数禾使用 Knative 加速 AI 模型服务部署丨KubeCon China 2023
作者:李鹏(阿里云)、魏文哲(数禾科技), 此文基于 KubeCon China 2023 分享整理
摘要
AI 服务的数据、训练、推理等都需要消耗大量的计算资源以及运维成本,在数禾科技的金融业务场景下,模型存频繁迭代,线上也会同时部署多个版本的模型用于评估模型线上的真实效果,资源成本高。如何在保证服务质量基础之上提升 AI 服务运维效率并降低资源成本具有挑战性。
Knative 是一款基于 Kubernetes 之上的开源 Serverless 应用架构,提供基于请求的自动弹性、缩容到 0 以及灰度发布等功能。通过 Knative 部署 Serverless 应用可以做到专注于应用逻辑开发,资源按需使用。因此将 AI 服务与 Knative 技术相结合可以获得更高的效率并降低成本。
当前数禾科技通过 Knative 部署 500+AI 模型服务,资源成本节约比例 60%,平均部署周期由之前的 1 天缩短至 0.5 天。
在本次分享中,我们将向您展示如何基于 Knative 部署 AI 工作负载,具体内容包括:
- Knative 介绍
- 数禾基于 Knative 的最佳实践
- 如何在 Knative 部署 Stable Diffusion
Knative 介绍

众所周知 Kubernetes 自 2014 年开源以来,受到众多厂商和开发者的关注,作为一款开源容器化编排系统,用户使用 K8s 可以做到降低运维成本、提高运维效率,并且其提供标准化 API,某种意义就是避免被云厂商绑定,进而形成了以 K8s 为核心的云原生生态。据 CNCF 2021 调查,96% 的企业正在使用或评估 Kubernetes。
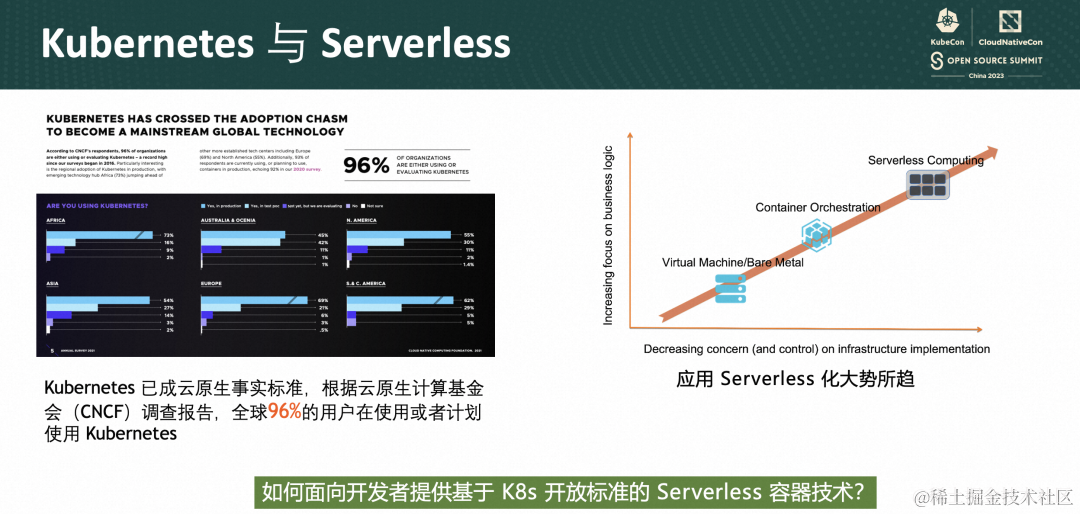
随着云原生技术的演进,以应用为中心,资源按需使用的 Serverless 技术逐渐成为主流。Gartner 预测,2025 年将有 50% 以上的全球企业部署 Serverless。
我们知道以 AWS Lambda 为代表的 FaaS 将 Serverless 带火了。FaaS 确实简化了编程,只需要编写一段代码就可以直接运行,不需要开发者关心底层基础设施。但是 FaaS 当前也存在的明显的不足,包括开发模式侵入性强、函数运行时长限制,跨云平台的支持等。
而以 K8s 为代表的容器技术,恰恰已经很好的解决了这些问题。Serverless 的核心理念是聚焦业务逻辑,减少基础设施的关注。
那么如何面向开发者提供基于 K8s 开放标准的 Serverless 容器技术?
答案是:Knative。
Knative 发展轨迹
Knative 是在 2018 的 Google Cloud Next 大会上发布的一款基于 Kubernetes 的开源 Serverless 容器编排框架。目标就是制定云原生、跨平台的 Serverless 应用编排标准,打造企业级 Serverless 平台。 阿里云容器服务也在最早 2019 的时候,已经提供 Knative 产品化能力,随着 2022 年 3 月加入到 CNCF,目前越拉越多的开发者拥抱 Knative。
