性能测试分析案例-定位服务器丢包
环境准备
预先安装 docker、curl、hping3 等工具,如 apt install docker.io curl hping3。
操作和分析
案例是一个 Nginx 应用,如下图所示,hping3 和 curl 是 Nginx 的客户端。
在终端一中执行下面的命令,启动 Nginx 应用,并在 80 端口监听。如果一切正常,你应该可以看到如下的输出:
docker run --name nginx --hostname nginx --privileged -p 80:80 -itd feisky/nginx:drop
执行 docker ps 命令,查询容器的状态,你会发现容器已经处于运行状态(Up)了:
docker ps

终端二中,执行下面的 hping3 命令,进一步验证 Nginx 是不是真的可以正常访问了。
hping3 -c 10 -S -p 80 xxx.xxx.xxx.xxx
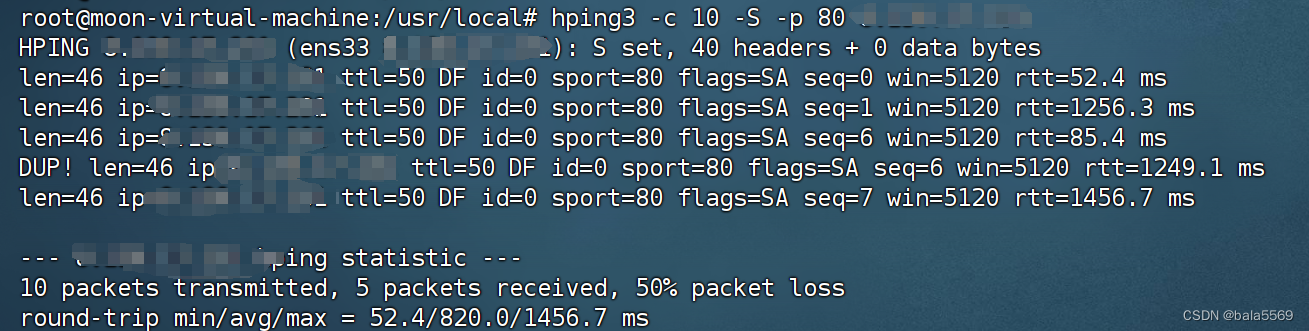
发送了 10 个请求包,却只收到了 5 个回复,50% 的包都丢了。再观察每个请求的 RTT 可以发现,RTT 也有非常大的波动变化,小的时候只有 52ms,而大的时候则有1s。
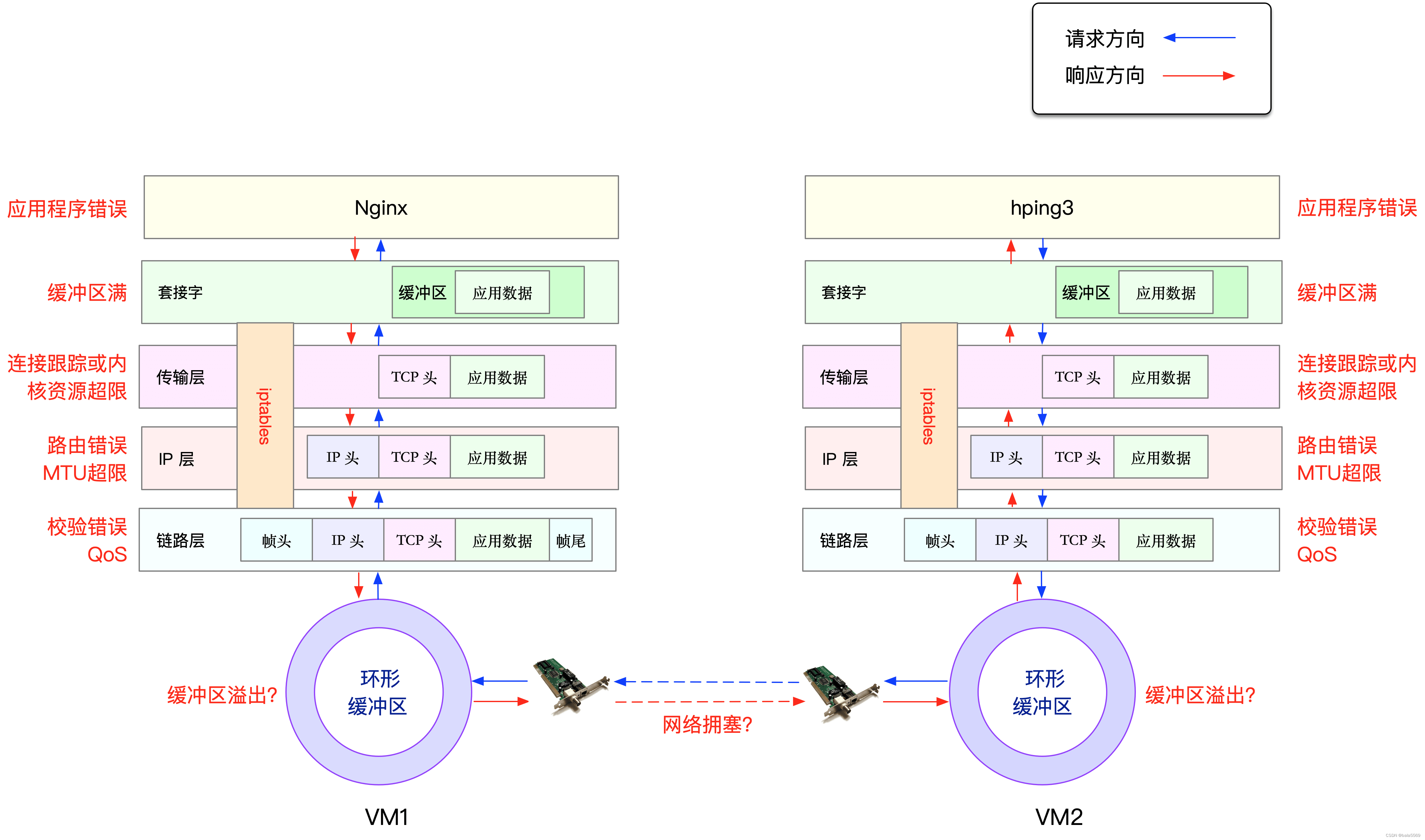
发生丢包的位置,实际上贯穿了整个网络协议栈。换句话说,全程都有丢包的可能。比如我们从下往上看:
在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
在网卡收包后,环形缓冲区可能会因为溢出而丢包;
在链路层,可能会因为网络帧校验失败、QoS 等而丢包;
在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;
在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;
在套接字层,可能会因为套接字缓冲区溢出而丢包;
在应用层,可能会因为应用程序异常而丢包;
此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包。
终端一,执行下面的命令,进入容器的终端中:
$ docker exec -it nginx bash
链路层
当缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中,记录下收发错误的次数。
你可以通过 ethtool 或者 netstat ,来查看网卡的丢包记录。比如,可以在容器中执行下面的命令,查看丢包情况:
netstat -i

RX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。没有任何错误,说明容器的虚拟网卡没有丢包。
还要查看一下 eth0 上是否配置了 tc 规则,并查看有没有丢包。我们继续容器终端中,执行下面的 tc 命令,不过这次注意添加 -s 选项,以输出统计信息:
tc -s qdisc show dev eth0

eth0 上面配置了一个网络模拟排队规则(qdisc netem),并且配置了丢包率为 30%(loss 30%)。再看后面的统计信息,发送了 29 个包,但是丢了 13 个。Nginx 回复的响应包,被 netem 模块给丢了。删掉 netem 模块就可以了。我们可以继续在容器终端中,执行下面的命令,删除 tc 中的 netem 模块:
root@nginx:/# tc qdisc del dev eth0 root netem loss 30%
切换到终端二中,重新执行刚才的 hping3 命令,看看现在还有没有问题:
hping3 -c 10 -S -p 80 xxx.xxx.xxx.xxx
还是 50% 的丢包;RTT 的波动也仍旧很大,从 3ms 到 1s。
丢包还在继续发生。不过,既然链路层已经排查完了,我们就继续向上层分析,看看网络层和传输层有没有问题。
网络层和传输层
执行下面的 netstat -s 命令,就可以看到协议的收发汇总,以及错误信息了:
netstat -s
Ip:
Forwarding: 1
61 total packets received
0 forwarded
0 incoming packets discarded
43 incoming packets delivered
48 requests sent out
Icmp:
0 ICMP messages received
0 input ICMP message failed
ICMP input histogram:
0 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
Tcp:
0 active connection openings
2 passive connection openings
10 failed connection attempts
0 connection resets received
0 connections established
43 segments received
64 segments sent out
17 segments retransmitted
0 bad segments received
0 resets sent
Udp:
0 packets received
0 packets to unknown port received
0 packet receive errors
0 packets sent
0 receive buffer errors
0 send buffer errors
UdpLite:
TcpExt:
10 resets received for embryonic SYN_RECV sockets
1 TCP sockets finished time wait in fast timer
4 SYNs to LISTEN sockets dropped
0 packet headers predicted
7 acknowledgments not containing data payload received
3 predicted acknowledgments
TCPSackRecovery: 1
3 congestion windows recovered without slow start after partial ack
TCPSackFailures: 1
1 timeouts in loss state
2 fast retransmits
TCPTimeouts: 12
TCPLossProbes: 2
TCPDSACKRecv: 1
TCPSpuriousRTOs: 2
TCPSackShifted: 1
TCPSackShiftFallback: 3
TCPRetransFail: 3
TCPSynRetrans: 5
TCPOrigDataSent: 20
IpExt:
InOctets: 2853
OutOctets: 3642
