算法设计与分析(1):导论和线性时间选择
本系列的目的是简要概述算法主题及其涉及的思维类型:为什么我们专注于我们所做的主题,以及为什么我们强调证明保证。我们会通过一个很容易涉及到的问题示例,即查找 n n n 个元素集合的中位数。对于这个问题,有一个简单的 O ( n log ? n ) O (n \log n ) O(nlogn) 时间算法,但我们可以使用随机化和巧妙的确定性构造做得更好。这些说明了我们将在本系列中使用(和构建)的一些想法和工具。我们还将练习编写和解决递归关系,这是算法分析的关键工具。
在本章中,我们涵盖:
- 算法的研究是关于什么的?
- 为什么我们关心规格和证明保证?
- 寻找中位数:预期线性时间内的随机算法。
- 分析随机递归算法 - 中值的确定性线性时间算法。
1 目标
该系列涉及算法的设计和分析——如何设计正确高效的算法,以及如何清晰地分析其正确性和运行时间。什么是算法?算法最基本的定义是解决计算问题的方法。一个配方。算法还需要一个规范说明它能提供什么保证。例如,我们可能能够说明,我们的算法可以在任何大小为 n n n 的输入上正确解决这个问题,并且运行时间不超过 f ( n ) f(n) f(n)。这门课程涵盖了整个过程:高效算法的设计,以及证明它们满足期望的规范。对于这些章节中的每一章,我们将研究重要的技术发展,通过练习我们将不断增强自身对关键问题的清晰思考能力。
这个系列的主要目标是提供设计和分析你未来需要解决的算法问题所需的知识工具。我们将讨论的一些工具包括动态规划、分治法、哈希和其他数据结构、随机化、网络流以及线性规划。我们将讨论和使用的一些分析工具包括递归、概率分析、摊销分析和潜在函数。我们还将讨论一些处理NP-完全问题的方法,包括近似算法的概念。
另一个目标是讨论超越传统输入-输出模型的模型。在传统模型中,我们认为算法在前期获得所有输入,只需执行计算并给出输出。当适用时,这个模型很好,但它并不总是正确的模型。例如,由于一些问题需要在没有完整信息的情况下做出决策,因此这些问题可能具有挑战性。解决这类问题的算法称为在线算法,我们也将对其进行讨论。在其他环境中,我们可能需要处理“流”输入数据的数量,其中我们拥有的空间远小于数据。在另一些环境中,输入被一组自私的代理人持有,他们可能会也可能不会告诉我们正确的值。
2 关于保证和规范
一个重点是证明算法的正确性和运行时间保证。拥有这样的保证有什么用呢?假设我们正在讨论对一个包含 n n n 个数字的列表进行排序的问题。很明显,我们至少想知道我们的算法是否正确,这样我们就不必担心它是否总是给出了正确的答案。但是,为什么要分析运行时间呢?为什么不直接编写我们的算法,在100个随机输入上测试它,然后看看会发生什么呢?这里有几个理由可以激发我们对这种分析的关注——你可能也能想到更多的理由:
可组合性 运行时间的保证提供了“清晰的接口”。这意味着我们可以将该算法作为子例程在其他一些算法中使用,而不需要担心它现在被使用的输入是否与它最初被测试的输入类型相匹配。
可扩展性 我们将检查的这种保证类型将告诉我们运行时间随问题实例大小的增长率。由于各种原因,这一点很有用。例如,它大致告诉了我们,给定一定的资源,我们可以合理期望处理的问题大小。
设计更好的算法 分析算法的渐近运行时间是思考算法的一种有用方式,这通常会导致非显而易见的改进。
理解 分析可以告诉我们算法的哪些部分对于什么样的输入至关重要,以及原因。如果以后我们得到一个稍微不同但相关的任务,我们的分析通常可以很快告诉我们对现有算法进行小的修改后是否可以期望在新问题上获得类似的性能。
复杂性理论上的动机 在复杂性理论中,我们想知道:“基本问题 X X X 的确有多难?”例如,我们可能知道,对于一个给定的问题,没有算法可以以 o ( n log ? n ) o(n \log n) o(nlogn)(渐近更慢于 n log ? n n \log n nlogn )的时间运行,而我们有一个以 O ( n 3 / 2 ) O(n^{3/2}) O(n3/2) 运行时间的算法。这告诉了我们对该问题的理解程度,以及我们改进的余地有多大。
