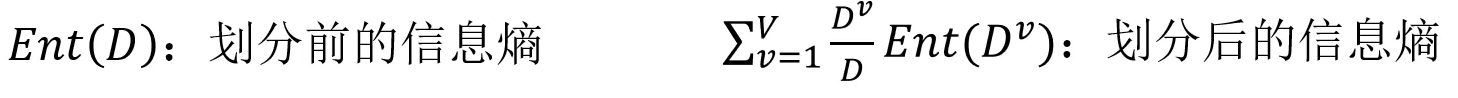
目标:划分后样本发布不确定性尽可能小,即划分后信息熵小,信息增益大
异常检测(Anomaly Detection)
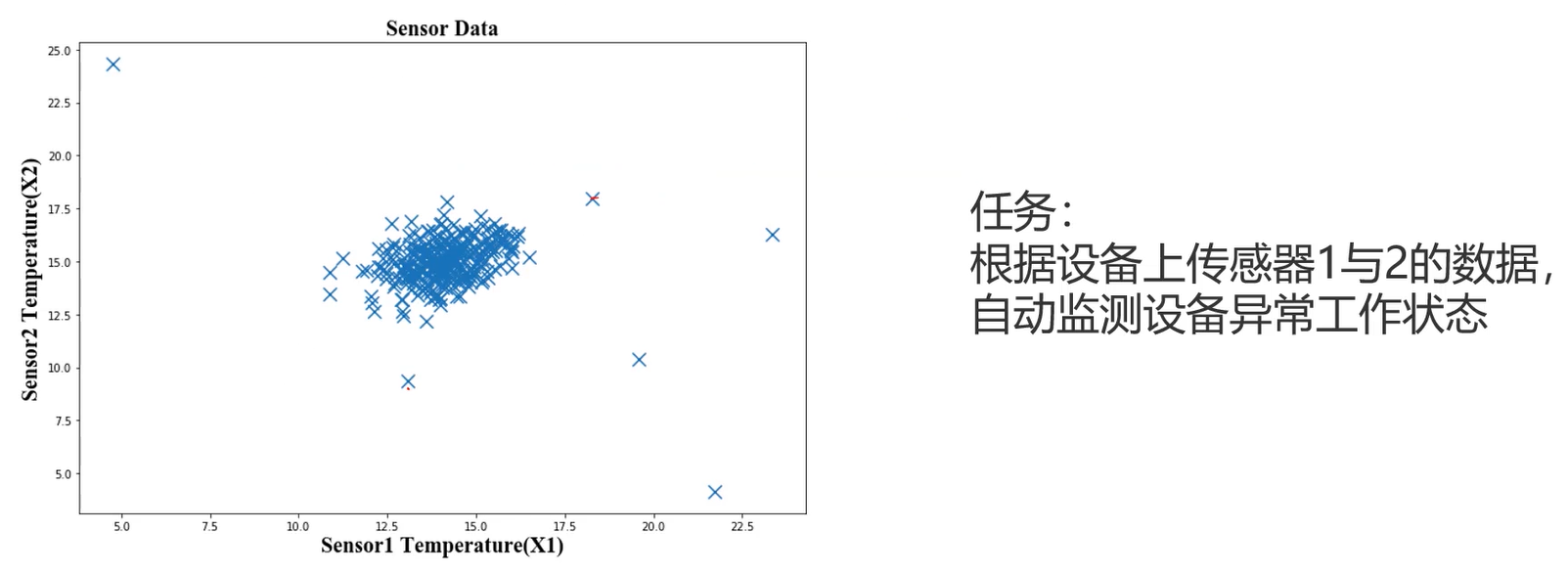
自动寻找图片中异常的目标

案例:
异常消费检测、劣质产品检测、缺陷基因检测…
根据输入数据,对不符合预期模式的数据进行识别
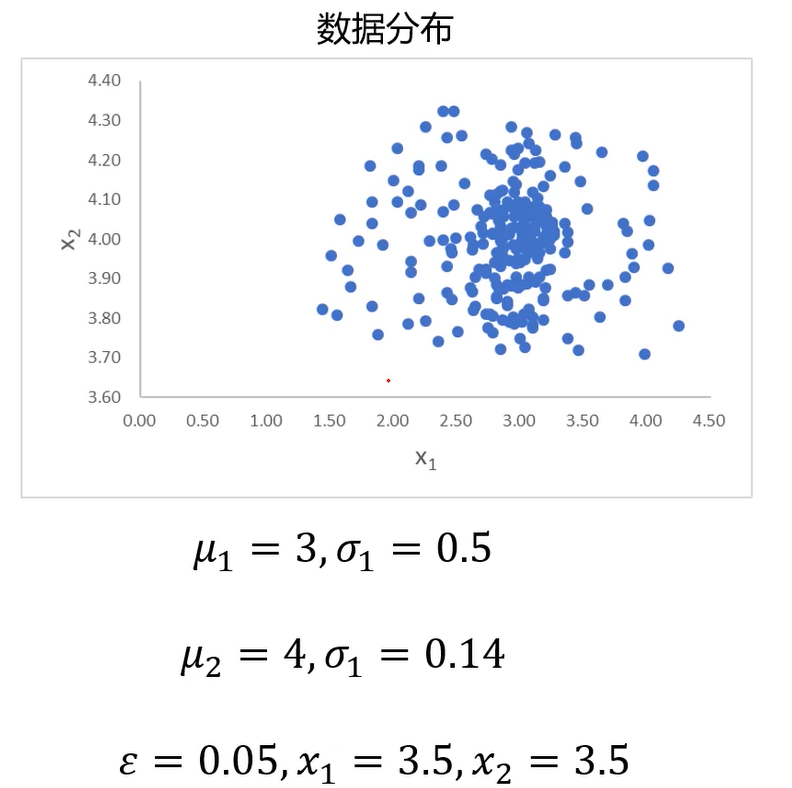
一维数据集:
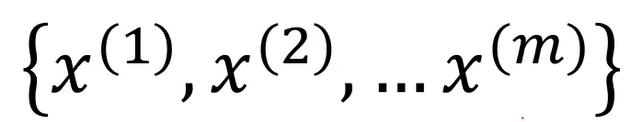

寻找低概率数据(事件)
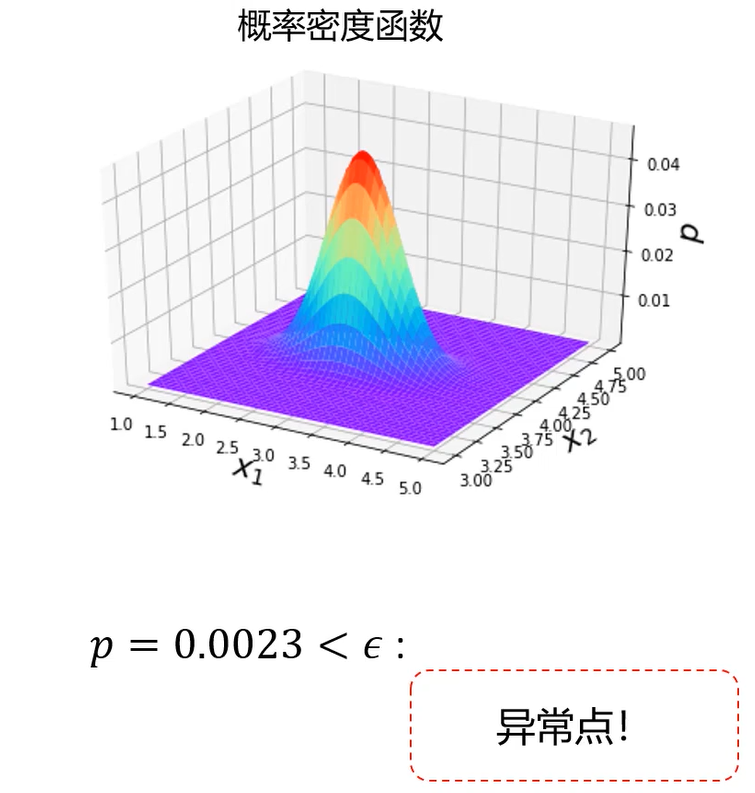
概率密度
概率密度函数一个描述随机变量在某个确定的取值点附件的可能性的函数
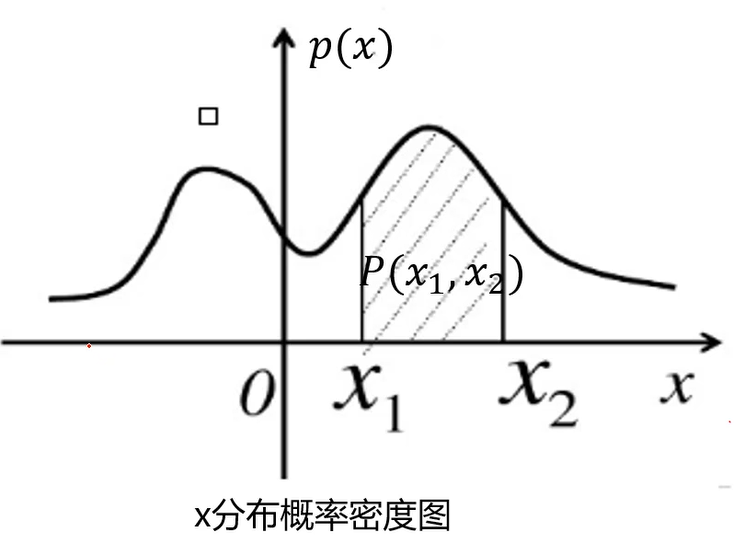
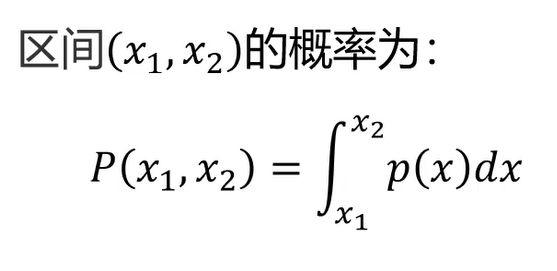
高斯分布

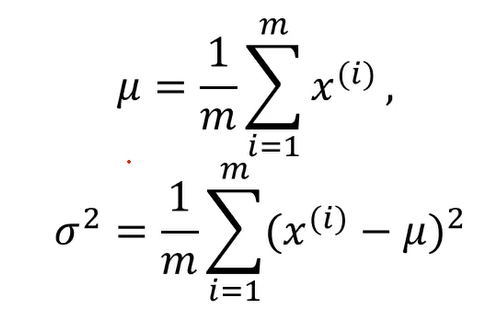
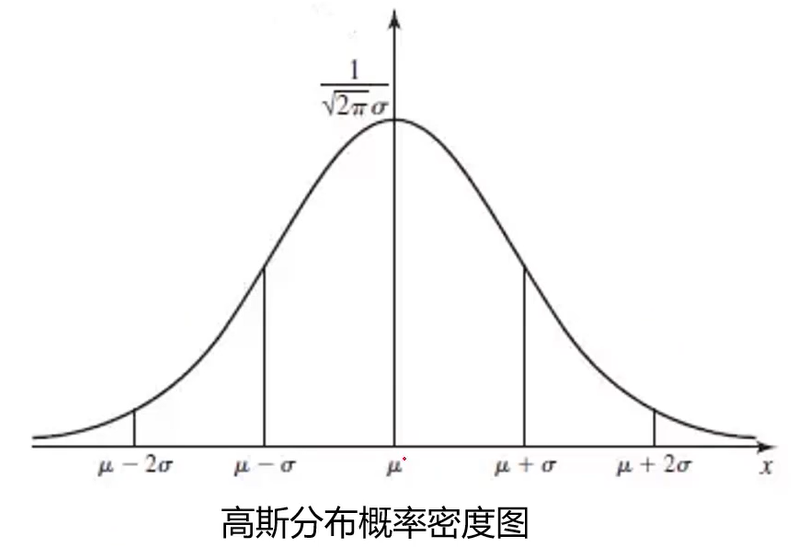
基于高斯分布实现异常检测


3、根据数据点概率,进行判断


当数据维度高于一维
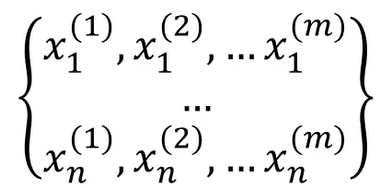
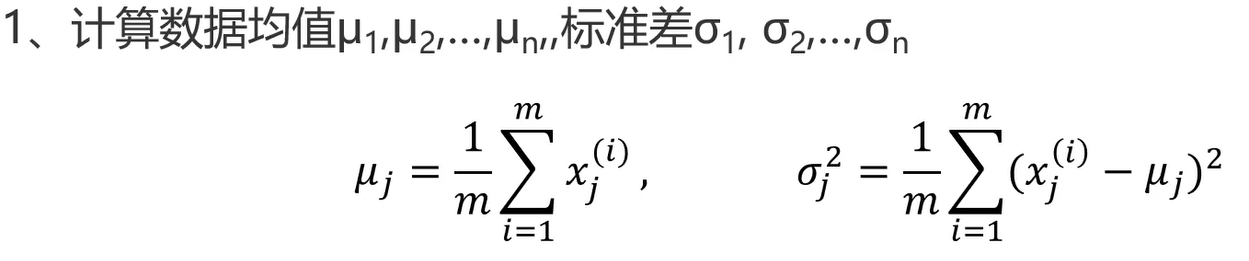
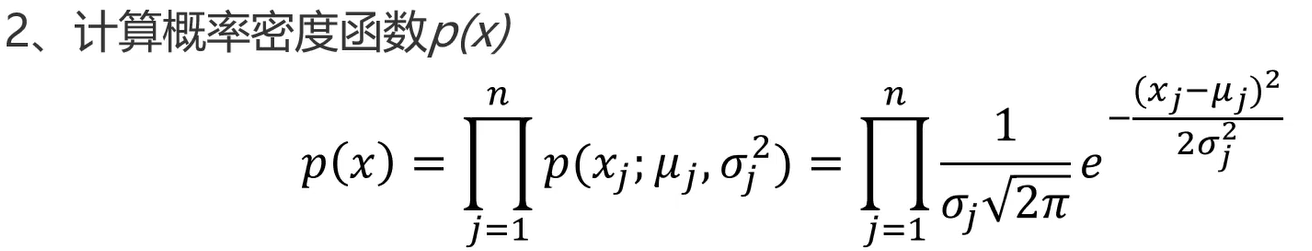
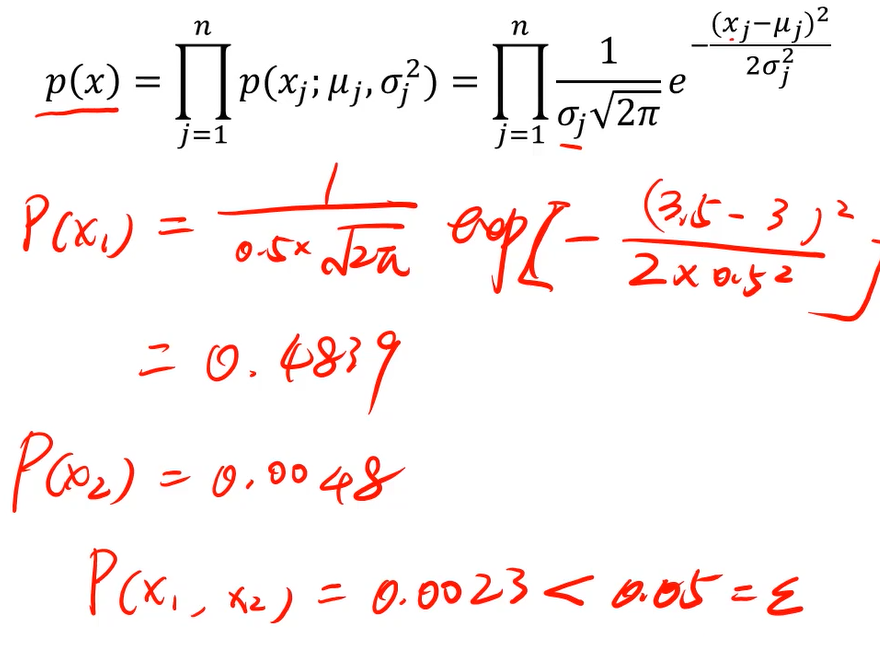
主成分分析(PCA)
数据降维(Dimensionality Reduction)
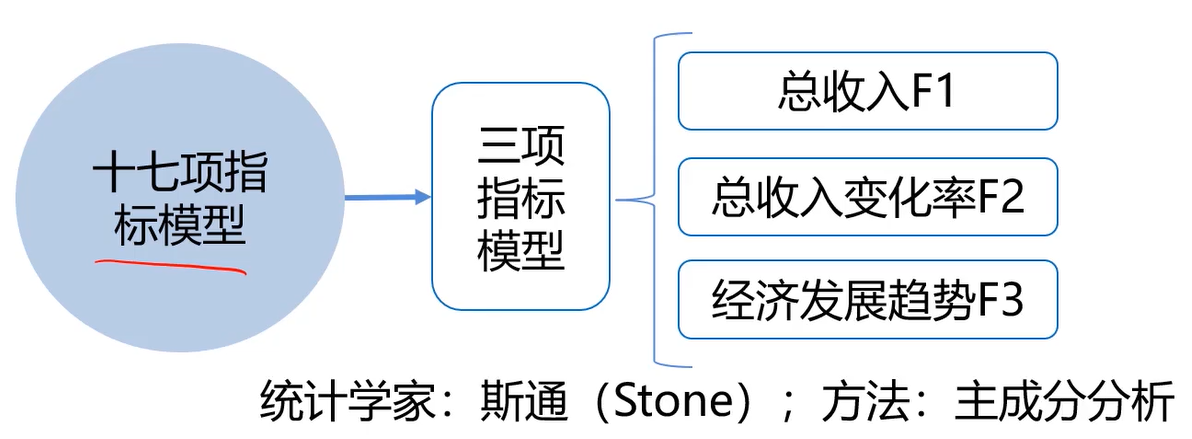
数据降维案例(经济分析)
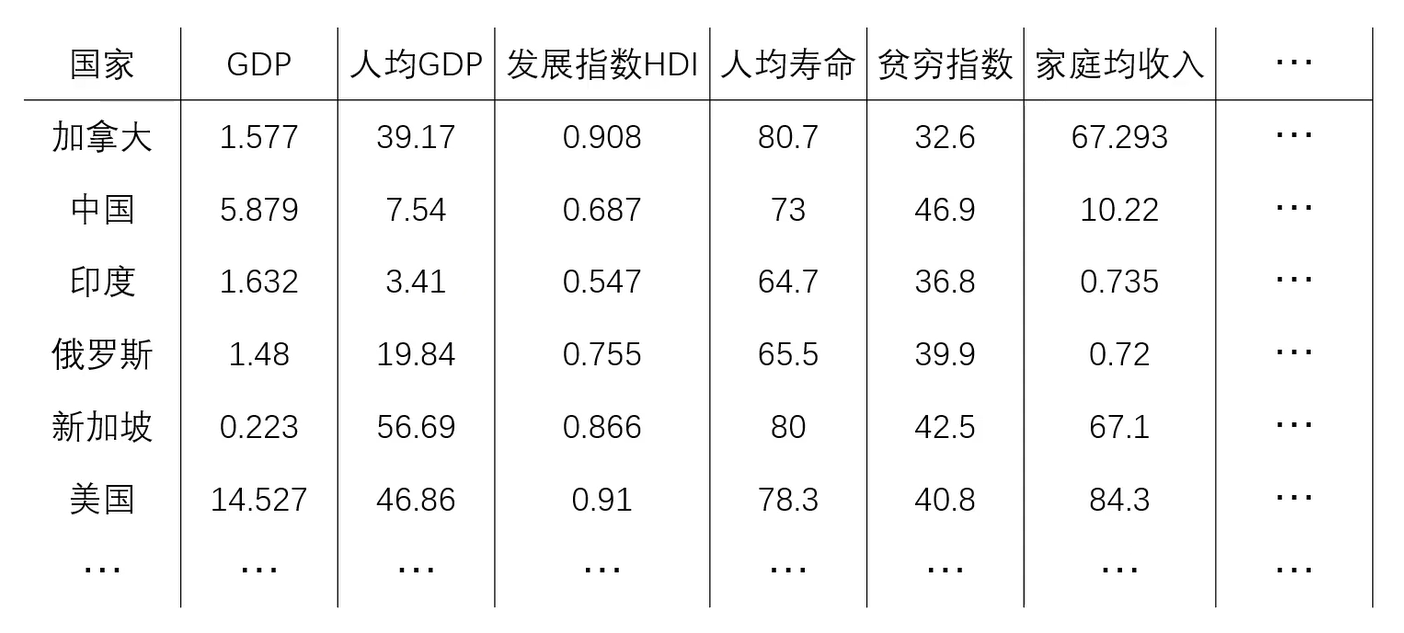
任务(真实事件):通过美国1929-1938年各年经济数据,预测国民收入与支出
数据包括:雇主补贴、消费资料和生产资料、纯公共支出、净增库存、股息、利息、外贸平衡等十七个指标
数据降维:指在某些限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程
作用:
- 减少模型分析数据量,提升处理效率,降低计算难度
- 实现数据可视化
数据量下降举例:2D数据降维到1D数据
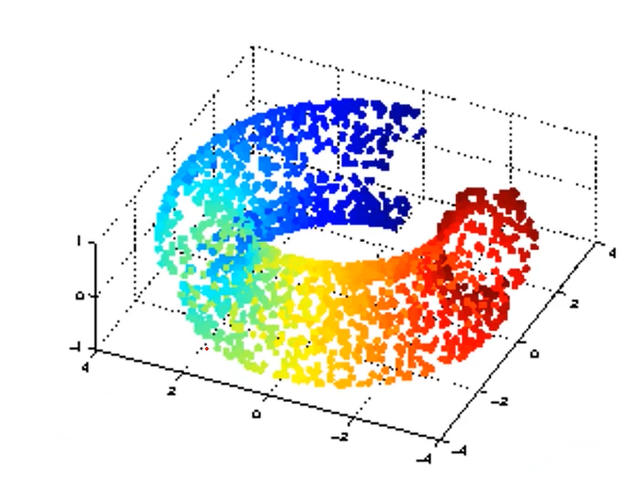
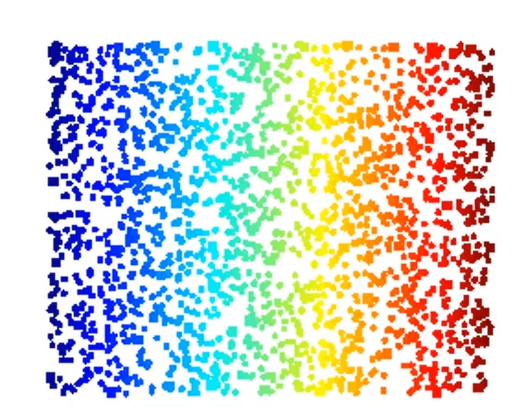
3D数据降维到2D数据