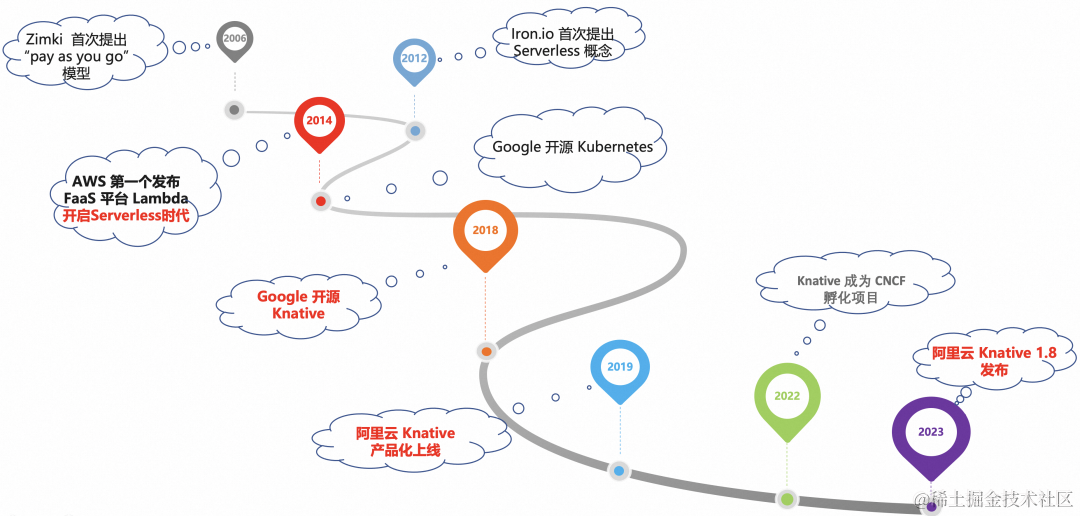
Knative 概要介绍
Knative 核心模块主要包括部署工作负载的 Serving 和事件驱动框架 Eventing 。
Knative Serving 核心能力就是其简洁、高效的应用托管服务,这也是其支撑 Serverless 能力的基础。Knative 可以根据您应用的请求量在高峰时期自动扩容实例数,当请求量减少以后自动缩容实例数,可以非常自动化的帮助您节省成本。
Knative 的 Eventing 提供了完整的事件模型。事件接入以后通过 CloudEvent 标准在内部流转,结合 Broker/Trigger 机制给事件处理提供了非常理想的方式。
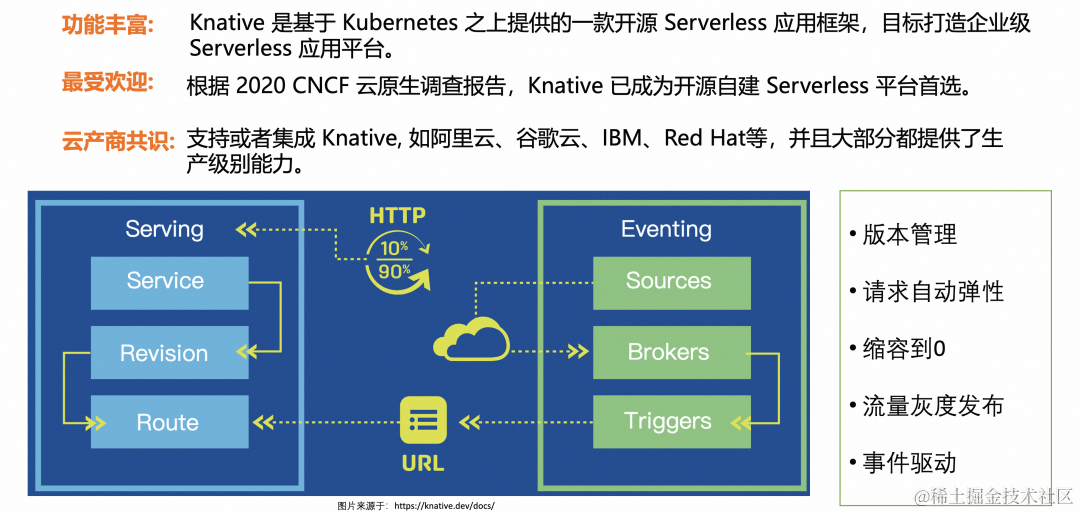
Knative 应用模型
Knative 应用模型是 Knative Service:
- Knative Service 中包含 2 部分配置,一部分用于配置工作负载,叫做 Configuration,每次 Configuration 内容更新都会创建一个新的 Revision。
- 另一部分 Route 主要负责 Knative 的流量管理。
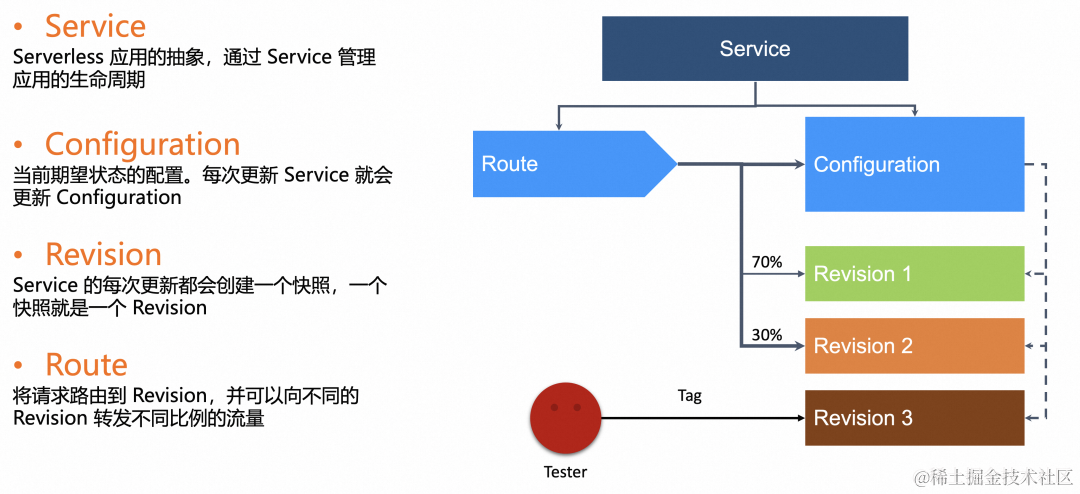
我们看一下基于流量的灰度发布我们可以怎样做:
假设一开始我们创建了 V1 版本的 Revison,这时候如果有新的版本变更,那么我们只需要更新 Service 中的 Configuration,就会创建出 V2 版本,然后我们可以通过 Route 对 V1、V2 设置不同对流量比例,这里 v1 是 70%,v2 是 30%,那么流量就会分别按照 7:3 的比例分发到这两个版本上。一旦新到 V2 版本验证没有问题,那么我们接下来就可以通过调整比例继续灰度,直到新版本 V2 100%。在这个灰度到过程中,一旦发现新版本有异常,可以通过调整比例进行回滚操作。
除此以外,我们可以在 Route 到 Traffic 中对 Revison 打 Tag,打完 Tag 的 Revison,我们可以直接通过 Url 进行单独的版本测试,可以理解为金丝雀验证,对这个版本对调试不会影响正常对流量访问。
基于请求的自动弹性: KPA
为什么要做基于请求的自动弹性?
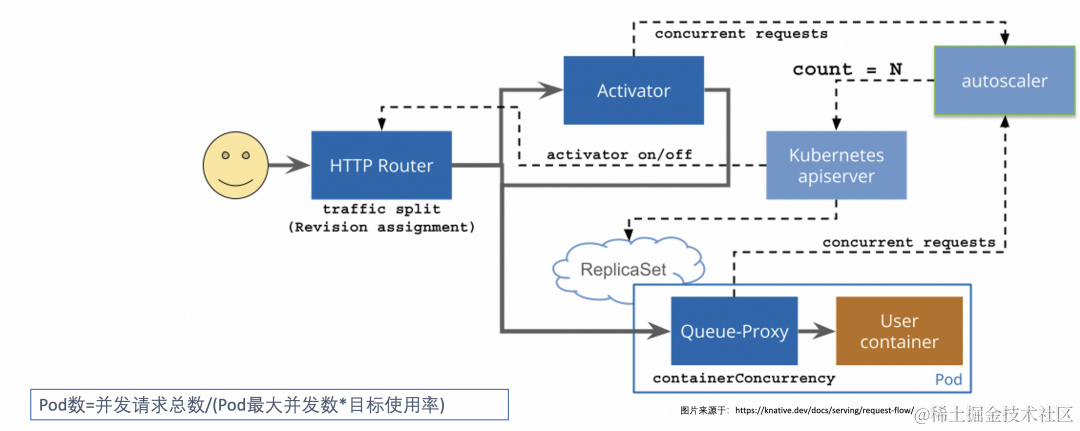
基于 CPU 或者 Memory 的弹性,有时候并不能完全反映业务的真实使用情况,而基于并发数或者每秒处理请求数(QPS/RPS),对于 web 服务来说更能直接反映服务性能,Knative 提供了基于请求的自动弹性能力。
如何采集指标?
要获得当前服务的请求数,Knative Serving 为每个 Pod 注入 QUEUE 代理容器(queue-proxy),该容器负责收集用户容器并发数 (concurrency) 或请求数 (rps) 指标。Autoscaler 定时获取这些指标之后,会根据相应的算法,调整 Deployment 的 Pod 数量,从而实现基于请求的自动扩缩容。
如何计算弹性 Pod 数?
