数据分析案例-外国电影票房数据可视化分析(文末送书)
?
🤵?♂? 个人主页:@艾派森的个人主页
?🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
????????外国电影票房数据的可视化分析是一项有益的研究,通过对电影票房数据进行可视化呈现,可以深入挖掘影响因素、趋势和模式,为电影产业的决策制定、市场规划和投资提供重要参考。以下是该实验的背景:
-
全球电影市场的扩张: 随着全球化的发展,外国电影在国际市场上的份额逐渐增加。了解外国电影在不同国家和地区的票房表现,可以为电影制片方、发行方以及相关从业者提供参考,帮助他们更好地规划国际上映策略和市场推广。
-
文化差异与受众喜好: 不同国家和地区有着独特的文化、语言和审美趣味,这些因素对电影的受众喜好产生深远影响。通过可视化分析外国电影在不同市场的票房表现,可以揭示出文化差异对电影市场的影响,帮助制片方更好地理解目标受众。
-
市场趋势和热点分析: 通过对外国电影票房数据的时间趋势分析,可以识别出不同时间段内的热门类型、导演或演员,帮助行业从业者把握市场趋势,更好地进行投资和项目规划。
-
数据驱动决策: 随着大数据和数据科学技术的发展,电影产业也越来越注重数据驱动的决策。通过可视化分析外国电影票房数据,可以提供直观的数据呈现,帮助从业者迅速理解市场格局,为决策提供更科学的依据。
-
竞争分析与市场定位: 了解外国电影在全球市场的竞争格局,分析不同电影的成功或失败因素,有助于制片方更好地制定市场定位策略,避免竞争风险,提高影片在国际市场上的竞争力。
????????通过对外国电影票房数据的可视化分析,可以为电影从业者提供全面的市场洞察,促使他们更加精准地应对市场变化,优化电影制作和推广策略。
2.数据集介绍
? ? ? ? 该数据集来源于kaggle,该数据集包含1995年至2018年上映的电影类型统计数据,原始数据集共有300条,9个变量,各变量含义解释如下:
Genre:电影的类别或类型。(分类)
Year:电影发行的年份。(数字)
Movies Released :特定类型和年份发行的电影数量。(数字)
Gross:该类型和年份的电影产生的总收入。(数字)
Tickets Sold:该类型和年份的电影售出门票总数。(数字)
Inflation-Adjusted Gross:考虑到货币价值随时间的变化,根据通货膨胀进行调整的总收入。(数字)
Top Movie:该类型和年份中票房最高的电影的标题。(文本)
Top Movie Gross (That Year):该类型和年份中票房最高的电影产生的总收入。(数字)
Top Movie Inflation-Adjusted Gross (That Year):根据该类型和年份的通货膨胀调整后票房最高的电影的总收入。(数字)
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
导入数据分析常用的第三方库并加载数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.subplots as sp
df = pd.read_csv("movies_data.csv")
df.head()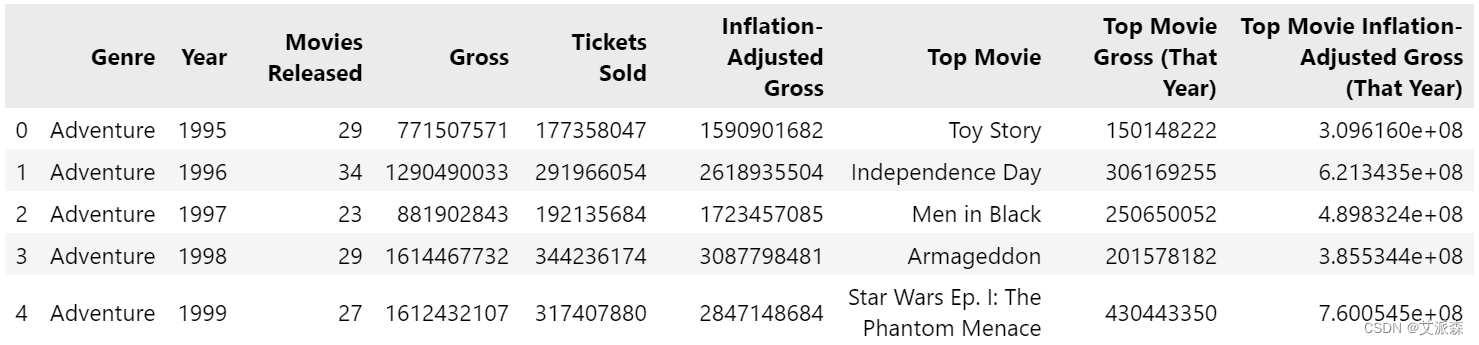
查看数据大小
?
查看数据基本信息

