《深入理解计算机系统》学习笔记 - 第六课 - 机器级别的程序二
Lecture 06 Machine Level Programming II Control 机器级别程序控制二
文章目录
处理器的状态

- 临时数据: %rax,…
- 运行时栈位置:%rsp (当前栈顶位置)
- 指向当前程序执行位置: %rip,…
- 最近一次 tests 的状态: CF, ZF, SF, OF
特别的寄存器:
-
%rsp
寄存器存的是栈指针,它能告诉你程序执行到哪儿了。
栈中有非常多的状态信息,这些状态信息控制着过程的执行。
所以你不能随意地使用它或设置它,但是其他寄存器可以使用和设置它。 -
%rip
指令指针, instruction pointer。
它包含地是当前正在执行指令地的地址。
它不是你能正常方式访问的寄存器。
它只是告诉你程序执行到哪,当前正在执行的程序的哪个部分。
条件码(隐式设置)
单比特寄存器:
只占用一位。默认位0,如果符合条件设置为1.
* CF Carry Flag,进位标志(仅对无符号)
* SF Sign Flag , 符号标志(仅对有符号)
* ZF Zero Flag, 0值标志
* OF OverFlow Flag, 溢出标志(仅对有符号)
通过算术运算隐式设置条件码(将其视为副作用)
通过算术运算隐式设置示例
add Src, Dest <-> t = a + b
CF 将设置,如果从最高有效位溢出(无符号)。
ZF 将设置,如果 t == 0
SF 将设置,如果 t < 0 (有符号)
OF 将设置,如果二进制补码溢出(有符号)
(a>0 && b>0 && t<0) || (a<0 && b<0 && t>=0)
通过cmp比较命令显示的设置条件码
cmpq Src2, Src1
示例:
cmpq b,a
计算a-b, 而不保存结果。只是设置条件码。
CF 将设置,如果从最高有效位溢出(无符号)。
ZF 将设置,如果 a == b
SF 将设置,如果 a-b < 0 (有符号)
OF 将设置,如果二进制补码溢出(有符号)
(a>0 && b>0 && (a-b)<0) || (a<0 && b<0 && (a-b)>=0)
通过test命令显示的设置条件码
testq Src2, Src1
cmp用于两个数的比较,而test常用于判断某一个数是正/负/零值。
说明:
testq b,a
计算a&b, 而不保存结果。只是设置条件码。
ZF 将设置,如果 a&b == 0
SF 将设置,如果 a&b < 0
- 判断某一个数是正/负/零值
testq a, a
读取条件码
两种方式:
- 直接从特殊的状态寄存器中读取条件码值。原则上可以,但是一般不会这么用。
常见作法: - 尝试读取它。
- 根据其他寄存器的值设置一位标志位,建立一个条件分支。
SetX 指令
根据条件码的组合,将目标低序字节设置为0或1。
不改变剩余的7字节。
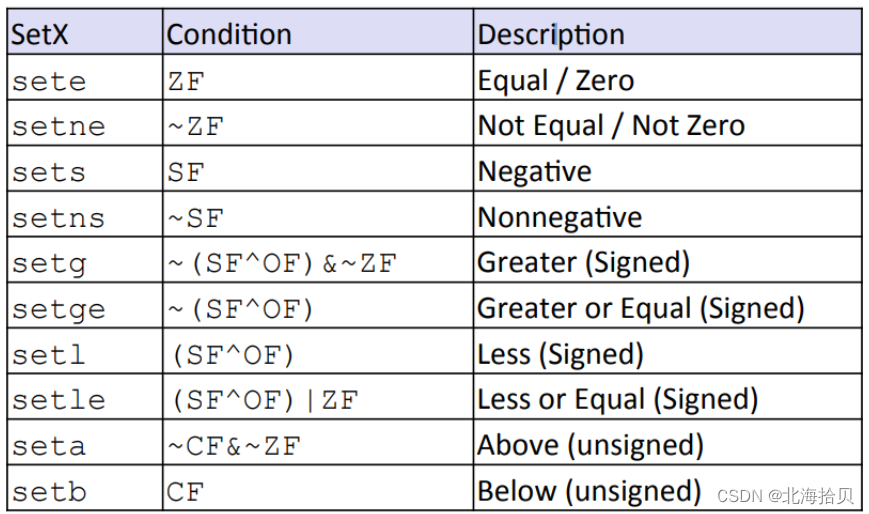
例如:sete: 根据条件码的组合ZF,如果条件码ZF值是1的话,则标志位设置为1.