当思考算法时,将算法设计者想出一个好算法来解决问题,而它的对手试图给出一个会导致算法运行缓慢的输入的游戏,常常是有帮助的。最坏情况下性能良好的算法是指无论对手选择什么输入,该算法的性能都很好的算法。当我们讨论下界和博弈论时,我们将以更正式的方式回到这种观点。
3 示例:中位数查找
使算法设计成为“计算机科学”的一个原因是,从问题的定义最明显的解决方式通常不是获得解决方案的最佳方式。中位数查找就是一个例子。回想一下集合的中位数概念。对于一个包含 n n n 个元素的集合,这是集合中的“中间”元素,即有确切的 ? n / 2 ? ?n/2? ?n/2? 个元素比它大。用计算机科学的术语来说,如果元素是从0开始索引的,则中位数是在排序顺序表示的集合中的第 ? ( n ? 1 ) / 2 ? ?(n - 1)/2? ?(n?1)/2? 个元素。
给定一个未排序的数组,能多快找到中位数元素?也许最简单的解决方案,一个可以用一句话描述并用你最喜欢的编程语言一行或两行代码实现的解决方案,就是对数组排序,然后读取位置 ? ( n ? 1 ) / 2 ? ?(n?1)/2? ?(n?1)/2? 处的元素,这使用MergeSort、HeapSort(确定性算法)或QuickSort(随机化算法)等你最喜欢的排序算法需要 O ( n log ? n ) O(n \log n) O(nlogn) 时间。
有没有比排序更快的方法?在本章中,我们将描述这个问题的两种线性时间算法:一种是随机化的,一种是确定性的。更一般地说,我们解决了在一个未排序的包含 n n n 个元素的数组中找出第 k k k 小元素的问题。
3.1 问题和随机解决方法
让我们考虑一个比中值查找稍微更普遍的问题:查找大小为 n n n 的未排序数组中的第 k k k 个最小元素。
为消除歧义,我们假设数组是从0开始索引的,所以第 k k k 小的元素是数组排序后将处在第 k k k 个位置的元素。另一种说法是,恰好有 k k k 个其他元素比它小的元素。另外,假设所有元素都是不同的,以避免当存在重复元素时,第 k k k 小元素的含义产生疑问。
解决这个问题的直接方法是排序,然后输出第 k k k 个元素。如果我们使用归并排序、快速排序或堆排序,可以在 O ( n log ? n ) O(n \log n) O(nlogn) 的时间内完成此操作。然而,我们今天希望能得到比这快的方法。有没有更快的算法——线性时间的算法?答案是肯定的。我们将一起探索一个简单的随机化解决方法和一个更加复杂的确定性解决方法。
获得线性时间算法的关键思想是识别和消除冗余/浪费的工作。请注意,通过对数组排序,我们不仅找到了给定 k k k 值的第 k k k 小元素,实际上我们找到了每一个可能的 k k k 值的答案。因此,与完全排序数组不同,对数组进行“部分排序”,使第 k k k 个元素最终位于正确的位置就足够了,但其余元素可能仍然没有完全排序。这可能让你想起快速排序,它选择一个称为“枢轴”的元素,并将其放置在数组中的正确排序位置,然后将所有小于它的元素移动到左侧,大于它的元素移动到右侧。从本质上讲,这是相对于枢轴对数组进行部分排序。然后递归地对两侧进行排序以对整个数组进行排序。
那么,如果我们只运行快速排序,但跳过一些不相关的步骤,会怎么样呢?具体来说,请注意,如果我们运行快速排序并且我们的目标是在最后输出第 k k k 个元素,那么在围绕枢轴分割数组之后,我们知道两个分区中的哪一个一定包含答案。因此,与递归地对两边进行排序不同,我们忽略不包含答案的那一边,只进行一次递归。