国家分布可视化(基于50项经济指标)
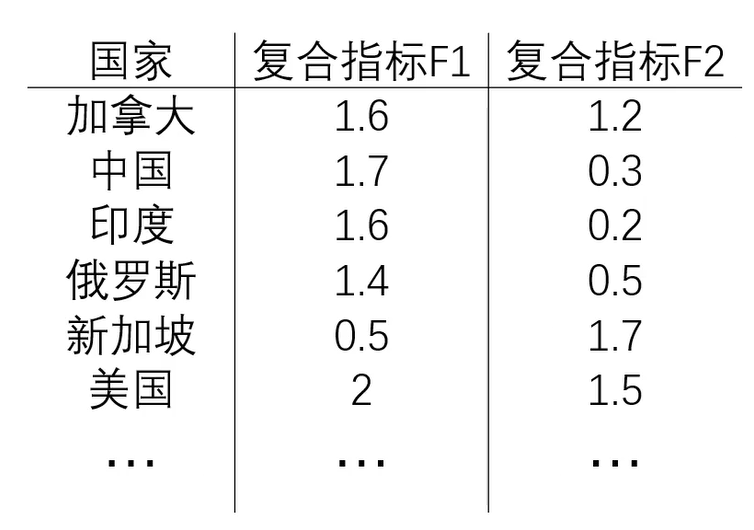
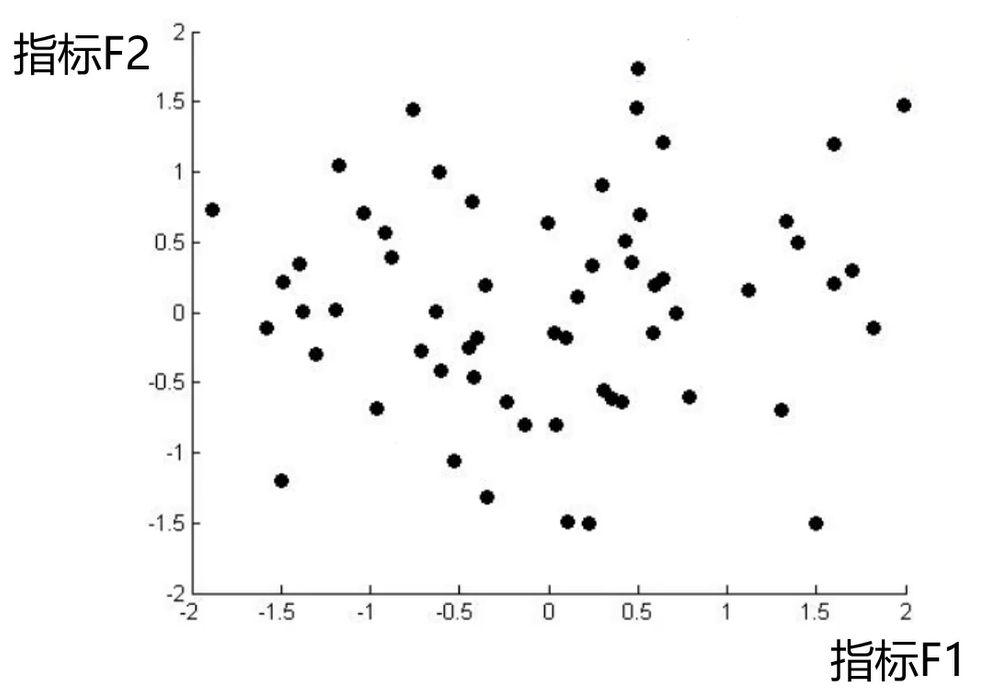
数据降维的实现:主成分分析(PCA)
PCA(principal components analysis):数据降维技术中,应用最最多的方法
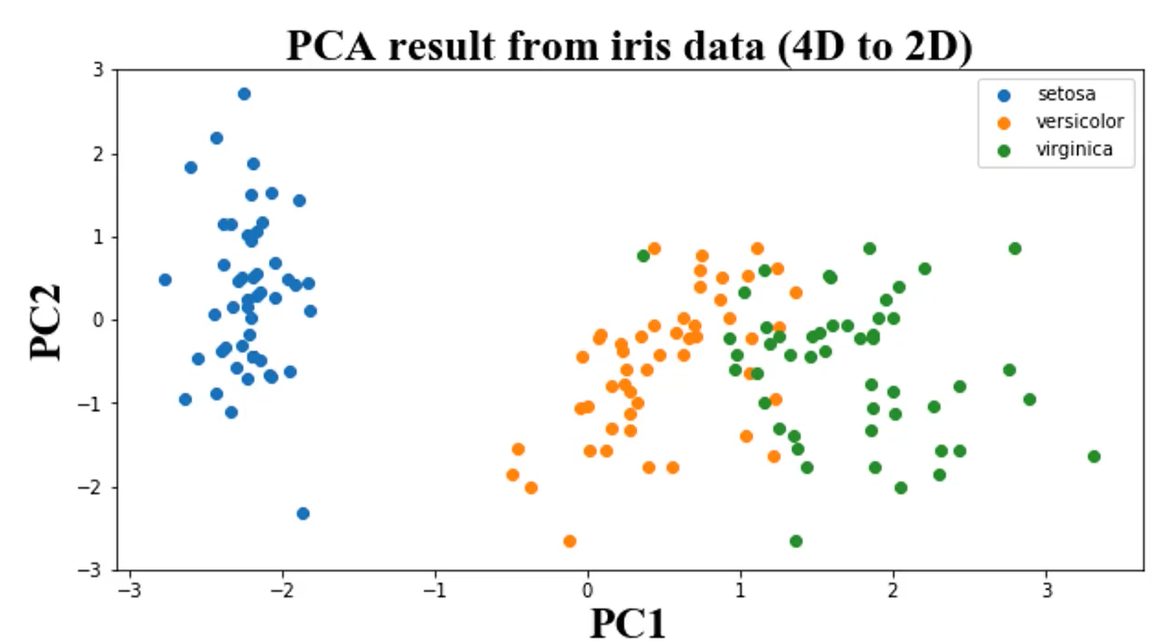
目标:寻找k(k<n)维新数据,使它们反映事物的主要特征
核心:在信息损失尽可能少的情况下,降低数据维度
如何保留主要信息:投影后的不同特征数据尽可能分得开(即不相关)
如何实现?
使投影后数据的方差最大,因为方差越大数据也越分散
计算过程:
- 原始数据预处理
- 计算协方差矩阵特征向量、及数据在各特征向量投影的方差
- 根据需求(任务指定或方差比例)确定降维维度k
- 选取k维特征向量,计算数据在其形成空间的投影
实战准备
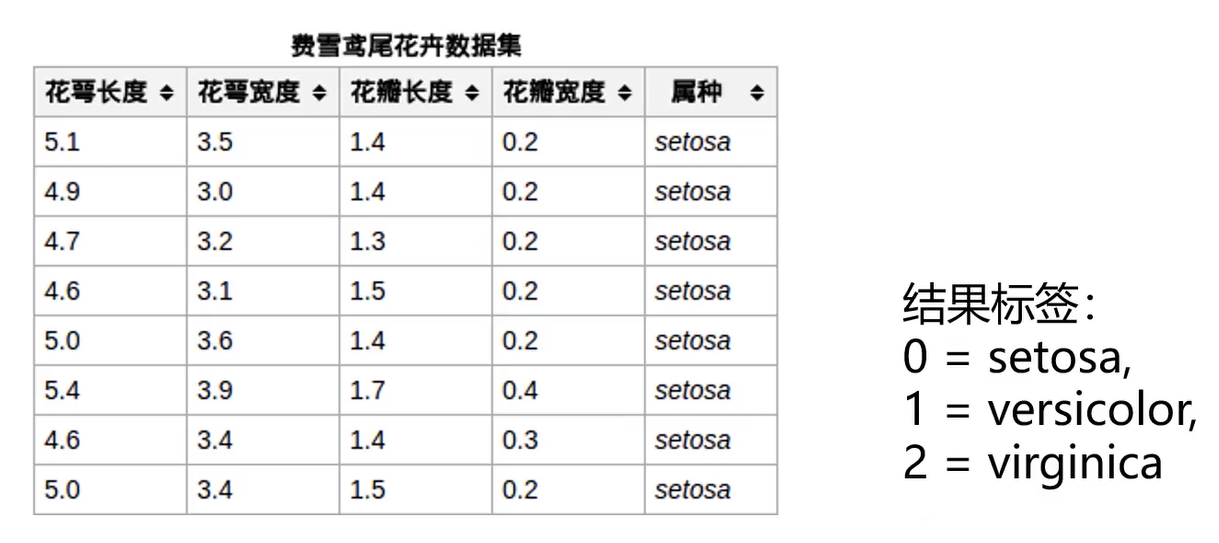
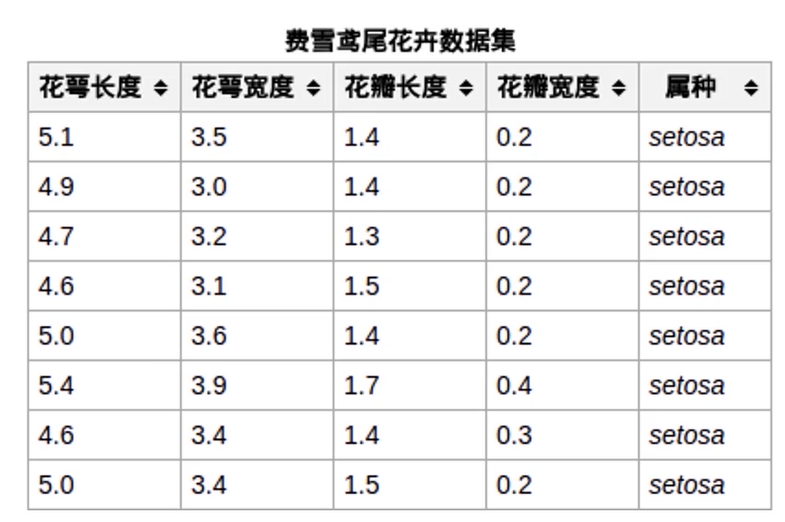
lris数据集
lris鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例
3类共150条数据,每类各50个数据
每条数据都有4项特征:
花萼长度(Sepal Length)、花萼宽度(Sepal Width)、
花瓣长度(Petal Length)、花瓣宽度(Petal Width)
通过4个特征预测花卉属于三类(iris-setosa,iris-versicolour,iris-virginica)中的哪一品种
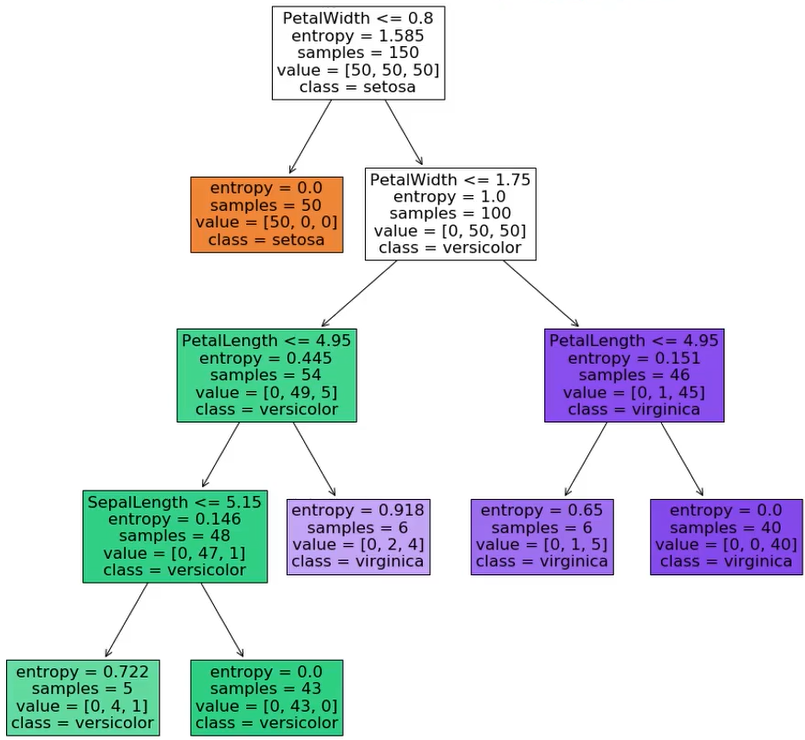
决策树实现iris数据分类
模型训练
from sklearn import tree
dc_tree=tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
dc_tree.fit(X,y)
可视化决策树
tree.plot_tree(dc_tree,filled='True',
feature_names=['SepalLength','SepalWidth',
'PetalLength','PetalWidth'],
class_names=['setosa','versicolor','virginica'])
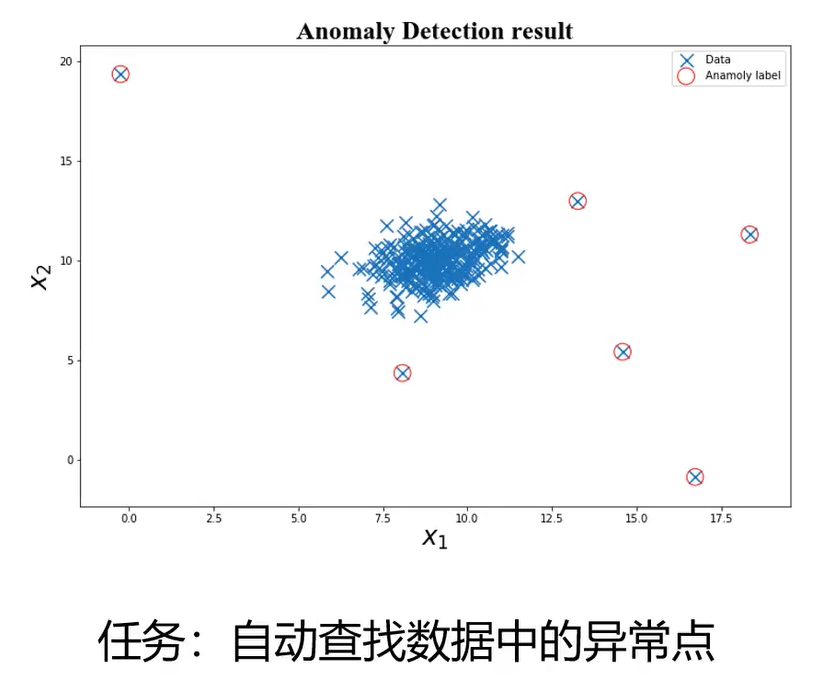
异常数据检测
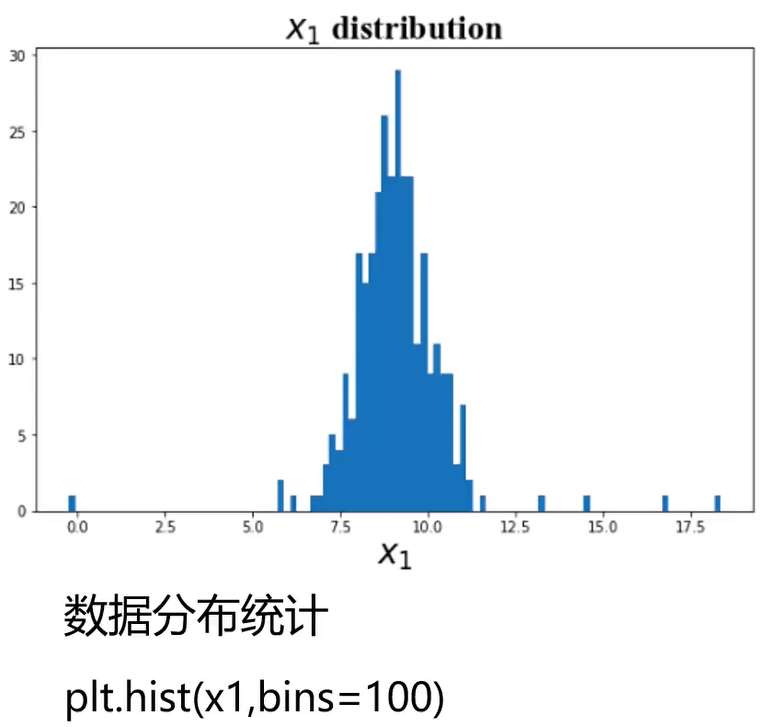
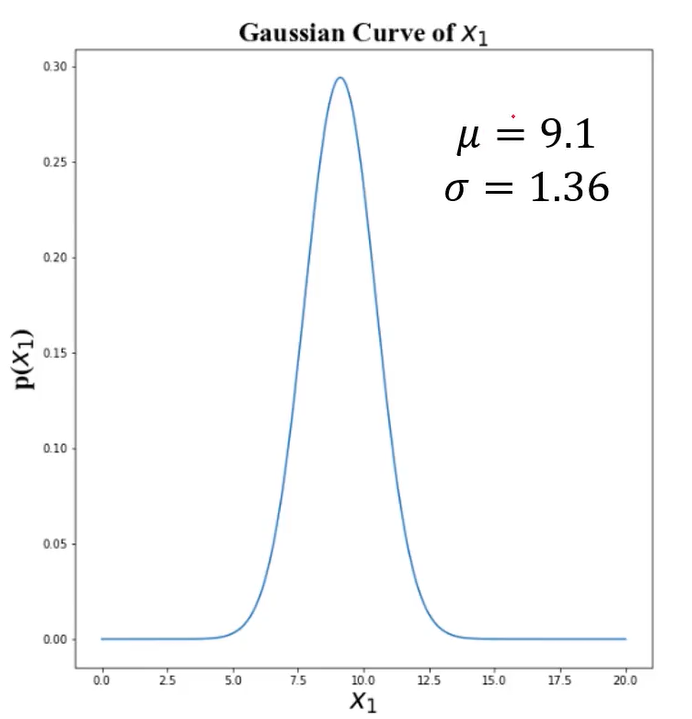
