使用ddddocr训练一键识别文字点选、图标点选验证码(不写一行代码训练,开箱即用)
前言:当写上这个标题,你可能就知道,估计是又用上工具了,不然怎么可能自己不写个网络去训练呢,是的,本文的讲解目的,就是善于工具去更方便的完成我们的工具,众所周知,ddddocr提供了一键识别预测框的功能,即识别出所有文字和图标的位置,但是无法识别具体位置是哪个类别,所以本文主要讲解识别类型的简便训练用法
本文方法类似于以下文章:
四六位、不定长、计算题等验证码,一款工具全部搞定,简单方便还开箱即用,精度高达96%!!
Pytorch利用ddddocr辅助识别点选验证码
但区别于以上文章,更简洁或工具不同,有兴趣的也可以扩展延读一下,接下来是正文部分
先讲解下大致流程,因为我们只需要实现将对应的文字或图标(以下都简称为点选)的位置识别出对应的分类,所以我们只需要找一个分类模型即可,接触过深度学习的小伙伴可能就会想到了,目前也有很多分类模型也可供使用(例如resnet、mobilenet等),这些模型结构是不用从头写了,但是损失函数、优化器、训练步骤以及数据集预处理,也还是要处理的,到这里,有想法的小伙伴可能就想到了,只要解决上述所说的问题基本就成了,所以这里选择采用预处理、训练等一体化的训练工具:PaddleClas
paddleclas是由百度飞桨提供的一个图像识别和图像分类任务的工具集
paddleclas本身不仅提供resnet、mobilenet等主流分类模型的一键训练,同时自身也提供了PP-LCNet等自研模型的一键训练,这里可以根据自己的喜好来选择对应的模型训练,我这里直接使用PP-LCNetV2自研模型作为训练讲解演示,这里完全可以不用考虑模型的准确率,只需要考虑数据集的质量,因为使用的官方模型,肯定比自己手写一些模型要强的,具体可以参考模型介绍
数据集准备
前置条件,因为我们已经具备了ddddocr提供的检测,我们只需要做分类识别,所以这里,可以把ddddocr提供的预测框全部切割保存下来,以便下一步处理,大致展示如下:
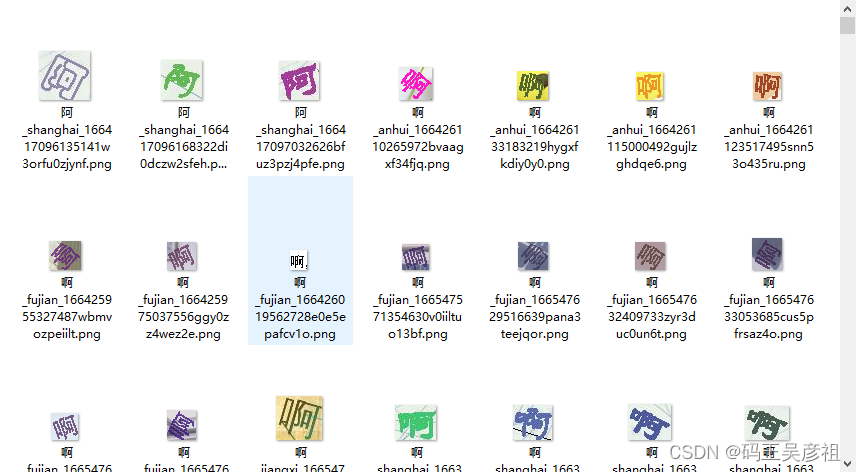
然后我们找到官方数据集分类的帮助地址PaddleClas数据准备
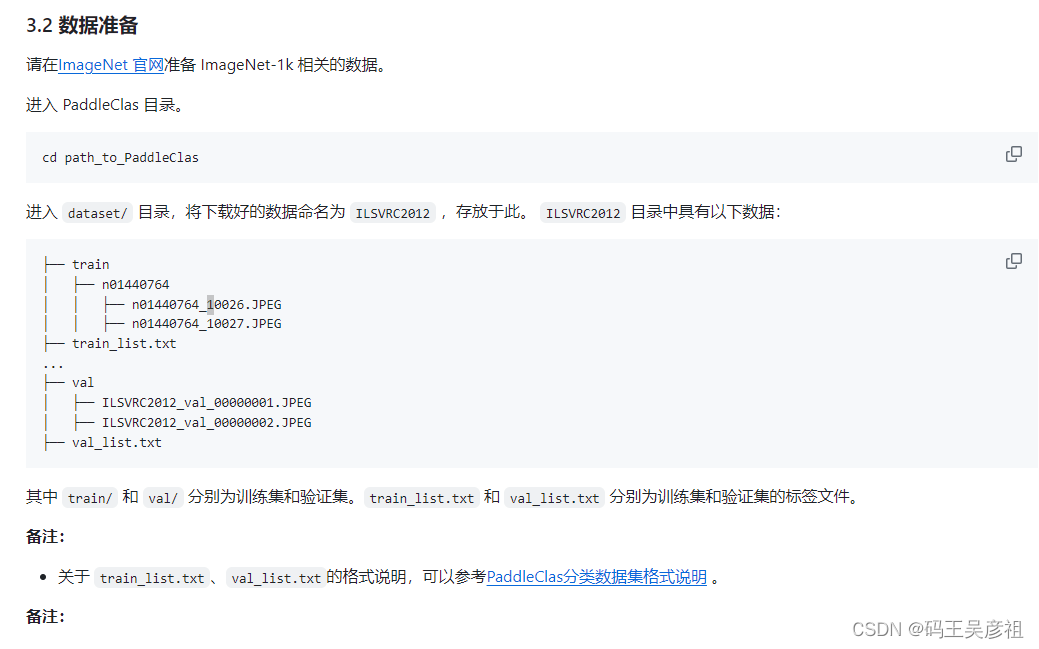
从文章链接中可以看到需要准备的训练集train和验证集val为一级目录,具体类别n01440764为二级目录,图片编号名称n01440764_10023.JPEG为三级目录,这里的val只有两层目录,经过本人实测,val也可以像train一样改为三级目录,只需要在训练配置中修改好对应路径即可
接下来需要准备两份标签文件train_list.txt和val_list.txt用于记录每个图片的路径地址和对应的标签,在准备这份标签文件前,需要有一个文字字典,因为对应的标签为数字,这里,我的字典文件格式如下:

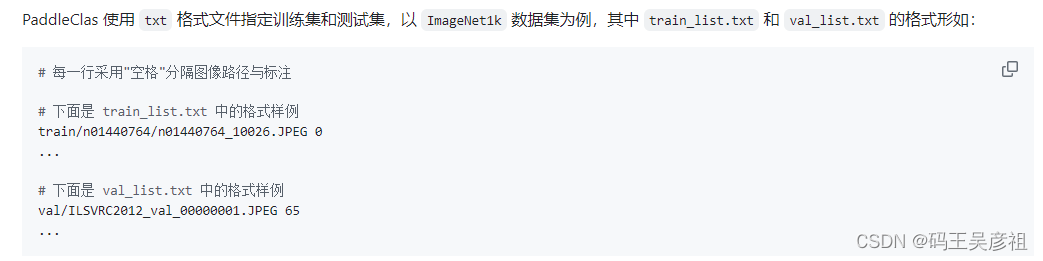