Autoscaler 会根据每个 Pod 的平均请求数(或并发数)进行所需 Pod 数计算。默认情况下 Knative 使用基于并发数的自动弹性,默认 Pod 的最大并发数为 100。此外 Knative 中还提供了一个叫 target-utilization-percentage 的概念,称之为目标使用率。
以基于并发数弹性为例,Pod 数计算方式如下:
POD数=并发请求总数/(Pod最大并发数*目标使用率)
缩容到 0 的实现机制
使用 KPA 时中当无流量请求时,会将 Pod 数自动缩容到 0;当有请求时,会从 0 开始扩容 Pod。那么 Knative 中是如何实现这样的操作呢?答案是通过模式切换。
Knative 中定义了 2 种请求访问模式:Proxy 和 Serve。 Proxy 顾名思义,代理模式,也就是请求会通过 activator 组件进行代理转发。Serve 模式是请求直达模式,从网关直接请求到 Pod,不经过 activator 代理。如下图:
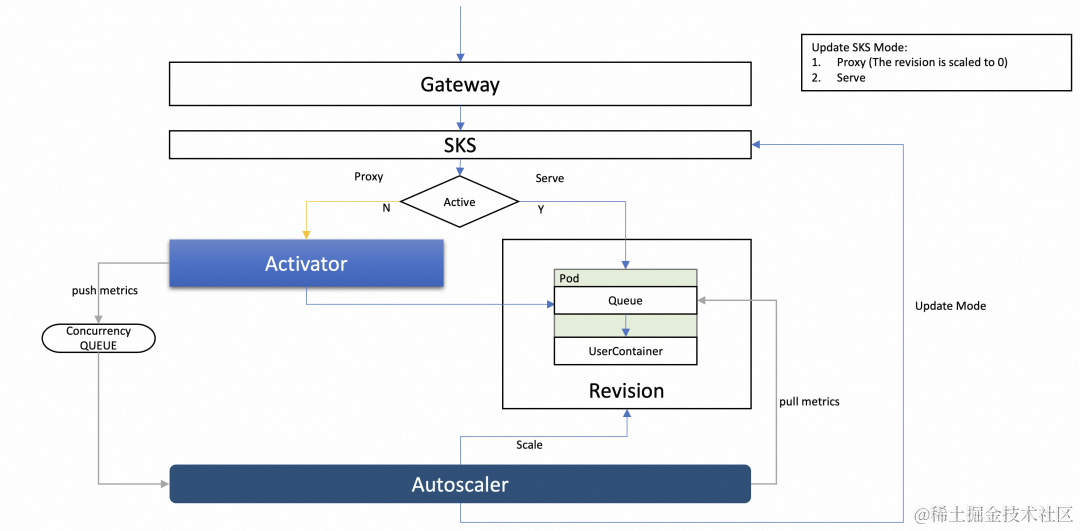
模式的切换是由 autoscaler 组件负责,当请求为 0 时,autoscaler 会将请求模式切换为 Proxy 模式。这时候请求会通过网关请求到 activator 组件,activator 收到请求之后会将请求放在队列中,同时推送指标通知 autoscaler 进行扩容,当 activator 检测到由扩容 Ready 的 Pod 之后,随即将请求进行转发。
应对突发流量
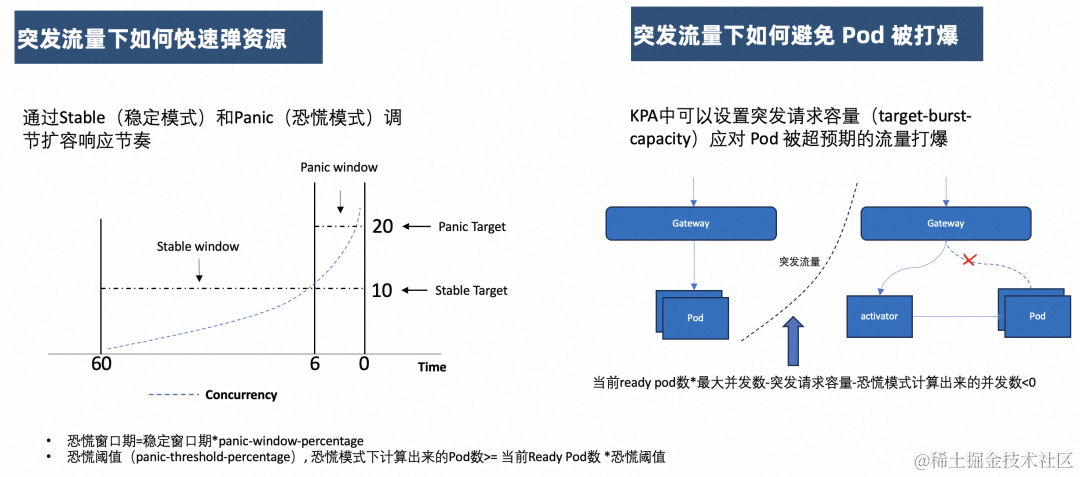
突发流量下如何快速弹资源
这里 KPA 涉及到 2 个与弹性相关的概念:Stable(稳定模式)和 Panic(恐慌模式),基于这 2 种模式,我们可以看到 KPA 如何快速弹资源。
首先稳定模式是基于稳定窗口期,默认是 60 秒。也就是计算在 60 秒时间段内,Pod 的平均并发数。
而恐慌模式是基于恐慌窗口期,恐慌窗口期是通过稳定窗口期与 panic-window-percentage 参数计算得到。*恐慌窗口期计算方式:恐慌窗口期=稳定窗口期 panic-window-percentage。 默认情况下也就是 6 秒。计算在 6 秒时间段内,Pod 的平均并发数。
KPA 中会基于稳定模式和恐慌模式 Pod 的平均并发数分别计算所需要的 Pod 数。
那么实际根据哪个值进行弹性生效呢?这里会依据恐慌模式下计算的 Pod 数是否超过恐慌阈值 PanicThreshold 进行判断。默认情况下,当恐慌模式下计算出来的 Pod 数大于或等于当前 Ready Pod 数的 2 倍,那么就会使用恐慌模式 Pod 数进行弹性生效,否则使用稳定模式 Pod 数。
