oh no!mysql数据丢失了
背景
业务开发反馈,使用的的mysql数据库,某表数据部分丢了,需要还原这张表最近的备份数据排查、修复。
数据丢失,严重了!!!
排查解决历程
第一次排查
还原数据
线上数据,我们的策略通过mysqldump每小时备份一次,根据业务提供的时间节点,找到相邻的最近时间的备份数据,还原到测试环境,提供给业务开发,跟线上数据比对,找出的丢失的数据进行还原。
业务开发反馈,还原的数据没有丢失的数据,接着继续还原了几个备份数据,结果还是说没有,但业务咬死数据就是丢失了。
我只能怀疑,代码是里面是不是有delete语句删除的,或者本地通过数据库工具直连线上数据库,这种做法,是非常不安全的,非常不推荐,线上数据库的权限就应该牢牢的掌握在dba的手里。
review代码
下载业务代码,查找丢失的数据的表,是否存在delete语句,结果找了一圈,没有,唉。那只能怀疑是不是人为通过数据库工具连上线上数据库删除的,只能看下binlog日志了
查看binglog日志
binlog用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。binlog是MySQL的逻辑日志,并且由Server层进行记录,使用任何存储引擎的MySQL数据库都会记录binlog日志。
- 逻辑日志:可以简单理解为记录的就是SQL语句。
- 物理日志:因为MySQL数据最终是保存在数据页中的,物理日志记录的就是数据页变更
懵逼了,日志里面也没发现数据丢失表,对应的delete语句。排查就这样结束了…
结论
数据丢失了,原因也没找到,一口大锅飞过来了,业务开发给出的事故报告,运维组维护的mysql中间不稳定导致数据丢失,原因未找到。这个锅也只能背了,学艺不精,怪谁呢?
锅背了,该有的策略还得加上,杜绝下次出现这种事故的发生。终极大招-审计日志
审计日志
数据库审计功能主要将用户对数据库的各类操作行为记录审计日志,以便日后进行跟踪、查询、分析,以实现对用户操作的监控和审计。审计是一项非常重要的工作,也是企业数据安全体系的重要组成部分,等保评测中也要求有审计日志。对于 DBA 而言,数据库审计也极其重要,特别是发生人为事故后,审计日志便于我们进行责任追溯,问题查找。
审计日志攻略,这篇文章无意间看到,写的挺好,可以看下mysql的审计日志是怎么玩的。有区别的地方,我使用的审计插件是Percona Audit Log Plugin
呵呵,审计日志开启,我就看看数据到底是怎么丢失的。
第二次排查
没过多久,业务反馈数据又丢了,查看审计日志,找出对丢失数据表的操作,结果没找到delete 、truncate删除表的数据的语句,说明数据不存在删除,也不存在丢失一说。
我弱弱问了一句,你们判断数据丢失的依据是什么?重点来了,自增id不连续,中间缺少了一部分数据
这玩笑开大了,这种结论都能下,浪费我这么多精力
mysql自增策略,只保证递增,没说连续,再说了业务数据依赖自增,也是非常不合理的。
我怀疑是数据没插入进去,回滚导致的吧,查看binlog日志,完全印证我的猜想,看图:
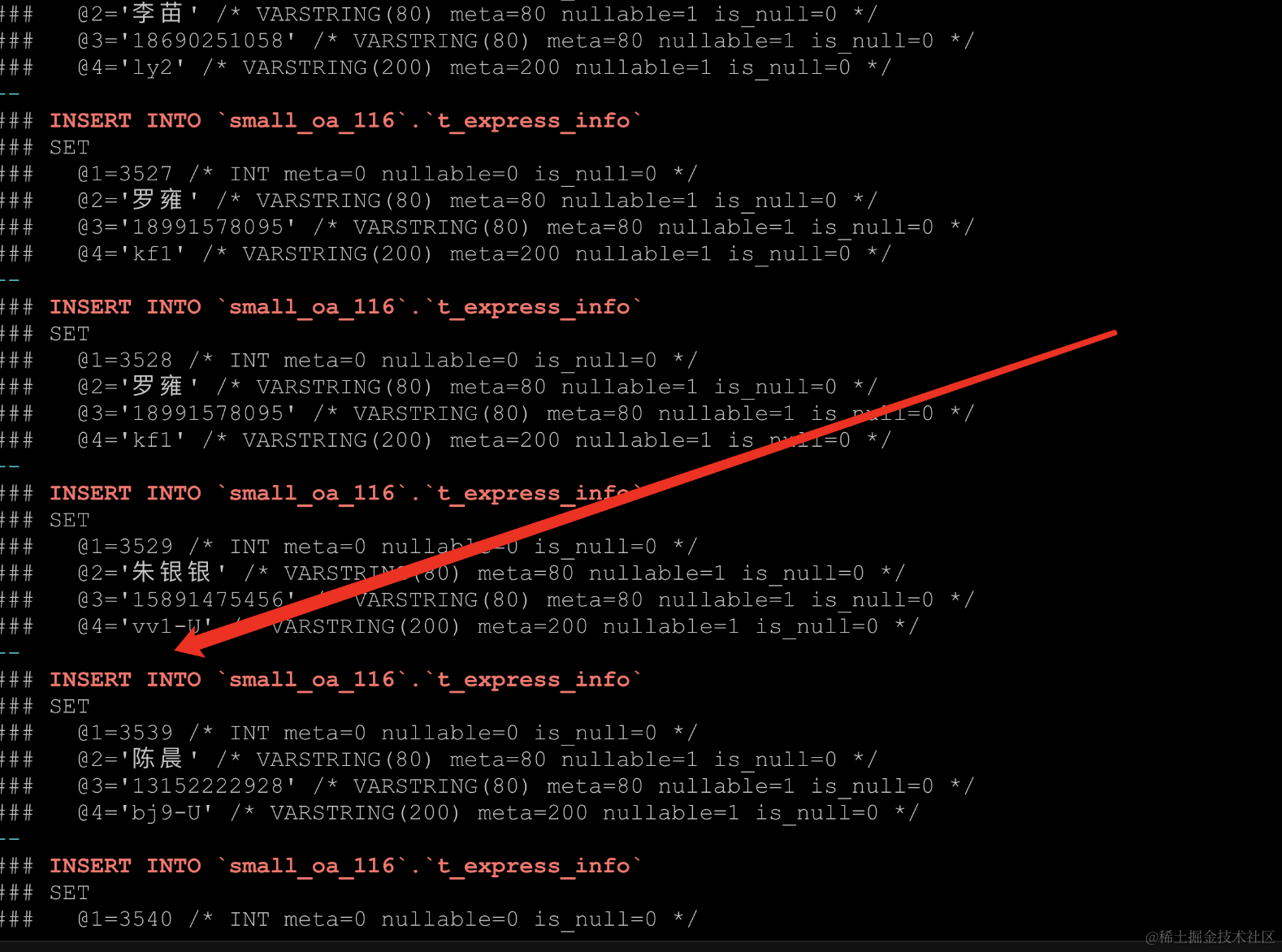
业务的反馈:

跟binlog记录的数据完全吻合,查找应用的日志,也发现了,对应这张表的数据插入有回滚异常的日志记录。