更具体地说,该算法选择一个随机枢轴,然后将数组划分为两个集合 LESS \text{LESS} LESS 和 GREATER \text{GREATER} GREATER,由小于和大于枢轴的元素组成。在划分步骤之后,我们可以通过查看集合的大小来判断 LESS \text{LESS} LESS 或 GREATER \text{GREATER} GREATER 中的哪一个包含我们正在查找的项。例如,如果我们在数组中查找第 87 87 87 小的元素,并且假设在选择枢轴和划分之后,我们发现 LESS \text{LESS} LESS 有 200 200 200 个元素,那么我们只需要在 LESS \text{LESS} LESS 中找到第 87 87 87 小的元素。另一方面,如果我们发现 LESS \text{LESS} LESS 有 40 40 40 个元素,那么我们只需要在 GREATER \text{GREATER} GREATER 中找到第 87 ? 40 ? 1 = 46 87-40-1=46 87?40?1=46 小的元素。(如果 LESS \text{LESS} LESS 的大小刚好为 86 86 86,我们可以直接返回枢轴元素)。有人可能会首先认为,算法只对一个子集进行递归,而不是两个子集,时间只会减少一倍。然而,由于这是递归发生的,它会累积节省,我们最终得到 Θ ( n ) Θ(n) Θ(n) 而不是 Θ ( n log ? n ) Θ(n \log n) Θ(nlogn)。这个算法通常被称为随机选择或快速选择。

定理1 QuickSelect 的预期比较次数最多为
8
n
8n
8n 。
正式地,让 T ( n ) T(n) T(n) 表示快速选择算法在任何大小为 n n n 的(最坏情况)输入上执行的比较次数的期望。我们想要的是一个看起来像
T ( n ) ≤ n ? 1 + E [ T ( X ) ] T(n) ≤ n-1 + \mathbb{E}[T(X)] T(n)≤n?1+E[T(X)]
的递归关系式,其中 n ? 1 n-1 n?1 次比较来自将枢轴元素与其他每一个元素进行比较并将它们放入 LESS \text{LESS} LESS 和 GREATER \text{GREATER} GREATER,而 X X X 是递归解决的子问题的大小对应的一个随机变量。我们不能直接去解这个递归关系,因为我们还不知道 X X X 或 E [ T ( X ) ] \mathbb{E}[T(X)] E[T(X)] 的样子。
在给出正式证明之前,这里有一些直观想法。首先,递归调用数组的大小 X X X 有多大?它取决于两个因素: k k k 的值和随机选择的枢轴。将输入划分为 LESS \text{LESS} LESS 和 GREATER \text{GREATER} GREATER (大小之和为 n ? 1 n-1 n?1)后,算法会对其中一个递归调用快速选择,但选择哪一个?由于我们对最坏情况输入的行为感兴趣,我们可以悲观地假设 k k k 的值总是使我们选择 LESS \text{LESS} LESS 和 GREATER \text{GREATER} GREATER 中较大的一个。因此,问题变成:如果我们选择一个随机枢轴并将输入划分为 LESS \text{LESS} LESS 和 GREATER \text{GREATER} GREATER ,那么两个集合中较大的一个有多大?忽略舍入的话,可能的划分大小为:
( 0 , n ? 1 ) , ( 1 , n ? 2 ) , ( 2 , n ? 3 ) , . . . , ( n / 2 ? 2 , n / 2 + 1 ) , ( n / 2 ? 1 , n / 2 ) (0, n-1), (1, n-2), (2, n-3), ..., (n/2-2, n/2+1), (n/2-1, n/2) (0,n?1),(1,n?2),(2,n?3),...,(n/2?2,n/2+1),(n/2?1,n/2)
所以我们可以看出两个集合中较大的一个是从下列中随机选择的数字:
