Druid集群搭建手册
1.?Java环境安装和配置
建议使用JDK1.8。可以参考《Linux安装JDK完整步骤》。
2.?创建用户
创建druid用户,用来管理druid相关的服务。执行命令:
useradd druid #创建用户
passwd druid #设置druid用户密码3.?Zookeeper安装和配置
Druid的服务套件imply自带zookeeper,方便单机部署。如果是集群部署,最好使用自己部署的zookeeper集群。
如果已安装,则跳过本节;如果没有安装,请参考《日志平台搭建手册》。
4.?HDFS安装和配置
Druid集群搭建需要依赖HDFS,用来存储数据文件,这里只需要进行单机安装。本文档采用Hadoop安装包为hadoop-2.9.1.tar.gz,所有命令均由druid用户操作执行。
4.1.?解压安装
执行命令,完成安装包的解压:tar -zxvf hadoop-2.9.1.tar.gz,解压完成后在当前目录生成hadoop-2.9.1目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s hadoop-2.9.1 hadoop,创建完成之后,当前目录结构如下图:

4.2.?简单配置
4.2.1.?创建目录
创建hadoop运行目录,执行命令:
mkdir -p /data/var/hadoop/tmp再创建hdfs namenode的name目录和data目录,执行命令:
mkdir -p /data/var/hadoop/tmp/dfs/name
mkdir -p /data/var/hadoop/tmp/dfs/data4.2.2.?编辑配置文件
这里涉及两个配置文件,均位于hadoop解压目录下,分别为:etc/hadoop/core-site.xml和etc/hadoop/hdfs-site.xml。
编辑core-site.xml文件,内容如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/var/hadoop/tmp</value>
<description>hadoop的运行临时文件的主目录</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://yourhost:9000</value>
<description>HDFS的访问路径</description>
</property>
</configuration>注意将上述配置中红色字体部分内容改为实际ip或域名。
编辑hdfs-site.xml文件,内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/var/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/data/var/hadoop/tmp/dfs/data</value>
</property>
</configuration>4.3.?启动和停止
配置完成之后,执行以下语句格式化NameNode:
./bin/hdfs namenode –format,成功后会看到如下提示:
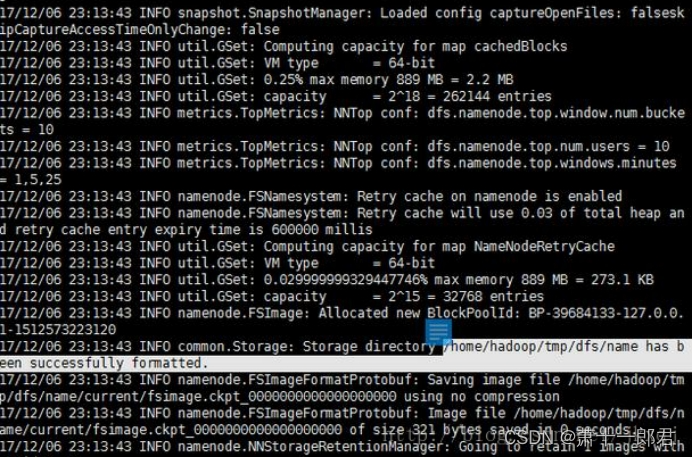
接着执行以下命令启动NameNode和DataNode守护进程:
./sbin/start-dfs.sh
若提示ssh连接,输入yes即可。完成之后,输入命令jps来判断是否成功启动。若成功启动则会列出如下进程:
NameNode
DataNode
SecondaryNameNode
成功启动后,可以访问 Web 界面?http://localhost:50070?查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。?若有如下页面,恭喜安装成功!