示例:
- c代码
int gt(long x, long y)
{
return x > y;
}
- 寄存器
%rdi x
%rsi y
%rax 返回值
- 汇编代码
cmpq %rsi, %rdi # y:x
setg %al # x-y>0 : x>y 设置标志位为1
movzbl %al, %eax # 将标志位的值存到返回值中
ret
跳转指令 jump
根据条件码来跳转到不同代码段。
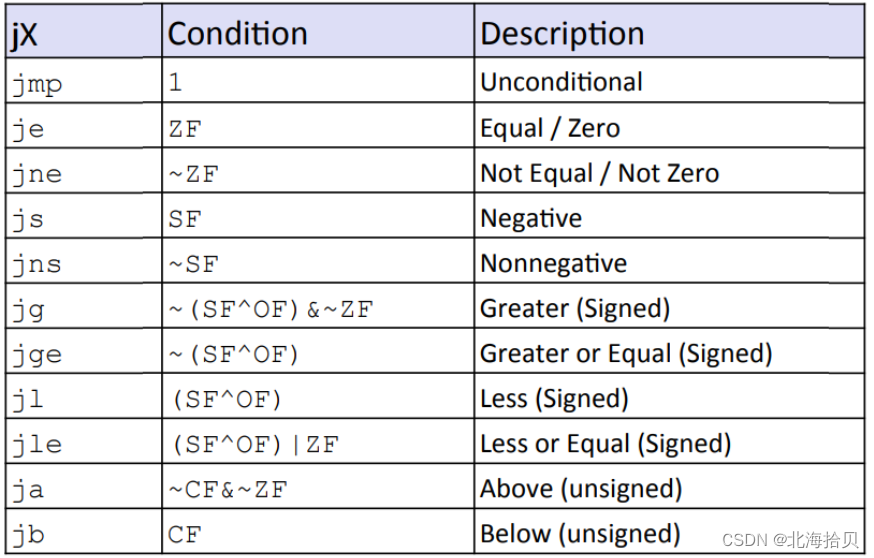
条件分支示例(老版)
- c 代码
long absdiff(long x, long y)
{
long result;
if (x > y)
result = x -y;
else
result = y -x;
return result;
}
- 汇编代码
命令:gcc -Og -S -fno-if-conversion absdiff.c
使用”-fno-fi-conversion“来指定不使用条件移动优化
absdiff:
cmpq %rsi, %rdi # y,x: x > y
jle .L2
movq %rdi, %rax
subq %rsi, %rax
ret
.L2:
movq %rsi, %rax
subq %rdi, %rax
ret
注意:值最终要存入%rax中。
所以是这样:
movq %rdi, %rax
subq %rsi, %rax
而不是:
subq %rsi, %rdi
标签
jle .L2
通常在汇编代码中,如果给出一个名称紧跟着是冒号。那么叫做标签。
它只在汇编代码中可见,实际上并不在目标代码中。
稍后会计算目的地址,地址用于编码,实际上跳转到的位置。
当你在看汇编代码时,它提供的功能之一是更容易理解它然后找到地址。所以它只是告诉你这个位置会发生跳转。
Goto 跳转
- C 代码
long absdiffgoto(long x, long y)
{
long result;
int ntest = x <= y;
if (ntest) got Else;
result = x - y;
goto Done;
Else:
result = y - x;
Done:
return result;
}
- 汇编代码
absdiffgoto:
cmpq %rsi, %rdi #y,x : x:y
jg .L2
movq %rsi, %rax
subq %rdi, %rax
ret
.L2: # x >= y
movq %rdi, %rax
subq %rsi, %rax
.L3:
ret
一般条件语句转换为汇编GOTO
- c语言
格式:
val = Test ? Then_Expr : Else_Expr;
代码:
val = x > y ? x-y : y-x;
- goto 版本
ntest = !test
if (ntest) goto Else;
val = Then_Expr;
goto Done;
Else:
val = Else_Expr;
Done:
//...