n ? 1 , n ? 2 , n ? 3 , . . . , n / 2 + 1 , n / 2 n-1, n-2, n-3, ..., n/2+1, n/2 n?1,n?2,n?3,...,n/2+1,n/2
所以,较大一半的期望大小约为 3 n / 4 3n/4 3n/4,同样,忽略舍入错误。
换一种表达方式,如果我们随机将一根糖果棒分成两块,较大一块的期望大小是糖果棒的 3 / 4 3/4 3/4。使用这一点,我们可能会尝试写下以下几乎正确但不完全正确的递归关系:
T ( n ) ≤ n ? 1 + T ( 3 n / 4 ) T(n) ≤ n-1 + T(3n/4) T(n)≤n?1+T(3n/4)
如果我们解这个递归关系,可以得到 T ( n ) = O ( n ) T(n)=O(n) T(n)=O(n),但不幸的是,这个推导并不完全有效。原因是 3 n / 4 3n/4 3n/4 只是较大那块的期望大小。也就是说,如果 X X X 是较大那块的大小,我们写了一个递归关系式,其中递归调用的代价是 T ( E [ X ] ) T(\mathbb{E}[X]) T(E[X]),但它本应该是 E [ T ( X ) ] \mathbb{E}[T(X)] E[T(X)],这两者并不相同!(下面的练习表明两者可能差很多。)让我们现在更正式地看一下这个。
证明定理1. 为了修正证明,我们需要正确分析 T ( X ) T(X) T(X) 的期望值,而不是 X X X 的期望值所对应的 T T T 值。为此,我们可以考虑 X X X 取某些值的概率是多少,并分析 T T T 的相应行为。那么, X X X 最多为 3 / 4 3/4 3/4 的概率是多少?这发生在 LESS \text{LESS} LESS 和 GREATER \text{GREATER} GREATER 中较小的一个至少有四分之一的元素时,也就是当枢轴元素不在底部四分之一或顶部四分之一时。这意味着枢轴需要在数据的中间一半,发生概率为 1 / 2 1/2 1/2。另一半时间内, X X X 的大小将更大,最多为 n ? 1 n-1 n?1。虽然这听起来相当宽松,但这已经足够好来写下一个很好的上界递归!
E [ T ( X ) ] ≤ 1 2 T ( 3 n 4 ) + 1 2 T ( n ) \mathbb{E}[T(X)] ≤ \frac{1}{2}T\left(\frac{3n}{4}\right) + \frac{1}{2}T(n) E[T(X)]≤21?T(43n?)+21?T(n)
这个界似乎太宽松了,但我们将看到它已经足够好。回到我们原始的递归关系,我们现在可以正确地断定:
T ( n ) ≤ n ? 1 + ( 1 2 T ( 3 n 4 ) + 1 2 T ( n ) ) T(n) ≤ n-1 + (\frac{1}{2}T(\frac{3n}{4}) + \frac{1}{2}T(n)) T(n)≤n?1+(21?T(43n?)+21?T(n))
将两边乘以 2 2 2 然后减去 T ( n ) T(n) T(n),我们得到:
T ( n ) ≤ 2 ( n ? 1 ) + T ( 3 n 4 ) T(n) ≤ 2(n-1) + T\left(\frac{3n}{4}\right) T(n)≤2(n?1)+T(43n?)
我们现在可以使用归纳法来证明这个递归关系满足
T
(
n
)
≤
8
n
T(n)≤8n
T(n)≤8n。基础情况很简单,当
n
=
1
n=1
n=1 时没有比较,所以
T
(
1
)
=
0
T(1)=0
T(1)=0。现在为了归纳假设对于所有
i
<
k
i<k
i<k,
T
(
i
)
≤
8
i
T(i)≤8i
T(i)≤8i 成立。我们想要证明
T
(
k
)
≤
8
k
T(k)≤8k
T(k)≤8k。我们有:
T
(
k
)
≤
2
(
k
?