显然,恐慌模式的设计是为了应对突发流量场景。至于弹性敏感度,则可以通过上述的可配置参数进行调节。
突发流量下如何避免 Pod 被打爆
KPA 中可以设置突发请求容量(target-burst-capacity)应对 Pod 被超预期的流量打爆。也就是通过这个参数值的计算,来调节请求是否切换到 Proxy 模式,从而面对突发流量时通过 activator 组件作为请求缓冲区,避免 Pod 被打爆。
减少冷启动的一些技巧
延迟缩容
对于启动成本较高的 Pod, KPA 中可以通过设置 Pod 延迟缩容时间以及 Pod 缩容到 0 保留期,来减少 Pod 扩缩容频率。

调低目标使用率,实现资源预热
Knative 中提供了目标阈值使用率的配置。通过调小该值可以提前扩容超过实际需要使用量的 Pod 数,在请求达到目标并发数之前进行扩容,间接的可以做到资源预热。
弹性策略配置
通过上面的介绍,我们对 Knative Pod Autoscaler 工作机制有了进一步的了解,那么接下来介绍如何配置 KPA。Knative 中配置 KPA 提供了两种方式:全局模式和 Revision 模式。 全局模式可以通过 ConfigMap:config-autoscaler 进行配置,参数如下:

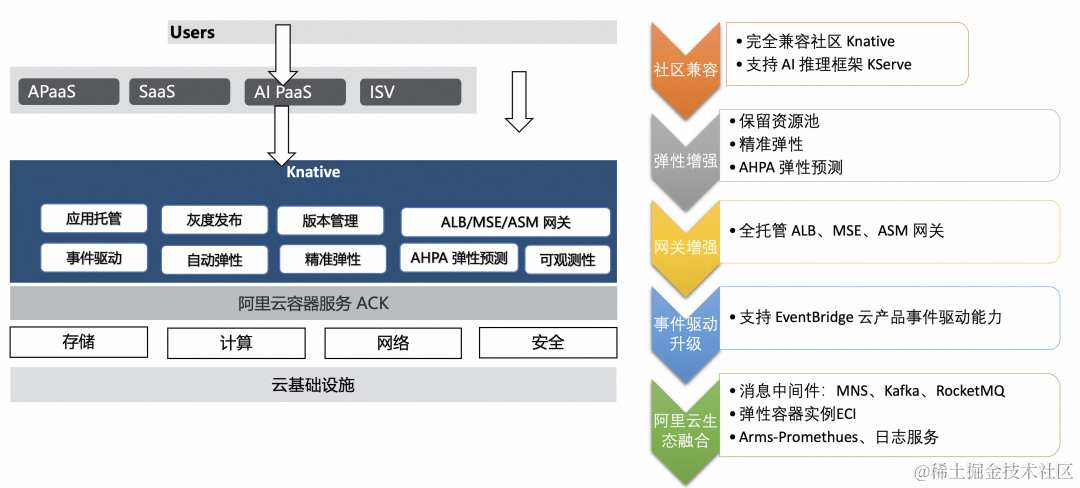
阿里云容器服务 Knative
开源的产品一般都不能直接拿来产品化使用。Knative 产品化面临的问题包括:
- 管控组件多,运维复杂
- 算力多样性,如何按需调度到不同的资源规格上
- 云产品级别的网关能力
- 冷启动的问题如何解
- 。。
针对这些问题,我们提供了容器服务 Knative 产品。完全兼容社区 Knative,支持 AI 推理框架 KServe。增强弹性能力,支持保留资源池、精准弹性以及弹性预测;支持全托管 ALB、MSE 以及 ASM 网关;事件驱动方面与云产品 EventBridge 进行集成;此外与阿里云其它产品,如 ECI、arms、日志服务等进行了全方位的融合。
保留资源池
在原生的 KPA 能力之上,我们提供了保留资源池的能力。该功能可以应用在如下场景:
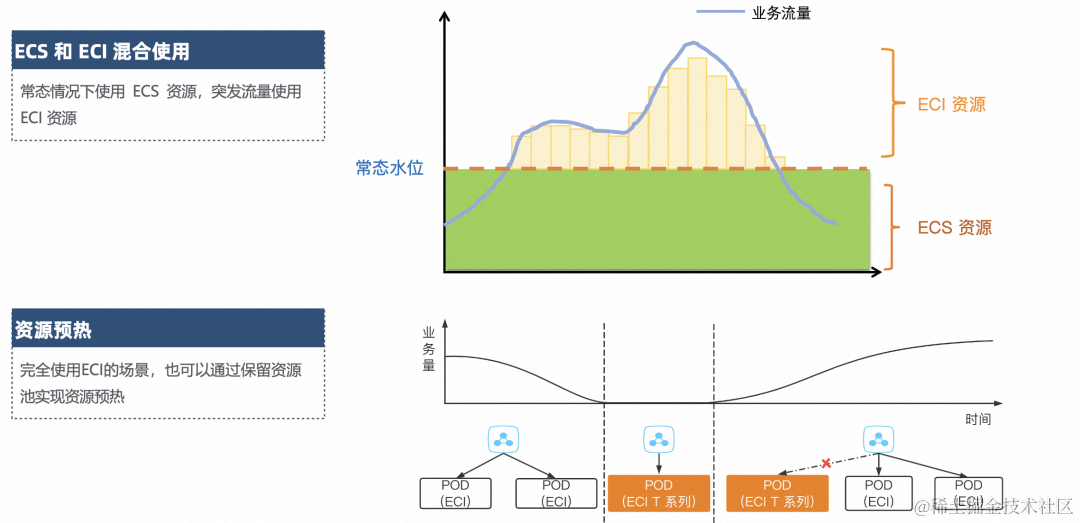
- ECS 与 ECI 混用。如果希望常态情况下使用 ECS 资源,突发流量使用 ECI, 那么我们可以通过保留资源池来实现。在常态下通过 ECS 资源承载流量,突发流量则新扩容出来的资源使用 ECI。
- 资源预热。对于完全使用 ECI 的场景,也可以通过保留资源池实现资源预热。当在业务波谷时使用低规格的保留实例替换默认的计算型实例,当第一个请求来临时使用保留实例提供服务,同时也会触发默认规格实例的扩容。当默认规格实例扩容完成以后所有新请求就会都转发到默认规格上,然后下线保留实例。通过这种无缝替换的方式实现了成本和效率的平衡,即降低了常驻实例的成本又不会有显著的冷启动时长。
