四、类文件 | 字节码 | 语法糖
一、类文件结构
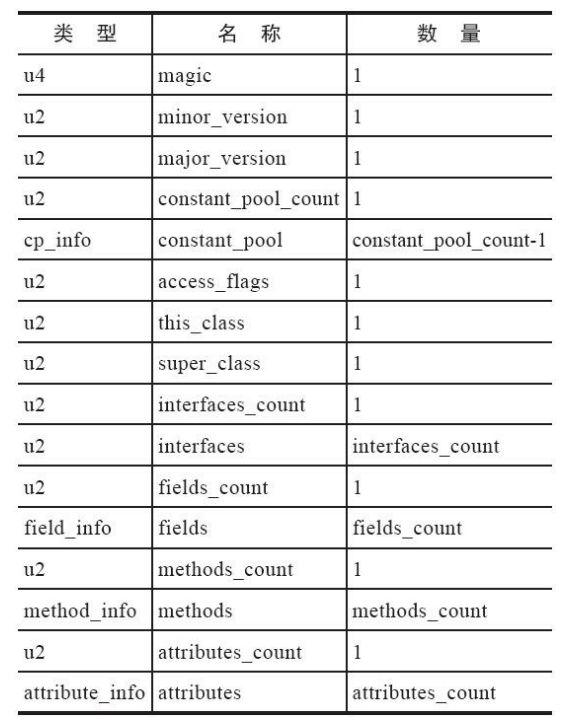
1、魔数
0-3个字节,表示它是否是【class】类型的文件
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
2、版本
4-7 字节, 表示类的版本 00 34 (52) 表示 Java8 【53表示Java9】 34是16进制转成十进制是52
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
3、常量池
8-9字节,表示常量池长度,00 23(35)表示常量池有#1 ~ #34项,注意#0项不计入,也没有值
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
举例:
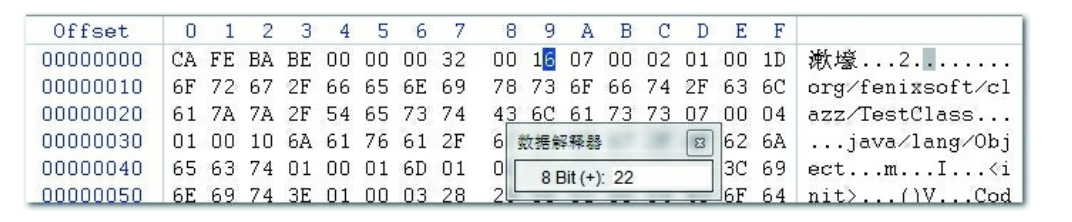
常量池入口固定需要放置一项u2类型的数据表示常量池项数,也就是两个字节长度,也就是0x0016表示常量池有22项,因为是16进制所以需要转换。
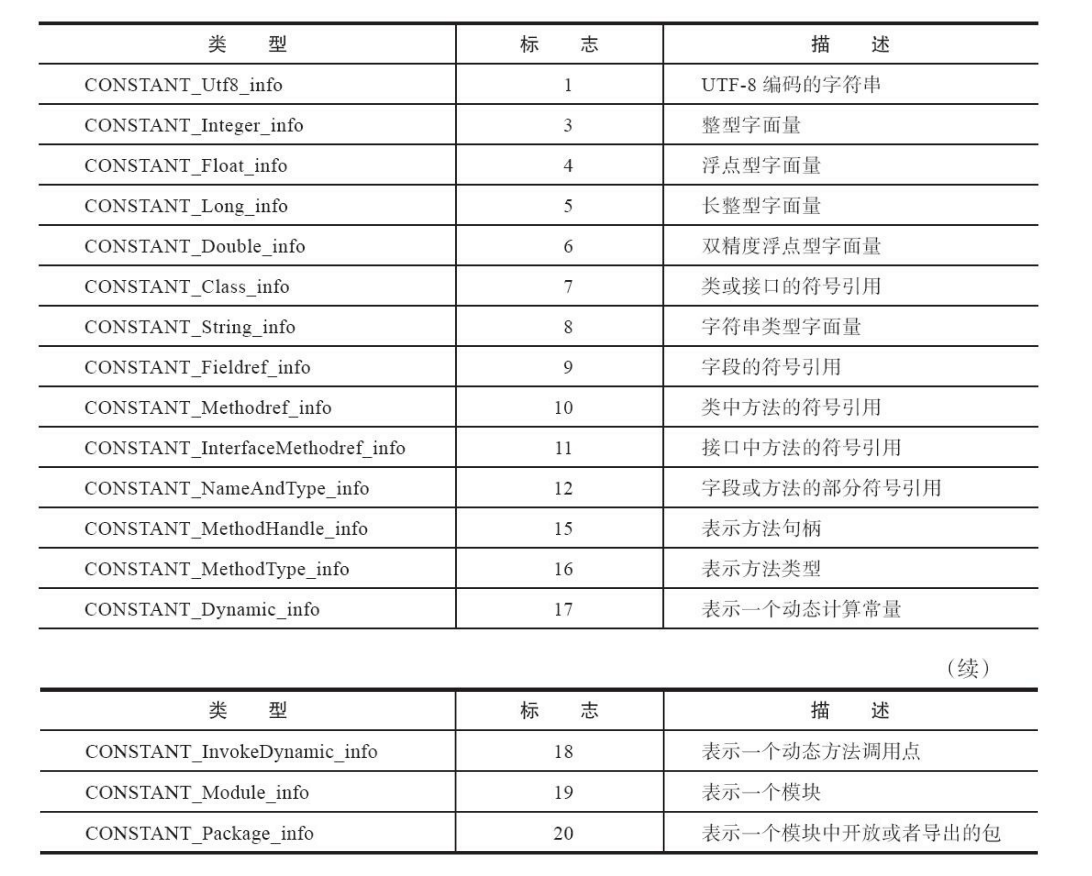
第一项开头是07,找上方的表,对应是
![]()
所以找到Class_info的常量的结构

tag占u1也就是一个字节,也就是刚才的07
name_index是常量池的索引值,它指向常量池中一个 CONSTANT_Utf8_info类型常量,此常量代表了这个类(或者接口)的全限定名
name_index占u2也就是两个字节,所以后面两位字节表示的是需要找的项数也就是找第二项(0x02)
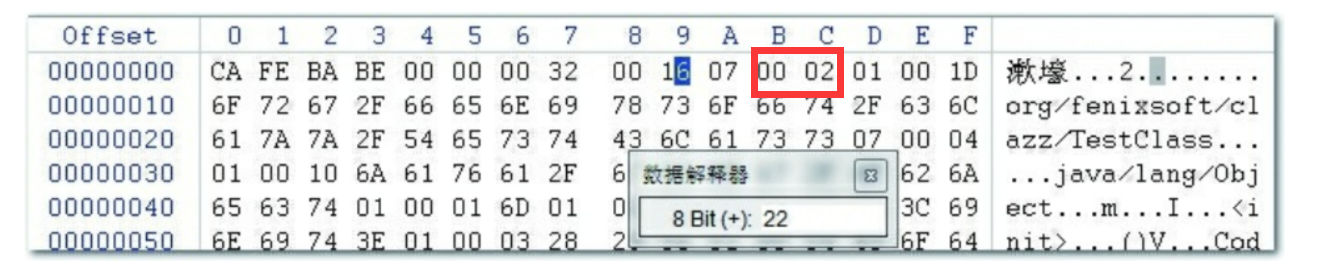
第二项开头是01,找上方的表,对应是
![]()
所以找到Utf8常量的结构

tag占u1也就是一个字节,也就是刚才的01
length占u2也就是两个字节,也就是接下来的两个字节00 1D转成十进制29
最后bytes占u1也就是一个字节,但是有length个,所以接下来的29个字节都是表示我们要找的东西。【org/fenixsoft/clazz/TestClass】

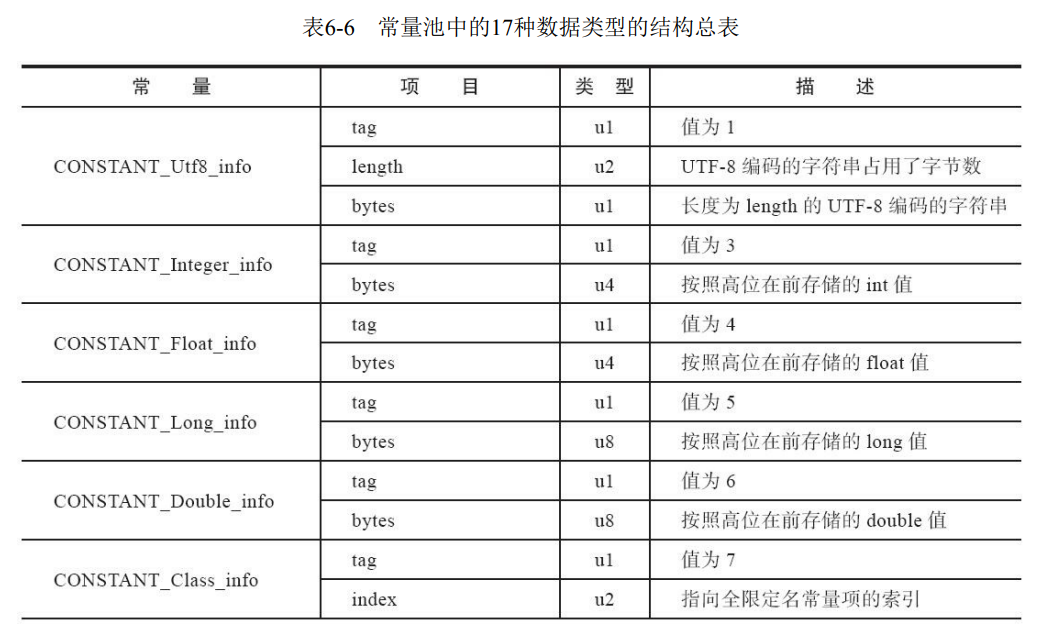
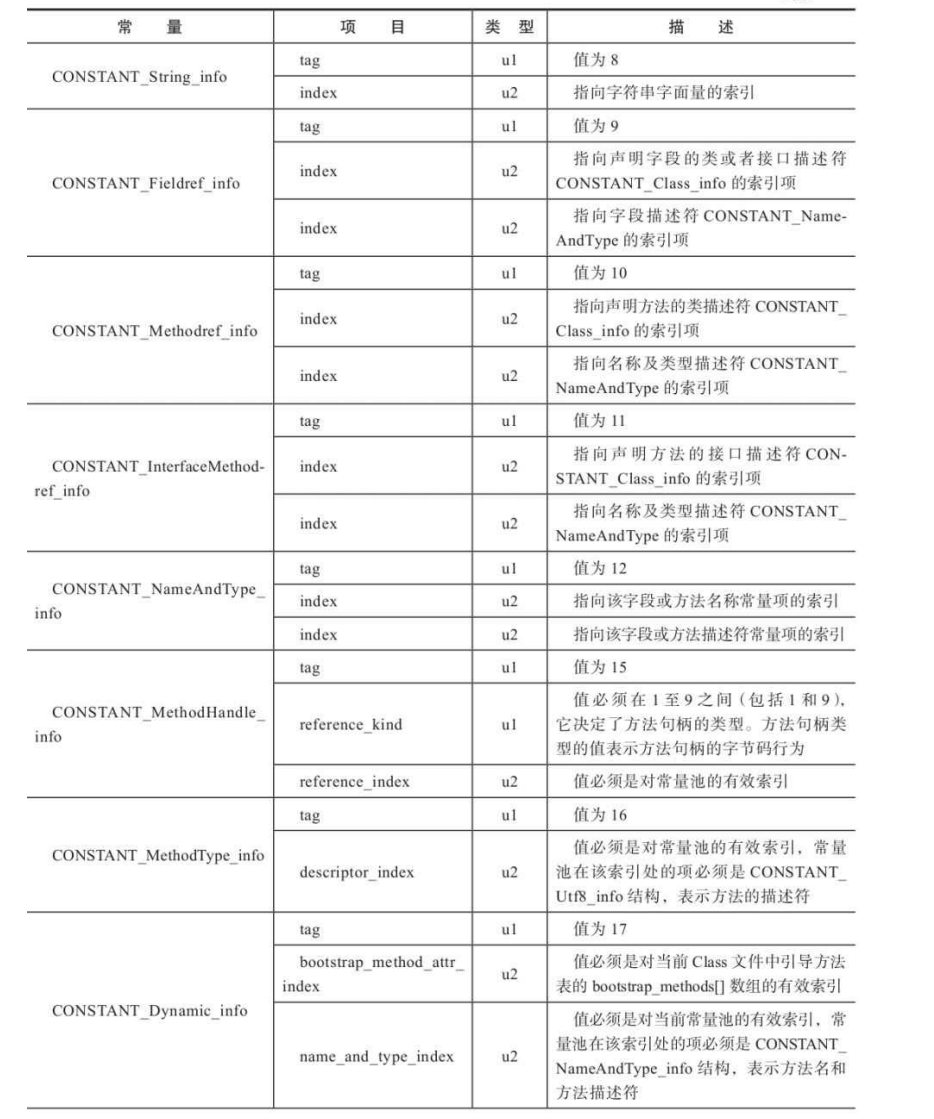
常量池结构总表