计算数据均值、标准差:
x1_mean = x1.mean()
x1_sigma = x1.std()
计算对应的高斯分布数值:
from scipy.stats import norm
x1_range = np.linspace(0,20,300)
normal1 = norm.pdf(x1_range,x1_mean,x1_sigma)
可视化高斯分布曲线
plt.plot(x1_range,normal1)
模型训练:
from sklearn.covariance import EllipticEnvelope
clf=EllipticEnvelope()
clf.fit(data)
可视化异常数据:
annamoly_points = plt.scatter(data.loc[:,'x1'][y_predict==-1],
data.loc[:,'x2'][y_predict==-1],
marker = 'o',
facecolor = "none",
edgecolor = "red",s=250)
PCA(iris数据降维后分类)
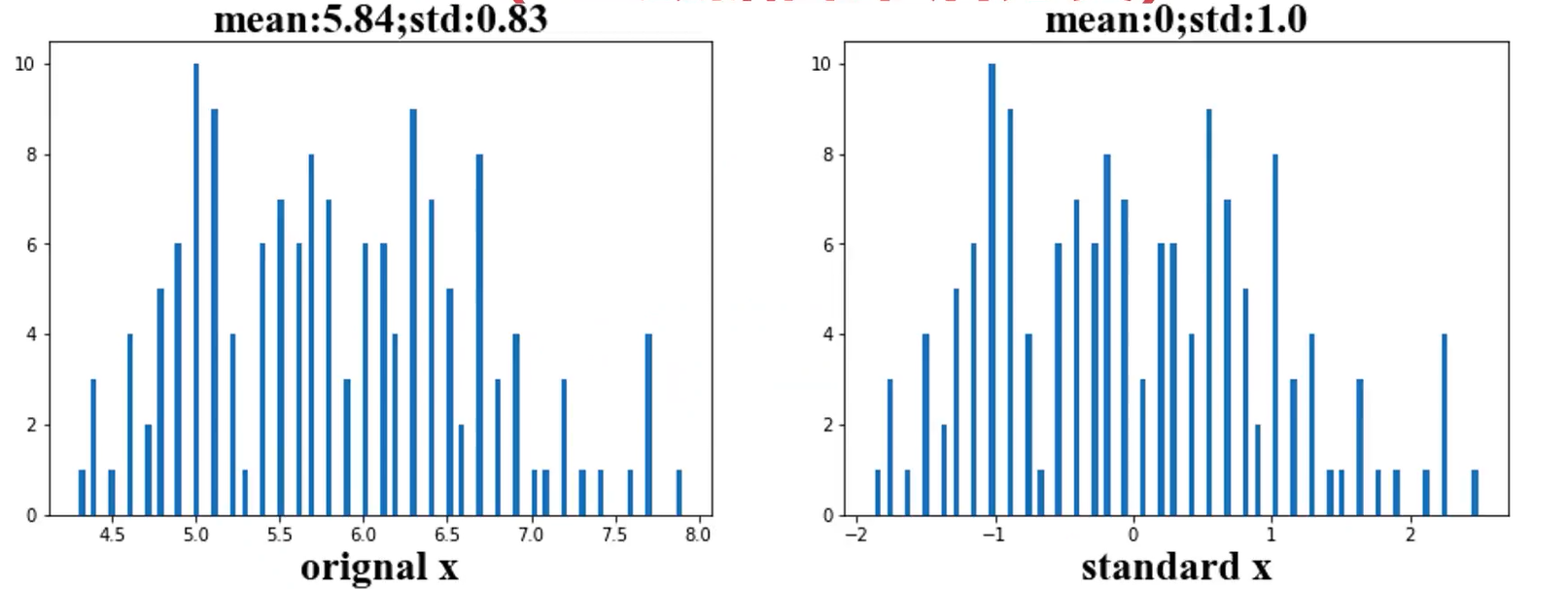
数据标准化预处理:
from sklearn.preprocessing import StandardScaler
X_norm = StabdardScaler().fit_transform(X)
模型训练获得PCA降维后数据:
from sklearn.decomposition import PCA
pca = PCA(n_components=4)
X_reduced = pca.fit_transform(X_norm)
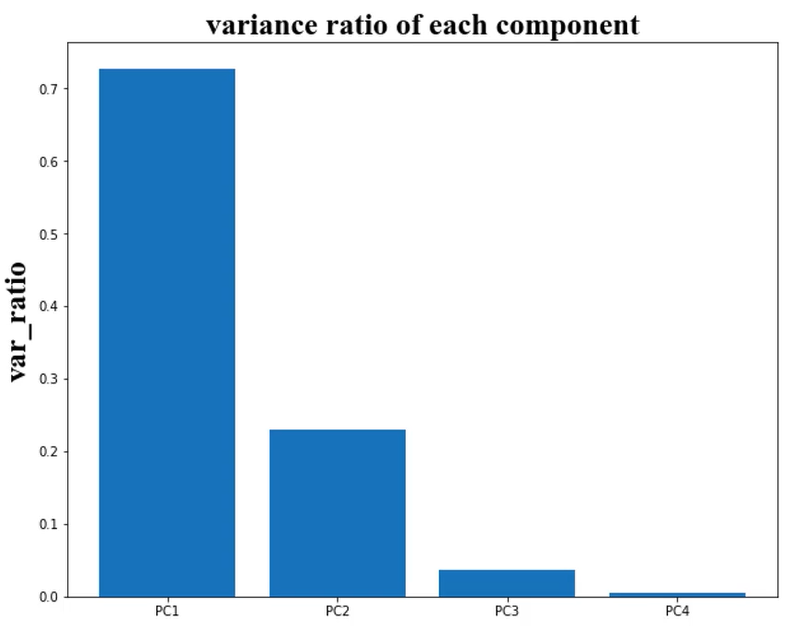
计算个成分投影数据方差比例:
var_ratio = pca.explained_variance_ratio_
可视化方差比例:
plt.bar([1,2,3,4],var_ratio)
plt.title('variance ratio of each component')
plt.xticks([1,2,3,4],['PC1','PC2','PC3','PC4'])
plt.ylabel('var_ratio')
plt.show()
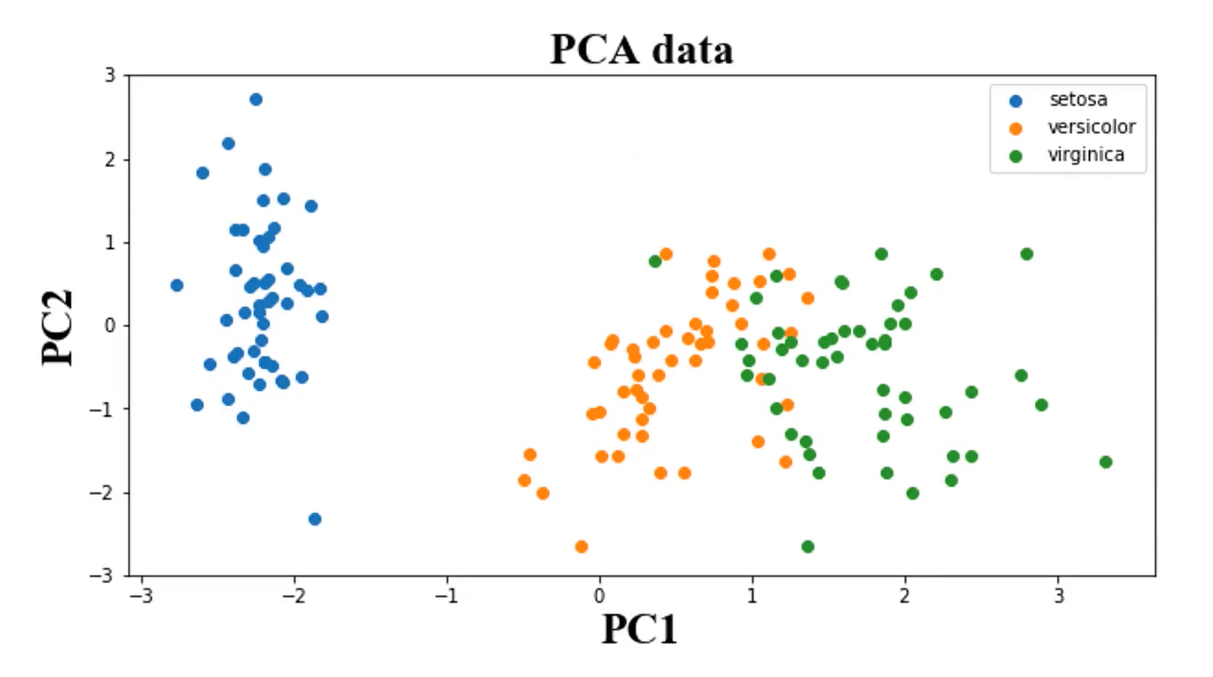
可视化PCA后的数据:
setosa = plt.scatter(X_reduced[:,0][y==0],X_reduced[:,1][y==0])
versicolor = plt.scatter(X_reduced[:,0][y==1],X_reduced[:,1][y==1])