停止hadoop,执行命令:./sbin/stop-dfs.sh。
4.4.?使用验证
使用验证主要是利用脚本hdfs进行相关操作,执行命令:./bin/hdfs dfs -h进行命令帮助查看。
查看根目录的文件列表:./bin/hdfs dfs -ls /
上传文件到HDFS的根目录:./bin/hdfs dfs -put README.txt /
删除刚才上传的文件:./bin/hdfs dfs -rm /README.txt
4.5.?补充
4.3节中执行hdfs的启动命令之后,控制台会提示需要输入ssh的连接密码,总共需要输入3次密码,比较繁琐。本节实现ssh免密登录本机。假设该机器已安装ssh客户端。
首先执行如下命令生成公钥和私钥对:ssh-keygen -t rsa,一直按回车键,直到命令执行完毕。执行完成之后进入当前用户目录,使用ls -al命令查看目录列表,生成了一个.ssh目录,该目录下有id_rsa和id_rsa.pub两个文件。
在.ssh目录下创建文件authorized_keys,然后执行cat id_rsa.pub >> authorized_keys。
最后确定文件访问权限,id_rsa,id_rsa.pub,authorized_keys的访问权限设置为600。
测试时候成功,执行命令:ssh localhost,如果成功登录,则表示免密登录设置成功。
再次执行hdfs的启动命令,则控制台不会提示输入登录密码。
5.?MySQl安装和配置
Druid集群搭建依赖MySql数据库,存储元数据信息。
5.1.?安装必要的编译工具
执行如下命令安装必要的编译工具:
yum -y install cmake ncurses-devel gcc gcc-c++
5.2.?安装boost
安装mysql之前是必须先安装boost库。经过我之前的失败经历,安装mysql5.7.12要求boost的版本是boost_1_59_0,版本不同的话会失败。
这里在Download boost_1_59_0.tar.gz (Boost C++ Libraries)下载压缩包,也可以在centos中使用wget命令下载。
下载完毕后:? tar -xzvf boost_1_59_0.tar.gz? cd boost_1_59_0? ./bootstrap.sh --with-libraries=system,filesystem,log,thread --with-toolset=gcc? ./b2 toolset=gcc
./b2 install --prefix=/usr/local/boost地址自己决定,默认是/usr/local/lib
5.3.?编译安装MySQL
在http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.12.tar.gz下载mysql5.7.12的压缩包,或使用wget命令直接下载。
tar -xzvf mysql-5.7.12.tar.gz解压
cd mysql-5.7.12
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/mysqldata/ -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DMYSQL_TCP_PORT=3306 -DMYSQL_USER=mysql -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_ARCHIVE_STORAGE_ENGINE=1 -DWITH_BLACKHOLE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DDOWNLOAD_BOOST=1 -DWITH_BOOST=boost_1_59_0(boost解压目录)
make
make install
make clean
rm CMakeCache.txt5.4.?修改配置文件
vim /etc/my.cnf? 写入内容:
[mysqld]
basedir =/usr/local/mysql
datadir=/usr/local/mysql/data/
port = 3306
socket=/tmp/mysql.sock
user=root
[client]
socket=/tmp/mysql.sock设置mysql开机自动启动?
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod 755 /etc/init.d/mysqld
chkconfig –add mysqld
chkconfig –level 345 mysqld on5.5.?启动MySQL
初始化mysql?./mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data? 这条命令执行后会产生一个初始密码:?A temporary password is generated for root@localhost: tj+/Yssvc9Gb (要记下来)
执行命令启动mysql服务:service mysqld start
使用root登录数据库 密码是之前记下来的密码,使用set password=‘’;命令修改密码。
6.?Druid安装和配置
Druid是一种列式存储数据库,能够实现大数据量的实时统计分析。本文档采用druid安装包为imply-2.6.0.tar,所有命令均由druid用户操作执行。
6.1.?单机安装
执行命令,完成安装包的解压:tar -zxvf imply-2.6.0.tar,解压完成后在当前目录生成imply-2.6.0目录,针对该目录创建软连接,方便以后软件升级,执行命令:ln -s imply-2.6.0 imply,创建完成之后,当前目录结构如下图:

单机安装无须任何配置,进入imply目录执行如下命令即可启动Druid:
./bin/supervise -c conf/supervise/quickstart.conf
命令执行之后,控制台将输出信息,可以看出该脚本启动了7个相关进程,包括:zk、coordinator、broker、historical、overlord、middleManager、imply-ui。
如果Druid相关服务正常启动,可以访问Druid控制台页面:http://localhost:8081;还可以访问Druid协调信息页面:http://localhost:8090;还可以访问一个最重要的页面——数据操作查看页面:http://localhost:9095
| 服务节点名称 | 说明 | 端口 |
| 协调节点coordinator | 负责历史节点的负载均衡以及通过规则管理数据的生命周期 | 8081 |
| 历史节点historical | 负责加载已生成好的数据文件已提供数据查询 | 8083 |
| 索引服务——overlord | 索引服务的主节点 | 8090 |
| 索引服务——middleManager | 索引服务的从节点 | 8091 |
| 查询节点broker | 对外提供数据查询服务,并同时从实时节点与历史节点查询数据,合并后返回给调用方 | 8082 |
| Imply-ui,pivot服务 | 提供可视化的数据操作界面 | 9095 |
6.2.?集群安装
6.2.1.?集群规划
将协调节点coordinator和索引服务的主节点overlord部署在一台机器上,这两个节点均属于管理类型节点,主要负责协调其他节点有条不紊的工作。假设该机器ip为192.168.10.100,命令为master节点。