精准弹性
单个 Pod 处理请求的吞吐率有限,如果多个请求转发到同一个 Pod,会导致服务端过载异常,因此需要精准的控制单个 Pod 请求并发处理数。尤其对一些 AIGC 场景下,单个请求会占用较多的 GPU 资源,需要严格的限制每个 Pod 并发处理的请求数。
Knative 与 MSE 云原生网关结合,提供基于并发数精准控制弹性的实现:mpa 弹性插件。
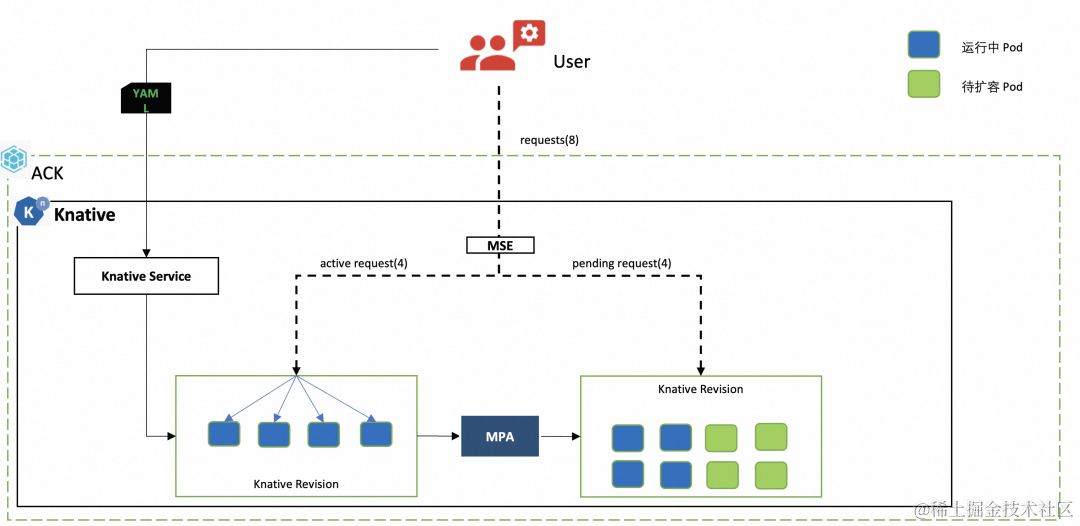
mpa 会从 MSE 网关获取并发数,并计算所需要的 Pod 数进行扩缩容,待 Pod ready 之后,MSE 网关将请求转发到相应的 Pod。
弹性预测
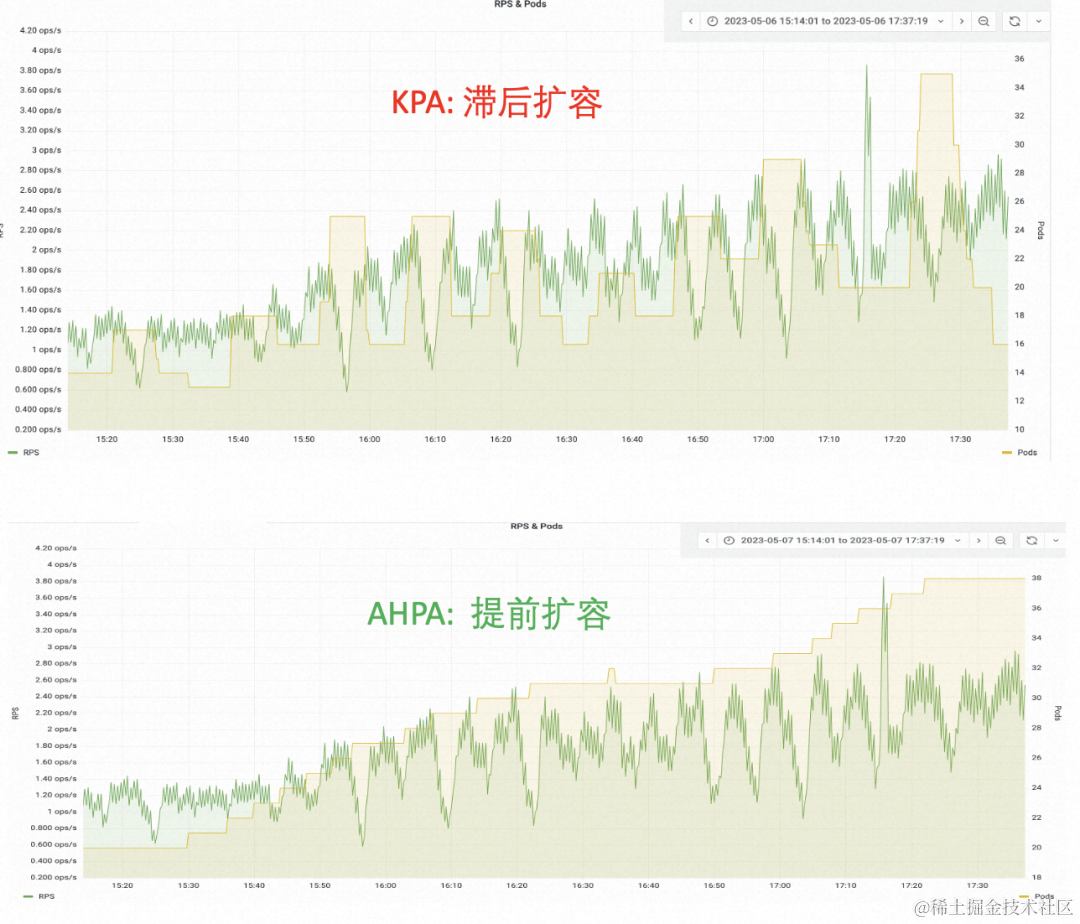
容器服务 AHPA(Advanced Horizontal Pod Autoscaler)可以根据业务历史指标,自动识别弹性周期并对容量进行预测,解决弹性滞后的问题。
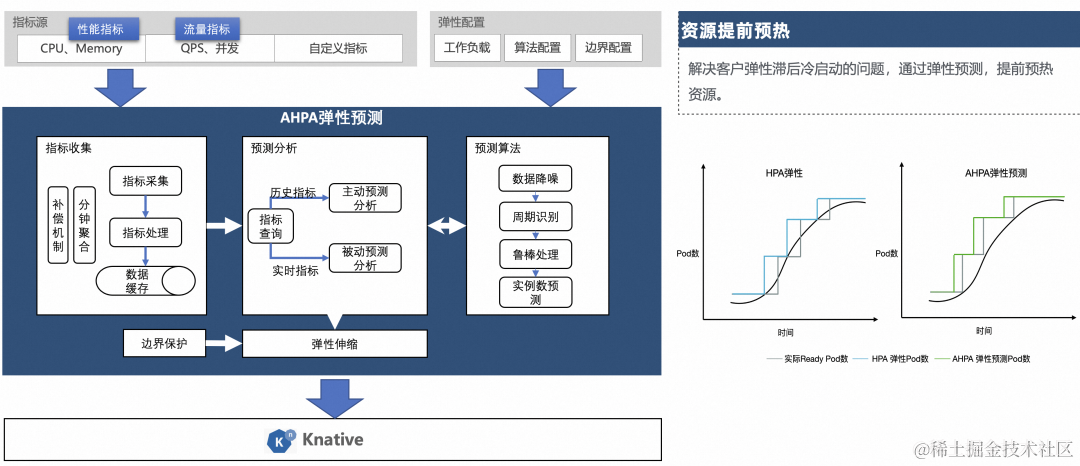
当前 Knative 支持 AHPA(Advanced Horizontal Pod Autoscaler)的弹性能力,当请求具有周期性时,可通过弹性预测,实现预热资源。相比于调低阈值进行资源预热,通过 AHPA 可以最大程度的提升资源利用率。
通过 AHPA 可以做到:
- 资源提前准备:在请求到来之前,提前扩容
- 稳定可信:预测准备的 RPS 吞吐量足够覆盖实际需要的请求数
事件驱动
Knative 中通过 Eventing 提供事件驱动能力,在 Eventing 中通过 Broker/Trigger 进行事件流转和分发。
但直接使用原生的 Eventing 也面临一些问题:
- 如何覆盖足够多的事件源
- 如何保障事件流转过程中不丢
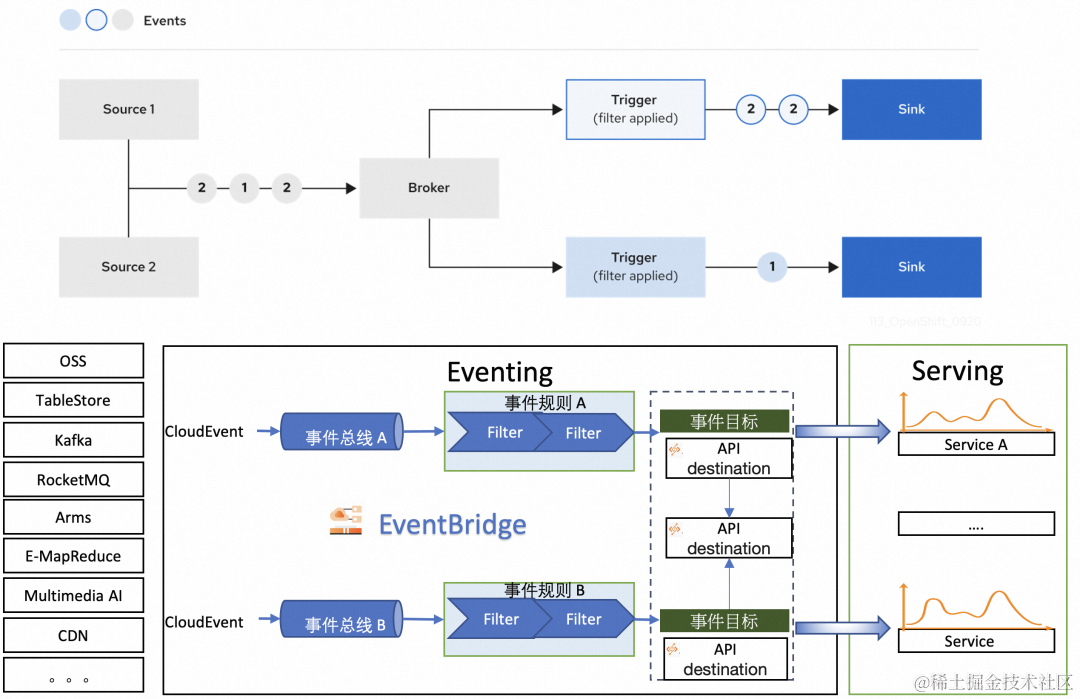
如何打造生产级别的事件驱动能力呢?我们与阿里云 EventBridge 进行结合。
EventBridge 是阿里云提供的一款无服务器事件总线服务, 阿里云 Knative Eventing 底层集成了 EventBridge, 提供了面向 Knative Eventing 使用的云产品级别事件驱动能力。
那么我们实际的业务场景中如何使用 Knative ?通过 Knative 又能我们带来哪些收益呢?接下来给大家介绍一下数禾科技使用 Knative 的最佳实践。
数禾基于 Knative 的最佳实践