virginica = plt.scatter(X_reduced[:,0][y==2],X_reduce[:,1][y==1])
实战-决策树实现iris数据分类
- 基于iris_data.csv数据,建立决策树模型,评估模型表现
- 可视化决策树结构
- 修改min_samples_leaf参数,对比模型结果
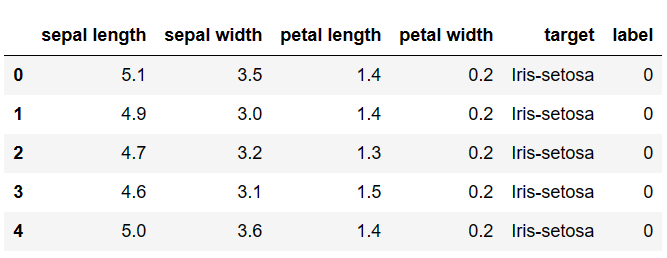
导入导加载数据
import pandas as pd
import numpy as np
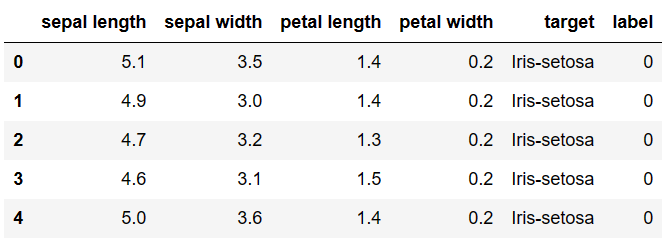
data = pd.read_csv('iris_data.csv')
data.head()
赋值
X=data.drop(['target','label'],axis=1)
y=data.loc[:,'label']
模型建立 训练
from sklearn import tree
dc_tree = tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
dc_tree.fit(X,y)
评估
y_predict = dc_tree.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
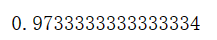
from matplotlib import pyplot as plt
fig=plt.figure(figsize=(10,10))
tree.plot_tree(dc_tree,filled='True',feature_names=['SepalLength','SepalWidth','PatalLength','PetalWidth'],class_names=['setosa','versicolor','virginica'])
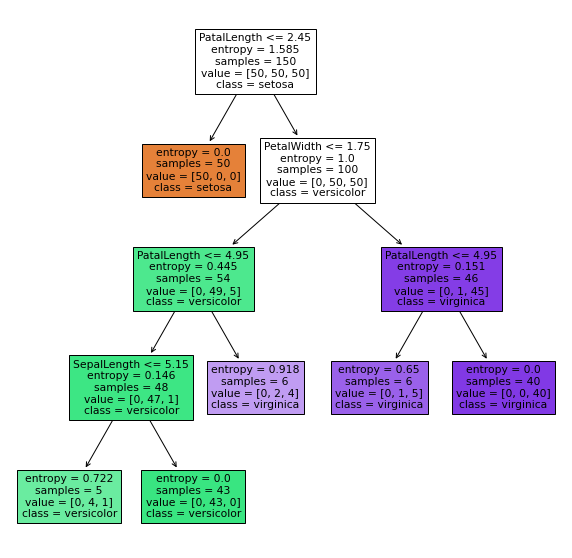
实战-异常数据检测
- 基于anomaly_data.csv数据,可视化数据分布情况、及其对应高斯分布的概率密度函数
- 建立模型,实现异常数据点预测
- 可视化异常检测处理结果
- 修改概率分布阈值
EllipticEnvelope(contamination=0.1)中的contamination,查看阈值改变对结果的影响
导入包 加载数据
import pandas as pd
import numpy as np
data = pd.read_csv('anomaly_data.csv')
data.head()
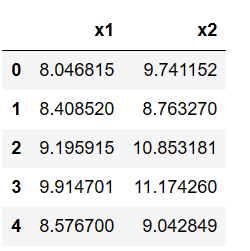
数据可视化
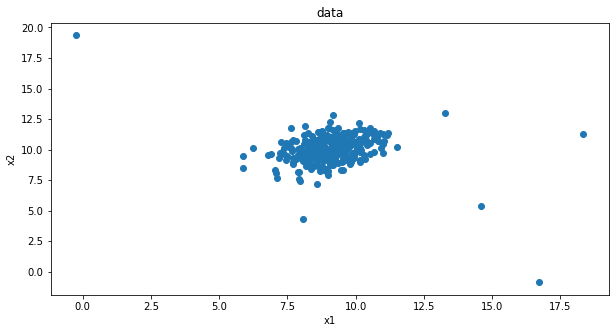