InNoECTPkts: 61
TCP 协议发生了丢包和重传,分别是:
10次连接失败重试(failed connection attempts)
17次重传(segments retransmitted)
10 次半连接重置(resets received for embryonic SYN_RECV sockets)
5次 SYN 重传(TCPSynRetrans)
12 次超时(TCPTimeouts)
TCP 协议有多次超时和失败重试,并且主要错误是半连接重置。换句话说,主要的失败,都是三次握手失败。
iptables
iptables 和内核的连接跟踪机制也可能会导致丢包。
# 容器终端中执行exit
root@nginx:/# exit
exit
# 主机终端中查询内核配置
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 65536
$ sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 14
连接跟踪数只有 14,而最大连接跟踪数则是 65536。显然,这里的丢包,不可能是连接跟踪导致的。
iptables 的原理,它基于 Netfilter 框架,通过一系列的规则,对网络数据包进行过滤(如防火墙)和修改(如 NAT)。
iptables -nvL 命令,查看各条规则的统计信息。比如,你可以执行下面的 docker exec 命令,进入容器终端;然后再执行下面的 iptables 命令,就可以看到 filter 表的统计数据了:
# 在主机中执行
docker exec -it nginx bash
# 在容器中执行
root@nginx:/# iptables -t filter -nvL
Chain INPUT (policy ACCEPT 25 packets, 1000 bytes)
pkts bytes target prot opt in out source destination
6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 15 packets, 660 bytes)
pkts bytes target prot opt in out source destination
6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
两条 DROP 规则的统计数值不是 0,它们分别在 INPUT 和 OUTPUT 链中。这两条规则实际上是一样的,指的是使用 statistic 模块,进行随机 30% 的丢包。
接下来的优化就比较简单了。比如,把这两条规则直接删除就可以了。我们可以在容器终端中,执行下面的两条 iptables 命令,删除这两条 DROP 规则:
root@nginx:/# iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP
root@nginx:/# iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP
执行刚才的 hping3 命令,看看现在是否正常:
hping3 -c 10 -S -p 80 xxx.xxx.xxx.xxx
没有丢包了
终端一,在容器终端中执行 exit 命令,退出容器终端:
root@nginx:/# exit
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!