我准备了5000多个文字种类,如果你需要这份字典,可以私信我免费发你,接下来,写一段简单的代码来编写标签文件
import os
font_lib = eval(open("../font_lib_new.txt", "r").read()) #字典
path = "train"
fonts = os.listdir(path)
sums = 0
with open("train_list.txt", "w", encoding="utf8") as f:
for font in fonts:
imgs = os.listdir(os.path.join(path, font))
for img in imgs:
im_path = os.path.join(path, font, img)
im_index = font_lib.index(font)
f.write(im_path + " " + str(im_index) + "\n")
sums += 1
print("共写入数量", sums)
这里的代码仅供参数,具体以实际情况而定,我这里准备了1000万训练集和50万验证集,均由代码生成
注意:初始情况下,你可能不知道扣下来的每个字是什么类别,你可以使用第三方打码平台进行标注,我这里是通过代码自动生成文字,如果你对生成文字感兴趣,可以参考captcha和pillow第三方库
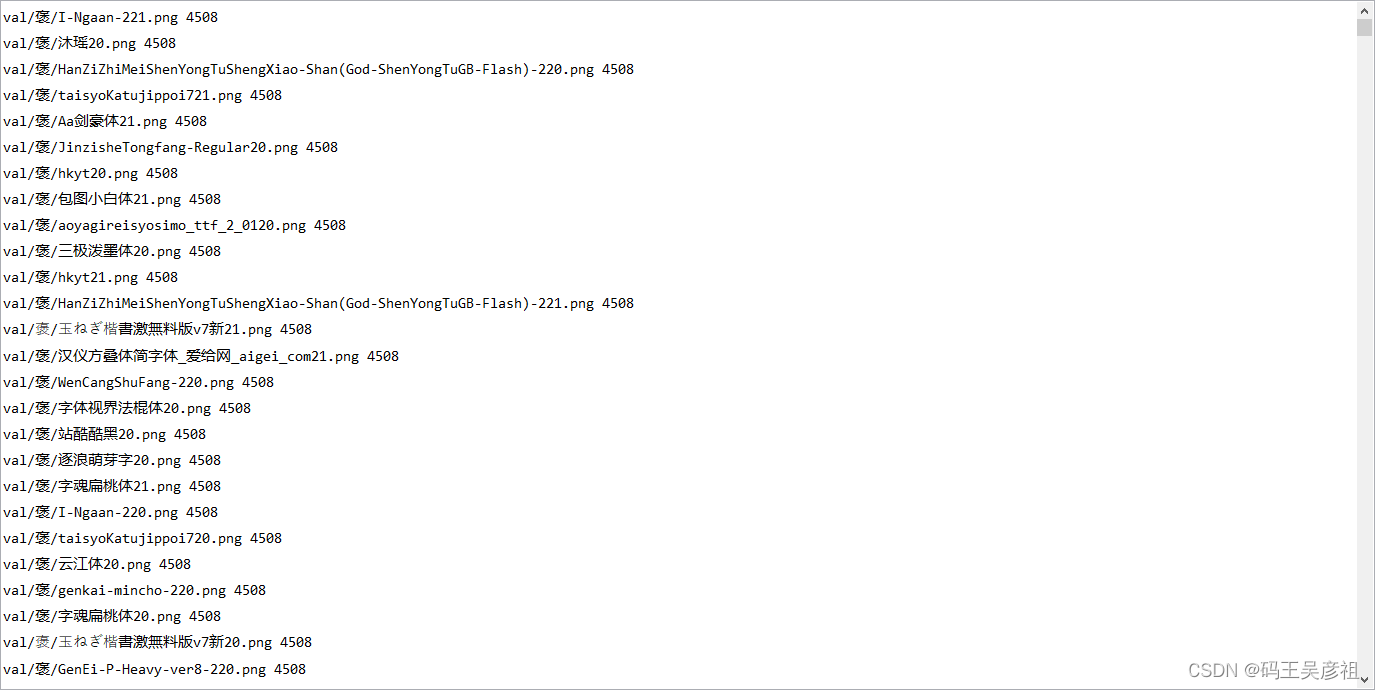
train_list.txt、val_list.txt 格式参考如下
准备训练
训练之前,需要先把官方代码clone下来,放到训练的机器上
因为训练采用的官方预训练模型,所以这里也先参考一下官方训练教程
进入该目录
cd /mnt/disk1/PaddleClas/PaddleClas-release-2.5
在 ppcls/configs/ImageNet/PPLCNetV2/PPLCNetV2_base.yaml 中提供了 PPLCNetV2_base 训练配置,可以通过如下脚本启动训练:
export CUDA_VISIBLE_DEVICES=0,1,2,3
python3 -m paddle.distributed.launch \
--gpus="0,1,2,3" \
tools/train.py \
-c ppcls/configs/ImageNet/PPLCNetV2/PPLCNetV2_base.yaml
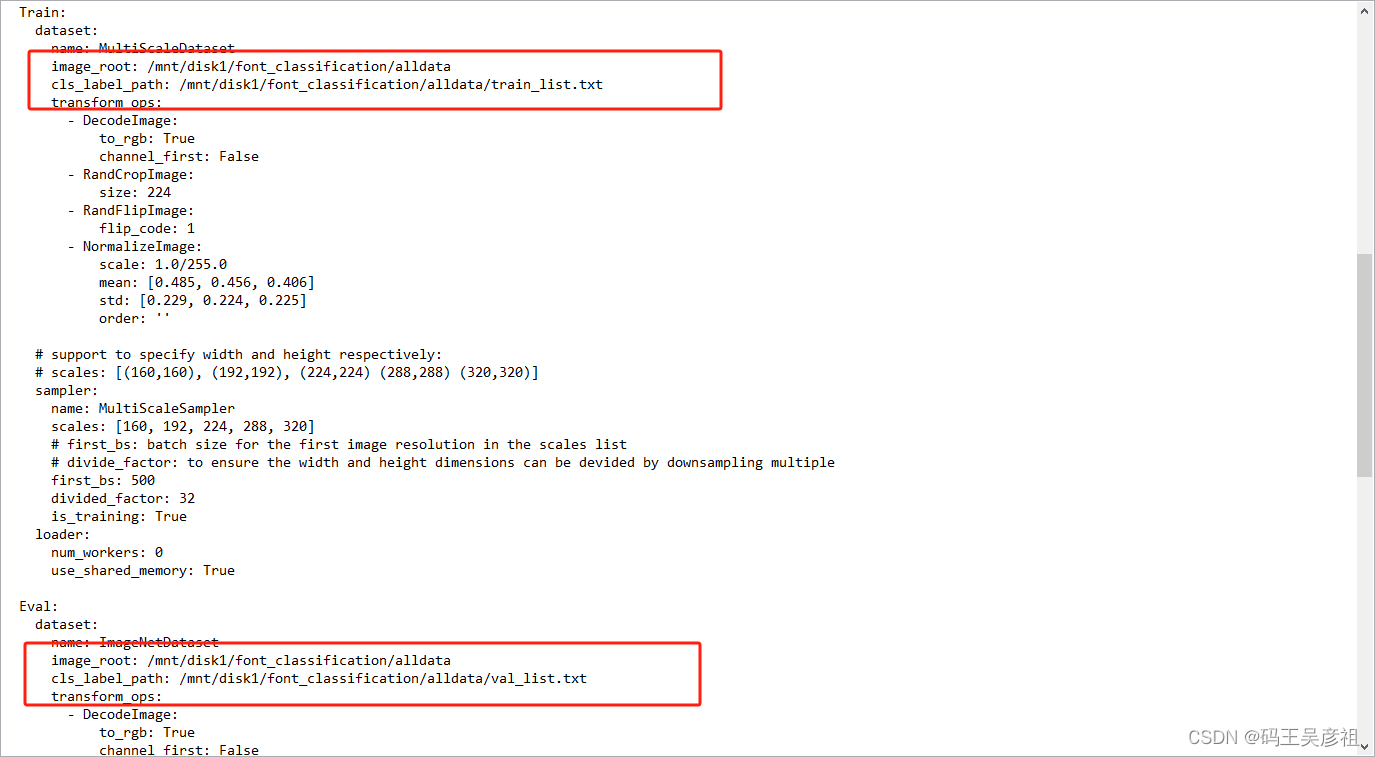
这里可以配置一些全局配置,例如训练的gpu对应的配置文件等,也可以设置配置文件里面的参数,我的配置参数如下:

因为我的数据集略大,所以我这里调整了一下学习率,你可以根据自己情况调整,然后,你需要调整一下训练集和验证集的目录地址和标签文件目录地址,如下:
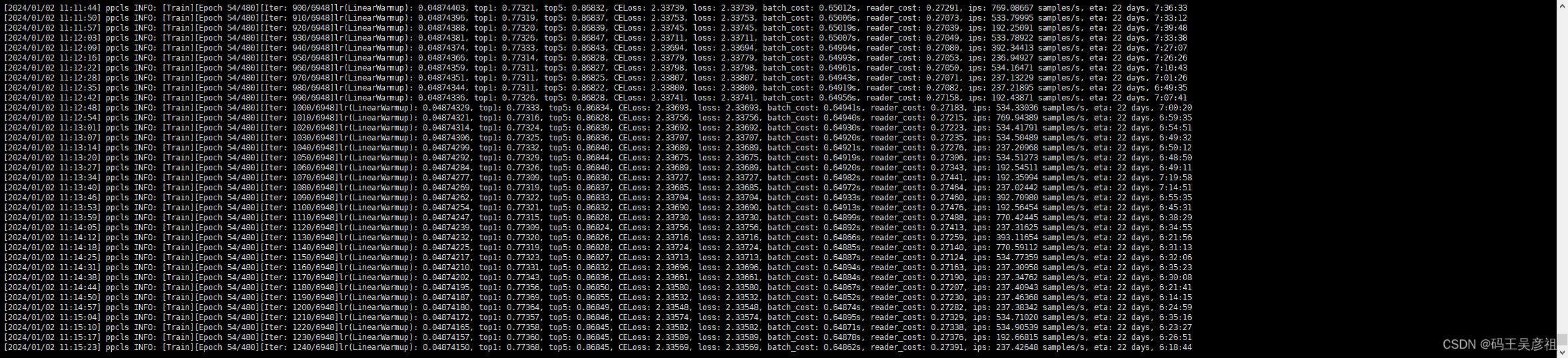
正常情况下,你的模型就会开始如下训练了,在命令行界面中,会提示当前epoch、学习率,top1和top5的准确率以及损失函数的数值