使用条件移动 cmove
条件移动指令支持的模式:
if (Test) Dest <- Src
GCC尝试在安全的情况下使用。
- c 语言
val = Test
? Then_Expr
: Else_Expr;
- Goto 版本
result = Then_Expr;
eval = Else_expr;
nt = !Test;
if (nt) result = eval;
return result;
也就是将条件的真,假两面结果都预先计算出来。
为什么使用条件移动优化?
条件移动优化基本思想:把then代码和else都执行得到两个结果,然后选择使用哪一个结果。
看起来浪费实践但事实证明它更有效率。
举个例子:
现代处理器有点像在海上航行的邮轮,它向着某个航线前进,很难让它停下或转向。
假设你知道的指令序列正在代码海洋中巡航,这些指令可以很顺畅的执行,因为他们使用了所谓的流水线技术。这意味着他们在完成一个指令之前就开始执行下一个指令的一部分。
实际上流水线能达到20条以上指令的深度,但是,如果分支猜错了,你必须阻止它并转向另一个方向重新开始。
在较差情况下,这可能需要40个指令40个时钟周期。所以,如果你认为这是一个绝对值,这是很常见的。你能预测一个值是正的还是负的?一般不能预测。
所以一半的实践,不管你猜什么,你猜的都是错了。
事实证明这些条件移动指令,通过先执行两个分支来提高效率要容易的多。在最后一分钟,你要做的就是是否将值移入寄存器。
这并不需要暂停整个处理器的执行,然后重新选择分支执行。
条件分支对于指令的流水式执行方式式毁灭性的。
一般情况,会一次性加载很多条指令,但是条件分支直接跳过这些指令,白加载了,需要重新加载。
条件移动不需要控制转移。
条件移动示例
- c代码
long absdiff(long x, long y)
{
long result;
if (x > y)
result = x -y;
else
result = y -x;
return result;
}
- 条件移动汇编码
absdiff:
movq %rdi, %rax # x
subq %rsi, %rax # result = x-y
movq %rsi, %rdx
subq %rdi, %rdx # eval = y-x
cmpq %rsi, %rdi # x:y
cmovle %rdx, %rax # if <=, result = eval
ret
条件移动失败案例
两个条件分支的值都需要的计算。
- 复杂的计算
val = Test(x) ? Hard1(x) : Hard2(x)
两个计算都很复杂。
只有当计算很简单时,使用条件移动才有意义。
- 高风险计算
val = p ? *p : 0;
某个分支计算可能存在不可预料的影响。
- 计算可能会有副作用
val = x > 0 ? x*=7 : x+=3;
直接使用指针运算,可能会报错。
循环
汇编是通过跳转jump来实现循环,就和c语言中的goto实现循环一样。
Do-While 循环
- c 代码,do-while版本
long pcount_do(unsigned long x)
{
long result = 0;
do {
result += x & 0x1; // 统计x最后一位是1的话,加1
x >>= 1; // 右移一位:最后一位统计完了就丢弃
} while (x);
return result;
}
统计参数x中位中为1的数量。
使用条件分支来进入循环或者跳出循环。
- c 语言代码,goto版本
long pcount_goto(unsigned long x)
{
long result = 0;
loop:
result += x & 0x1;
x >>= 1;
if(x) goto loop;
return result;
}
- 汇编代码
pcount_do:
movl $0, %eax # result = 0
.L2:
movq %rdi, %rdx
andl $1, %edx # t = x & 0x1
addq %rdx, %rax # result += t
shrq %rdi # x >>= 1
jne .L2 # if (x) goto loop
ret
do-while 转换为 goto 版本
- c代码
do
Body
while (Test)
- goto 版本
loop:
Body
if (Test)
goto loop
while循环
while 转换为 goto 版本的一种方式
- c 代码
while (Test)
Body
- goto 版本
goto test;
loop:
Body
test:
if (Test)
goto loop;
done:
代码示例
- c代码
