爬虫入门,爬取豆瓣top250电影信息
发布时间:2024年01月19日
import requests
import csv
import parsel
import time
f = open('豆瓣top250.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(['电影名','导演','主演','年份','国家','类型','简介','评分','评分人数'])
for page in range(0,250,25):
time.sleep(2)
page_new = page/25+1
print(f'正在爬取第{page_new}页内容')
url = f'https://movie.douban.com/top250?start={page}&filter='
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
# print(response.text)
selector = parsel.Selector(response.text)
li_list = selector.css('.grid_view li')
for li in li_list:
title = li.css('.info .hd span.title:nth-child(1)::text').get() # 获取电影的名字
movie_info_list = li.css('.bd p:nth-child(1)::text').getall() # 获取电影信息,getall获取的是列表数据
introduce = li.css('.inq::text').get() # 电影的简介
rate = li.css('.rating_num::text').get() # 电影评分
comment_num = li.css('.star span:nth-child(4)::text').get().replace('人评价', '') # 评论人数
actor_list = movie_info_list[0].strip().split('???')
if len(actor_list) > 1:
actor_1 = actor_list[0].replace('导演: ','') # 导演
actor_2 = actor_list[1].replace('主演: ','') # 主演
actor_2 = actor_2.replace('...','')
movie_info = movie_info_list[1].strip().split('?/?')
movie_year = movie_info[0] # 年份
movie_country = movie_info[1] # 国家
movie_type = movie_info[2] # 类型
else:
actor_1 = actor_list[0]
actor_2 = 'None'
print(title,actor_1,actor_2,movie_year,movie_country,movie_type,introduce,rate,comment_num,sep='|')
csv_writer.writerow([title,actor_1,actor_2,movie_year,movie_country,movie_type,introduce,rate,comment_num])结果展现:
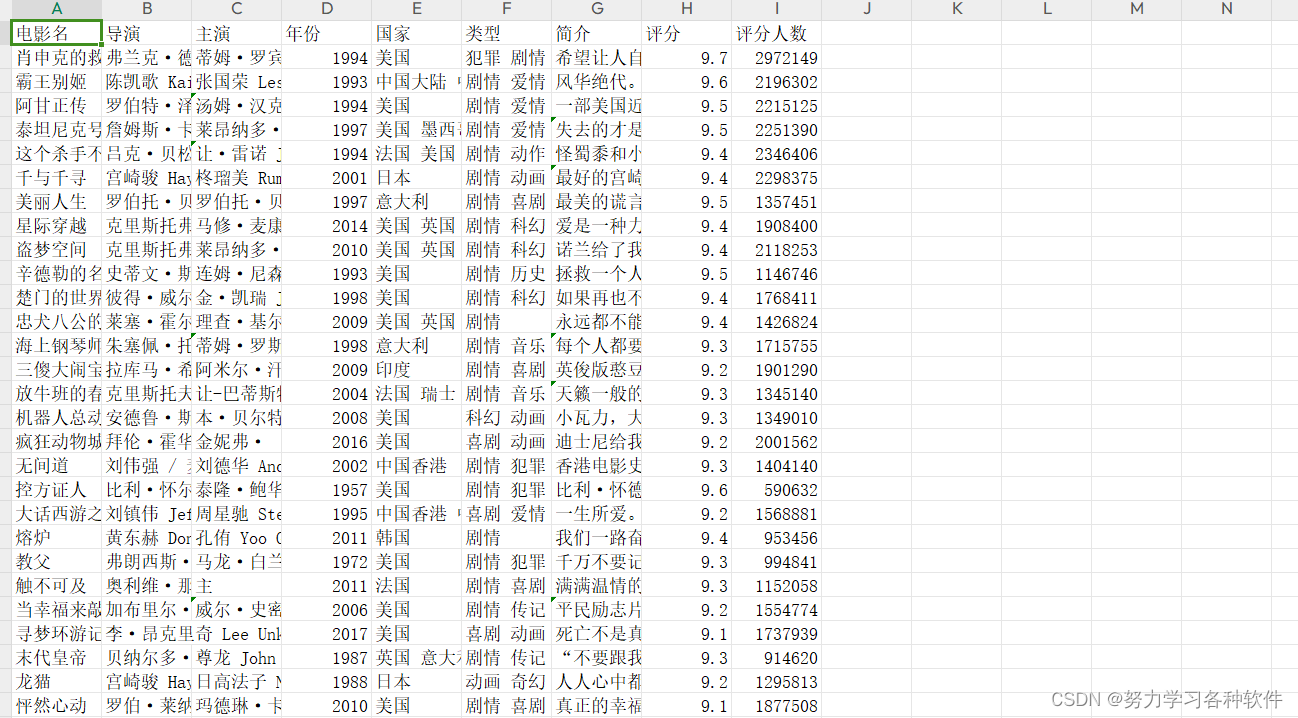
文章来源:https://blog.csdn.net/m0_57265868/article/details/135704145
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 改善制造业客户体验的实用技巧与策略
- 《每天一分钟学习C语言·七》指针、字节对齐等
- ASP.NETCore WebAPI 入门 杨中科
- Python基础学习:同步异步阻塞与非阻塞
- C++处方管理系统架构——设计模式应用场景分析
- 高光谱分类论文解读分享之HybridSN:基于 3-D–2-D CNN 的高光谱分类(经典回顾)
- 【亲测可行】如何申请并登录腾讯云免费服务器
- QSqlQuery 是 Qt 框架中的一个类,用于执行 SQL 查询和操作数据库。
- spring事务不生效的场景有哪些
- 标识符(C语言)