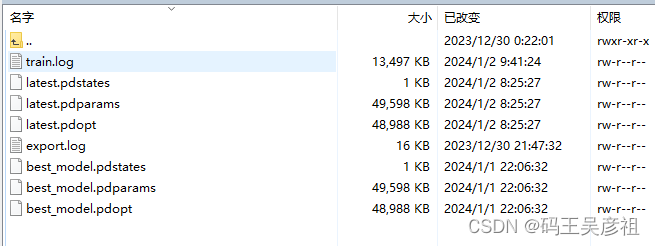
备注:当前精度最佳的模型会保存在 output/PPLCNetV2_base/best_model.pdparams,你会在这里看到当前最佳模型,最后一次训练的模型以及每次训练的模型
模型评估和预测
关于模型评估和预测,其实paddleclas官方也提供了方法,我们这里先参考一下(如果对自己的模型准确率自信,也可以跳过这一步,直接导出模型和推理)
训练好模型之后,可以通过以下命令实现对模型指标的评估。
python3 tools/eval.py \
-c ppcls/configs/ImageNet/PPLCNetV2/PPLCNetV2_base.yaml \
-o Global.pretrained_model=output/PPLCNetV2_base/best_model
其中 -o Global.pretrained_model=“output/PPLCNetV2_base/best_model” 指定了当前最佳权重所在的路径,如果指定其他权重,只需替换对应的路径即可。
模型训练完成之后,可以加载训练得到的预训练模型,进行模型预测。在模型库的 tools/infer.py 中提供了完整的示例,只需执行下述命令即可完成模型预测:
python3 tools/infer.py \
-c ppcls/configs/ImageNet/PPLCNetV2/PPLCNetV2_base.yaml \
-o Global.pretrained_model=output/PPLCNetV2_base/best_model
输出结果如下:
[{'class_ids': [8, 7, 86, 82, 83], 'scores': [0.8859, 0.07156, 0.00588, 0.00047, 0.00034], 'file_name': 'docs/images/inference_deployment/whl_demo.jpg', 'label_names': ['hen', 'cock', 'partridge', 'ruffed grouse, partridge, Bonasa umbellus', 'prairie chicken, prairie grouse, prairie fowl']}]
模型导出
Paddle Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。相比于直接基于预训练模型进行预测,Paddle Inference可使用MKLDNN、CUDNN、TensorRT 进行预测加速,从而实现更优的推理性能。更多关于Paddle Inference推理引擎的介绍,可以参考Paddle Inference官网教程。
当使用 Paddle Inference 推理时,加载的模型类型为 inference 模型。本案例提供了两种获得 inference 模型的方法,如果希望得到和文档相同的结果,请选择直接下载 inference 模型的方式。