long pcount_while(unsigned long x) {
long result = 0;
while (x) {
result += x & 0x1;
x >>= 1;
}
return result;
}
- 跳转到中部(jump to middle),goto版本
long pcount_goto_jtm(unsigned long x) {
long result = 0;
goto test;
loop:
result += x & 0x1;
x >>= 1;
test:
if(x) goto loop;
return result;
}
while 转换为 goto 版本的另一种方式
- c 代码
while (Test)
Body
- do-while 版本
if (!Test)
goto done;
do
Body
while(Test)
done:
- goto 版本
if (!Test)
goto done;
loop:
Body
if (Test)
goto loop;
done:
代码示例
- c 代码
long pcount_while(unsigned long x) {
long result = 0;
while (x) {
result += x & 0x1;
x >>= 1;
}
return result;
}
- do-while版本
long pcount_goto_dw(unsigned long x) {
long result = 0;
if (!x) goto done;
loop:
result += x & 0x1;
x >>= 1;
if(x) goto loop;
done:
return result;
}
for 循环
格式:
for (Init; Test; Update)
Body
- c 代码
#include <stddef.h>
#define WSIZE 8*sizeof(int)
long pcount_for(unsigned long x)
{
size_t i;
long result = 0;
for (i = 0; i < WSIZE; i++)
{
unsigned bit = (x >> i) & 0x1;
result += bit;
}
return result;
}
- 汇编代码
pcount_for:
movl $0, %eax # i = 0
movl $0, %ecx # result = 0
.L2:
cmpq $31, %rcx # 31:i
ja .L4 # i > 31
movq %rdi, %rdx # bit = x
shrq %cl, %rdx # x >> i
andl $1, %edx # bit:(x >> i) & 0x1
addq %rdx, %rax # result += bit;
addq $1, %rcx # i++
jmp .L2 # 在次进入循环
.L4:
ret
for 循环 -》 while 循环
for格式:
for (Init; Test; Update)
Body
while 版本格式:
Init;
while (Test) {
Body
Update;
}
while 代码:
long pcount_for_while(unsigned long x)
{
size_t i;
long result = 0;
i = 0;
while (i < WSIZE)
{
unsigned bit = (x >> i) & 0x1;
result += bit;
i++;
}
return result;
}
do-while代码:
long pcount_for_goto_dw(unsigned long x) {
size_t i;
long result = 0;
i = 0;
if (!(i < WSIZE))
goto done;
loop:
{
unsigned bit = (x >> i) & 0x1;
result += bit;
}
i++;
if (i < WSIZE)
goto loop;
done:
return result;
}
switch
将它的一般形式看作一些代码块,其入口点由这些case值标记,然后这些代码块以各种不同的方式串起来并做各种各样的事情。
这些代码块编译成一串总代码,并将它们存储在内存的某些位置,加载内存能得到这些代码块。
再建一张表,该表的每一项都描述了一个代码块的起始位置,如果我一个范围的话,我会把它们按照我的case标签的顺序排列。
我们假设以下:0 到 n-1
这个表有很多地址项,这些地址项时代码块的位置。这就像一个数组,你可以通过下标获取值,不必遍历寻找。switch的机器码也用了同样的思想,一步到位,准确地知道你想要跳转到地方。遍历地话复杂度是O(n)