将历史节点historical、索引服务从节点middleManager、查询节点broker和数据管理界面imply-ui部署在一个节点,方便数据操作交互。假设该机器ip为192.168.10.101,名为query节点。
6.2.2.?服务配置
6.2.2.1.?全局配置
配置文件路径:imply/conf/druid/_common/common.runtime.properties,全局配置内容如下:
#
# Extensions
#
druid.extensions.directory=dist/druid/extensions
druid.extensions.hadoopDependenciesDir=dist/druid/hadoop-dependencies
druid.extensions.loadList=["druid-parser-route","mysql-metadata-storage","druid-hdfs-storage","druid-kafka-indexing-service"]
#
# Logging
#
# Log all runtime properties on startup. Disable to avoid logging properties on startup:
druid.startup.logging.logProperties=true
#
# Zookeeper
#
druid.zk.service.host=host1:2181,host2:2181,host3:2181
druid.zk.paths.base=/druid
#
# Metadata storage
#
# For MySQL:
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://host:3306/druid
druid.metadata.storage.connector.user=root
druid.metadata.storage.connector.password=888888
#
# Deep storage
#
# For HDFS:
druid.storage.type=hdfs
druid.storage.storageDirectory=hdfs://host-hadoop:9000/druid/segments
#
# Indexing service logs
#
# For HDFS:
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=hdfs://host-hadoop:9000/druid/indexing-logs
#
# Service discovery
#
druid.selectors.indexing.serviceName=druid/overlord
druid.selectors.coordinator.serviceName=druid/coordinator
#
# Monitoring
#
druid.monitoring.monitors=["io.druid.java.util.metrics.JvmMonitor"]
druid.emitter=logging
druid.emitter.logging.logLevel=debug注意上述配置中加粗的配置项,请根据之前的zookeeper、mysql和hadoop的安装,填写实际的ip、端口和访问账号和密码。
6.2.2.2.?协调节点coordinator配置
该节点配置文件所在目录:imply/conf/druid/coordinator,下面包含三个配置文件:jvm.config,main.config,runtime.properties。
修改jvm.config文件,调整jvm的参数如下:
-server
-Xms512m #根据实际情况进行设置
-Xmx512m #根据实际情况进行设置
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
-Dderby.stream.error.file=var/druid/derby.log编辑runtime.properties文件,修改协调节点的host和port。
druid.host=192.168.10.100
druid.port=80816.2.2.3.?历史节点historical配置
该节点配置文件所在目录:imply/conf/druid/historical,同协调节点一样包含3个配置文件。
修改jvm.config文件,调整jvm的参数如下:
-server
-Xms512m #根据实际情况进行设置
-Xmx512m #根据实际情况进行设置
-XX:MaxDirectMemorySize=1g #根据实际情况进行设置
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager编辑runtime.properties文件,修改协调节点的host和port。
druid.host=192.168.10.101
druid.port=80836.2.2.4.?索引服务overlord配置
该节点配置文件所在目录:imply/conf/druid/overlord,同协调节点一样包含3个配置文件。
修改jvm.config文件,调整jvm的参数如下:
-server
-Xms256m
-Xmx256m
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager编辑runtime.properties文件,修改协调节点的host和port。
druid.host=192.168.10.100
druid.port=80906.2.2.5.?索引服务middleManager配置
该节点配置文件所在目录:imply/conf/druid/middleManager,同协调节点一样包含3个配置文件。
修改jvm.config文件,调整jvm的参数如下:
-server
-Xms64m
-Xmx64m
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager编辑runtime.properties文件,修改协调节点的host和port,以及indexer的javaOpts。
druid.host=192.168.10.101
druid.port=8091
druid.indexer.runner.javaOpts=-server -Xmx1g -Duser.timezone=UTC+0800 -Dfile.encoding=UTF-8 -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager6.2.2.6.?查询节点broker配置
该节点配置文件所在目录:imply/conf/druid/broker,同协调节点一样包含3个配置文件。
修改jvm.config文件,调整jvm的参数如下:
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=1g
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager编辑runtime.properties文件,修改协调节点的host和port。
druid.host=192.168.10.101
druid.port=80826.2.2.7.?Pivot配置
配置文件路径:imply/conf/pivot/config.yaml,配置内容如下:
# The port on which the imply-ui server will listen on.
port: 9095
# runtime directory
varDir: var/pivot
# The initial settings that will be loaded in, in this case a connection will be created for a Druid cluster that is running locally.
initialSettings:
connections:
- name: druid
type: druid
title: My Druid
host: 192.168.10.101:8082
coordinatorHosts: ["192.168.10.100:8081"]
overlordHosts: ["192.168.10.100:8090"]
# imply-ui must have a state store in order to function
# The state (data cubes, dashboards, etc) can be stored in two ways.
# Choose just one option and comment out the other.
#
# 1) Stored in a sqlite file, editable at runtime with Settings View. Not suitable for running in a cluster.
# 2) Stored in a database, editable at runtime with Settings View. Works well with a cluster of Imply servers.
#stateStore:
# type: sqlite
# connection: var/pivot/pivot-settings.sqlite
stateStore:
type: mysql
#location: mysql
connection: 'mysql://root:888888@host:3306/pivot'上述配置中字体加粗的内容需要根据实际情况填写。
6.2.3.?启动和停止
常用的启动命令为imply/bin/supervise,该命令的启动配置文件位于imply/conf/supervise目录下,配置文件指定启动的服务列表。
6.2.3.1.?启动master节点服务
6.2.3.1.1.?准备master节点启动配置文件
Master节点服务包含协调节点coordinator和统治节点overlord,且这些服务依赖独立的zookeeper服务。我们把master节点启动配置文件命令为master.conf。在imply/conf/supervise目录下执行如下命令:
cp master-no-zk.conf master.conf6.2.3.1.2.?启动命令
前台启动命令如下:
./bin/supervise -c conf/supervise/master.conf后台启动命令如下:
nohup ./bin/supervise -c conf/supervise/master.conf > master.log &成功启动之后,执行命令ps -ef | grep imply,结果如下:
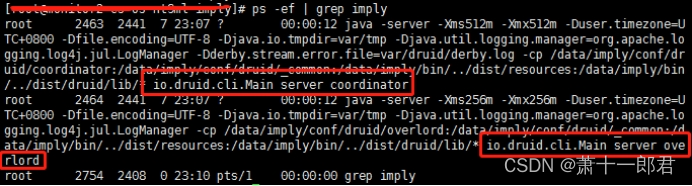
从上图可以看出,协调节点coordinator和统治节点overlord已正常运行。
6.2.3.2.?启动query节点服务
6.2.3.2.1.?准备query节点启动配置文件
修改imply/conf/supervise/query.conf,内容如下:
:verify bin/verify-java
:verify bin/verify-node
:verify bin/verify-version-check
broker bin/run-druid broker conf #启动broker查询节点
imply-ui bin/run-imply-ui conf #启动imply-ui
historical bin/run-druid historical conf #启动historical历史节点
middleManager bin/run-druid middleManager conf #启动索引服务从节点middleManager
# Uncomment to user Tranquility Server
#!p95 tranquility-server bin/tranquility server -configFile conf/tranquility/server.json
# Uncomment to use Tranquility Kafka
#!p95 tranquility-kafka bin/tranquility kafka -configFile conf/tranquility/kafka.json6.2.3.2.2.?启动命令
前台启动命令如下:
./bin/supervise -c conf/supervise/query.conf后台启动命令如下:
nohup ./bin/supervise -c conf/supervise/query.conf > query.log &成功启动之后,执行命令ps -ef | grep imply,结果如下:
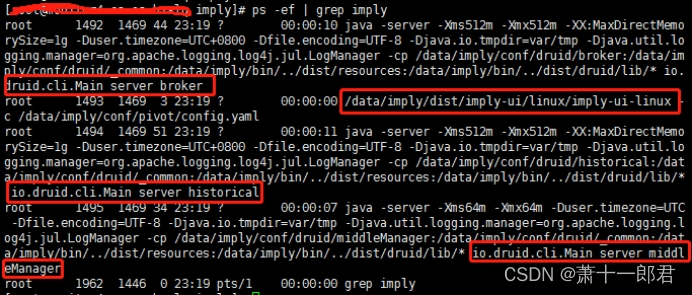