1
)
+
T
(
3
k
4
)
≤
2
(
k
?
1
)
+
8
(
3
k
4
)
≤
2
k
+
6
k
=
8
k
\begin{aligned} T(k) & ≤ 2(k-1) + T\left(\frac{3k}{4}\right)\\ & ≤ 2(k-1) + 8\left(\frac{3k}{4}\right)\\ & ≤ 2k + 6k\\ & = 8k \end{aligned}
T(k)?≤2(k?1)+T(43k?)≤2(k?1)+8(43k?)≤2k+6k=8k?
这证明了我们想要的界限。
4 确定性线性时间算法
有关确定性线性时间算法呢?长期以来人们认为这是不可能的,并且没有比首先对数组排序更快的方法。在正式证明这一点的过程中,发现这种想法是错误的,1972年,Manuel Blum、Bob Floyd、Vaughan Pratt、Ron Rivest和Bob Tarjan开发了一种确定性线性时间算法。
该算法的思想是,希望以一种产生良好划分的确定性方式选择枢轴元素。理想情况下,我们希望枢轴元素是中位数,这样两边的大小相同。但这正是我们最初要解决的问题!因此,作为代替,我们将给自己留出余地,允许枢轴元素是“大致”处于中间的任何元素(即某种“近似中位数”)。我们将使用一种称为中位数的中位数的技术,它取一堆小组元素的中位数,然后找到这些中位数的中位数。它有一个很棒的保证,即所选元素大于数组元素的至少30%,并且小于数组元素的至少30%。这使得它作为近似中位数和良好的枢轴选择效果很好!该算法如下。

定理2 确定性选择进行
O
(
n
)
O (n )
O(n) 次比较以查找大小为
n
n
n 的数组中的第
k
k
k 个最小元素。
证明定理2。设 T ( n ) T(n) T(n) 表示确定性选择算法在大小为 n n n 的输入上的最坏情况下执行的比较次数。
第1步需要 O ( n ) O(n) O(n) 的时间,因为找到5个元素的中位数只需要常数时间。第2步最多需要 T ( n / 5 ) T(n/5) T(n/5) 的时间。第3步再次需要 O ( n ) O(n) O(n) 的时间。现在,我们声明至少 3 / 10 3/10 3/10 的数组元素 ≤ p ≤p ≤p,至少 3 / 10 3/10 3/10 的数组元素 ≥ p ≥p ≥p。假设这一声明是真的,第4步最多需要 T ( 7 n / 10 ) T(7n/10) T(7n/10) 的时间,我们有递归关系:
T ( n ) ≤ c n + T ( n / 5 ) + T ( 7 n / 10 ) T(n) ≤ cn + T(n/5) + T(7n/10) T(n)≤cn+T(n/5)+T(7n/10)
这里 c c c 是某个常数。在求解这个递归关系之前,我们先证明pivot将大致在数组的中间这个声明。所以,问题是:中位数的中位数能有多坏?但首先,让我们举一个例子。假设数组有 15 15 15 个元素,分成 3 3 3 组,每组 5 5 5 个,如下:
{ 1 , 2 , 3 , 10 , 11 } , { 4 , 5 , 6 , 12 , 13 } , { 7 , 8 , 9 , 14 , 15 } \{1, 2, 3, 10, 11\}, \{4, 5, 6, 12, 13\}, \{7, 8, 9, 14, 15\} {1,2,3,10,11},{4,5,6,12,13},{7,8,9,14,15}
在这种情况下,中位数是 3 3 3, 6 6 6 和 9 9 9,中位数的中位数 p p p 是 6 6 6。有 5 5 5 个元素小于 p p p, 9 9 9 个元素大于 p p p。