from matplotlib import pyplot as plt
fig1=plt.figure(figsize=(10,5))
plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'])
plt.title('data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
赋值
x1=data.loc[:,'x1']
x2=data.loc[:,'x2']
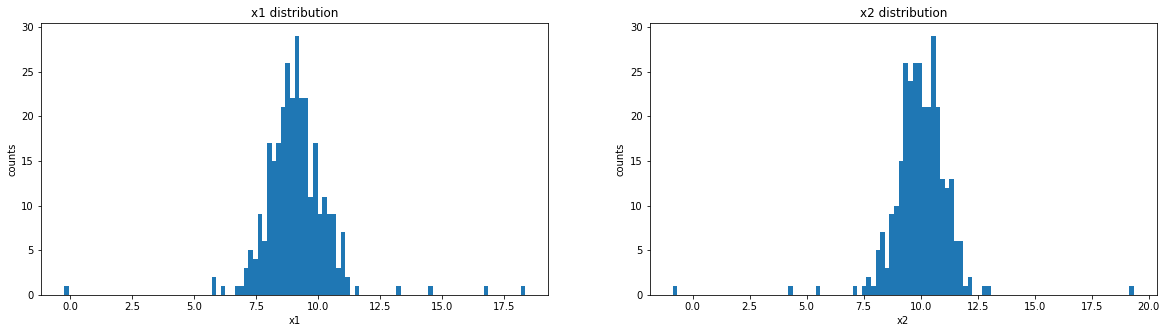
可视化数据分布
fig2=plt.figure(figsize=(20,5))
plt.subplot(121)
plt.hist(x1,bins=100)
plt.title('x1 distribution')
plt.xlabel('x1')
plt.ylabel('counts')
plt.subplot(122)
plt.hist(x2,bins=100)
plt.title('x2 distribution')
plt.xlabel('x2')
plt.ylabel('counts')
plt.show()
计算均值和标准差
x1_mean = x1.mean()
x1_sigma = x1.std()
x2_mean = x2.mean()
x2_sigma = x2.std()
print(x1_mean,x1_sigma,x2_mean,x2_sigma)
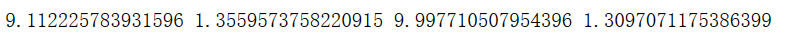
高斯分布的概率密度函数
from scipy.stats import norm
x1_range = np.linspace(0,20,300)
x1_normal = norm.pdf(x1_range,x1_mean,x1_sigma)
x2_range = np.linspace(0,20,300)
x2_normal = norm.pdf(x2_range,x2_mean,x2_sigma)
可视化
fig2 = plt.figure(figsize=(20,5))
plt.subplot(121)
plt.plot(x1_range,x1_normal)
plt.title('normal p(x1)')
plt.subplot(122)
plt.plot(x2_range,x2_normal)
plt.title('normal p(x2)')
plt.show()

建立模型 训练
from sklearn.covariance import EllipticEnvelope
ad_model = EllipticEnvelope()