从上图可以看出,查询节点broker、imply-ui节点、历史节点historical、middleManager节点均已正常运行。
6.2.3.3.?停止服务
Druid集群服务的停止方法有两种,一种是通过ps命令获取服务进程号之后,采用kill命令直接杀掉;另外一种方法是使用druid自带的命令,命令为imply/bin/service。查看命令使用方法:./bin/service --help,输出如下:
Unknown option: help usage: ./bin/service (--restart <service> | --tail <service> | --down) [-d <var dir>]执行命令:./bin/service --down,可以关闭该机器上所有的druid相关服务。
6.3.?集群操作
6.3.1.?导入数据
本文采用index-serveice服务进行实时数据导入,导入过程可以分为三个步骤:
6.3.1.1.?创建topic
在kafka集群创建一个topic,供生产者实时往该topic写入数据,供消费者实时从该topic读取数据。执行命令:
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
以上命令创建了一个名称为test的topic,该topic的分片数为3,副本数也为3。
6.3.1.2.?提交读取任务
Druid读取kafka数据采用index-service,需要先向overlord的节点提交任务,提交地址:http://192.168.10.100:8090/druid/indexer/v1/supervisor。
提交任务的规范明细内容如下:
{
"type": "kafka",
"dataSchema": {
"dataSource": "trans-kafka",
"parser": {
"type": "string",
"parseSpec": {
"format": "json",
"timestampSpec": {
"column": "tran_timestamp",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"mon_sid",
"target_ip",
"target_port",
"source_ip",
"tran_name",
"channel",
{"name" : "tran_cost", "type" : "long"},
"ret_code",
"ret_msg",
"tran_result",
"excp_stat"
]
}
}
},
"metricsSpec" : [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "NONE",
"rollup": false
}
},
"ioConfig": {
"topic": "test",
"consumerProperties": {
"group.id": "druid"
"bootstrap.servers": "IP2:9092,ip2:9092,IP3:9092"
}
}
}上述内容仅供参考,请读者根据自己的实际情况进行编写任务规范明细,将上述文件保存为kafka-index.json,然后执行如下命令,将任务提交给索引服务主节点overlord。
curl -X POST -H 'Content-Type:application/json' -d @kafka-index.json http://192.168.10.100:8090/druid/indexer/v1/supervisor。
提交完成之后,可以查看活跃的任务列表,执行如下命令:
curl -X GET http://192.168.10.100:8090/druid/indexer/v1/supervisor
6.3.1.3.?写入数据
本节写入数据是指向kafka中的topic写入数据,上节druid已经指定消费test topic,那么现在我们只需要向test topic写入数据,即可实现数据实时流转。写入数据的方法有两种:
(1)采用kafka自带的生产者命令写入数据,该方法只能用来测试系统的联通性,命令如下:
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
(2)采用Java程序调用kafka的依赖包,自己编码写入数据,该部分类型不详述,在生产环境中以实现。
6.3.2.?查询数据
数据查询需要发送查询参数给查询节点broker,请求地址为http://192.168.10.101:8082/druid/v2/,目前有两种方式实现数据查询:
6.3.2.1.?命令查询
将查询参数信息保存到本地文件,本文假设该文件命名为query.json,内容如下:
{
"queryType": "timeseries",
"dataSource": "trans-kafka",
"granularity": "minute",
"intervals": ["2018-08-09T19:20:00.000Z/2018-08-10T00:00:01.000Z"],
"aggregations": [
{
"type": "count",
"name": "total"
}
]
}查询参数以json格式组织,发起请求则可以通过curl命令实现,如下:
curl -X POST -H 'Content-Type:application/json' -d @query.json http://192.168.10.101:8082/druid/v2/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!