此处,我们提供了将权重和模型转换的脚本,执行该脚本可以得到对应的 inference 模型:
python3 tools/export_model.py \
-c ppcls/configs/ImageNet/PPLCNetV2/PPLCNetV2_base.yaml \
-o Global.pretrained_model=output/PPLCNetV2_base/best_model \
-o Global.save_inference_dir=deploy/models/PPLCNetV2_base_infer
执行完该脚本后会在 deploy/models/ 下生成 PPLCNetV2_base_infer 文件夹,models 文件夹下应有如下文件结构:
├── PPLCNetV2_base_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
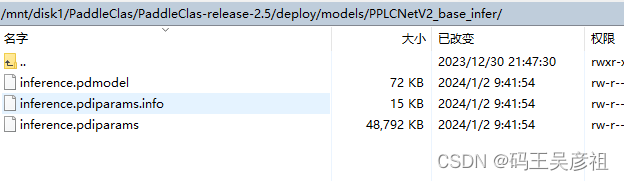
至此,模型导出就完毕了,这里导出的模型可以直接上生产环境了
模型推理
模型推理有两种方法,一种是用官方的推理方法,一种也是官方的第三方库,我们先来看官方的推理方法
基于 Python 预测引擎推理
返回 deploy 目录:
cd ../
运行下面的命令,对图像 ./images/ImageNet/ILSVRC2012_val_00000010.jpeg 进行分类。
# 使用下面的命令使用 GPU 进行预测
python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.inference_model_dir=models/PPLCNetV2_base_infer
# 使用下面的命令使用 CPU 进行预测
python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.inference_model_dir=models/PPLCNetV2_base_infer -o Global.use_gpu=False
输出结果如下。
ILSVRC2012_val_00000010.jpeg: class id(s): [332, 153, 229, 204, 265], score(s): [0.28, 0.25, 0.03, 0.02, 0.02], label_name(s): ['Angora, Angora rabbit', 'Maltese dog, Maltese terrier, Maltese', 'Old English sheepdog, bobtail', 'Lhasa, Lhasa apso', 'toy poodle']
基于文件夹的批量预测,如果希望预测文件夹内的图像,可以直接修改配置文件中的 Global.infer_imgs 字段,也可以通过下面的 -o 参数修改对应的配置。