一般来说,最坏情况是什么?如果有 g = n / 5 g=n/5 g=n/5 组,那么我们知道在至少 ? g / 2 ? ?g/2? ?g/2? (那些中位数 ≤ p ≤p ≤p 的组)中至少有 3 3 3 个元素 ≤ p ≤p ≤p。因此, ≤ p ≤p ≤p 的元素总数至少是 3 ? g / 2 ? ≥ 3 n / 10 3?g/2? ≥ 3n/10 3?g/2?≥3n/10。类似地, ≥ p ≥p ≥p 的元素总数也至少是 3 ? g / 2 ? ≥ 3 n / 10 3?g/2? ≥ 3n/10 3?g/2?≥3n/10。
最后,让我们求解这个递归关系。我们已经通过“猜测和检查”的方法解决了很多递归关系,这里也适用,但是我们怎么才能一眼看出答案是线性的呢?一种方法是考虑你之前课程中可能讨论过的递归树的“砖块”视图。
特别是,针对递归关系(1)构建递归树,使每个节点的宽度与其中的数量相同:
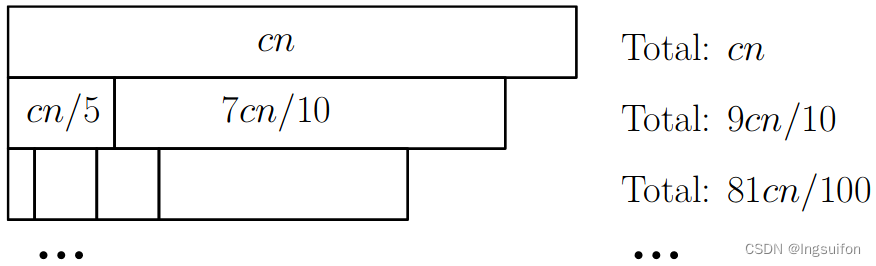
请注意,即使这堆砖块永远继续向下,总和也最多为
c n ( 1 + ( 9 / 10 ) + ( 9 / 10 ) 2 + ( 9 / 10 ) 3 + . . . ) c n (1 + (9/10) + (9/10)^2 + (9/10)^3 + . . .) cn(1+(9/10)+(9/10)2+(9/10)3+...)
最多为 10 c n 10cn 10cn。这就证明了定理。
请注意,在我们分析递归关系(1)时,我们使用的关键属性是 n / 5 + 7 n / 10 < n n/5+7n/10 < n n/5+7n/10<n。更一般地说,我们在这里看到,如果我们有一个大小为 n n n 的问题,我们可以通过在总大小最多为 ( 1 ? ε ) n (1?ε)n (1?ε)n 的碎片上执行递归调用来解决它(其中 ε > 0 ε>0 ε>0 是某个常数,外加一些 O ( n ) O(n) O(n) 的工作),那么花费的总时间将仅仅是线性的 n n n。
定理3 对于常数 c c c 和 a 1 , . . . , a k a_1,... ,a_k a1?,...,ak?,满足 a 1 + . . . + a k < 1 a_1+...+a_k<1 a1?+...+ak?<1,递归关系 T ( n ) ≤ T ( a 1 n ) + T ( a 2 n ) + . . . T ( a k n ) + c n T(n)≤T(a_1n)+T(a_2n)+...T(a_kn)+cn T(n)≤T(a1?n)+T(a2?n)+...T(ak?n)+cn 的解为 T ( n ) = O ( n ) T(n)= O(n) T(n)=O(n)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SD-WAN企业组网场景深度解析
- SourceTree修改仓库密码
- python&Django&mysql校园宿舍管理系统07558-计算机毕业设计项目选题推荐(附源码)
- React-Native环境搭建(IOS)
- react 第一个项目
- Python资源库
- Java (省市区三级联动),可扩展到4级或者5级(目前全网最新)
- Spring Boot3.2.2整合MyBatis Plus3.5.5
- 大数据技术在民生资金专项审计中的应用
- Mac电脑如何彻底删除清除数据?CleanMyMac X软件更专业