LLM + RecSys 初体验(上)
最近在逛小红书的时候,发现了一个新的GPU算力租赁平台,与AutoDL和恒源云等平台类似。正巧,官网有活动,注册即送RTX 4090三个小时,CPU 5 小时。正巧最近在测试 LLM+推荐系统的 OpenP5 平台,果断入手测试!
用我的专用邀请链接,注册 OpenBayes,双方各获得 60 分钟 RTX 4090 使用时长,支持累积,永久有效:
https://openbayes.com/console/signup?r=AlexShen_aAfZ
你们注册后也可以推荐给自己的朋友,这样赠送的时长是可以叠加的。
1. GPU 算力容器注册
首先在主界面上可以看到注册算力容器的入口
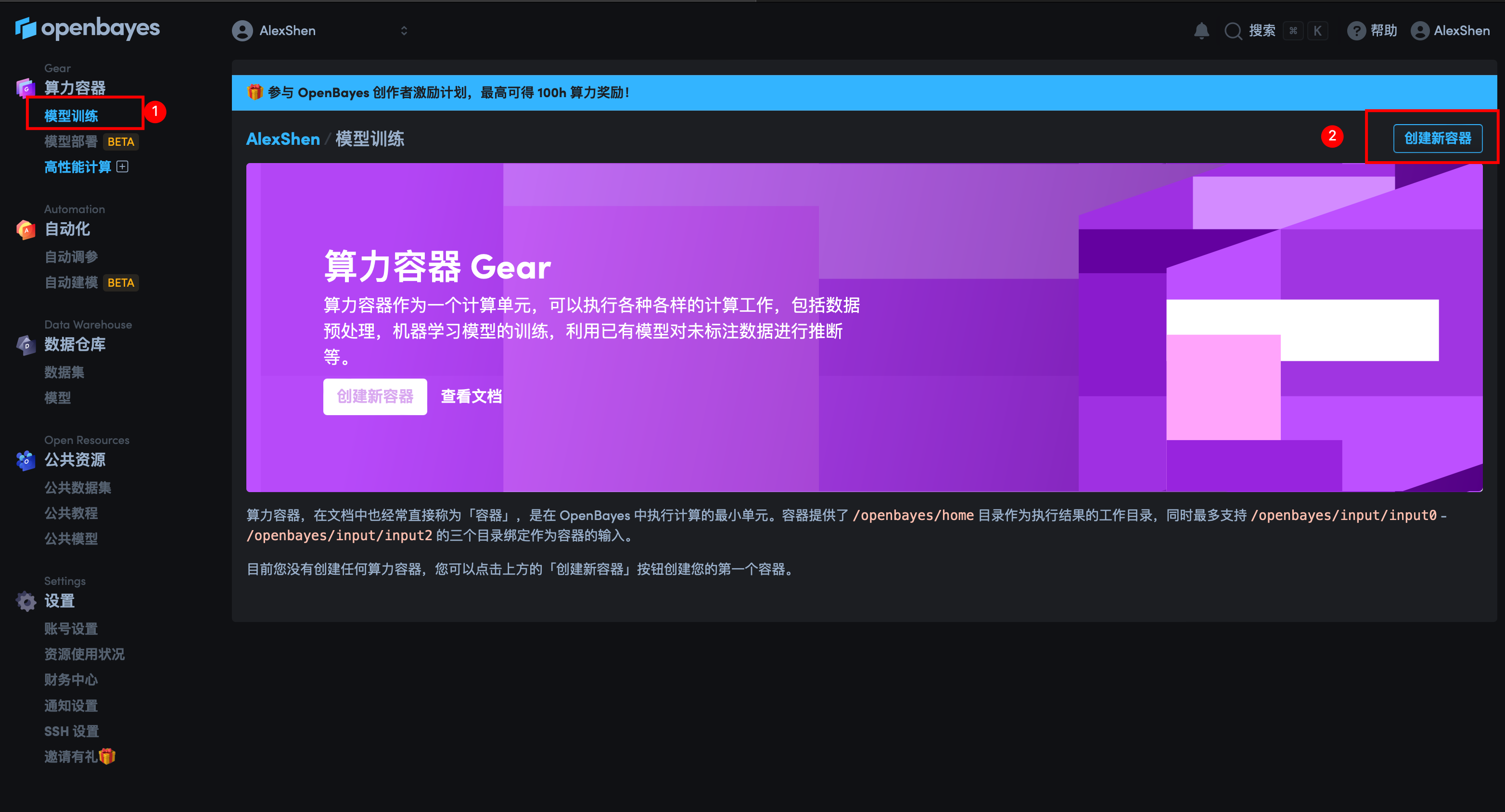