# 使用下面的命令使用 GPU 进行预测,如果希望使用 CPU 预测,可以在命令后面添加 -o Global.use_gpu=False
python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.inference_model_dir=models/PPLCNetV2_base_infer -o Global.infer_imgs=images/ImageNet/
终端中会输出该文件夹内所有图像的分类结果,如下所示。
ILSVRC2012_val_00000010.jpeg: class id(s): [332, 153, 229, 204, 265], score(s): [0.28, 0.25, 0.03, 0.02, 0.02], label_name(s): ['Angora, Angora rabbit', 'Maltese dog, Maltese terrier, Maltese', 'Old English sheepdog, bobtail', 'Lhasa, Lhasa apso', 'toy poodle']
ILSVRC2012_val_00010010.jpeg: class id(s): [626, 531, 761, 487, 673], score(s): [0.64, 0.06, 0.03, 0.02, 0.01], label_name(s): ['lighter, light, igniter, ignitor', 'digital watch', 'remote control, remote', 'cellular telephone, cellular phone, cellphone, cell, mobile phone', 'mouse, computer mouse']
ILSVRC2012_val_00020010.jpeg: class id(s): [178, 209, 246, 181, 211], score(s): [0.97, 0.00, 0.00, 0.00, 0.00], label_name(s): ['Weimaraner', 'Chesapeake Bay retriever', 'Great Dane', 'Bedlington terrier', 'vizsla, Hungarian pointer']
ILSVRC2012_val_00030010.jpeg: class id(s): [80, 143, 81, 137, 98], score(s): [0.91, 0.01, 0.00, 0.00, 0.00], label_name(s): ['black grouse', 'oystercatcher, oyster catcher', 'ptarmigan', 'American coot, marsh hen, mud hen, water hen, Fulica americana', 'red-breasted merganser, Mergus serrator'