4、访问标识
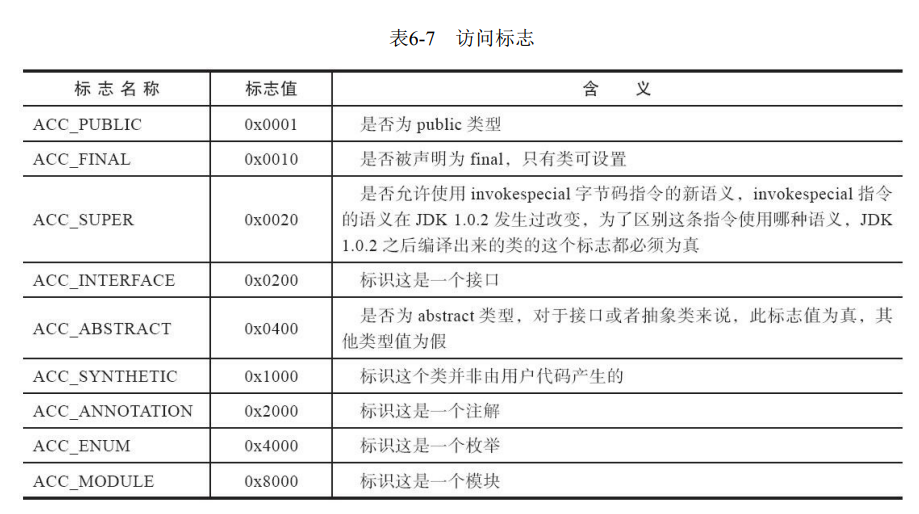

00 21 需要使用标志位0x0001 | 0x0020 也就是一个public类型 ...不是一个接口
查表得知
5、 类索引、父类索引与接口索引集合

对于接口索引集合,入口的第一项u2类型的数据为接口计数器(interfaces_count),表示索引表 的容量。如果该类没有实现任何接口,则该计数器值为0,后面接口的索引表不再占用任何字节。
从偏移地址0x000000F1开始的3个u2类型的值分别为0x0001、0x0003、0x0000,也就是类索引为 1,父类索引为3,接口索引集合大小为0。
6、成员变量
字段表(field_info)用于描述接口或者类中声明的变量。Java语言中的“字段”(Field)包括类级变 量以及实例级变量,但不包括在方法内部声明的局部变量。

描述符的作用是用来描述字段 的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类 型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大 写字符来表示,而对象类型则用字符L加对象的全限定名来表示,

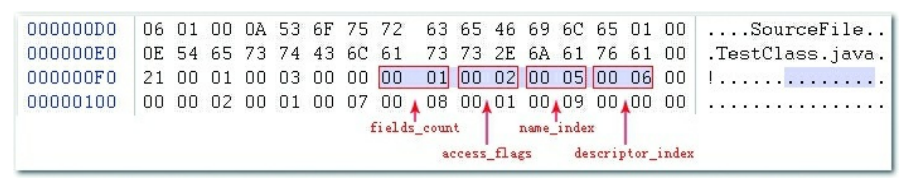
字段表集合从地址0x000000F8开始,第一个u2 类型的数据为容量计数器fields_count,如图6-8所示,其值为0x0001,说明这个类只有一个字段表数 据。接下来紧跟着容量计数器的是access_flags标志,值为0x0002,代表private修饰符的ACC_PRIVATE 标志位为真(ACC_PRIVATE标志的值为0x0002),其他修饰符为假。代表字段名称的name_index的值 为0x0005,从代码清单6-2列出的常量表中可查得第五项常量是一个CONSTANT_Utf8_info类型的字符 串,其值为“m”,代表字段描述符的descriptor_index的值为0x0006,指向常量池的字符串“I”。根据这些 信息,我们可以推断出原代码定义的字段为“private int m;”。
7、方法表集合
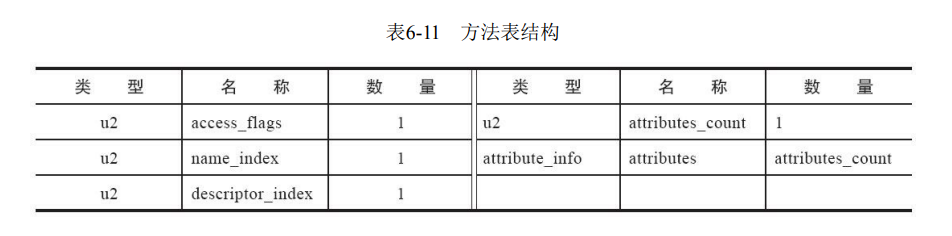
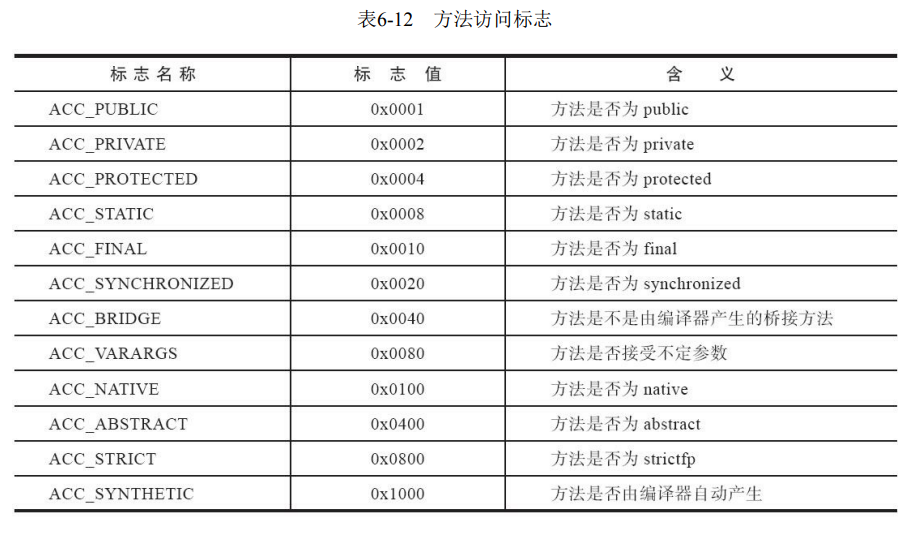
方法的定义可以通过访问标志、名称索引、描述符索引来 表达清楚,但方法里面的代码去哪里了?方法里的Java代码,经过Javac编译器编译成字节码指令之 后,存放在方法属性表集合中一个名为“Code”的属性里面,可以看《深入理解Java虚拟机》这本书的6.3.7部分,后面再补充。

方法表集合的 入口地址为0x00000101,第一个u2类型的数据(即计数器容量)的值为0x0002,代表集合中有两个方 法,这两个方法为编译器添加的实例构造器和源码中定义的方法inc()。第一个方法的访问标志值 为0x0001,也就是只有ACC_PUBLIC标志为真,名称索引值为0x0007,查代码清单6-2的常量池得方法 名为“”,描述符索引值为0x0008,对应常量为“()V”,属性表计数器attributes_count的值为 0x0001,表示此方法的属性表集合有1项属性,属性名称的索引值为0x0009,对应常量为“Code”,说明 此属性是方法的字节码描述。
二、字节码指令
1、构造方法
a. cinit 每个类的构造方法
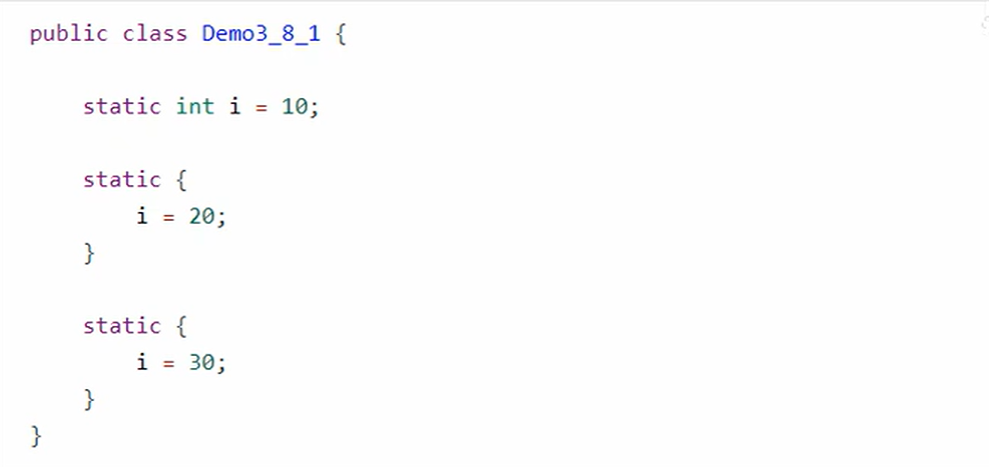
编译器会按照从上到下的顺序,收集所有静态代码块和静态成员赋值的代码,合并成为一个特殊的方法<cinit>()V:
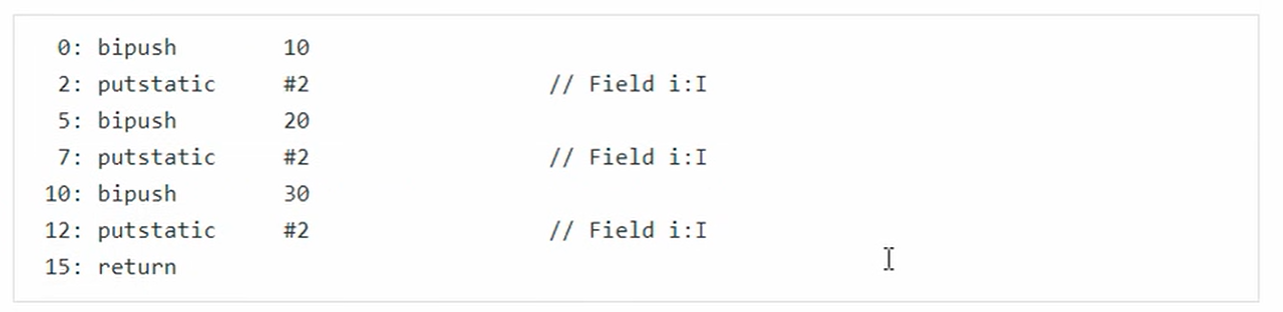
<cinit>()V 方法会在类加载的初始化阶段被调用
所以运行结果是30
b. init 每个实例的构造方法
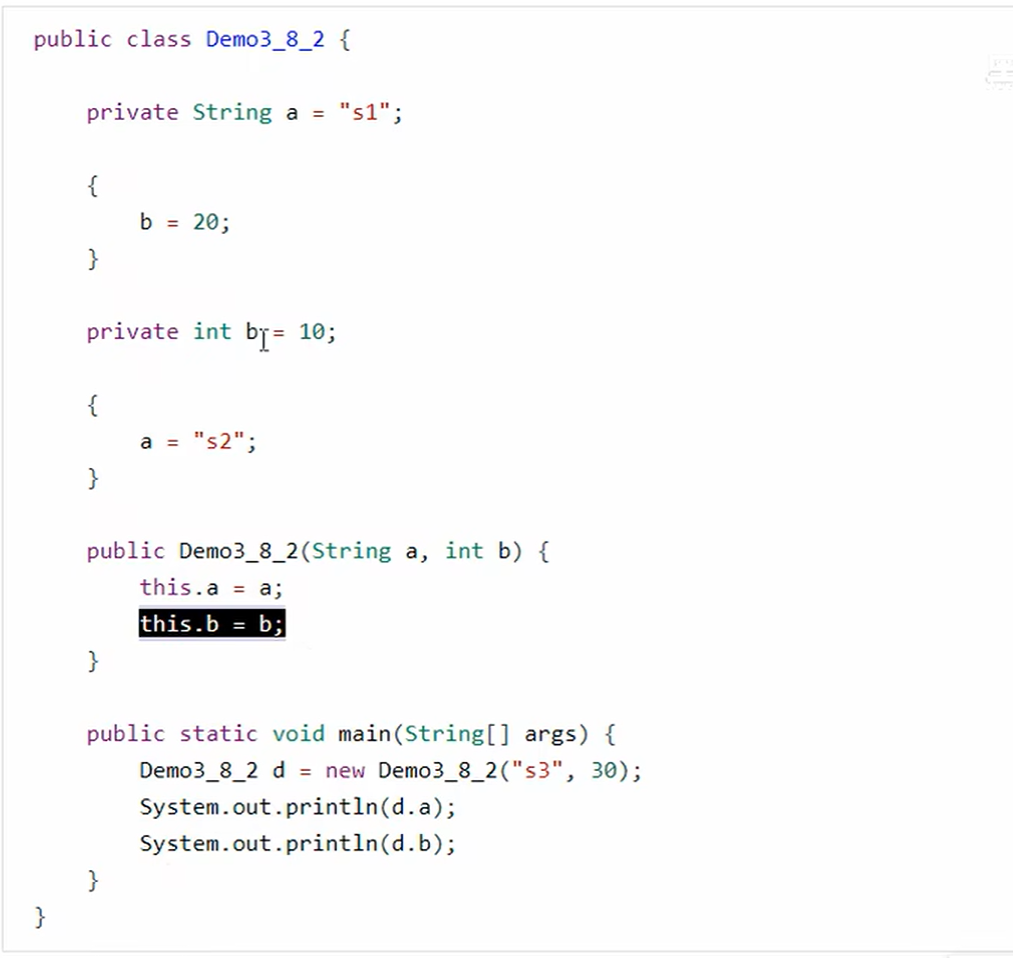
编译器会按照从上到下的顺序,将代码块{} 和 成员变量赋值的代码,组合成一个新的构成方法,但是原始构造方法会最后执行。
所以运行结果是 s3 30
2、方法调用
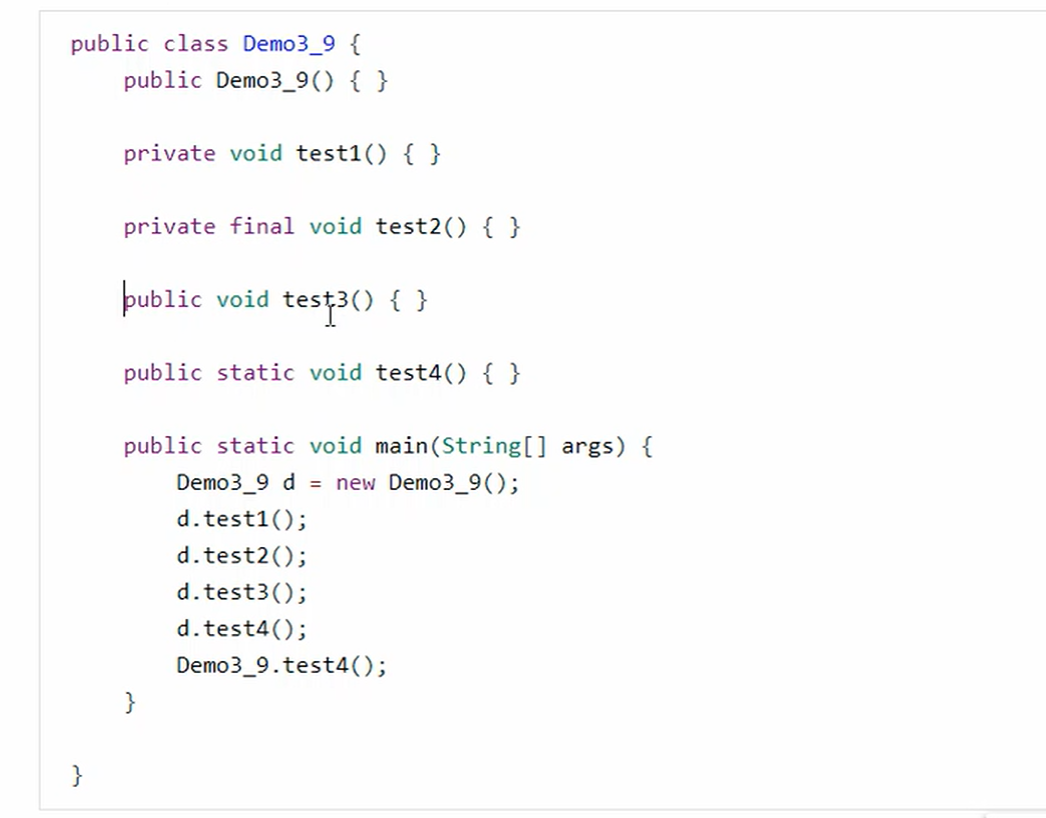
如果是静态方法的调用,如果通过对象类调用,虚拟机字节码还是会执行类名调用的方式。