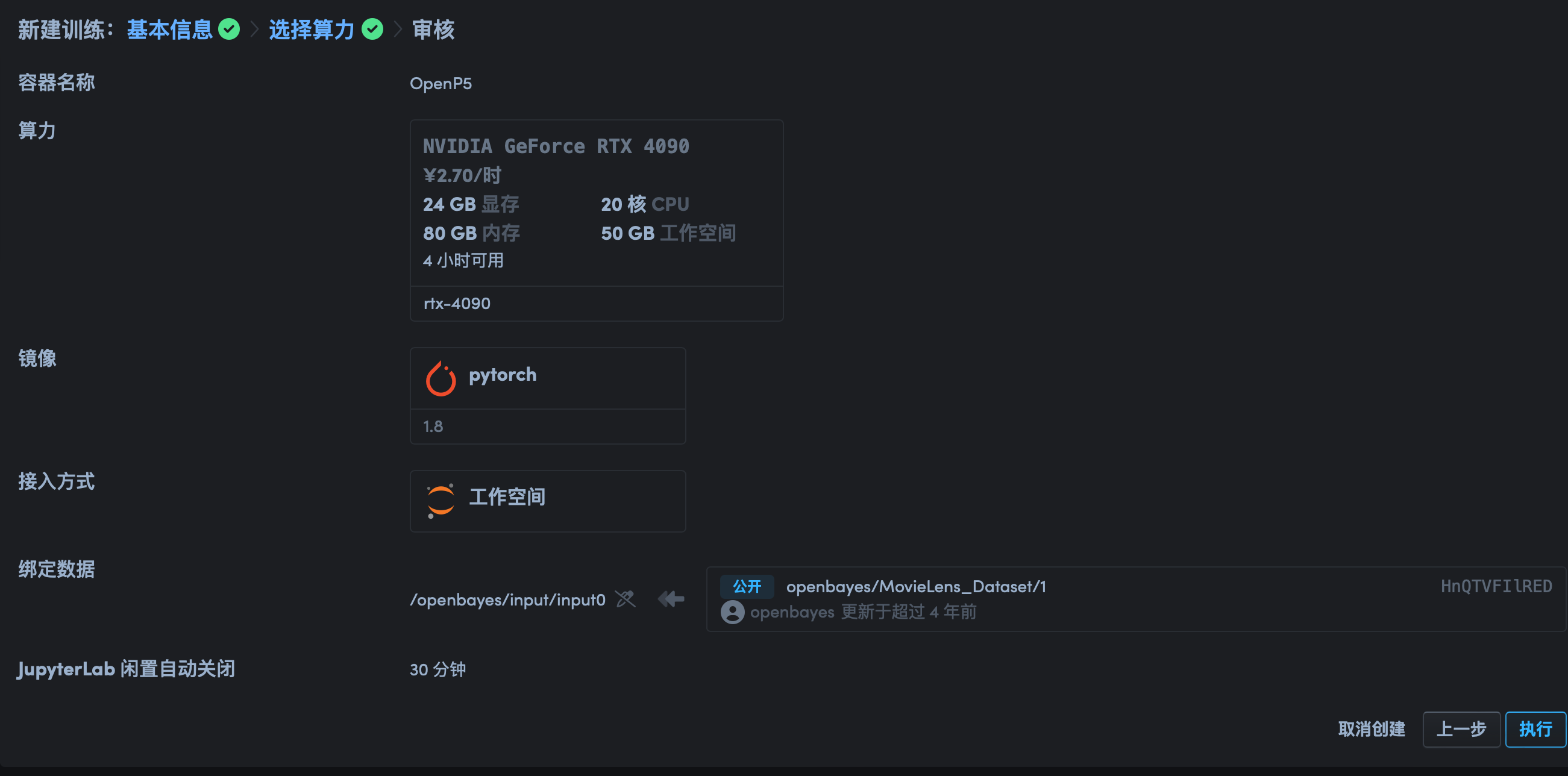
然后根据个人需要创建相应算力的容器即可。另外,官方提供了许多常见的数据集,可以直接搜索使用。我这次要做的是推荐系统相关的模型,因此选择了 Movielen 数据集。针对新用户,每个人都可以获得 3h 的 4090 显卡,对于一些简单的任务是足够的。
同时官方也提供了不同版本的 Pytorch,Tensorflow,paddlepaddle 的镜像,省去了配置环境的麻烦。
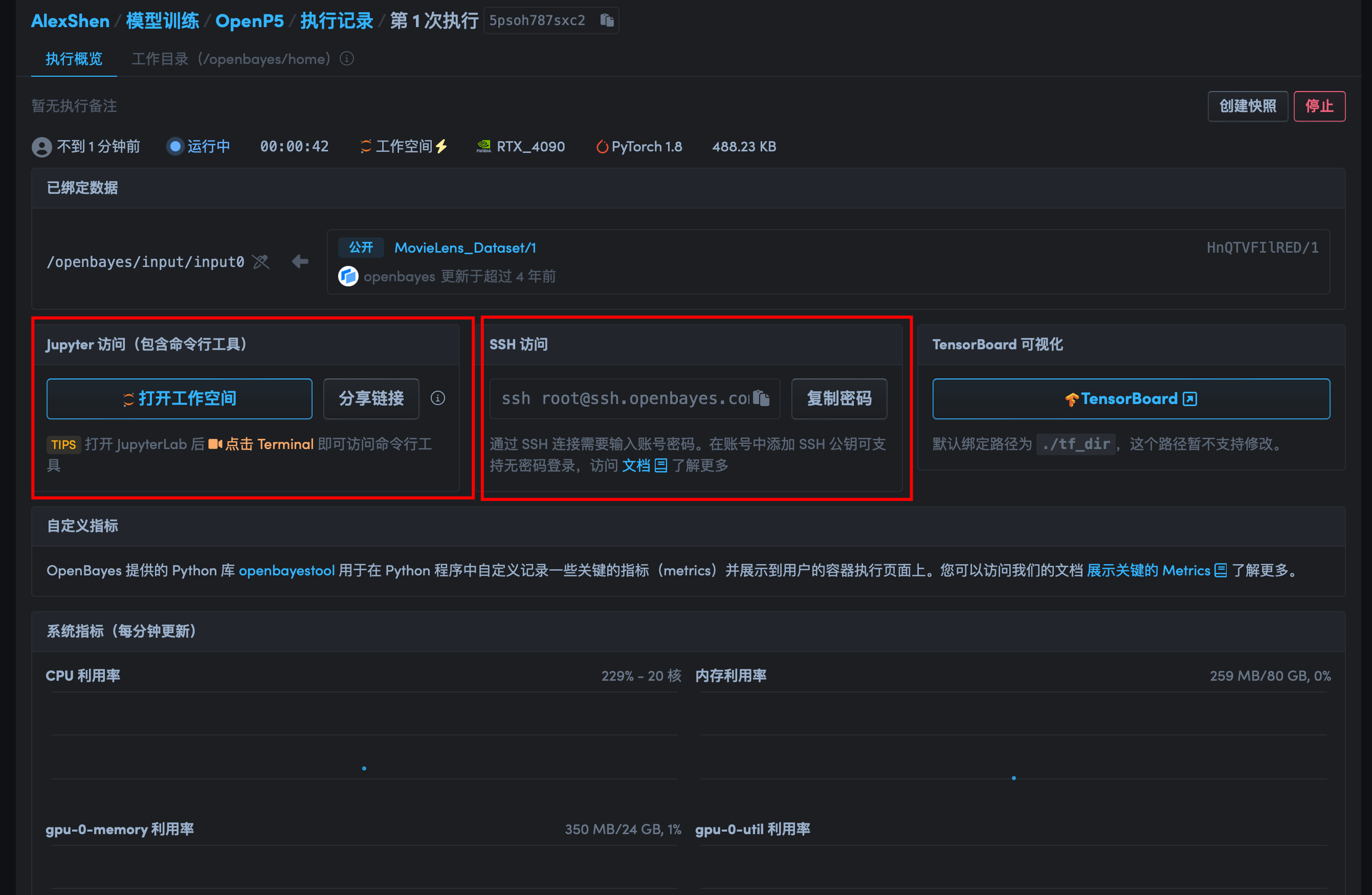
创建完成以后,可以看到如下图所示的控制台界面。官方也是提供了 Jupyter 以及 SSH 两种访问方式。
2. OpenP5 模型
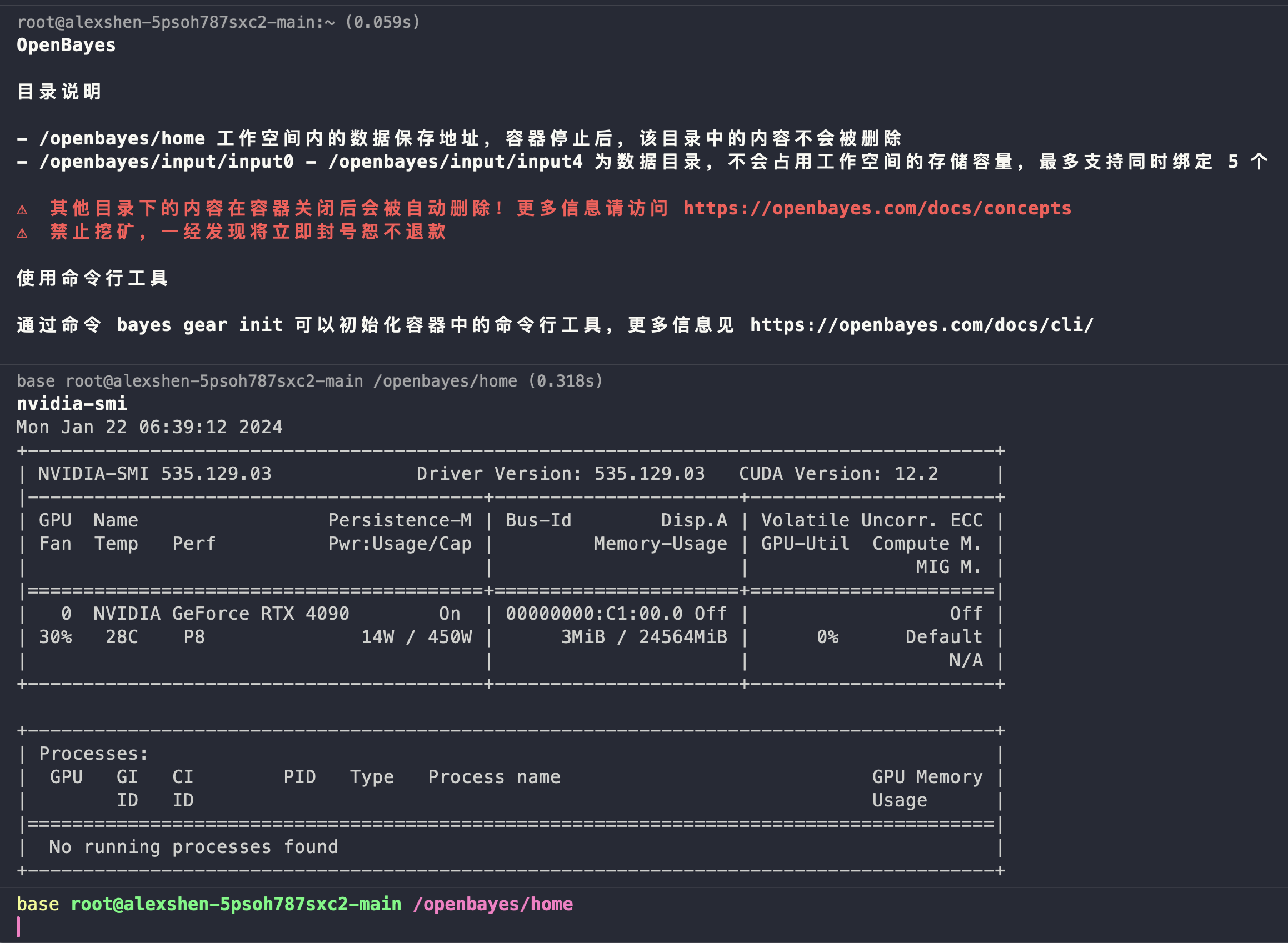