另外,还有基于c++的预测引擎推理,以及转成onnx模型,这里就不放出来了,详情可见官方文档模型推理部署
fastdeploy推理部署
FastDeploy是一款全场景、易用灵活、极致高效的AI推理部署工具, 支持云边端部署。提供超过 🔥160+ Text,Vision, Speech和跨模态模型📦开箱即用的部署体验,并实现🔚端到端的推理性能优化。包括 物体检测、字符识别(OCR)、人脸、人像扣图、多目标跟踪系统、NLP、Stable Diffusion文图生成、TTS 等几十种任务场景,满足开发者多场景、多硬件、多平台的产业部署需求。
PaddleClas支持利用FastDeploy在NVIDIA GPU、X86 CPU、飞腾CPU、ARM CPU、Intel GPU(独立显卡/集成显卡)硬件上快速部署图像分类模型
这里以cpu部署推理为例,在部署前,需确认软硬件环境,同时下载预编译部署库,参考FastDeploy安装文档安装FastDeploy预编译库.
运行部署示例
# 安装FastDpeloy python包(详细文档请参考`部署环境准备`)
pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
conda config --add channels conda-forge && conda install cudatoolkit=11.2 cudnn=8.2
# 下载部署示例代码
# 下载部署示例代码
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd FastDeploy/examples/vision/classification/paddleclas/cpu-gpu/python
# 如果您希望从PaddleClas下载示例代码,请运行
git clone https://github.com/PaddlePaddle/PaddleClas.git
# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到develop分支
git checkout develop
cd PaddleClas/deploy/fastdeploy/cpu-gpu/python
# 下载ResNet50_vd模型文件和测试图片
wget https://bj.bcebos.com/paddlehub/fastdeploy/ResNet50_vd_infer.tgz
tar -xvf ResNet50_vd_infer.tgz
wget https://gitee.com/paddlepaddle/PaddleClas/raw/release/2.4/deploy/images/ImageNet/ILSVRC2012_val_00000010.jpeg
