pandas笔记:找出在一个dataframe但不在另一个中的index
发布时间:2024年01月11日
1 问题描述
假设我们有两个dataframe(这一段代码)来自transbigdata 笔记:官方文档案例1(出租车GPS数据处理)-CSDN博客
data = tbd.clean_outofshape(data, sz, col=['Lng', 'Lat'], accuracy=500)
data
data2 = tbd.clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus'])
data2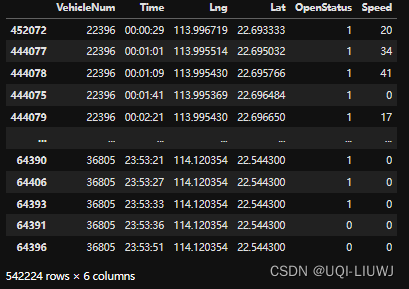
我们希望找到在data中但不在data2中的index
2 方法1 index.difference
data.index
#RangeIndex(start=0, stop=543138, step=1)
data2.index
'''
Index([452072, 444077, 444078, 444075, 444079, 444073, 444074, 444076, 452073,
446704,
...
64415, 64402, 64413, 64411, 64405, 64390, 64406, 64393, 64391,
64396],
dtype='int64', length=542224)
'''
diff_index = data.index.difference(data2.index)
diff_index
'''
Index([ 710, 807, 844, 1372, 1564, 1684, 1690, 1753, 2842,
4150,
...
532055, 533757, 534219, 540261, 540471, 540481, 541260, 541263, 541889,
542487],
dtype='int64', length=914)
'''3 方法2:使用merge
这个其实更灵活,可以通过设置on参数来指定用哪一列合并(不设置则默认是index)
merge几个参数的说明,可见:pandas 笔记:合并操作_pandas 字符合并-CSDN博客
merged=pd.merge(data,data2,how='outer',indicator=True)
merged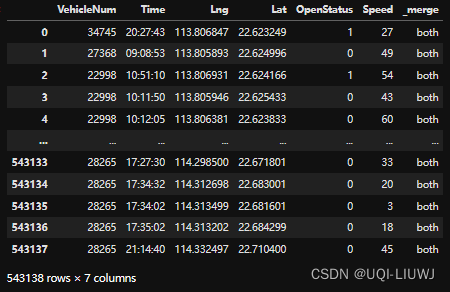
merged[merged['_merge']=='left_only'].index
'''
Index([ 710, 807, 844, 1372, 1564, 1684, 1690, 1753, 2842,
4150,
...
532055, 533757, 534219, 540261, 540471, 540481, 541260, 541263, 541889,
542487],
dtype='int64', length=914)
'''
文章来源:https://blog.csdn.net/qq_40206371/article/details/135505615
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!