数禾科技(全称“上海数禾信息科技有限公司”)成立于 2015 年 8 月,数禾科技以大数据和技术为驱动,为金融机构提供高效的智能零售金融解决方案,业务涵盖消费信贷、小微企业信贷、场景分期等多个领域,提供营销获客、风险防控、运营管理等服务。

数禾科技旗下还呗 APP 是一款基于消费多场景的分期服务平台,于 2016 年 2 月正式进入市场。通过与持牌金融机构合作,为大众提供个人消费信贷服务,并为小微企业主提供贷款资金支持。截至 2023 年 6 月,还呗累计激活用户 1.3 亿,为 1700 万用户提供合理信贷服务,助力用户“好借好还呗”。

模型发布痛点
模型上线阶段,资源浪费问题
- 为了保证我们的服务稳定,一般都会预留 buffer,通常都是按照超过我们实际使用规格储备资源。
- 创建的资源不是全时段用满资源,会看到线上的一些应用,尤其是一些离线 job 类型的应用,大部分时间整个 cpu 和内存的使用率都是很低的,只有某些时间段资源使用率才会上涨上去,有很明显的潮汐现象。
- 因为资源使用缺少足够的弹性,往往会造成资源大量的浪费。

模型下线阶段资源难回收的问题
- 线上的一个模型,可能会同时存在多个版本。
- 通过不同的版本来评估模型线上真实效果,如果某个版本评估效果不好,那么则会在决策流程中将这个版本拿掉。这时候这个模型实际就不再提供服务了,这时候如果资源不能及时下线,就会造成资源的浪费。
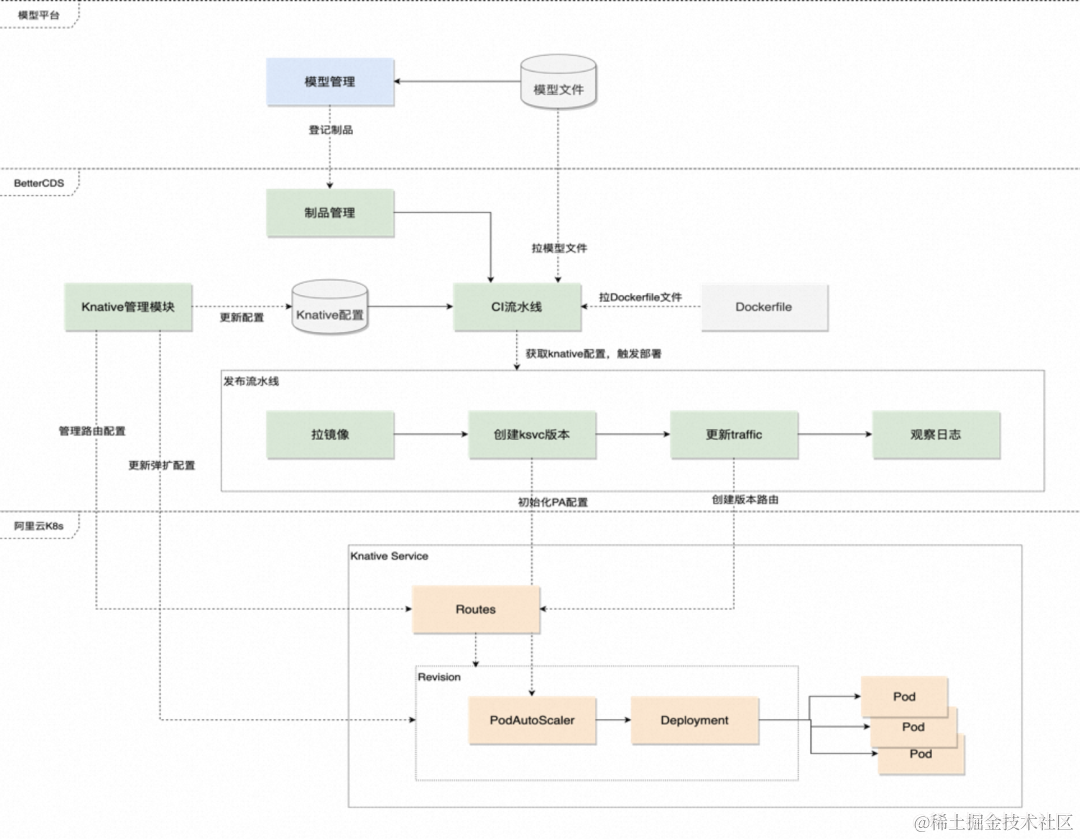
模型持续交付技术架构
模型平台部分
模型平台产出模型文件,然后将模型文件登记到 BetterCDS
BetterCDS 会产生一个跟这个模型文件对应的制品
通过制品可以完成模型发布及模型版本的管理
Knative 管理模块
配置模型全局的 Knative 弹扩配置
每个模型都可以配置自己的 knative 的弹扩配置
CI 流水线
CI 流水线主要流程是拉取模型文件,通过 dockerfile,构建模型镜像
部署过程
流水线去更新 Knative Service,设置路由版本和镜像地址,更新 knative 的弹扩配置,knative 则会产生一个对应制品的版本的 revision
Knative Service 更新过程
- knative service 更新则会产生一个 revision 版本
- revision 版本会产生一个 deployment 对象
- 流水线会观察 deployment 状态,如果所有 pod 都 ready 了,那么则认为这个版本就部署成功了
- 部署成功后为 revision 打一个 tag 来创建一个版本路由
模型多版本发布
通过 Knative 的 Configuration 实现了模型的多版本制品发布:
- 制品的多个版本跟 Configuration 的 Revision 版本一一对应。