# 在CPU上使用Paddle Inference推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device cpu --backend paddle --topk 1
# 在CPU上使用OenVINO推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device cpu --backend openvino --topk 1
# 在CPU上使用ONNX Runtime推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device cpu --backend ort --topk 1
# 在CPU上使用Paddle Lite推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device cpu --backend pplite --topk 1
# 在GPU上使用Paddle Inference推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device gpu --backend paddle --topk 1
# 在GPU上使用Paddle TensorRT推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device gpu --backend pptrt --topk 1
# 在GPU上使用ONNX Runtime推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device gpu --backend ort --topk 1
# 在GPU上使用Nvidia TensorRT推理
python infer.py --model ResNet50_vd_infer --image ILSVRC2012_val_00000010.jpeg --device gpu --backend trt --topk 1
运行完成后返回结果如下所示
ClassifyResult(
label_ids: 153,
scores: 0.686229,
)
部署示例选项说明
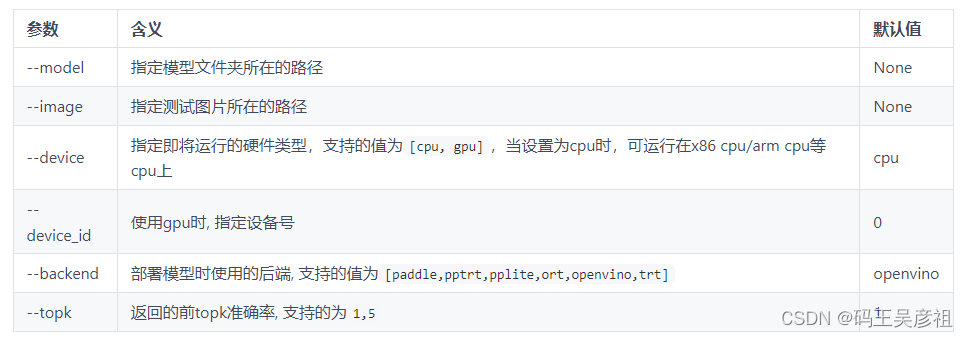
这里,我们以我们导出的模型为例,对test文件夹进行预测,使用大致如下数据集进行测试
import fastdeploy as fd
import cv2
import os
import numpy as np
def build_option(device):
option = fd.RuntimeOption()
if device == "gpu":
option.use_gpu(args.device_id)
return option
runtime_option = build_option("cpu")
model_path = "PPLCNetV2_base_infer"
