Clickhouse写入分布式表还是本地表
发布时间:2024年01月15日
先说结果,我们是写入分布式表。
网上的资料和ClickHouse云服务的同事都建议写入本地表。分布式表实际上是一张逻辑表并不存储真实的物理数据。如查询分布式表,分布式表会把查询请求发到每一个分片的本地表上进行查询,然后再集合每个分片本地表的结果,汇总之后再返回。写入分布式表,分布式表会根据一定规则,将写入的数据按照规则存储到不同的分片上。如果写入分布式表也只是单纯的网络转发,影响也不大,但是写入分布式表并非单纯的转发,实际情况见下图。
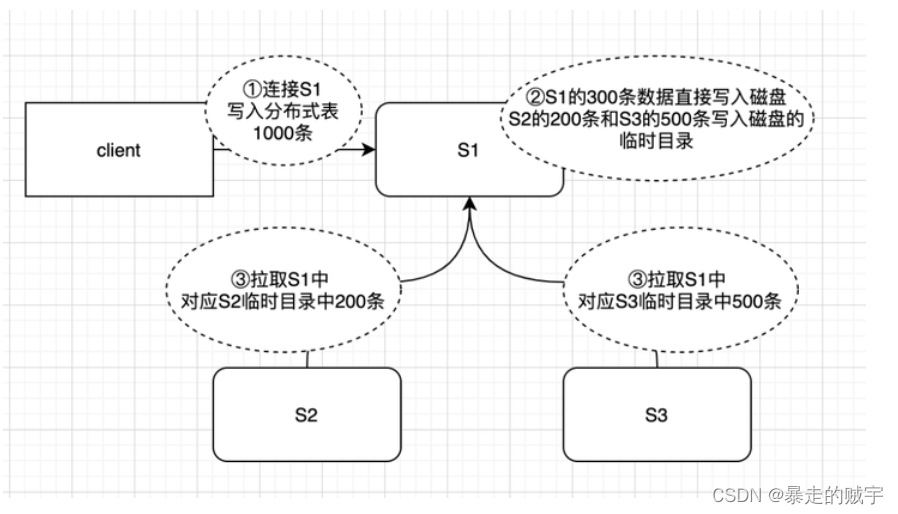
有三个分片S1、S2、S3,客户端连接到S1节点,进行写入分布式表操作。
-
第一步:写入分布式表1000条数据,分布式表会根据路由规则,假设按照规则300条分配到S1,200条到S2,500条到S3
-
第二步:client给过来1000条数据,属于S1的300条数据直接写入磁盘,数据S2,S3的数据也会写入到S1的临时目录
-
第三步:S2,S3接收到zk的变更通知,生成拉取S1中当前分片对应的临时目录数据的任务,并且将任务放到一个队列,等到某个时机会将数据拉到自身节点。
从分布式表的写入方式可以看到,会将所有数据落到client连接分片的磁盘上。如果数据量大,磁盘的IO会造成瓶颈。并且MergeTree系列引擎存在合并行为,本身就有写放大(一条数据合并多次),占用一定磁盘性能。在网上看到写入本地表的案例都是日增量百亿,千亿。我们选择写入分布式表主要有两点,一是简单,因为写入本地表需要改造代码,自己指定写入哪个节点,另一个是开发过程中写入本地表并未出现什么严重的性能瓶颈。双十一期间数据日增3000W(合并后)行并未造成写入压力。如果后续产生瓶颈,可能会放弃写入分布式表。
文章来源:https://blog.csdn.net/xxy1022_/article/details/135573056
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 语音识别之百度语音试用和OpenAiGPT开源Whisper使用
- HarmonyOS4.0系统性深入开发01应用模型的构成要素
- XV7021BB陀螺仪传感器
- Python之文件的相关操作
- RPC基础知识总结
- vscode配置latex环境
- 用这个技术管理备用电源!同事下巴都惊掉了!
- vscode(visual studio code) 免密登陆服务器
- P1428 小鱼比可爱
- 卫星导航实践题Satellite-navigation-practice-questions-I( L1频点C/A码信号的并行捕获)