- 制品包含模型版本镜像,通过更新 Knative Service 的镜像版本,产生于制品对应的 Revision。
模型多版本服务共存能力:
- 通过 Tag 的方式为 Revision 都创建了一个版本路由,根据不同的路由调用不同的版本服务。
- 因为有多版本同时存在,可以支持决策流程中调用不同的模型版本,以观察模型效果,同时由于多个路由版本的存在,可以支持多种流量策略。
还支持了支持一组 latest 路由,可以做到在不改变的决策流程的情况下,可以将 latest 路由切换到任意版本,就完成线上流量的切换。

基于请求的弹扩
为什么模型会采用基于请求数的弹扩策略:
-
模型大部分为计算密集型服务,模型 cpu 使用率跟请求数是正相关的,所以一旦请求激增,将导致 cpu 被打满,最终导致服务雪崩。
-
除了基于请求的弹扩,还有根据 cpu 和内存指标 HPA 弹扩,但是 HPA 弹扩也存在以下几点问题:
a. 指标的弹扩链路较长:从服务暴露指标,Prometheus 采集到指标,指标上升,然后 hpa 根据指标计算出扩容的 pod 数,然后开始弹扩 pod,整体弹扩的链路比较长。
b. 指标不准确:例如 java 的 gc 会导致内存的周期性变化。
c. 指标不能反映真实的服务状态:从指标上升时,响应延迟就已经变很高了,也就是说通过指标发现超过阈值,就已经延后了,然后再开始弹扩 pod,到 podready 的时候也已经延后了。
- 因此我们需要将弹扩时间提前,使用请求数来触发模型弹扩,保证模型服务可以保持正常服务状态。
以下是一个 revision 版本请求从 100%-0% 的弹扩工作过程:
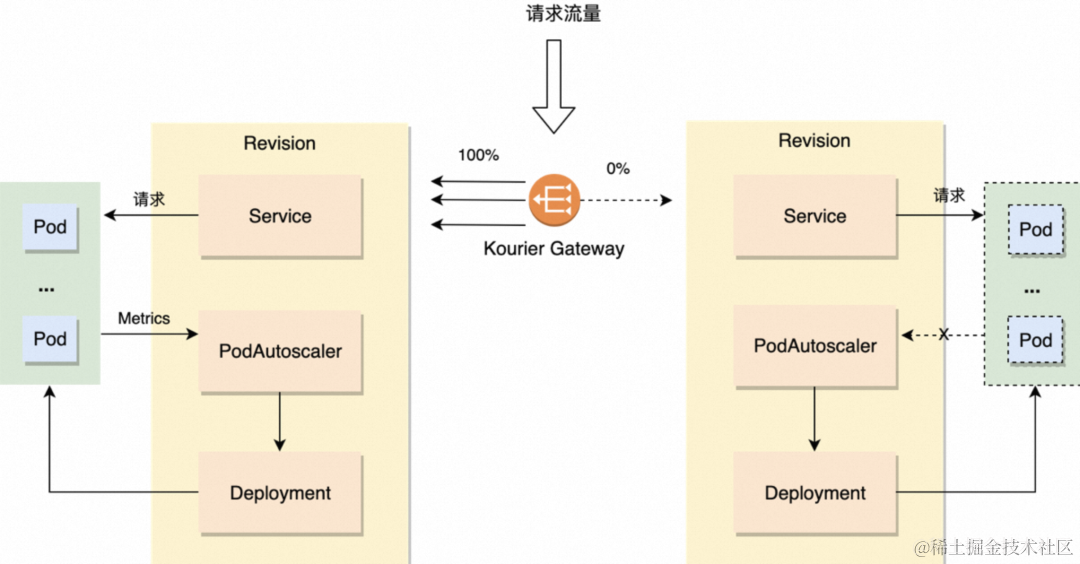
Knative 弹扩链路如下:
- 流量从 service 请求到 pod。
- PodAutoscaler 实时采集 Pod 中 queue-proxy 的流量请求指标,根据当前请求来计算出弹扩的 pod 数。
- PodAutoscaler 控制 Deployment 进行 pod 弹扩,弹扩出来的 Pod 又会加入到这个 Service 下,就完成了 Pod 的扩容。
相较于指标弹扩,基于请求的弹扩策略,响应更快,灵敏度更高。能够保证服务的响应。针对过去资源下线的痛点,由于支持可以缩容到 0,那么我们可以将 revision 最小 pod 数调整为 0,在没有请求的情况下,就会自动缩容到 0。再结合弹性节点,缩容到 0 也就不会再占用资源,也实现了模型服务的 Serverless 能力。
BetterCDS 一站式模型发布
模型是通过流水线完成版本部署的,以下是 BetterCDS 发布流水线步骤过程。

- 部署版本步骤:触发 Knative 模型部署。
- 新增路由:新增 Knative 版本路由。