invokespecial 和 invokestatic属于静态绑定,字节码生成的时候就已经知道这两类的方法,可以唯一确定的找到,当时invokevirtual也就是普通方法,有可能会被子类重写,所以无法唯一确定,需要多次查找,才能确定程序入口。
3、多态原理
当执行invokevirtual指令时,
- 先通过栈帧中的对象引用找到对象
- 分析对象头(8个字节是Class实际地址),找到对象的实际Class
- Class结构中有vtable(虚方法表),他在类加载的链接阶段就已经根据方法的重写规则生成好了
- 查表得到方法的具体地址
- 最后执行方法的字节码
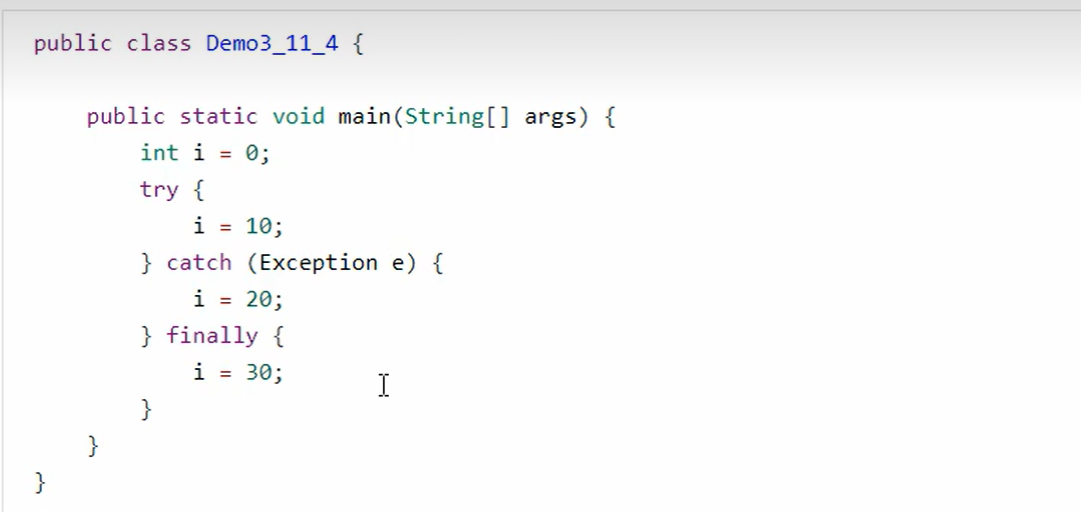
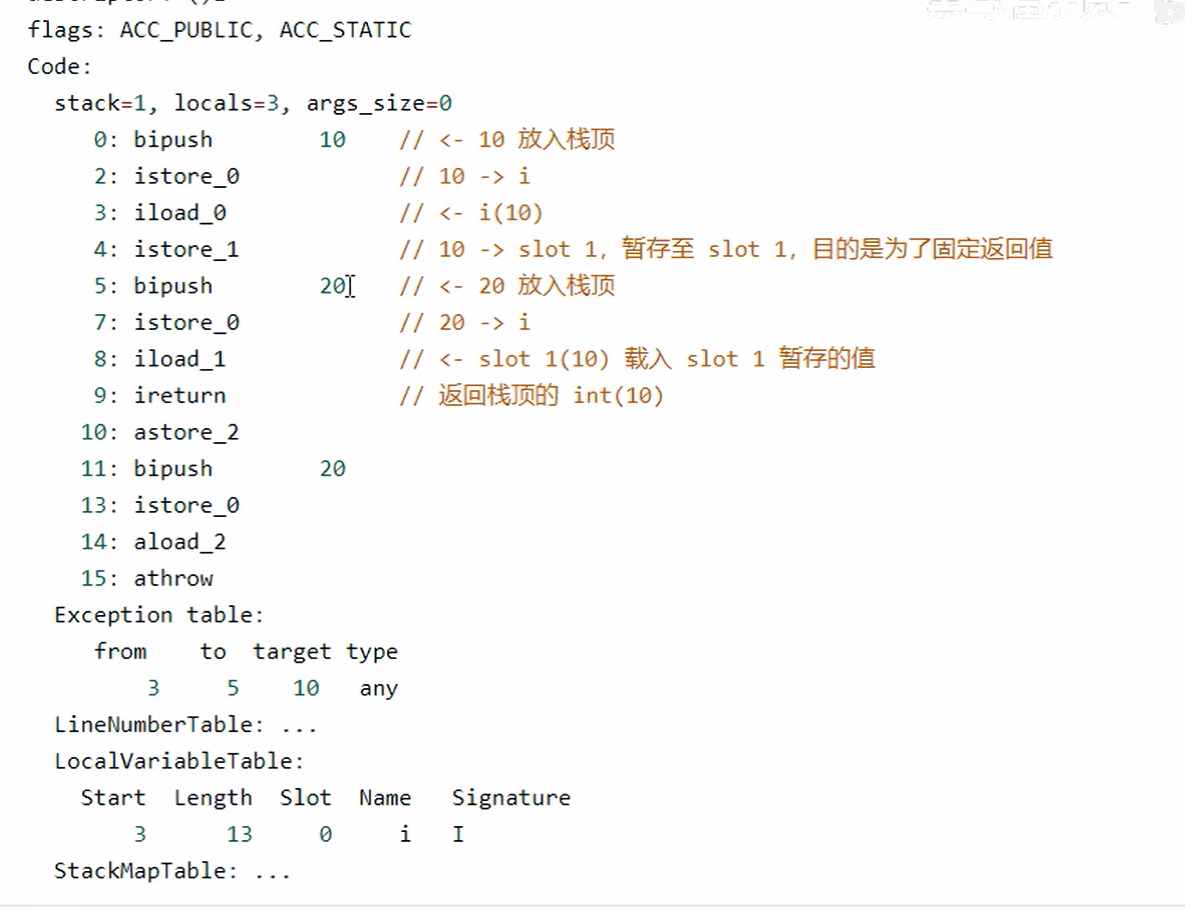
4、异常处理
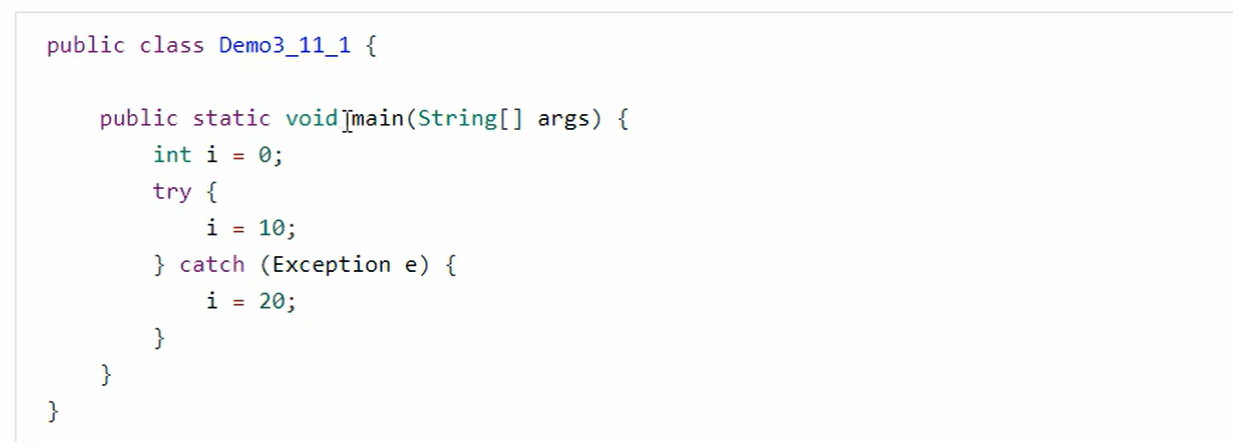
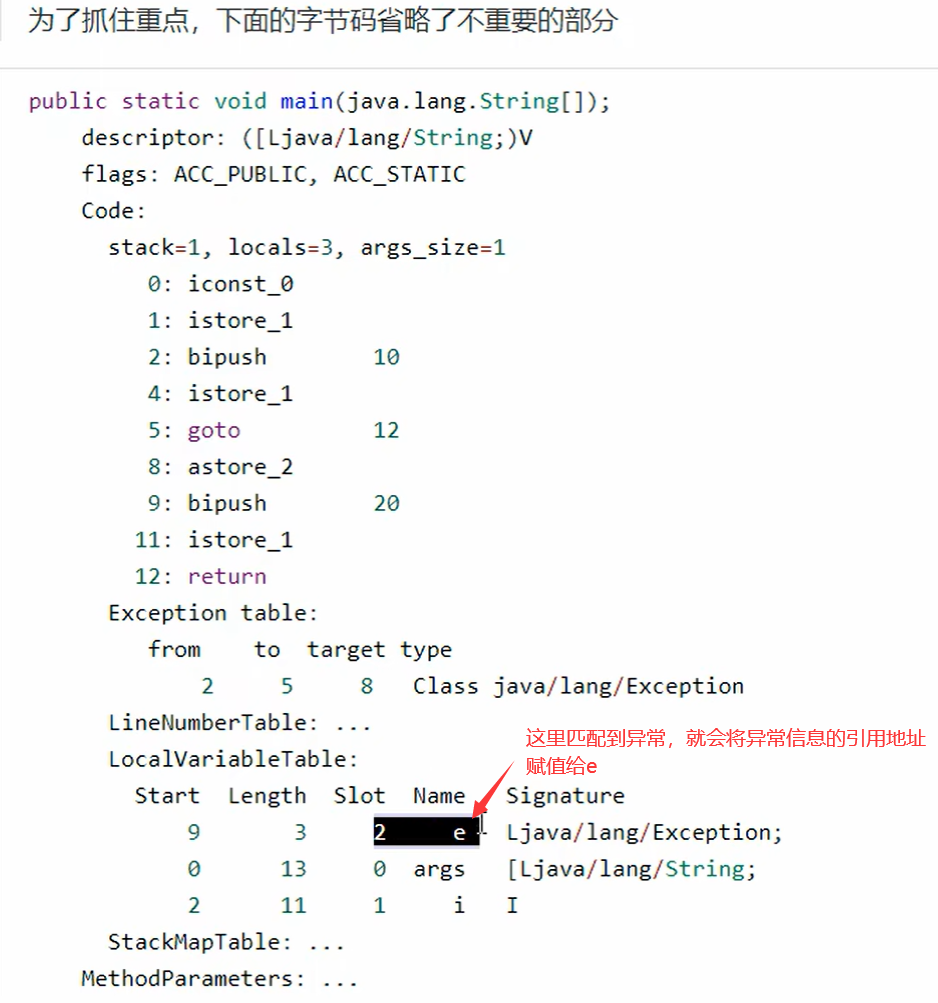
- 可以看到多出来一个Exception table 的结构,[from, to) 是前闭后开的监测范围,一旦这个范围内的字节码执行出现异常,则通过type匹配异常类型,如果一致,进入target所对应的行号
- 8行的字节码指令astore_2 是将异常对象引用存入局部变量表的slot2 位置
a. finally
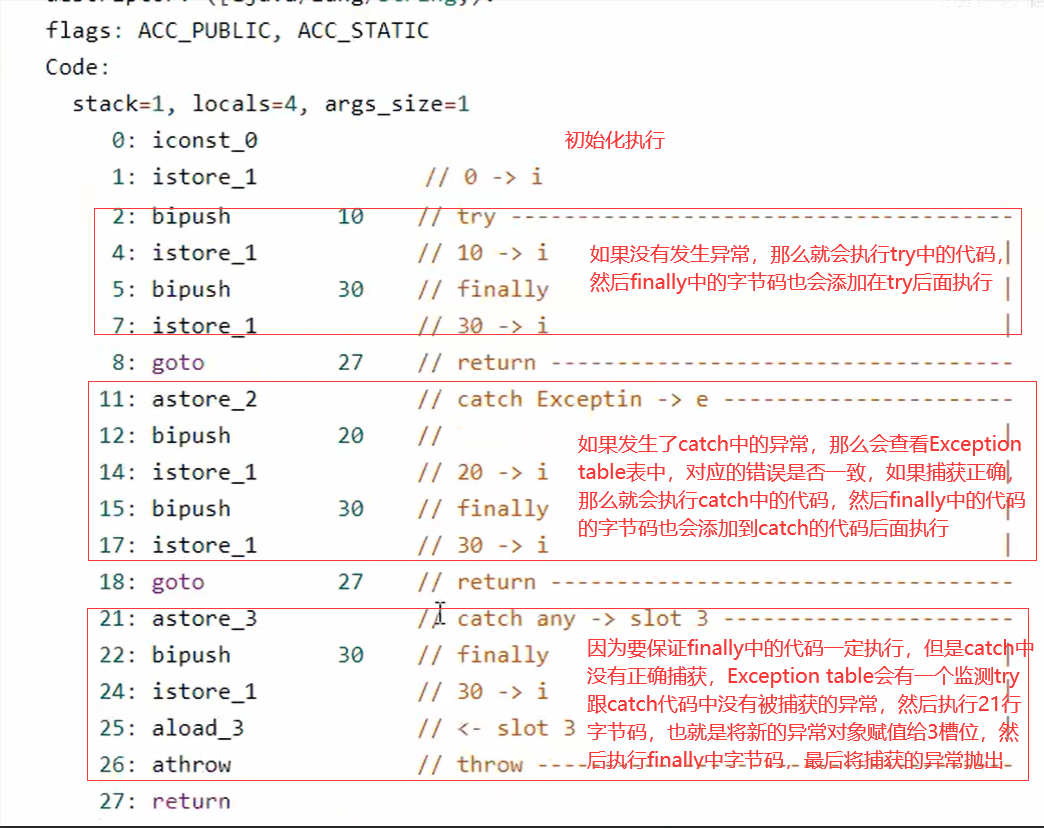