ad_model.fit(data)
预测结果
y_predict = ad_model.predict(data)
print(pd.value_counts(y_predict))

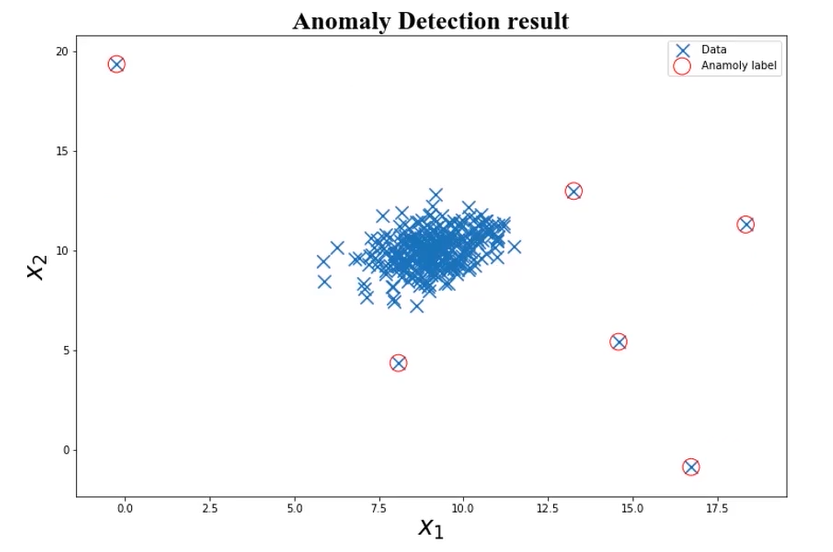
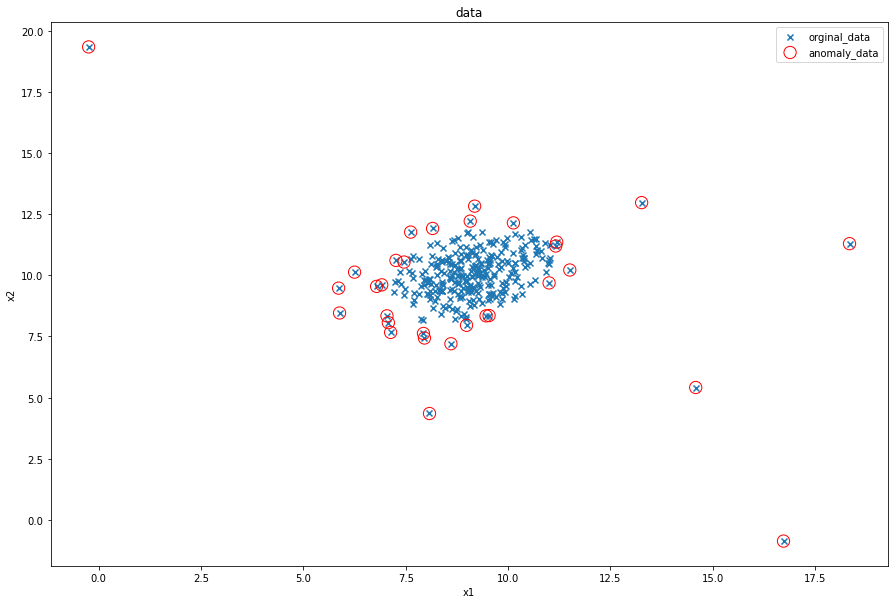
可视化
from matplotlib import pyplot as plt
fig4=plt.figure(figsize=(15,10))
orginal_data=plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'],marker='x')
anomaly_data=plt.scatter(data.loc[:,'x1'][y_predict==-1],data.loc[:,'x2'][y_predict==-1],marker='o',facecolor="none",edgecolors='red',s=150)
plt.title('data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend((orginal_data,anomaly_data),('orginal_data','anomaly_data'))
plt.show()
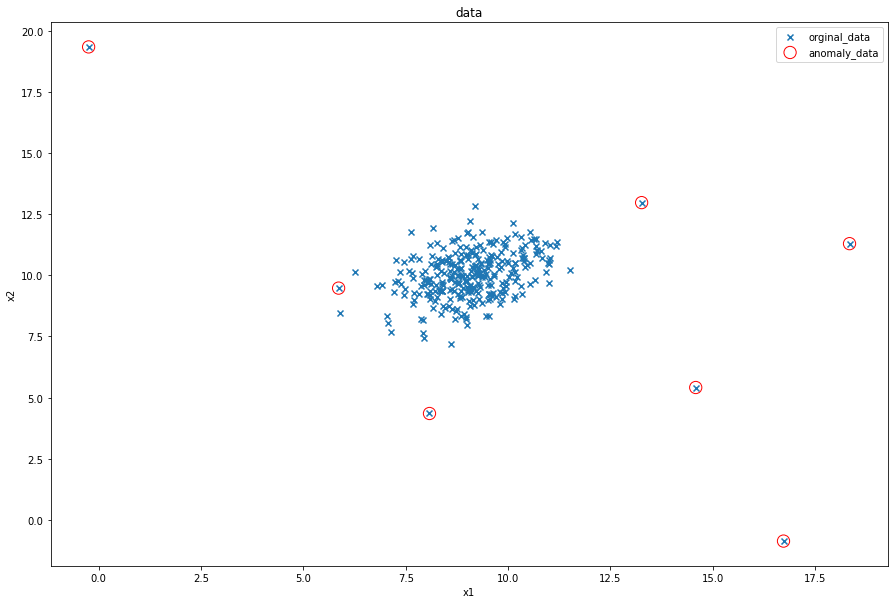
修改概率分布阈值
ad_model = EllipticEnvelope(contamination=0.02)
ad_model.fit(data)
y_predict = ad_model.predict(data)
fig5=plt.figure(figsize=(15,10))
orginal_data=plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'],marker='x')
anomaly_data=plt.scatter(data.loc[:,'x1'][y_predict==-1],data.loc[:,'x2'][y_predict==-1],marker='o',facecolor="none",edgecolors='red',s=150)
plt.title('data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend((orginal_data,anomaly_data),('orginal_data','anomaly_data'))
plt.show()
实战PAC(iris数据降维后分类)
