大模型+自动驾驶

论文:https://arxiv.org/pdf/2401.08045.pdf
大型基础模型的兴起,它们基于广泛的数据集进行训练,正在彻底改变人工智能领域的面貌。例如SAM、DALL-E2和GPT-4这样的模型通过提取复杂的模式,并在不同任务中有效地执行,从而作为广泛AI应用的强大构建块。自动驾驶,作为AI应用的一个活跃前沿,仍然面临着缺乏专门的视觉基础模型(Vision Foundation Models,VFMs)的挑战。全面训练数据的稀缺、多传感器集成的需求和多样的任务特定架构对该领域VFMs的发展构成了重大障碍。本文深入探讨了为自动驾驶量身定制VFMs的关键挑战,并概述了未来的发展方向。通过对250多篇论文的系统分析,我们剖析了VFM开发的基本技术,包括数据准备、预训练策略和下游任务适应。此外,我们还探索了如NeRF、扩散模型、3D高斯喷溅和世界模型等关键进展,为未来研究提供了全面的路线图。为了赋能研究者,我们建立并维护了Forge VFM4AD,一个开放获取的存储库,不断更新自动驾驶VFMs锻造的最新进展。
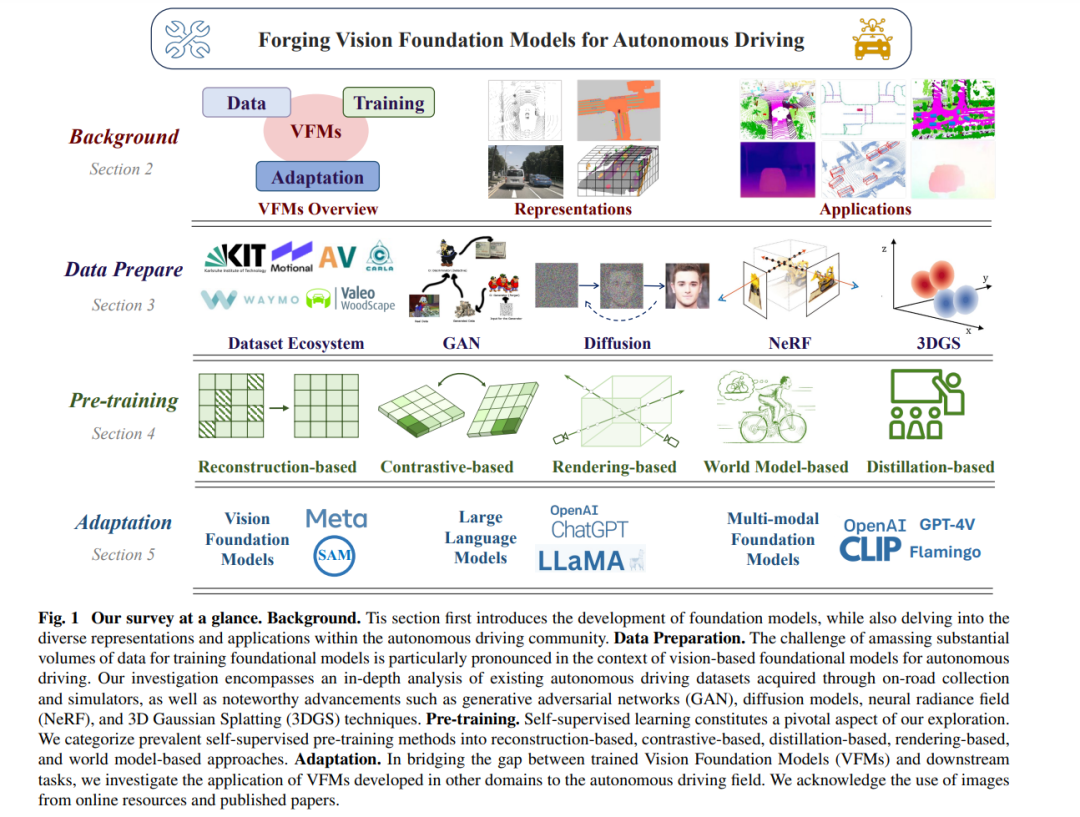
自动驾驶(AD)技术的迅速发展正在重塑交通运输领域,开启了一个由AI驱动的未来。传统的自动驾驾驶感知系统依赖于模块化架构,使用专门的算法来处理特定任务,例如对象检测 Lang et al. (2019);Mao, Xue, et al. (2021),语义分割 Y. Guo, Liu, Georgiou, 和 Lew (2018);X. Yan et al. (2022),以及深度估计 Ming, Meng, Fan, 和 Yu (2021)。每个任务通常由一个单独的模型解决,这些模型通常是在特定任务标签上训练的深度神经网络。然而,这些分隔的组件在提升单个任务性能的同时牺牲了更广泛的上下文理解和数据关系。这种方法通常导致输出不一致,并限制了系统处理长尾案例的能力。
大规模基础模型,尤其是自然语言处理(NLP)领域的 Brown et al. (2020);OpenAI (2023),已成为人工智能领域的强大力量。这些模型在训练时使用了广泛多样的数据集,并经常利用自监着学习技术。一旦训练完成,它们可以通过微调来适应广泛的特定任务。像GPT-3/4 Brown et al. (2020);OpenAI (2023)这样的数十亿参数模型在零/少次射击学习中的成功尤其值得注意。它们在少次射击学习方面的卓越能力使它们能够有效地处理分布外的AD数据情景,例如遇到未知对象。此外,它们在推理方面的内在能力使它们非常适合需要逻辑处理和明智决策的任务。
尽管大型基础模型确实在各个领域产生了革命性的影响,但它们对AD的影响尚未达到预期。将现有的在2D数据或其他领域的文本模态上训练的视觉基础模型(VFMs)直接应用于AD任务已被证明是明显不足的。这些模型缺乏利用对AD感知任务至关重要的丰富3D信息的能力,例如深度估计。此外,AD架构的内在异质性和多传感器融合的必要性给VFMs的直接适应带来了额外挑战。这一挑战由高效处理多样化传感器数据(例如激光雷达、相机、雷达)并无缝适应AD领域内各种下游任务的VFMs需求进一步加剧。