- c 代码
long switch_eg(long x, long y, long z)
{
long w = 1;
switch(x) {
case 1:
w = y*z;
break;
// 直穿 case
case 2:
w = y/z;
/* Fall Through */
case 3:
w += z;
break;
// 漏掉case 4
// 多case 标签
case 5:
case 6:
w -= z;
break;
default:
w = 2;
}
return w;
}
- 汇编代码
switch_eg:
movq %rdx, %rcx
cmpq $6, %rdi
ja .L8
jmp *.L4(,%rdi,8)
.L4: # 跳转表
.quad .L8 # x = 0
.quad .L7 # x = 1
.quad .L6 # x = 2
.quad .L9 # x = 3
.quad .L8 # x = 4
.quad .L3 # x = 5
.quad .L3 # x = 6
.L7:
movq %rsi, %rax
imulq %rdx, %rax
ret
.L6:
movq %rsi, %rax
cqto
idivq %rcx
jmp .L5 # 通过jmp 实现了,fall through 了。
.L9: # case 3, 注意没有ret,所以会走到.L5,走到.L5的ret返回。
movl $1, %eax
.L5:
addq %rcx, %rax
ret
.L3:
movl $1, %eax
subq %rdx, %rax
ret
.L8:
movl $2, %eax
ret
跳转表结构
- switch 格式
switch(x) {
case val_0:
Block 0
case val_1:
Block 1
// ...
case val_n-1:
Block n–1
}
-
跳转表
jtab:
Targ0
Targ1
Targ2
…
Targn-1 -
跳转目标
Targ0: Code Block 0
Targ1: Code Block 1
Targ2: Code Block 2
…
Targn - 1: Code Block n-1 -
翻译为C代码
goto *JTab[x];
switch示例解析
switch 外的逻辑
- c代码
long switch_eg(long x, long y, long z)
{
long w = 1;
switch(x) {
//. . .
}
return w;
}
- 汇编代码
switch_eg:
movq %rdx, %rcx
cmpq $6, %rdi # x:6
ja .L8 # 跳转到默认case
jmp *.L4(,%rdi,8) # 间接跳转:goto *JTab[x]
寄存器:
%rdi: x
%rsi: y
%rdx: z
%rax: 返回值
总结
- c 语言流程控制
- if-then-else
- do-while
- while,for
- switch
- 汇编流程控制
- 条件跳转(jump)
- 条件移动
- 间接跳转(通过跳转表)
- 编译器生成代码序列以实现更复杂的控制
- 标准技术
- 循环转换为do-while 或者 跳转到中部(jump-to-middle)形式
- 大的switch格式,使用跳转表
- 稀疏开关语句可以使用决策树(if—‐elseif—‐elseif—‐else)
《深入理解计算机系统》书籍学习笔记
《深入理解计算机系统》学习笔记 - 第一课 - 课程简介
《深入理解计算机系统》学习笔记 - 第二课 - 位,字节和整型
《深入理解计算机系统》学习笔记 - 第三课 - 位,字节和整型
《深入理解计算机系统》学习笔记 - 第四课 - 浮点数
《深入理解计算机系统》学习笔记 - 第五课 - 机器级别的程序
《深入理解计算机系统》学习笔记 - 第六课 - 机器级别的程序二
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- git 提炼笔记
- 独立按键控制直流电机调速
- 一个非常有用的golang开发工具库,对很多中间件进行了二次封装,使用起来更加的简单高效,目的是把一起操作进行简化CRUD增删改查
- 孪生神经网络MATLAB实战[含源码]
- ubuntu vscode 设置Maple font字体
- 【数据结构】使用循环链表结构实现约瑟夫环问题
- 非对称加密与对称加密的区别是什么?
- Element UI导航菜单之秘:无痕迹浏览与历史记录栈的管理
- Ardupilot开源飞控之VTOL之旅:打印件清单
- 管理团队铁三角之责权利