总结:
- 为什么最后需要将异常抛出,因为执行完finally中的代码之后,异常没有被catch,所以需要把异常抛出
- 最终一定会保证finally中的代码一定执行
- finally中的代码被复制了3份,分别放到了try、catch以及catch剩余的异常类型的流程
b.finally面试题
题目:
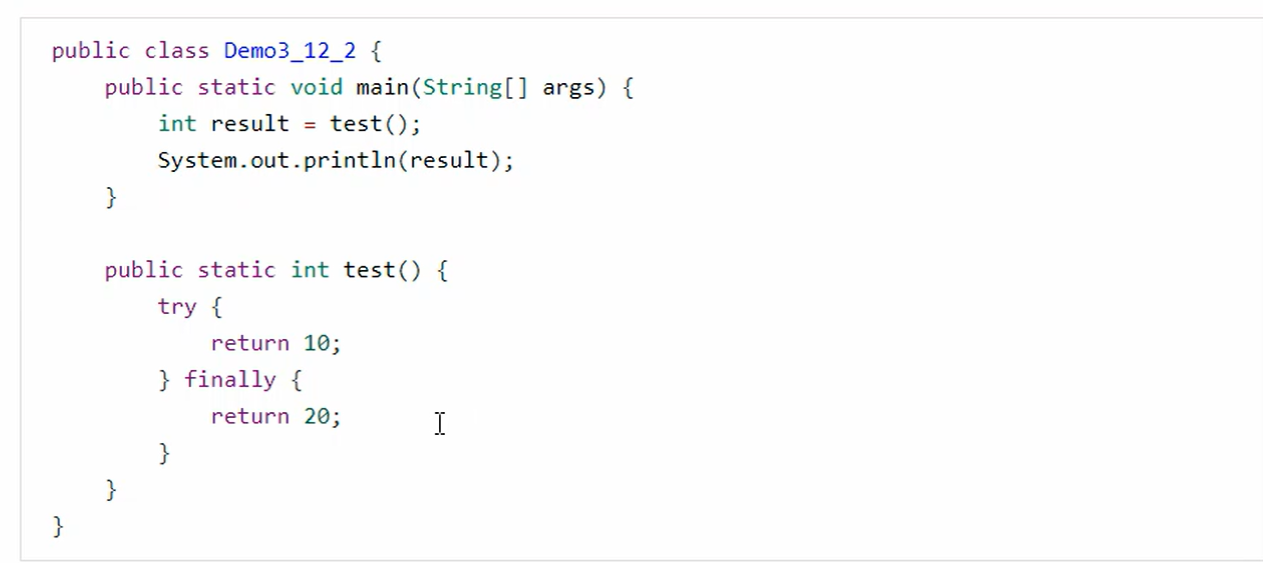
结果: 20
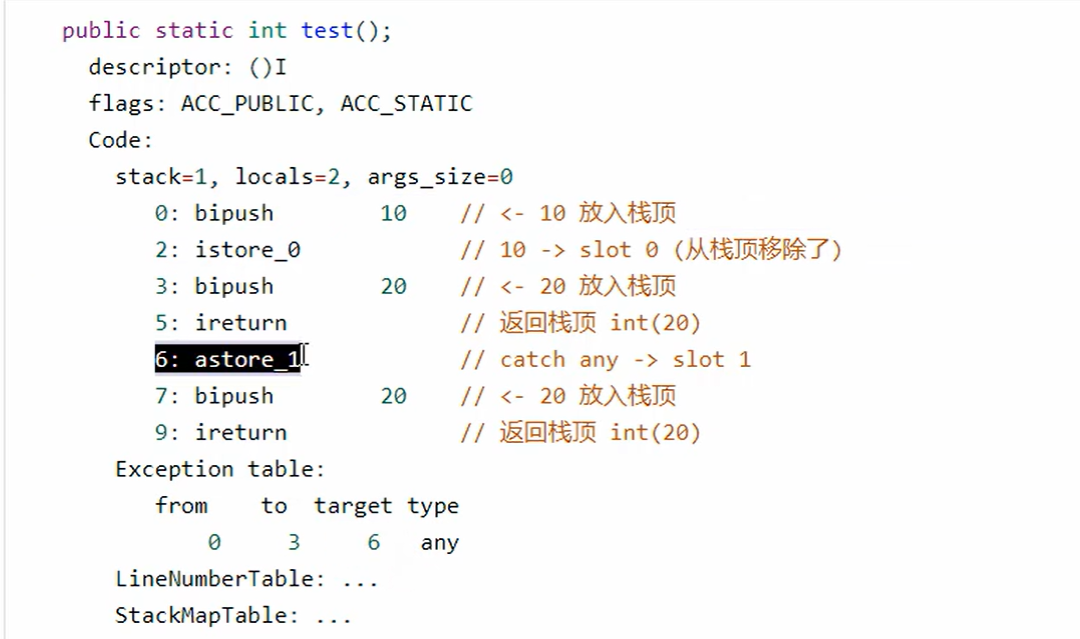
总结:
- 为什么字节码中的第2行要移除,似乎没啥用,且留个伏笔,看下一个例子
- 可以看到没有athrow抛出异常的信息,这是因为如果是finally中return了,那么最终的异常会被吃掉,不会爆异常,所以也就没有上面的athrow
- 所以编程中不要在finally添加return
题目:
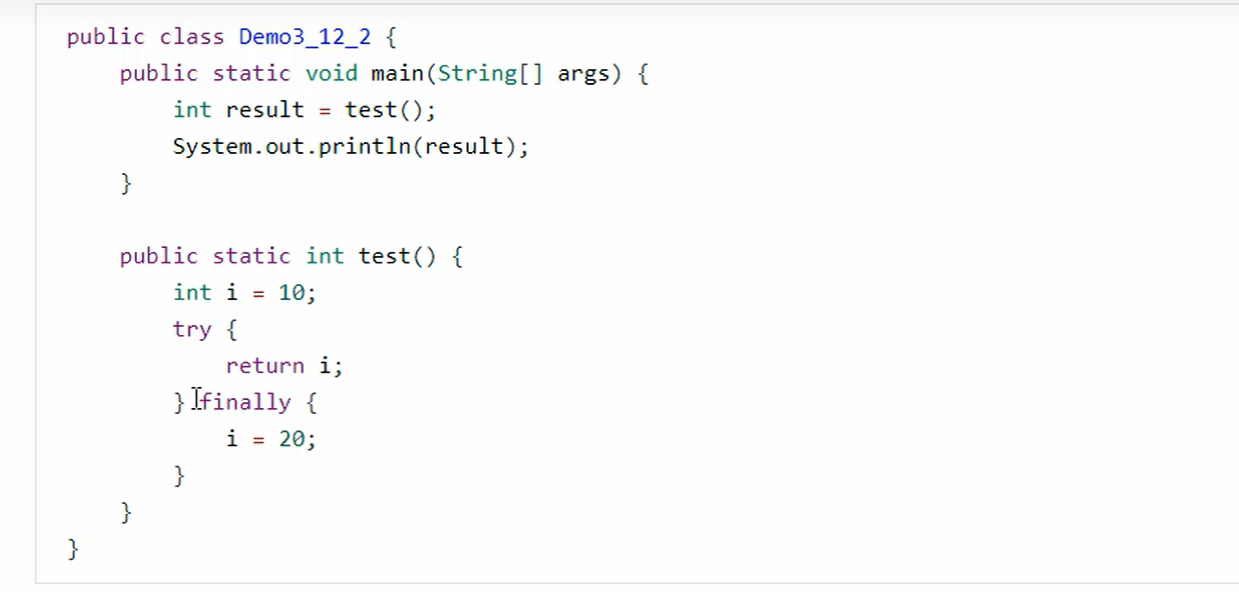
答案:10
通过这个例子可以发现
- 如果try中return 一个值,那么会将这个值弹出栈顶,暂存到一个新的不知名的槽位。
- 然后执行finally中的代码,之后会将槽位上的值重新放入栈顶,最后返回,finally中的赋值不会影响到他。
- 然后如果这时候finally中出现了return,那么try中暂存起来的值就不会回到栈顶,也就返回的是finally中的值
- athrow重新出现,因为finally中没有return
5、synchronized
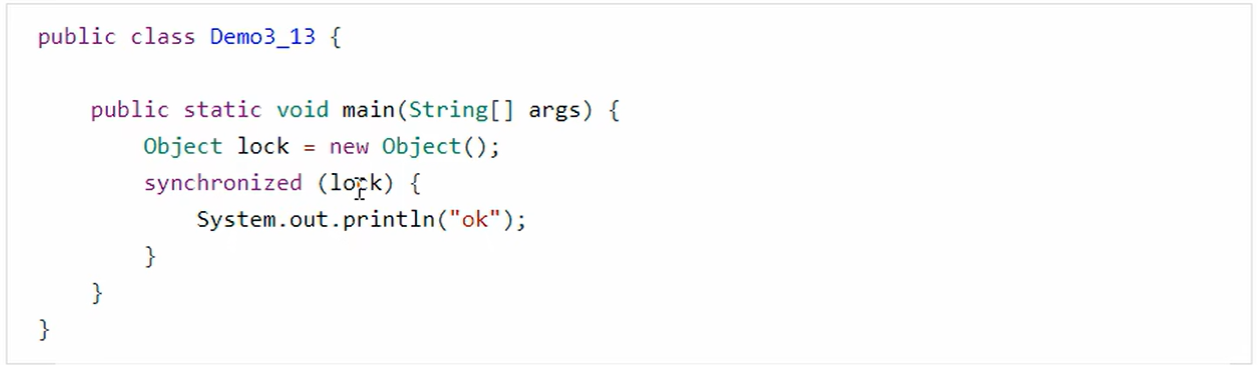
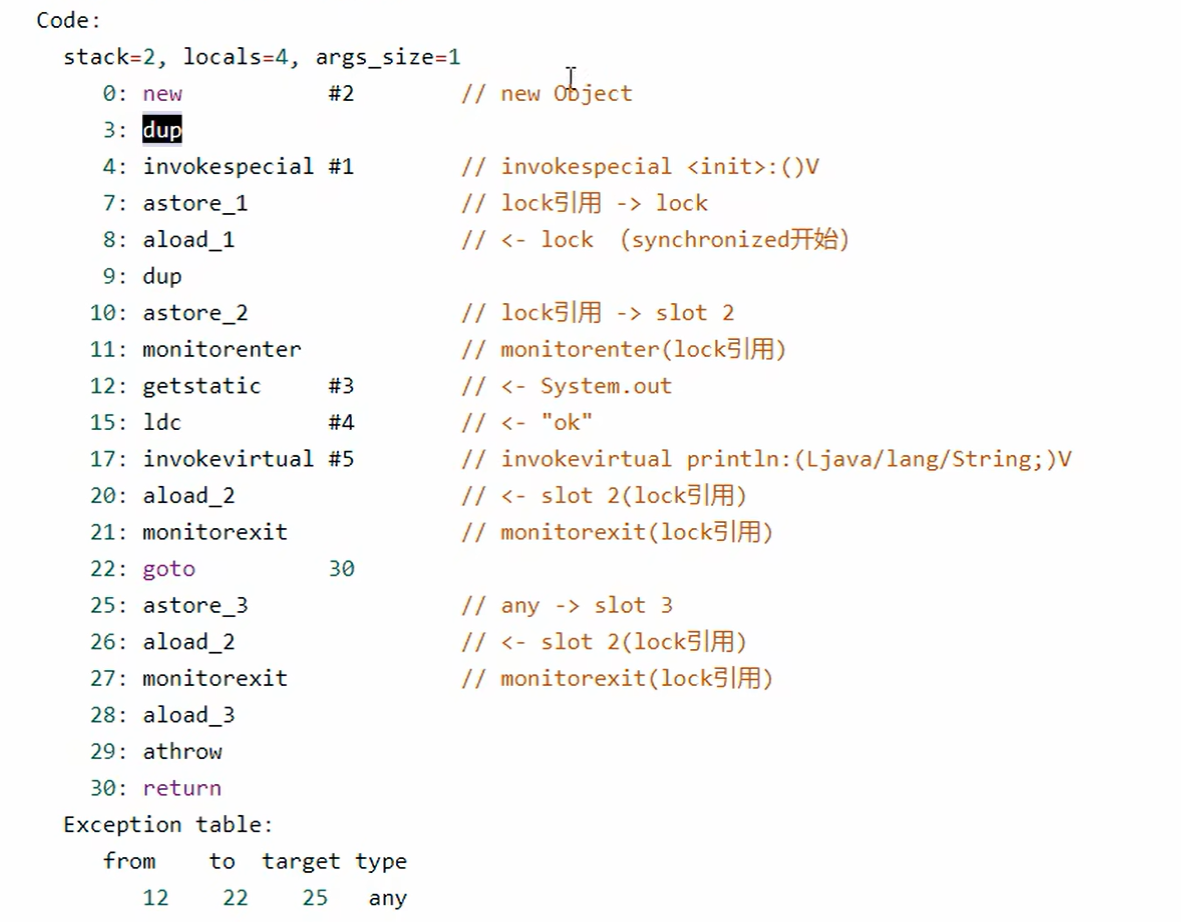