- 基于iris_data.csv数据,建立KNN模型实现数据分类(n_neighbors=3)
- 对数据进行标准化处理,选取一个维度可视化处理后的效果
- 进行与原数据等维度PCA,查看各主成分的方差比例
- 保留合适的主成分,可视化降维后的数据
- 基于降维后数据建立KNN模型,与原数据表现进行对比
载入数据
import pandas as pd
import numpy as np
data = pd.read_csv('iris_data.csv')
data.head()
赋值
X=data.drop(['target','label'],axis=1)
y=data.loc[:,'label']
建立模型 训练 计算准确率
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X,y)
y_predict = KNN.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
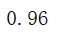
数据标准化处理
from sklearn.preprocessing import StandardScaler
X_norm = StandardScaler().fit_transform(X)
查看均值和标准差 对比
x1_mean = X.loc[:,'sepal length'].mean()
x1_norm_mean = X_norm[:,0].mean()
x1_sigma = X.loc[:,'sepal length'].std()
x1_norm_sigma = X_norm[:,0].std()
print(x1_mean,x1_sigma,x1_norm_mean,x1_norm_sigma)
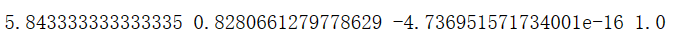
可视化
from matplotlib import pyplot as plt
fig1=plt.figure(figsize=(20,10))
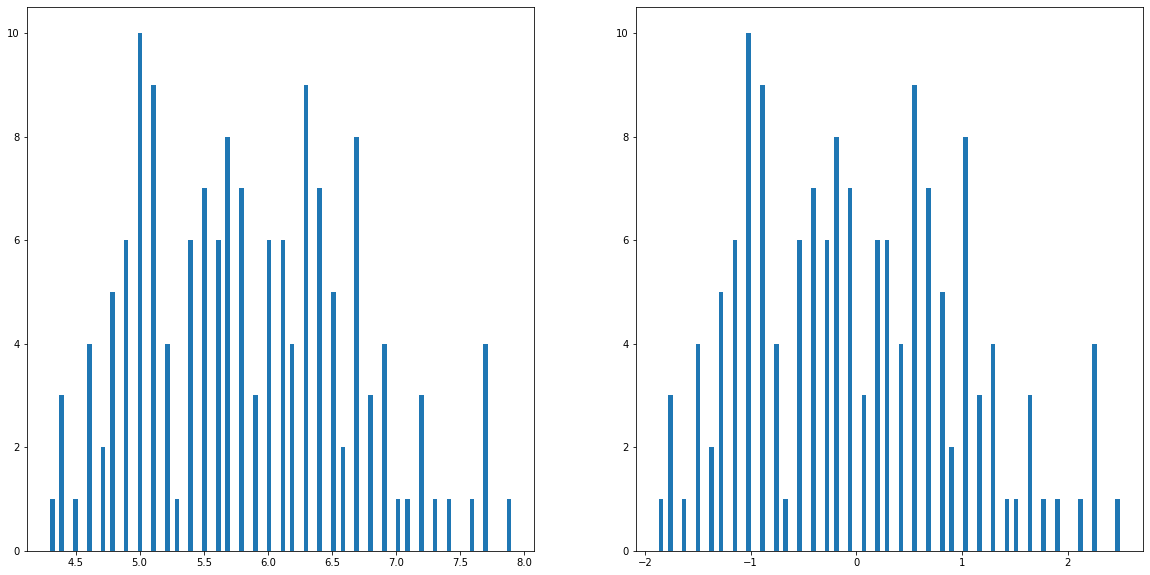
plt.subplot(121)
plt.hist(X.loc[:,'sepal length'],bins=100)
plt.subplot(122)
plt.hist(X_norm[:,0],bins=100)
plt.show()
PCA处理
from sklearn.decomposition import PCA
pca = PCA(n_components=4)
X_pca = pca.fit_transform(X_norm)
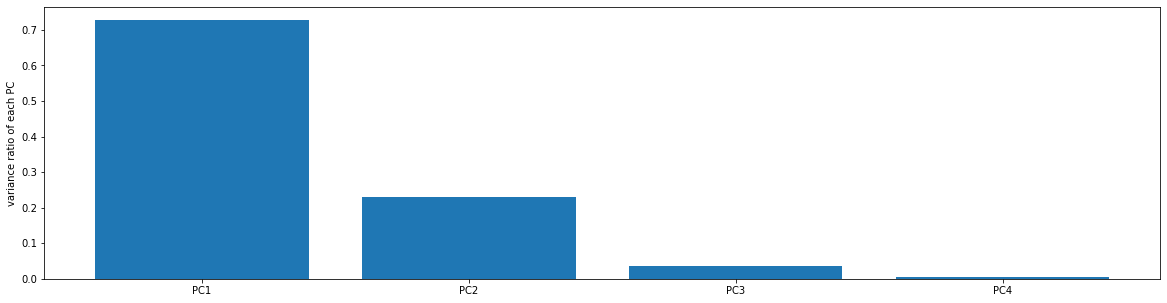