model_file = os.path.join(model_path, "inference.pdmodel")
params_file = os.path.join(model_path, "inference.pdiparams")
config_file = os.path.join(model_path, "inference_cls.yaml")
model = fd.vision.classification.PaddleClasModel(
model_file, params_file, config_file, runtime_option=runtime_option)
font_lib = eval(open("font_lib_new.txt", "r", encoding="utf8").read())
# 预测图片分类结果
sums, trues = 0, 0
false_fonts = []
imgs = os.listdir("test")
for img in imgs:
im = open(os.path.join("test", img), "rb").read()
# 将二进制数据转换为 numpy 数组
numpy_array = np.frombuffer(im, np.uint8)
# 使用 OpenCV 将 numpy 数组转换为图像对象
image = cv2.imdecode(numpy_array, cv2.IMREAD_UNCHANGED)
font = img[0]
result = model.predict(image, 1)
pred_font = font_lib[result.label_ids[0]]
if font == pred_font:
trues += 1
else:
false_fonts.append(font)
false_fonts.append(pred_font)
print(font, pred_font, img)
sums += 1
print("总数: ", sums, "正确总数: ", trues, "准确率: ", str(trues / sums))
print("有问题文字:", false_fonts)
注意,导出后没有inference_cls.yaml这个文件,在deploy/configs/inference_cls.yaml该目录下可以找到
总数: 15611 正确总数: 14283 准确率: 0.914931778873871
由于训练的时间比较短,针对我的数据集,我只训练了5-6个epoch,准确率也能达到91,如果再训练几轮,应该会更高
完结,???
如果教程中还有什么遗漏或者不明白的地方,欢迎私信提出,本文中用到的数据集和配置文件等也可以私信作者免费提供,麻烦大家动动发财的小手指,多点赞多收藏,得到一定量的点赞收藏,我将再出一篇文章,脱离ddddocr实现一键预测+识别点选验证码,感谢!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!