总结:
- 会复制一份锁引用对象存放在新的槽位中
- 加锁的时候使用原来的那份锁引用对象
- 释放锁的时候将复制的那份加载到栈顶,然后进行解锁操作
- 如果这期间出现了异常,那么会执行25行
- 也会将复制的那份加载到栈顶来,然后进行解锁,确保正常释放锁
三、编译器处理(语法糖)
java文件编译成class文件过程中,自动生成和转换的一些代码,减轻程序员负担。
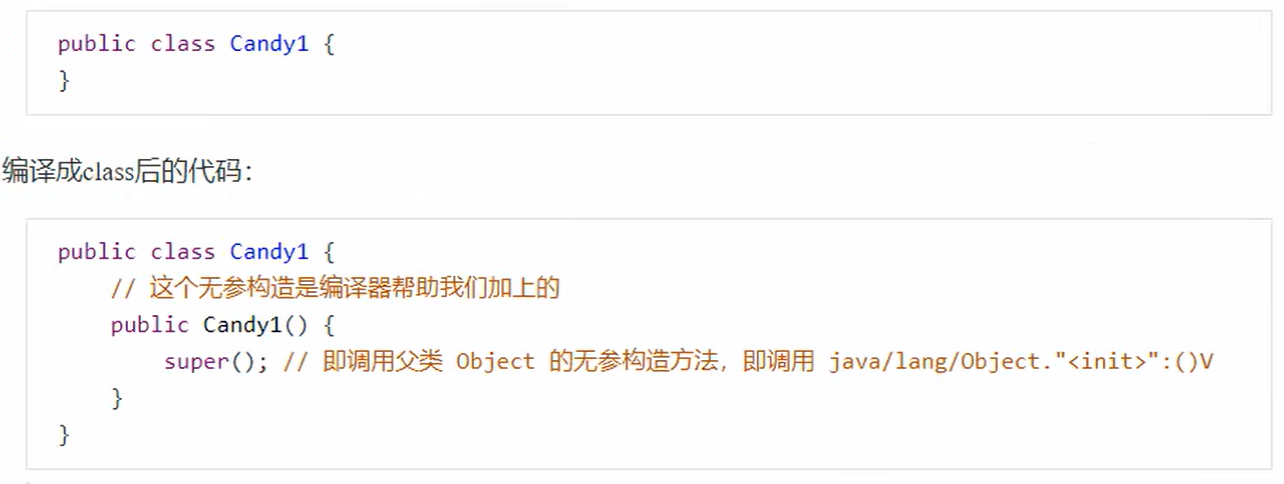
1. 默认构造器
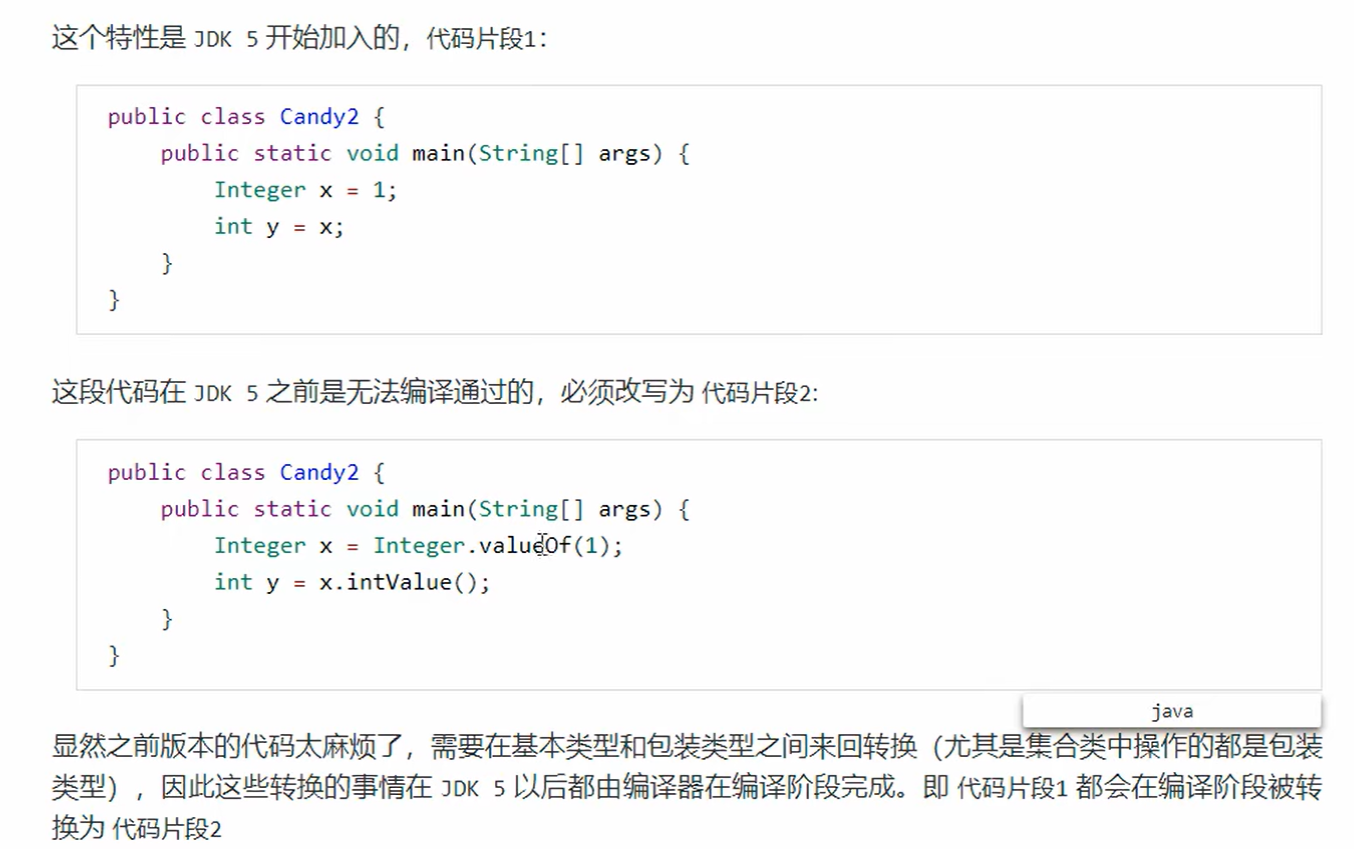
2. 自动拆装箱 98 102 114
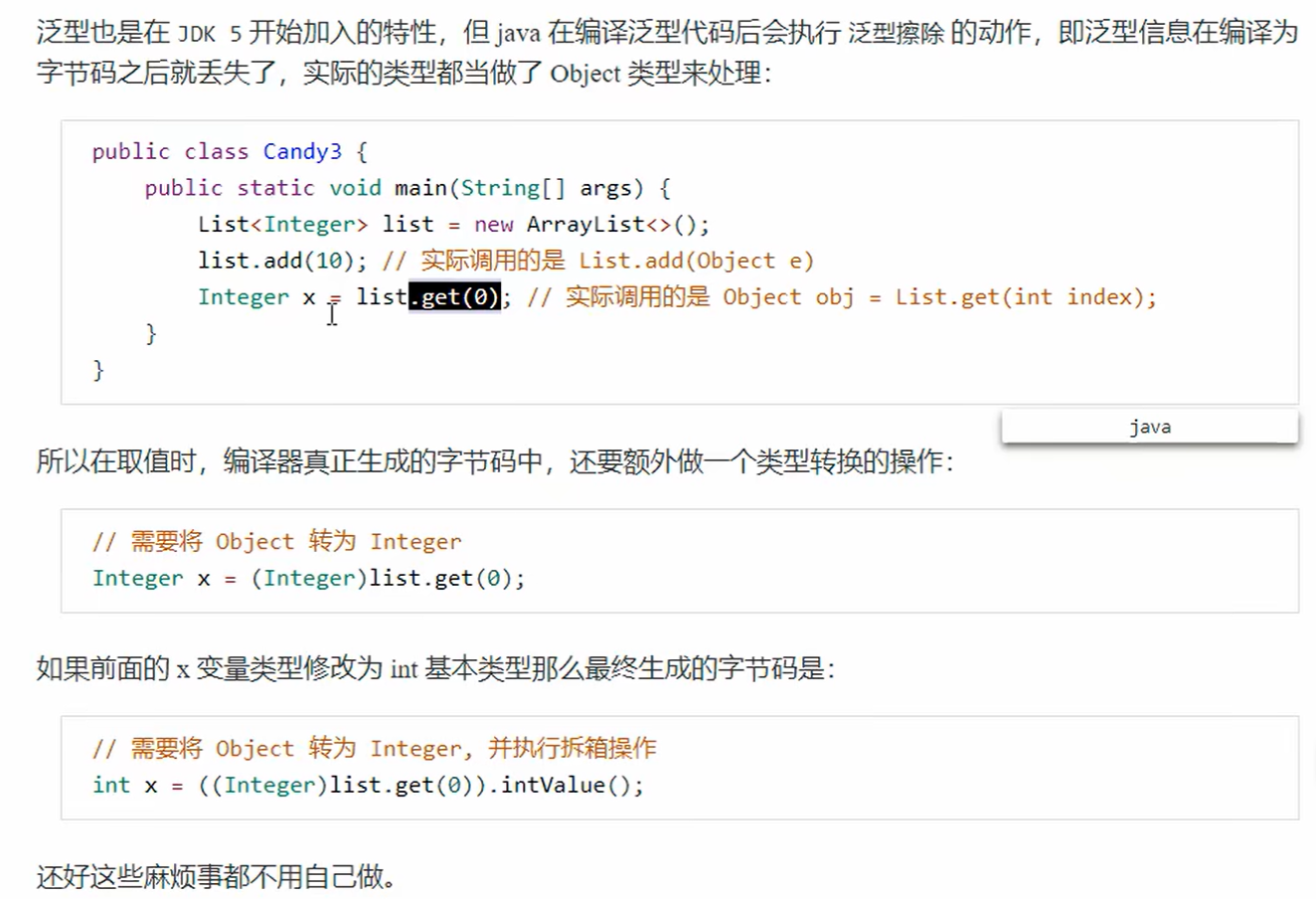
3. 泛型集合取值
a. 泛型擦除
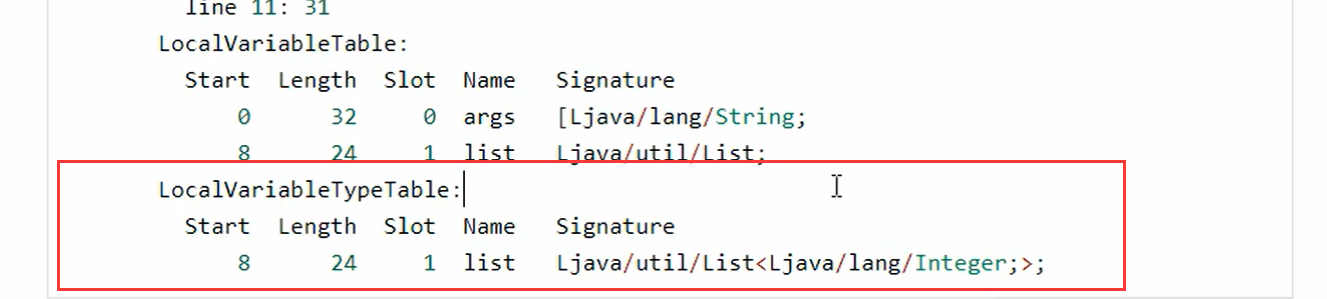
总结:
字节码中方法体里面的泛型信息就被擦除了,但是不是所有都擦除,局部变量泛型信息可以找到
b. 泛型反射
- 如果是局部变量的泛型信息 不能通过反射获取
- 方法参数、返回值的泛型信息就可以通过反射获取
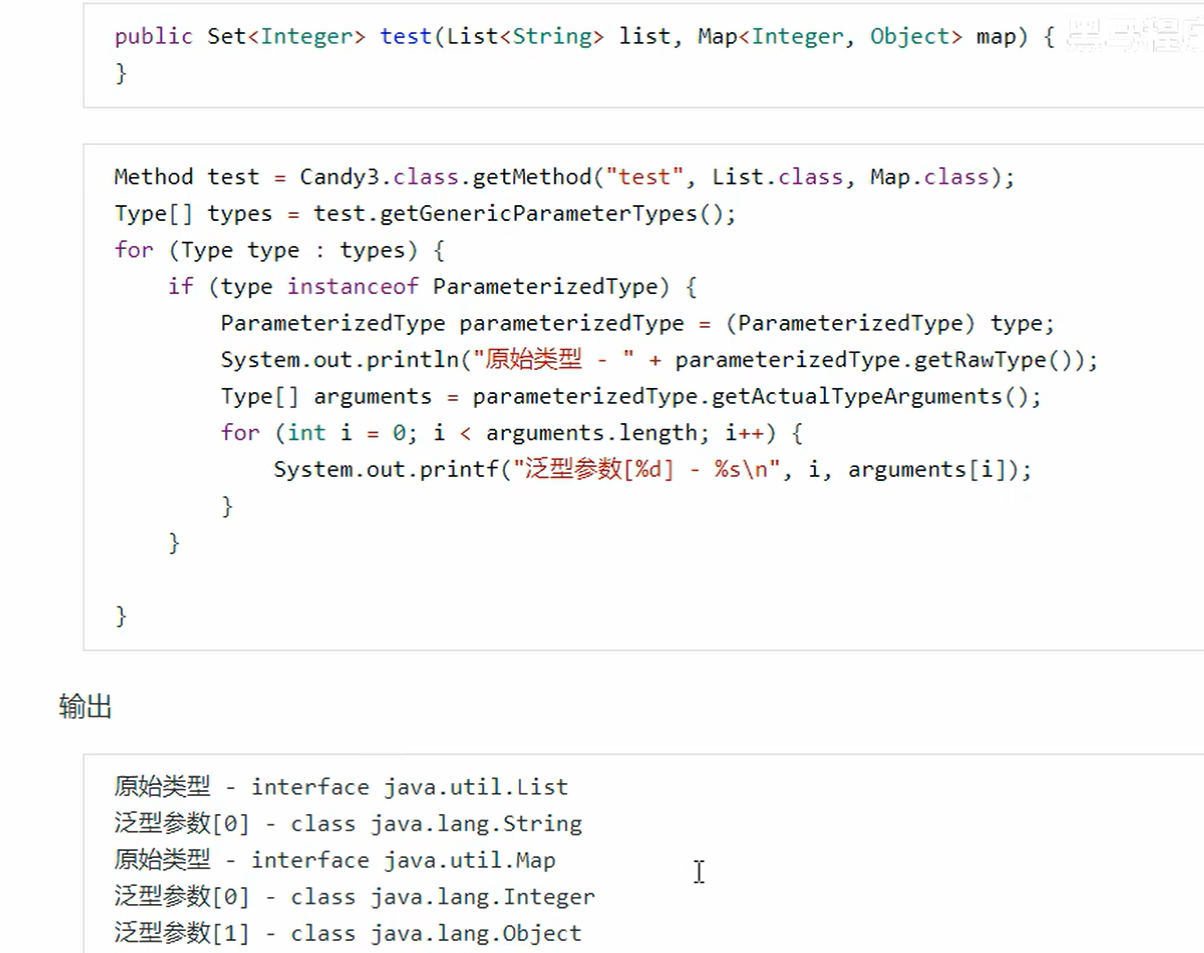
4. 可变参数
JDK5以后加入的新特性
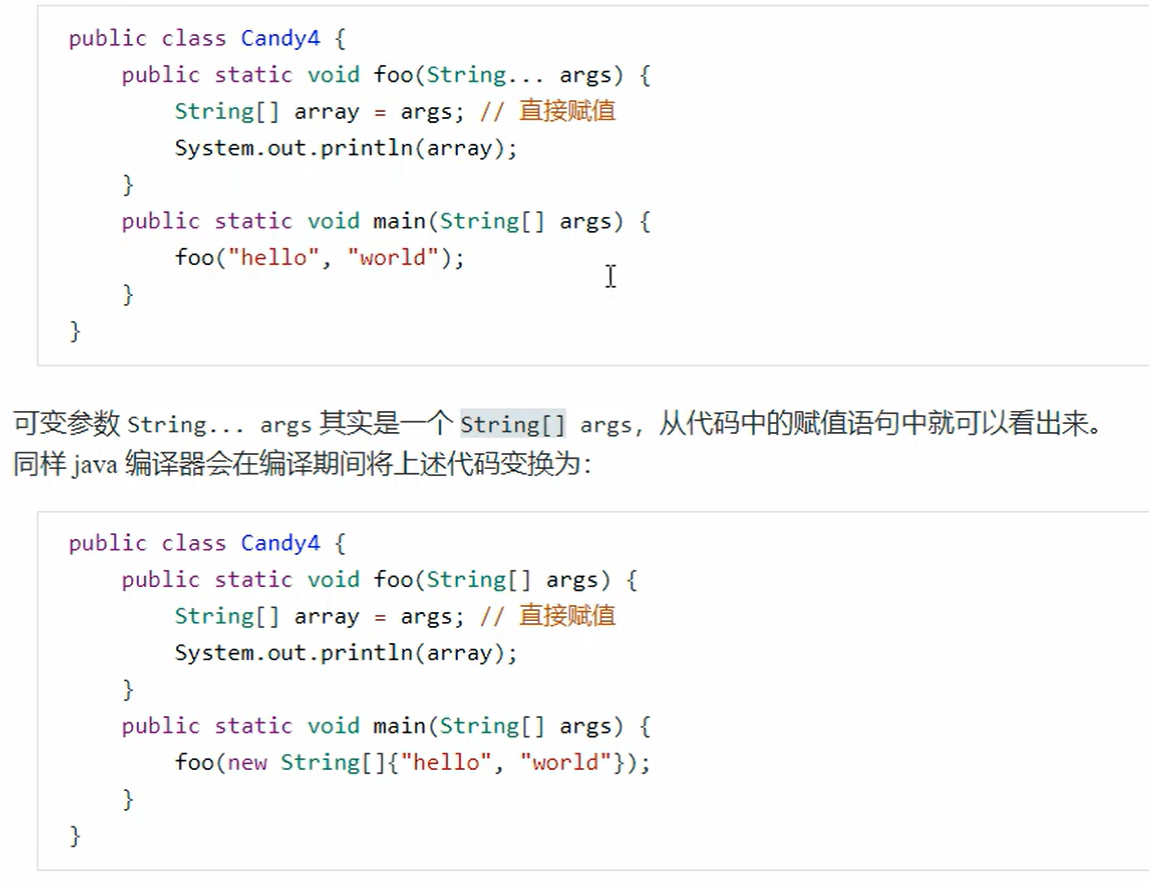
如果调用foo(),没有传入值,会创建一个空的数组,而不会传递null进去
5. foreach循环
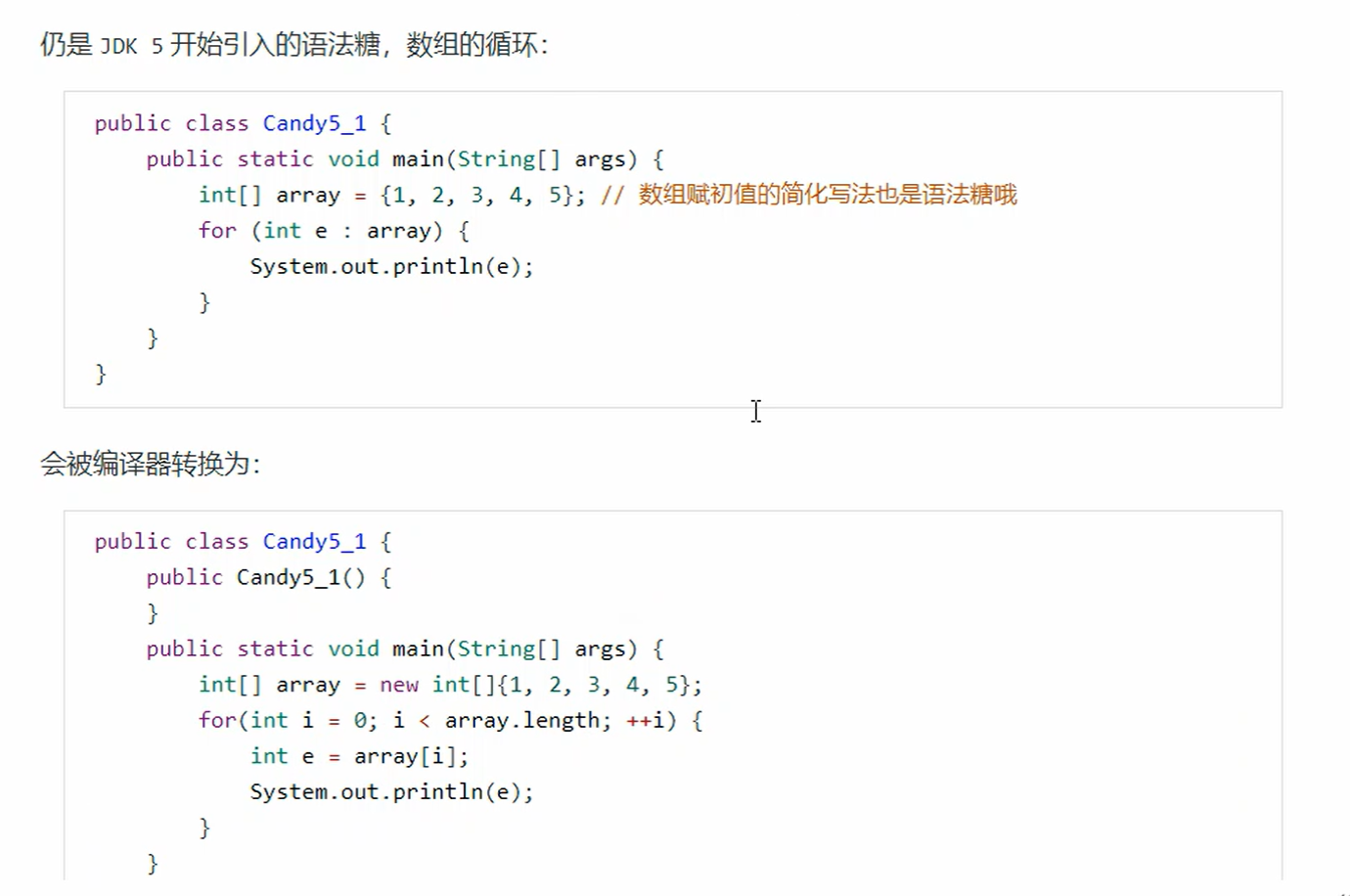