var_ratio = pca.explained_variance_ratio_
print(var_ratio)

可视化
fig2=plt.figure(figsize=(20,5))
plt.bar([1,2,3,4],var_ratio)
plt.xticks([1,2,3,4],['PC1','PC2','PC3','PC4'])
plt.ylabel('variance ratio of each PC')
plt.show()
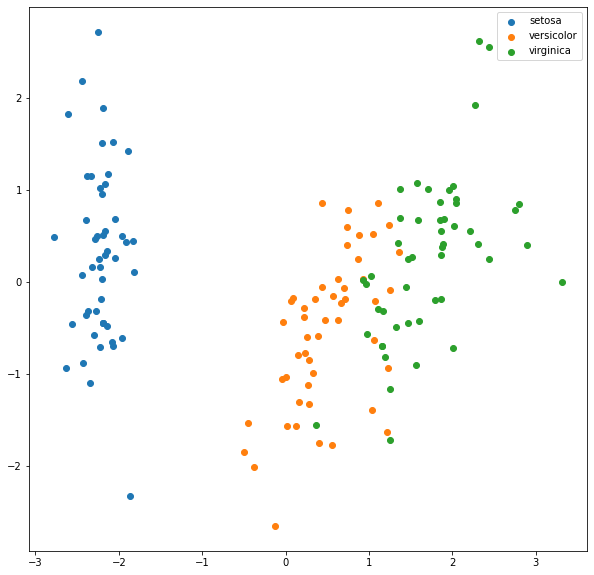
保留主成分
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_norm)
fig3=plt.figure(figsize=(10,10))
setosa=plt.scatter(X_pca[:,0][y==0],X_pca[:,1][y==0])
versicolor = plt.scatter(X_pca[:,0][y==1],X_pca[:,1][y==1])
virginica = plt.scatter(X_pca[:,0][y==2],X_pca[:,1][y==2])
plt.legend((setosa,versicolor,virginica),('setosa','versicolor','virginica'))
plt.show()
对比
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X,y)
y_predict = KNN.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X_pca,y)
y_predict = KNN.predict(X_pca)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
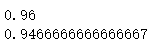
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vcomp120.dll缺失怎么解决,vcomp120.dll丢失的详细修复方法分享(总共5种方法)
- pandas的drop_duplicates无法去重问题
- 【AI图片故事】AI设计图片-未来机器人的“智慧”与工人的“情感”
- DAY36
- python SVM 保存和加载模型参数
- 仿三方智能对话分析原始会话窗口
- java的json解析
- Swagger2以及Spring Boot整合Swagger2教程
- Linux系统OpenGL安装
- input输入框输入只能输入数字、字母等组合的正则表达式