mysql自增主键为什么不是连续的,这是今天的知识点,跟着我一起分析下
mysql自增主键为什么不是连续的
不连续的三种场景
先讲下导致不联系的三种场景,大家可以自己试试
- 唯一键冲突导致自增主键不连续
- 事务回滚导致自增主键不连续
- 批量插入数据导致自增主键不连续
上面都场景,就是回滚导致的不连续
自增值保存在哪
-
在 MySQL 5.7 及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值 max(id),然后将 max(id)+1 作为这个表当前的自增值。
-
举例来说,如果一个表当前数据行里最大的 id 是 10,AUTO_INCREMENT=11。这时候,我们删除 id=10 的行,AUTO_INCREMENT 还是 11。但如果马上重启实例,重启后这个表的 AUTO_INCREMENT 就会变成 10。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
-
在 MySQL 8.0 版本,将自增值的变更记录在了 redo log 中,重启的时候依靠 redo log 恢复重启之前的值。
自增值的修改机制
在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
- 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段;
- 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。
假设,某次要插入的值是 X,当前的自增值是 Y。
- 如果 X<Y,那么这个表的自增值不变;
- 如果 X≥Y,就需要把当前自增值修改为新的自增值。
新的自增值生成算法是:从 auto_increment_offset 开始,以 auto_increment_increment 为步长,持续叠加,直到找到第一个大于 X 的值,作为新的自增值。
自增值为什么不能回退
自增值为什么不能回退,主要是为了数据库的性能,保证递增,不保持连续。这里有个自增锁的概念
自增 id 锁并不是一个事务锁,而是每次申请完就马上释放,以便允许别的事务再申请。如果自增id的锁是个事务锁,每次事务申请id后,处理完逻辑,再提交事务,想想这样非常影响插入的性能。
总结
对使用的技术,还是得好好研究,不要轻易下结论,方向偏了,费时费力。
写作不易,刚好你看到,刚好对你有帮助,动动小手,点点赞,有疑问的欢迎留言或者私信讨论
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Nacos与Eureka
- 手把手教你如何快速定位bug,如何编写测试用例,快来观摩......
- 台州市内旅游景点门票门户网站(JSP+java+springmvc+mysql+MyBatis)
- 10 标准库的硬件I2C驱动mpu6050模块
- 洛谷-P1802-5 倍经验日
- 数据结构(Chapter One -01)
- OpenTCS IDEA 全流程搭建和运行指南
- BASIC语言编辑器:PureBasic for Mac
- 第十二章Session
- Valheim英灵神殿2456-2457-2458端口TCP和UDP开通