注意
- foreach循环,能够实现对数组,以及所有实现了Iterable接口的集合类一起使用
- 其中Iterable用来获取集合的迭代器(Iterator)
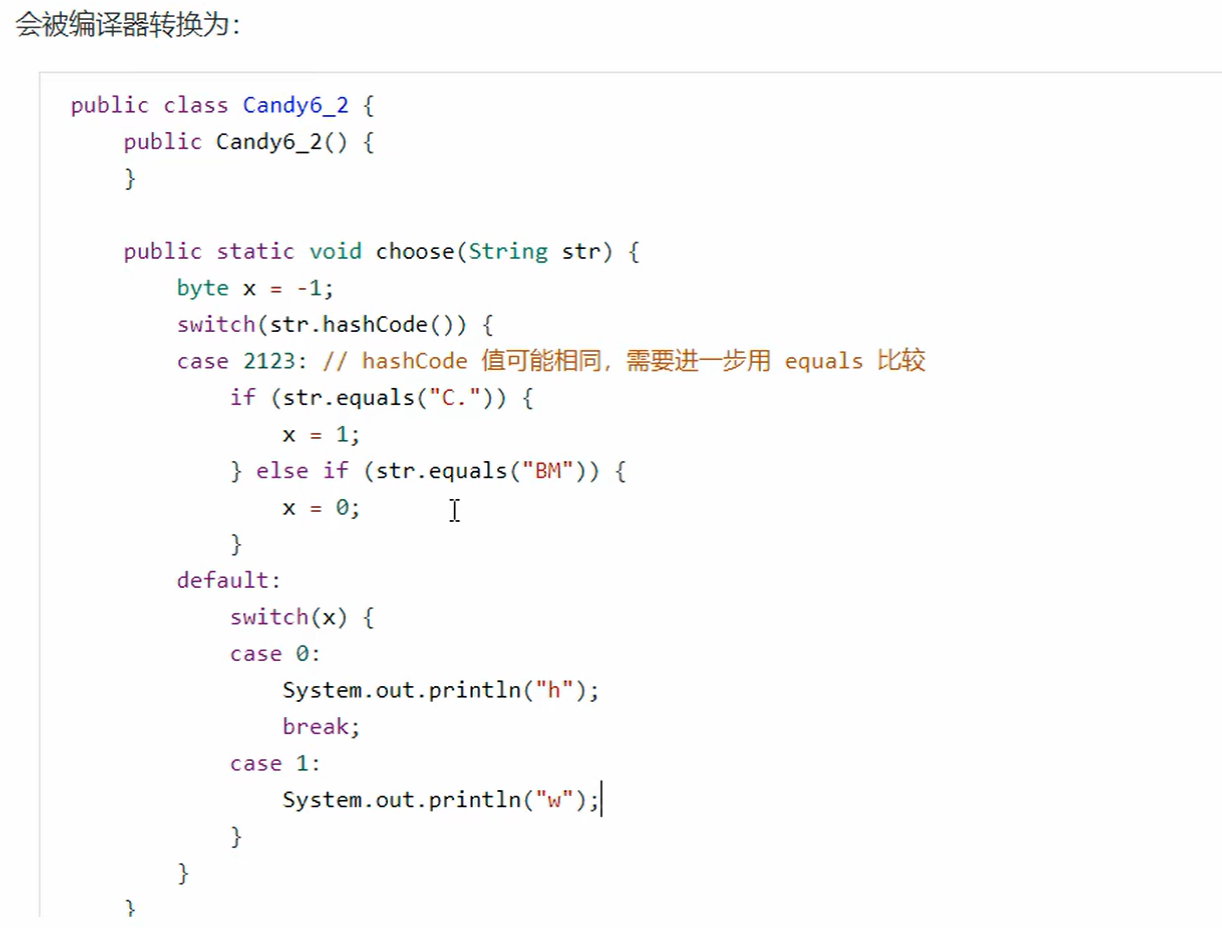
6. switch 字符串

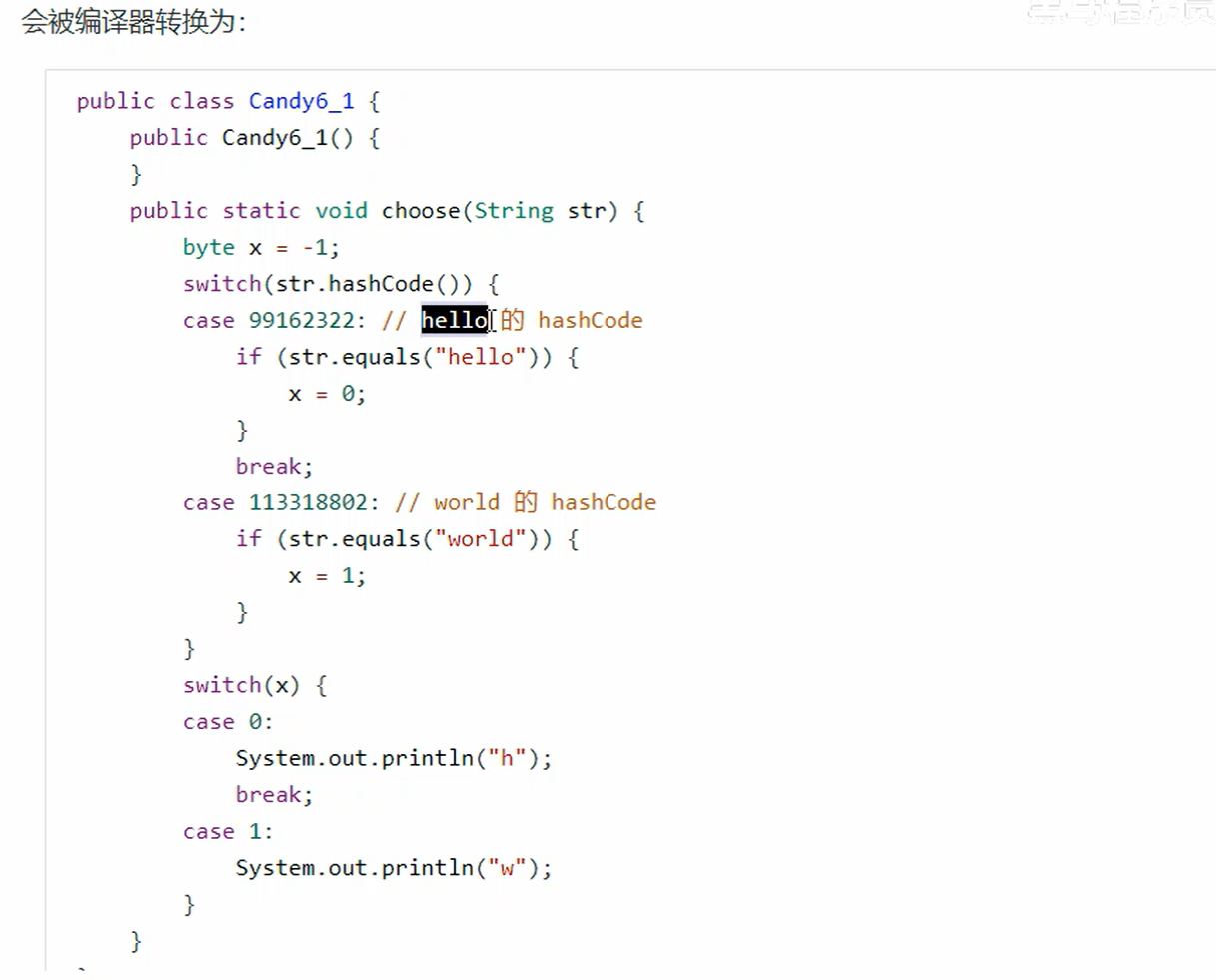
总结:
1、为什么需要比较完hashCode码之后还要比较一遍字符串值
- 因为两个对象相同,哈希码一定相同。但是哈希码相同,两个对象未必相同。
2、为什么不直接进行比较字符串值,省去比较hashCode的操作
- 因为比较hashCode值效率比直接比字符串要高很多,是为了提高效率,如果当比较的对象比较多的时候,一个一个枚举equals会比直接比较hashCode值效率差很多
例:
BM 和 C. 这两个字符串的hashCode值都是2123