在自动驾驶发展的背景下,两个关键因素阻碍了视觉基础模型的进展:- 数据稀缺性:由于隐私问题、安全规定和捕捉真实世界驾驶场景的复杂性,AD数据本质上是有限的。此外,AD数据必须满足严格的要求,包括多传感器对齐(例如激光雷达、相机、雷达)和时间一致性。
-
任务异质性:自动驾驶呈现出一系列不同的任务,每个任务都需要不同的输入形式(例如相机、激光雷达、雷达)和输出格式(例如3D边界框、车道线、深度图)。这种异质性对VFMs构成了挑战,因为针对一个任务优化的架构在其他任务上的表现往往不令人满意。因此,开发一个能够高效处理多传感器数据并在各种不同下游任务中表现良好的单一通用架构和表示仍然是一个重大障碍。
尽管存在这些挑战,但有迹象表明,为自动驾驶开发大型视觉基础模型的前景正在逐渐显现。通过持续收集 Caesar et al. (2020);Mao, Niu, et al. (2021)和先进模拟技术的不断发展 X. Li et al. (2023);Z. Yang et al. (2023a)为解决数据稀缺问题提供了可能。此外,感知领域的最新进展,尤其是转向统一表示法,利用鸟瞰图(BEV) Z. Li, Wang, et al. (2022);Philion 和 Fidler (2020),和占用表示法 X. Tian, Jiang, et al. (2023),为缺乏通用表示法和架构的问题提供了潜在的解决方案。
本文深入探讨了为自动驾驶发展大型视觉基础模型的关键技术,如图1所示。我们的探索从在基础模型、现有框架和任务方面建立全面背景开始,以及发展表示法,概述我们的核心动机在第2节中。随后,我们在第3节深入研究现有数据集和数据模拟技术,强调了像生成对抗网络(GANs)、神经辐射场(NeRFs)、扩散模型和3D高斯喷溅(3DGS)等技术在解决自动驾驶固有数据稀缺性方面的关键作用。在这个基础上,第4节分析了有效训练VFMs在未标记真实世界数据上的自我训练技术。最后,为了弥合训练有素的VFMs和下游任务之间的差距,第5节探讨了将在其他领域发展的基础模型应用于AD领域。我们审视了所学到的宝贵经验和潜在适应性,以实现自动驾驶中多样化下游任务的有效性能。
与现有的综述论文 Firoozi et al. (2023);Y. Huang, Chen, 和 Li (2023);J. Sun et al. (2023);Z. Yang, Jia, Li, 和 Yan (2023)不同,这些论文囊括了在各个领域应用大型基础模型,本文通过专注于为自动驾驶挑战量身定制的大型视觉基础模型的发展提出了一种新的方法。这种独特的视角使我们能够更深入地探讨构建VFMs所需的基本原则和技术进步,以推动该领域的实质性进展。
本工作的主要贡献可以总结如下:
-
我们采用了一个统一的流程来发展自动驾驶的大型视觉基础模型(VFMs)。这个流程包括对数据准备、自监着学习和适应的全面审查。
-
我们系统地分类了提出框架内每个过程的现有工作,如图2所示。我们的分析提供了细致的分类、深入的比较,并在每个部分总结了洞见。
-
我们深入探讨了在为自动驾驶打造视觉基础模型(VFMs)时遇到的关键挑战。通过对超过250篇综述论文的洞察,我们总结了关键方面,并提出了未来研究的方向。

数据准备?
