Datawhale 强化学习笔记(四)结合策略梯度和价值函数的 Actor-Critic 算法
策略梯度算法的缺点
- 采样效率低。由于使用的是蒙特卡洛估计,与基于价值算法的时序差分估计相比其采样速度必然是要慢很多的,这个问题在前面相关章节中也提到过。
- 高方差。虽然跟基于价值的算法一样都会导致高方差,但是策略梯度算法通常是在估计梯度时蒙特卡洛采样引起的高方差,这样的方差甚至比基于价值的算法还要高。
- 收敛性差。容易陷入局部最优,策略梯度方法并不保证全局最优解,因为它们可能会陷入局部最优点。策略空间可能非常复杂,存在多个局部最优点,因此算法可能会在局部最优点附近停滞。
- 难以处理高维离散动作空间:对于离散动作空间,采样的效率可能会受到限制,因为对每个动作的采样都需要计算一次策略。当动作空间非常大时,这可能会导致计算成本的急剧增加。
结合了策略梯度和值函数的 Actor-Critic 算法则能同时兼顾两者的优点,并且甚至能缓解两种方法都很难解决的高方差问题。
基于价值的(或称评论员型,Critic), 基于策略的(或称 演员型)
高方差的来源
- 策略梯度算法是因为直接对策略参数化,相当于既要利用策略去与环境交互采样,又要利用采样去估计策略梯度
- 基于价值的算法也是需要与环境交互采样来估计值函数的,因此也会有高方差的问题。
结合之后, Actor 部分还是负责估计策略梯度和采样,但 Critic 即原来的价值函数部分就不需要采样而只负责估计值函数了,并且由于它估计的值函数指的是策略函数的值,相当于带来了一个更稳定的估计,来指导 Actor 的更新,反而能够缓解策略梯度估计带来的方差。当然尽管 Actor-Critic 算法能够缓解方差问题,但并不能彻底解决问题。
Q Actor-Critic 算法
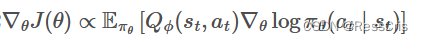
Q
?
(
s
t
,
a
t
)
Q_{\phi}(s_t, a_t)
Q??(st?,at?) 输入是状态和动作,估计当前的值。输出的是单个值。
?
\phi
? 表示 Critic 网络的参数。
Actor 策略函数 Policy
Critic 价值函数 Value Function
分别用两个模块来表示。
Actor 与环境交互采样,然后将采样的轨迹输入Critic 网络,Critic 网络估计出当前状态-动作对的价值,然后将价值作为 Actor 网络的梯度更新的依据。

优势函数,A2C, A3C
为了进一步缓解高方差问题,引入一个优势函数
A
p
i
(
s
t
,
a
t
)
A^{pi}(s_t, a_t)
Api(st?,at?), 表示当前状态-动作相对于平均水平的优势。


原先的 A2C 算法相当于只有一个全局网络并持续与环境交互更新。而 A3C 算法中增加了多个进程,每一个进程都拥有一个独立的网络和环境以供交互,并且每个进程每隔一段时间都会将自己的参数同步到全局网络中,这样就能提高训练效率。
广义优势估计(待填坑)
时序差分
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Java万花筒】云端之旅:Java容器化、微服务与云服务之道
- React Native 从类组件到函数组件
- python self用法详解
- 软件设计开发规程
- Kotlin 1.7.0 beta发布,改进构建器类型推断
- 清华大模型Chatglm2-6B的微调方法和微调模型使用方式(非常仔细,值得借鉴)
- [手机数据恢复排行榜] 8款删除照片恢复应用程序
- 微信小程序 分享按钮 监听用户分享成功
- 常用界面设计组件 —— 字符串与输入输出组件(QT)
- 华为OD机试 - 跳马(Java & JS & Python & C)