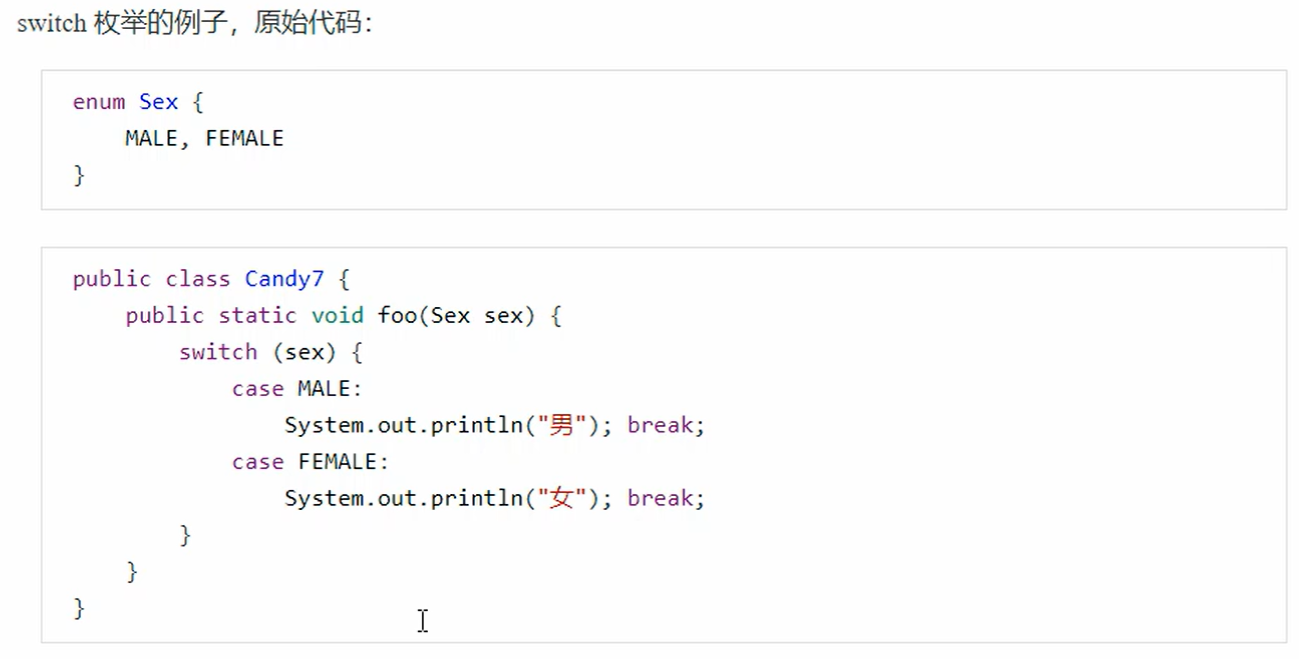
7. switch枚举
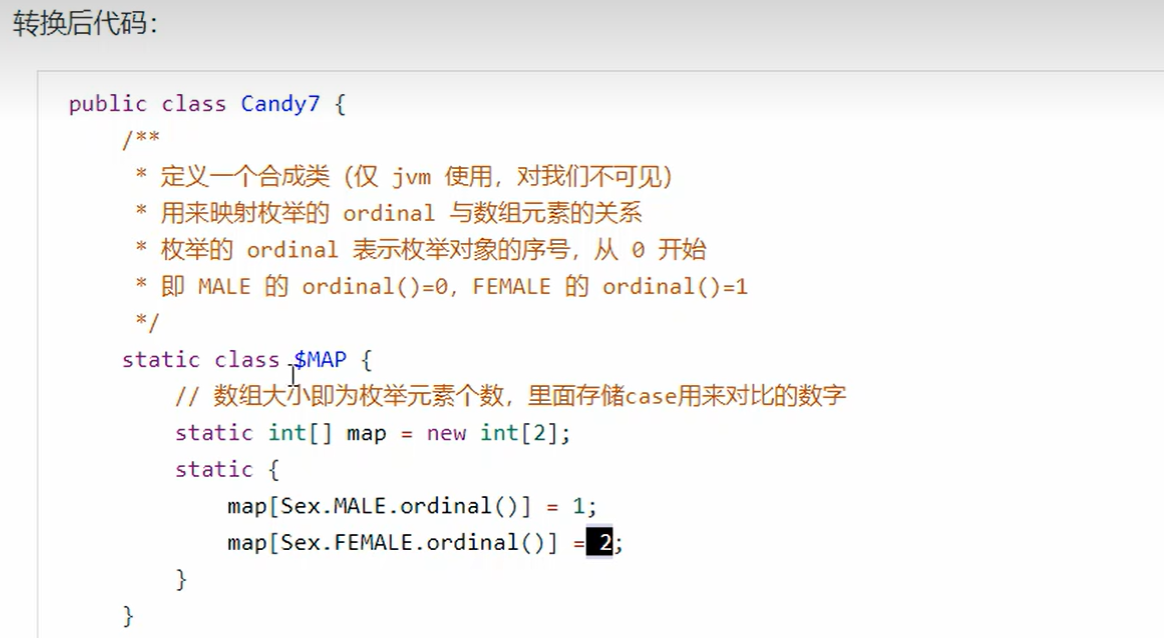

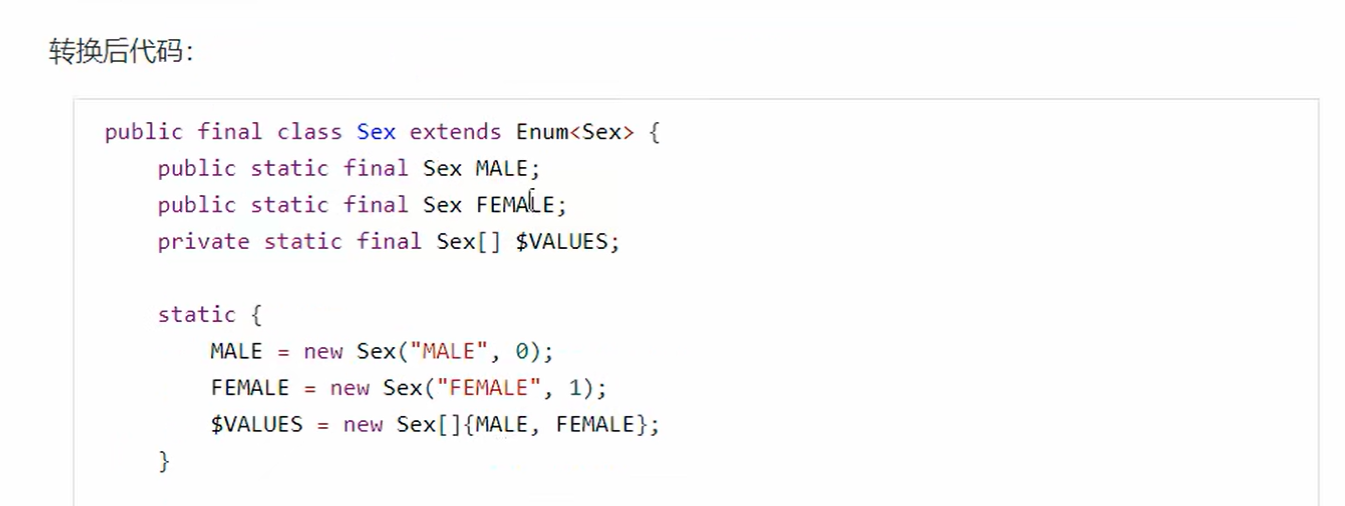
8. 枚举类

- final修饰的类不能够被继承
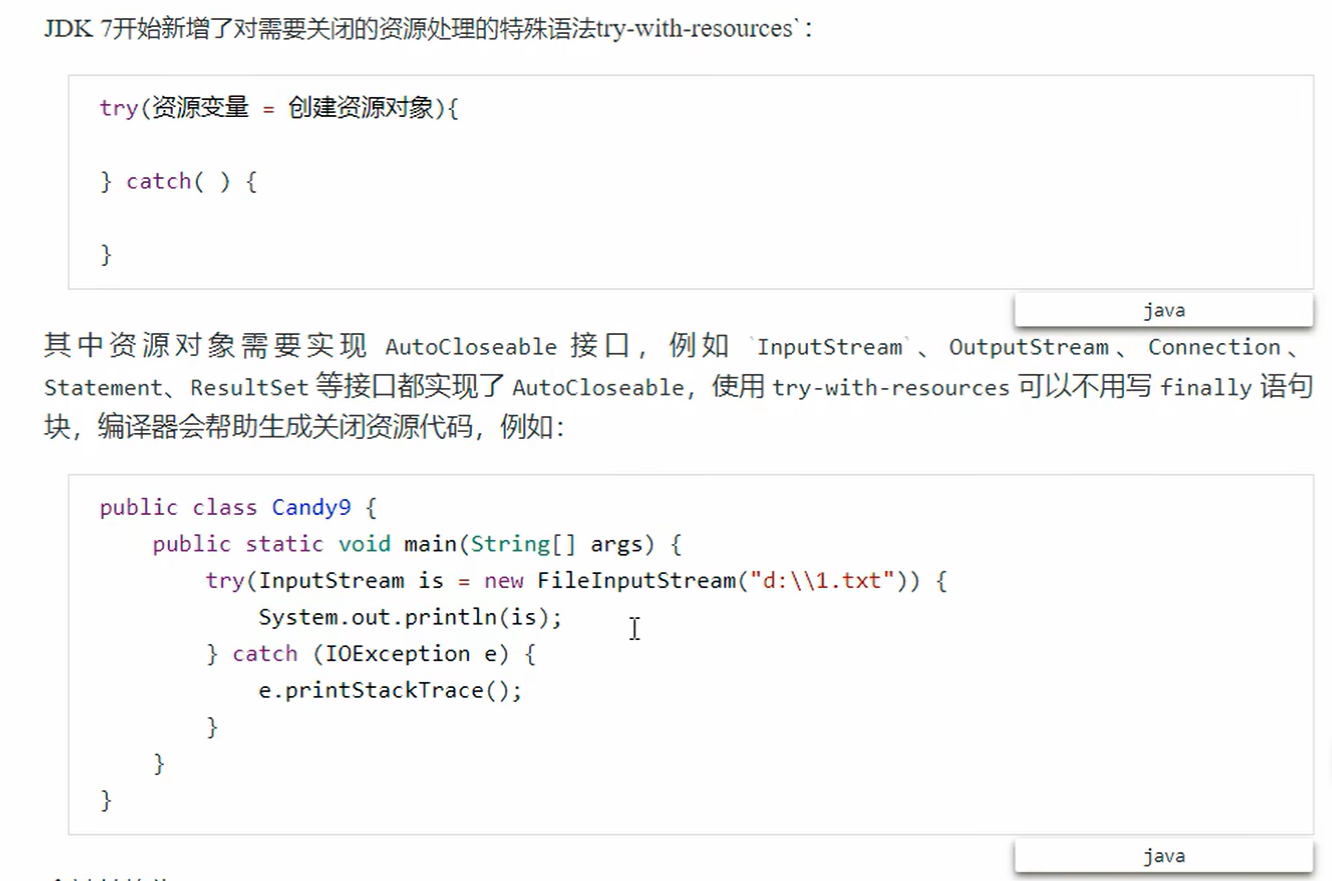
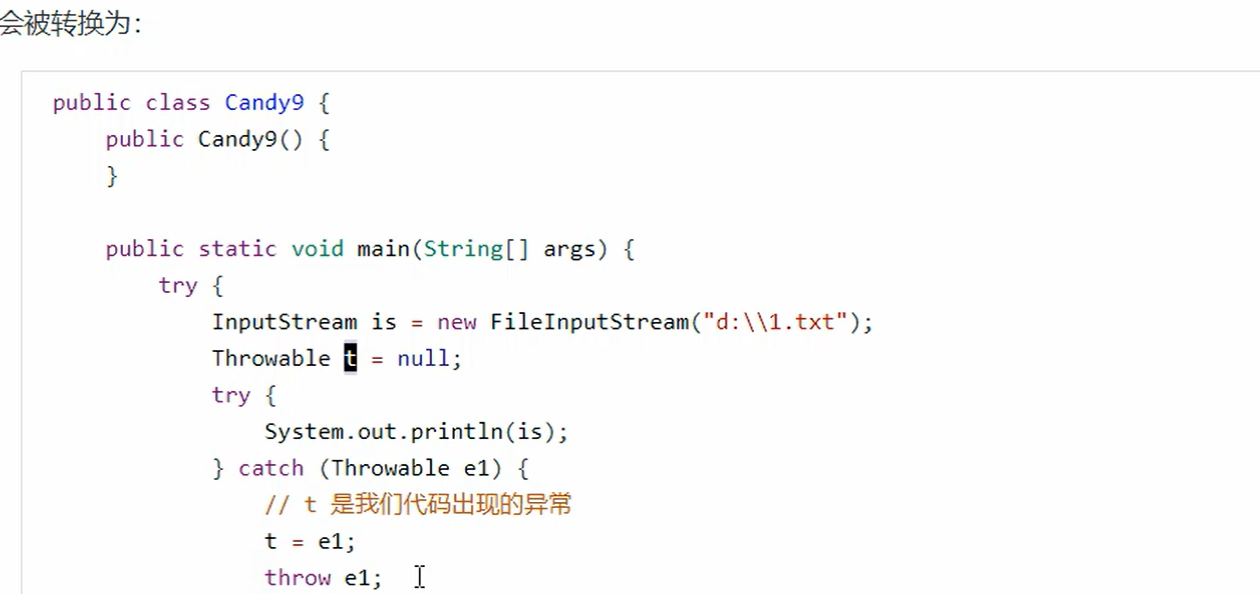
9. try-with-resources