在自动驾驶的背景下,鉴于确保人类安全所涉及的高风险,处理复杂驾驶场景的稳健性至关重要。自动驾驶系统必须有效地应对各种挑战,包括交通参与者、天气条件、照明以及道路状况。然而,收集涵盖所有可能场景的数据集(如意外的行人相关交通事故)是不切实际且效率低下的。此外,基于合成数据训练的模型可能难以有效地概括到现实世界场景,因为数据分布可能存在差异。因此,问题的关键在于生成逼真且可控制的数据。值得鼓舞的是,最近的进展,特别是在扩散模型和NeRF方面,已经产生了模糊了现实与机器生成界限的图像,为解决数据稀缺提供了有希望的技术支持。
本节不仅深入研究利用现有数据集,还探索了以成本效益和高效方式收集、合成或增强自动驾驶数据的多种方法。这包括生成对抗网络、扩散模型、神经辐射场和3D高斯喷溅等技术。表2提供了这些数据生成方法的概览。
自监着学习训练?
在获取大量逼真数据后,有效的预训练范式对于从庞大数据集中提取一般信息和构建视觉基础模型至关重要。
自监着学习(self supervised learning),即在大量未标记数据上进行训练,已在多个领域显示出潜力,如自然语言处理和特定的图像处理应用。此外,它为自动驾驶的视觉基础模型(VFMs)的发展带来了新的前景。如表3所示,我们对构建自动驾驶VFMs的自监着学习范式进行了全面的综述,涵盖了所有自监着或无监督方式的努力。这些方法被归类为五个主要类型,包括基于对比的、基于重构的、基于蒸馏的、基于渲染的和基于世界模型的。
适配
虽然当前缺乏为自动驾驶量身定制的视觉基础模型(Vision Foundation Model)构成了挑战,但我们可以分析现有基础模型的应用,例如来自其他领域的视觉基础模型、多模态基础模型和大型语言模型(Large Language Models),以增强我们的理解。表5清晰地总结了一些著名模型。通过检查现有解决方案的局限性,我们已经提取了关键见解,并提出了专门为自动驾驶定制的视觉基础模型。
结论
基础模型的出现已根本性地改变了人工智能的格局,其在革新自动驾驶方面的潜力不可否认。本文深入探讨了为自动驾驶专门打造视觉基础模型(VFM)的核心问题,重点突出了数据生成、预训练和适应性等关键技术。然而,朝着稳健且适应性强的自动驾驶感知系统迈进的道路依然充满挑战。我们希望我们的调查和平台能够促进未来在安全关键的自动驾驶领域内视觉基础模型的研究。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于linux的type help to learn how to use xshell prompt问题的解决办法。
- Poe会员开通保姆级教程
- T2I-Adapter: 让马良之神笔(扩散模型)从文本生成图像更加可控
- uni-app 前后端调用实例 基于Springboot 下拉刷新实现
- 想做好私域,数字化基础要打好!
- Airflow大揭秘:如何让大数据任务调度变得简单高效?
- MYSQL备份和恢复
- Hex2Bin转换工具文档、Bootloader 、OTA 、STM32等MCU适用
- 一文读懂CAN总线协议 (超详细配34张高清图)
- 【c语言】猜数字游戏