- 更新 latest 路由:更新 latest 路由作为流水线的参数,可以选择部署完成同时更新 latest 路由。
通过 Knative 弹扩配置管理模块可以配置每个模型可以配置全局的弹扩配置和版本的弹扩配置。

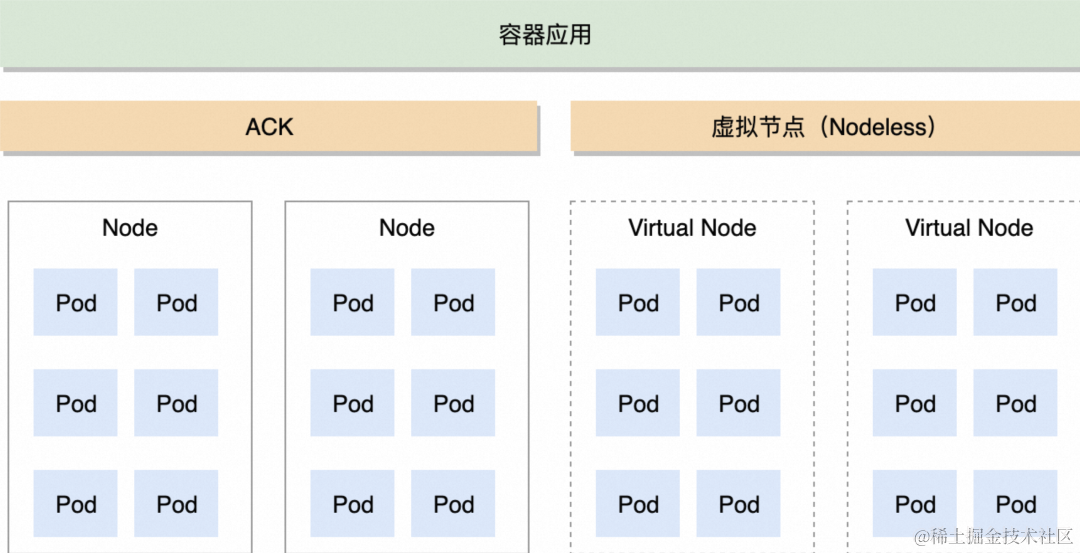
集群弹扩架构
容器应用运行在在我们的 ACK 和虚拟节点集群上,ecs 和弹性节点混合使用,平时业务由包年包月的 ecs 节点承载,弹性业务由按量付费的弹性节点承载,能够低成本实现高弹性。基于虚拟节点的弹性能力,即满足了弹性要求,又避免了资源浪费,降低使用成本。
- ACK?维护固定节点资源池根据常驻 Pod 和常规业务量储备 Node,包年包月成本更低
- 虚拟节点运行着弹性实例,提供弹性能力,因为无需关心节点,可以随用随弹扩弹性能力轻松应对突发流量和波峰波谷
- 对于 Job 和离线任务实时性要求不高的业务,因为有周期性,所以不会一直占用资源,成本优势高
- 免运维:弹性节点,Pod 用完即销毁
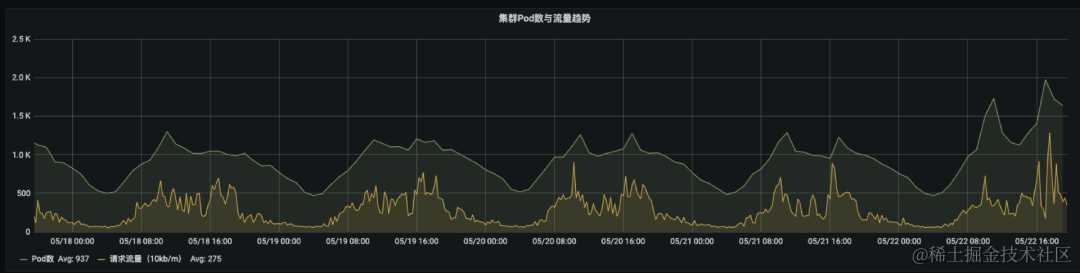
成果收益
通过 Knative 的弹性能力最大化提升了资源使用率,从资源和流量请求的曲线可以看出,我们的资源有波峰波谷,有明显的周期性,请求上升时 Pod 使用量上升,请求下降时 Pod 使用量下降。集群的峰值 Pod 个数接近 2000,成本较过去降低约 60%,资源节约十分可观。
得益于 Knative 的多版本发布能力,发布效率也得到了提升,从过去的小时级提升到了现在的分钟级。数禾的 Knative 模型实践也得到了权威的认证,被信通院云原生产业联盟评选为【云原生应用优秀案例】。

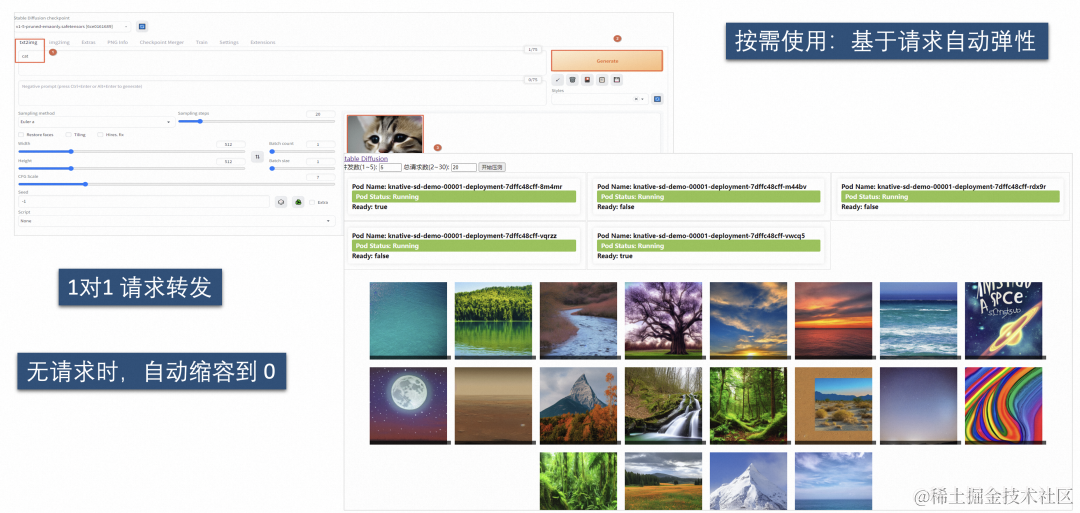
Knative 与 AIGC
作为 AIGC 领域的知名项目 Stable Diffusion,可以帮助用户快速、准确地生成想要的场景及图片。不过当前直接在 K8s 使用 Stable Diffusion 面临如下问题:
- 单个 Pod 处理请求的吞吐率有限,如果多个请求转发到同一个 Pod,会导致服务端过载异常,因此需要精准的控制单个 Pod 请求并发处理数。
- GPU 资源很珍贵,期望做到按需使用资源,在业务低谷及时释放 GPU 资源。
基于上面两个问题,我们通过 Knative 可以做到基于并发精准弹性,资源不用时,缩容到 0。
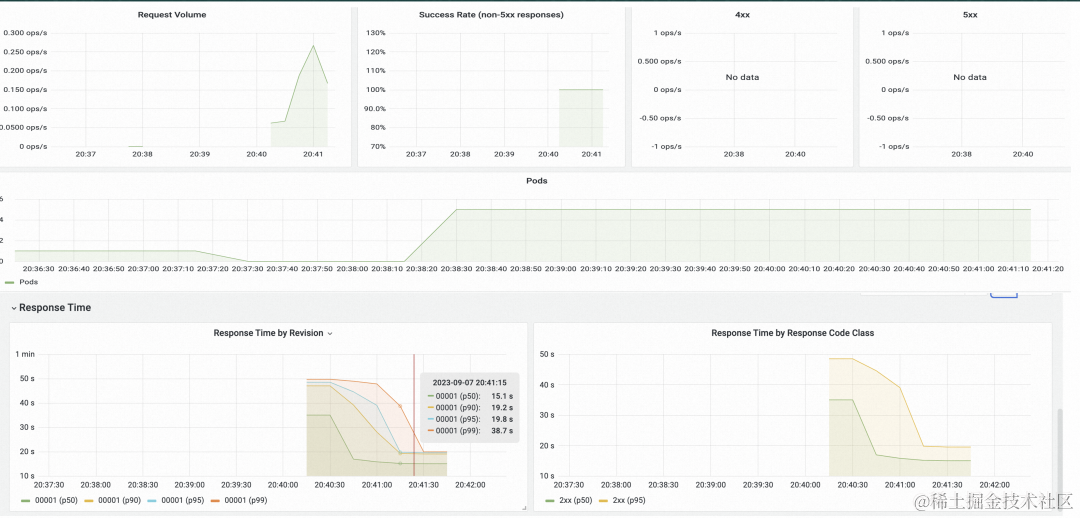
此外 Knative 提供了开箱即用的可观测大盘,可以查看请求数、请求成功率、Pod 扩缩容趋势以及请求响应延迟等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!