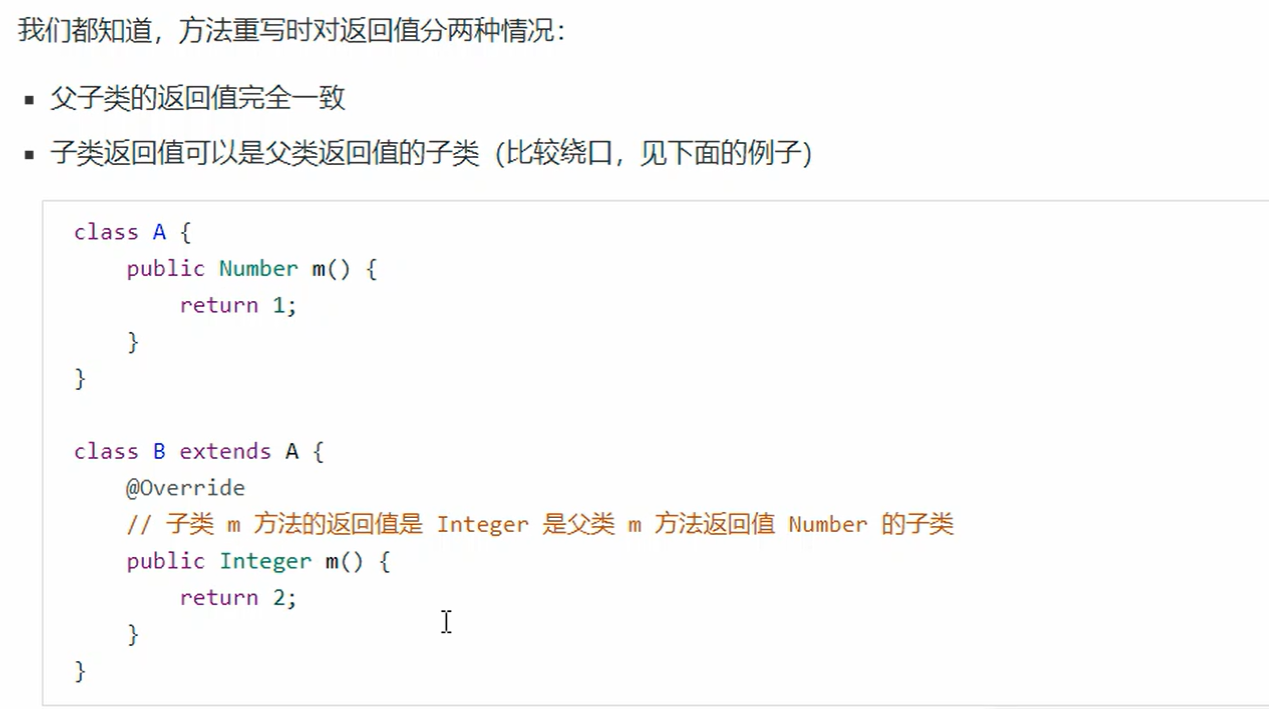
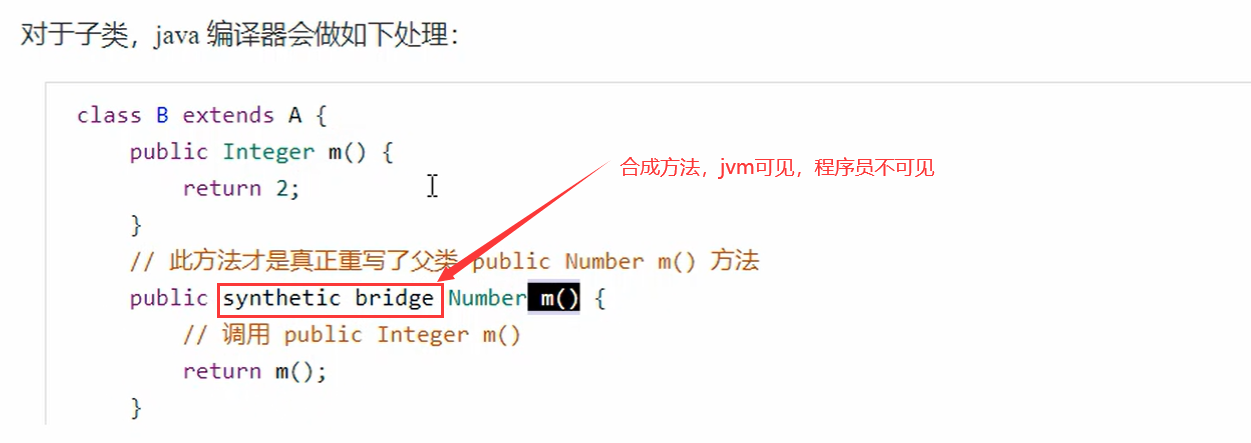
10. 方法重写时的桥接方法
重写规则,子类方法的返回类型不能超过父类方法的返回类型,子类方法的访问修饰符不能小于父类的访问修饰符

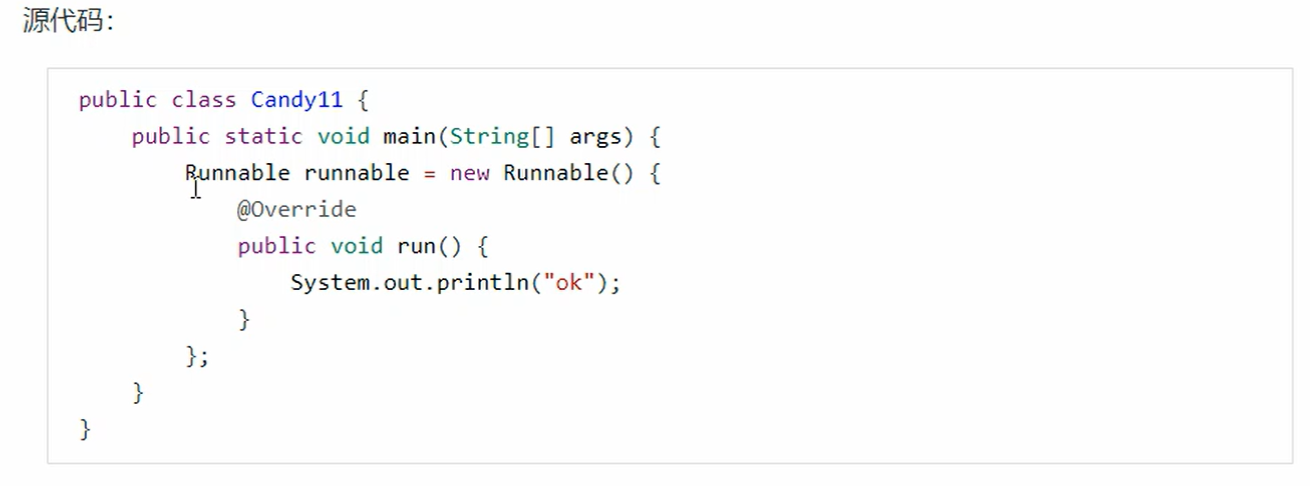
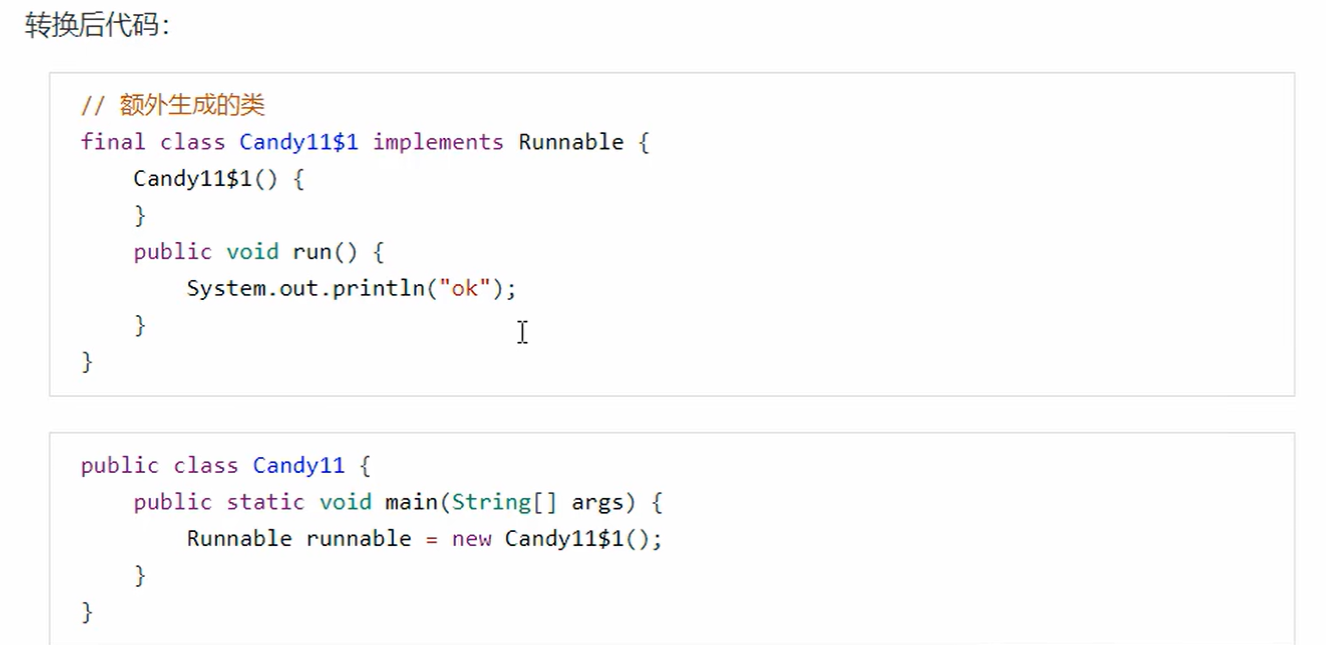
11. 匿名内部类

匿名内部类引用了外部的一个final修饰的变量,固定语法
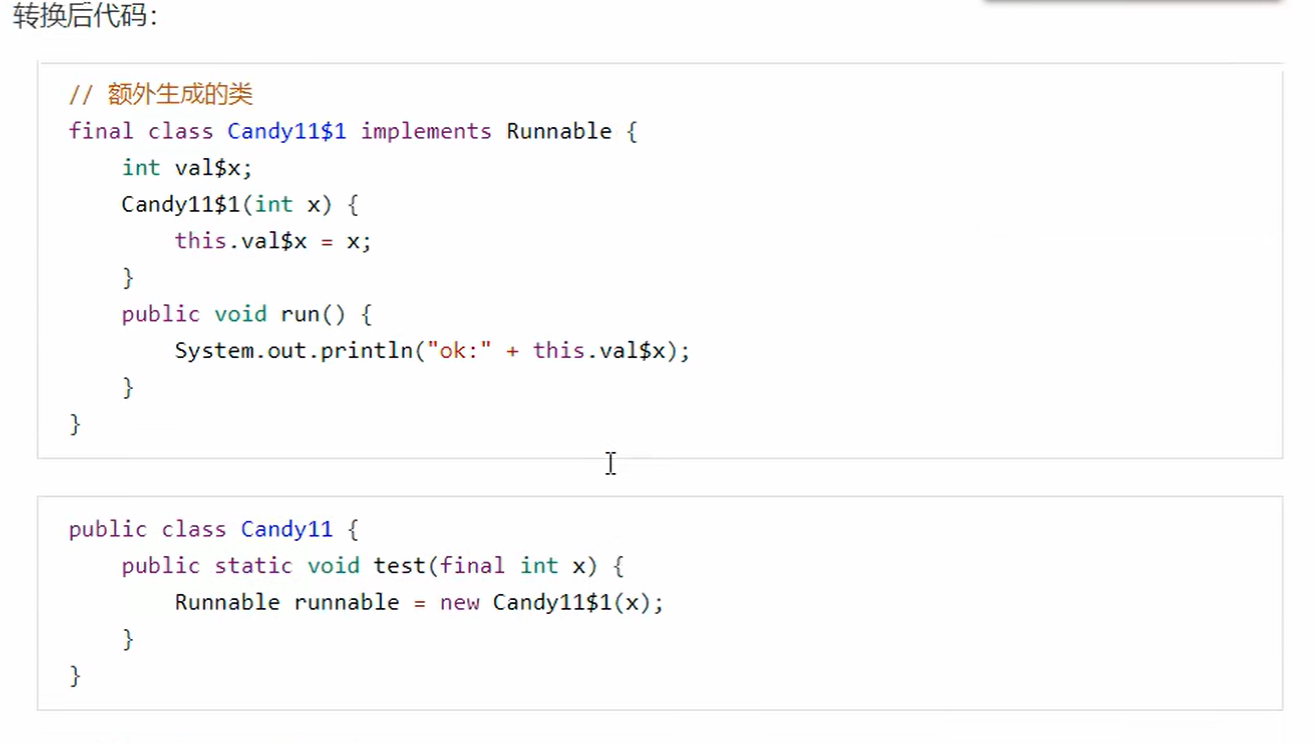
为什么需要是final修饰呢?
因为如果x的值不是final修饰的,那么说明是可以改变的,但是我们初始化的时候已经是传进去了一开始的值,内部类记录了已经是原先的值,你这时候修改了,跟内部类里面的值就不相同了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- kotlin first/last/indexOf/elementAt
- Golang 清晰代码指南 2
- 掌握Spring缓存-全面指南与最佳实践
- 营销投放下半场,游戏行业如何寻觅进化空间?
- javax.servlet-api报错问题
- 切比雪夫窗C、C++实现,基于Visual Studio 2022、C/C++语言实现切比雪夫窗函数[结果与matlab w = chebwin(L,r)函数相同]
- Fiddler抓取HTTPS最全(强)攻略
- ES在查询中发现无法匹配的字段类型
- HTML5+CSS3小实例:3D发光切换按钮效果
- Java SE入门及基础(11)