个人是比较习惯使用 SSH 连接服务器的。使用官方控制台提供的 ssh 连接指令,即可轻松的连接到 GPU 服务器。使用nvidia-smi可以查看 GPU 使用情况。
2.1 源码下载
本次测试的模型是一个基于 LLM 的推荐系统的开源平台。Github 链接:https://github.com/agiresearch/OpenP5
有兴趣的朋友可以进入 github,查看相应的论文。

git clone https://github.com/agiresearch/OpenP5.git
2.2 数据集下载
根据官方 README 的提示,前往 Google Drive 下载预处理过的数据集。本文采用ML100K 数据集进行测试。
本人在 Macos 平台,习惯使用 Termius 作为 SFTP 文件上传工具。
安装环境所需要的包
pip install transformers scikit-learn torchvision tqdm numpy datasets peft
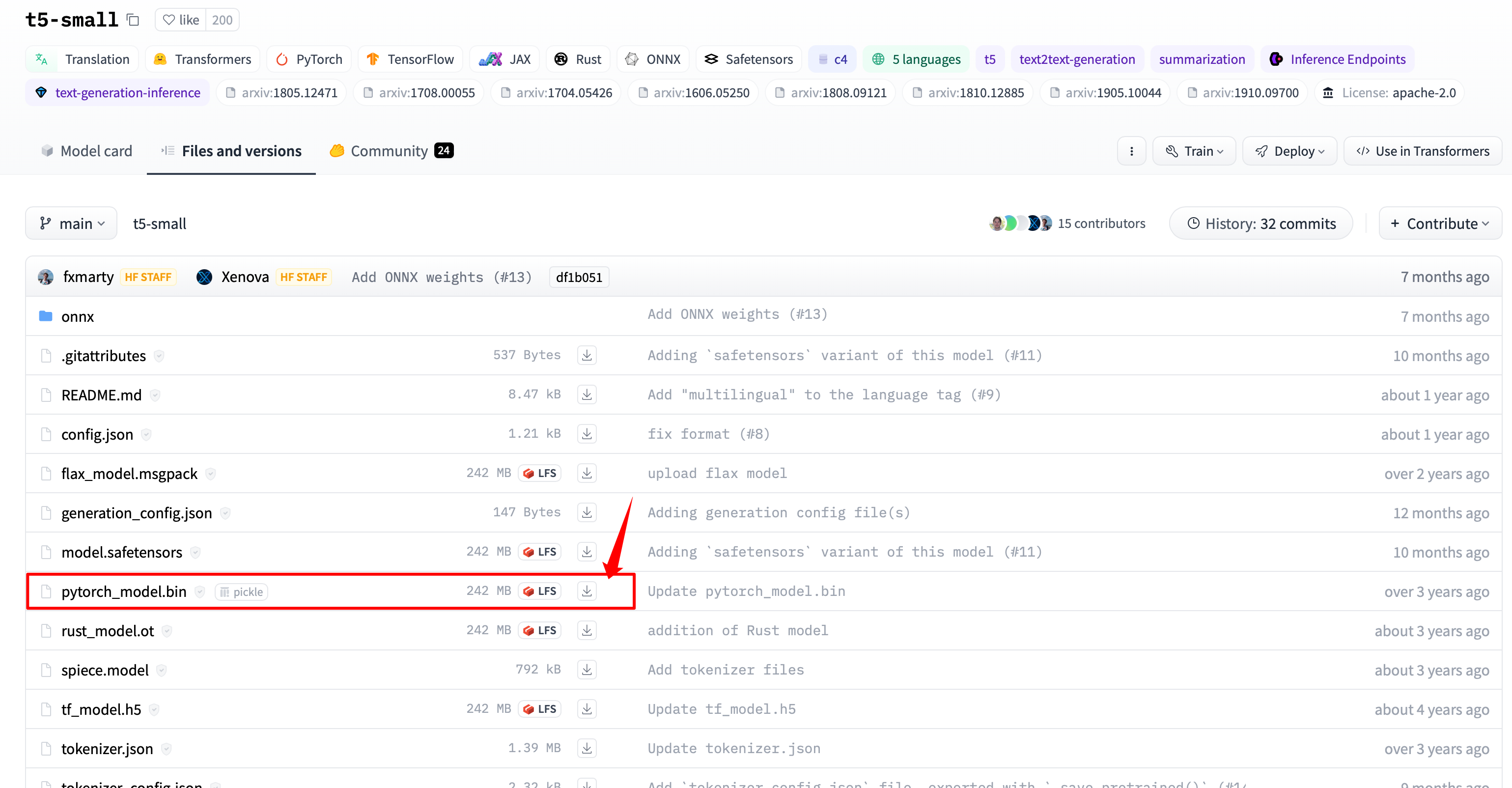
如果有网络问题,需要手动下载 huggingface t5-small 模型。https://huggingface.co/t5-small/
git lfs install
git clone https://huggingface.co/t5-small
2.3 修改运行指令
单卡服务器,需要修改CUDA_VISIBLE_DEVICES=0和 torchrun --nproc_per_node=1
#!/bin/bash
dir_path="../log/ML100K/"
if [ ! -d "$dir_path" ]; then
mkdir -p "$dir_path"
fi
CUDA_VISIBLE_DEVICES=0 torchrun --nproc_per_node=1 --master_port=1234 ../src/train.py --item_indexing sequential --tasks sequential,straightforward --datasets ML100K --epochs 10 --batch_size 128 --backbone t5-small --cutoff 1024 > ../log/ML100K/ML100K_t5_sequential.log
运行结果如下图所示。具体关于 OpenP5 的细节,将在下一篇博客中介绍。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 九州金榜|如何有效家庭教育以及对孩子的重要性
- gin参数验证
- matlab/simulink风电光伏储能虚拟同步机VSG下垂控制虚拟惯量控制,光伏变压减载控制一次调频二次调频研究,储能下垂控制SOC
- 【2023我的编程之旅】七次不同的计算机二级考试经历分享
- Halcon阈值处理的几种分割方法threshold/auto_threshold/binary_threshold/dyn_threshold
- 攻防实战-手把手带你打穿内网
- Linux awk命令教程:如何有效处理文本和数据分析(附案例详解和注意事项)
- Springboot单元测试mock踩坑
- HarmonOS 通用组件(Checkbox)
- TikTok海外直播专线:优化你的海外直播体验