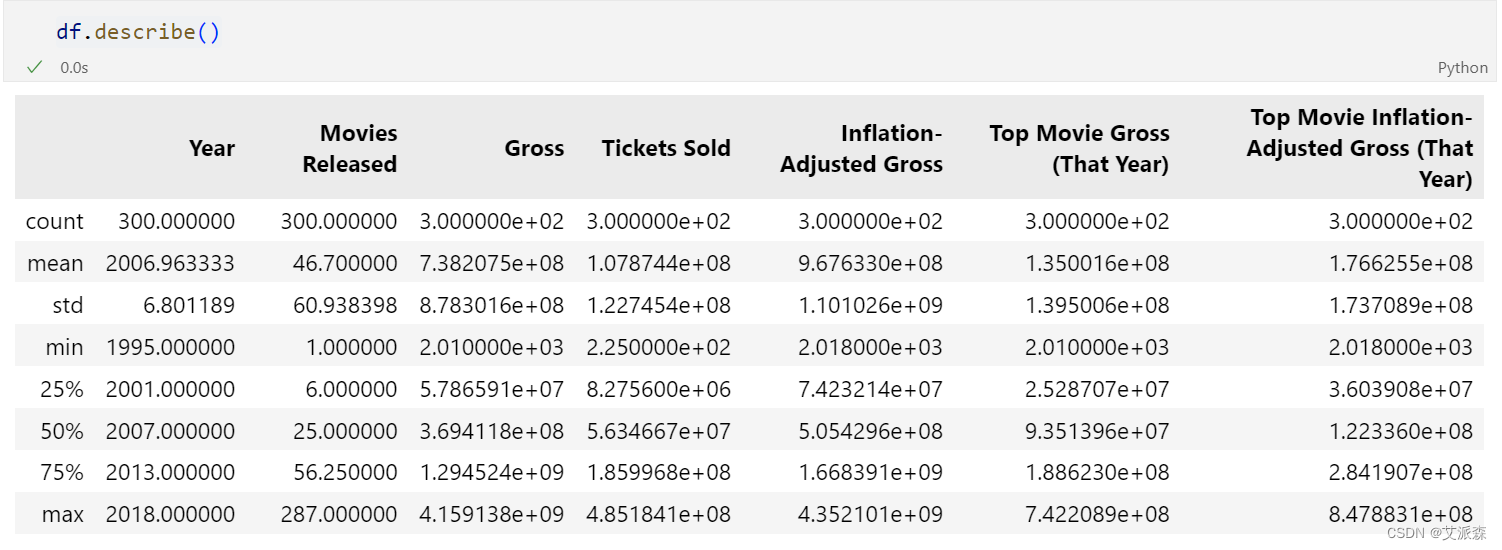
查看数值型变量的描述性统计
查看非数值型变量的描述性统计

统计缺失值情况

检测是否存在重复值?
?
结果为False,说明不存在
5.数据可视化
5.1基于门票销售和发行数量的流行类型
# 基于门票销售和发行数量的流行类型
# 根据上映的电影数量找到受欢迎的类型
genre_movies_released = df.groupby('Genre')['Movies Released'].sum().sort_values(ascending=False)
print("Popular genres based on Movies Released:")
print(genre_movies_released.head())
# 根据售出的门票总数来查找受欢迎的类型
genre_tickets_sold = df.groupby('Genre')['Tickets Sold'].sum().sort_values(ascending=False)
print("\nPopular genres based on Tickets Sold:")
print(genre_tickets_sold.head())
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
genre_movies_released.head().plot(kind='bar', ax=axes[0], color='skyblue')
axes[0].set_title('Top Genres by Movies Released')
axes[0].set_ylabel('Total Movies Released')
genre_tickets_sold.head().plot(kind='bar', ax=axes[1], color='lightcoral')
axes[1].set_title('Top Genres by Tickets Sold')
axes[1].set_ylabel('Total Tickets Sold')
plt.tight_layout()
plt.show()

5.2类型和收益分析
# 类型和收益分析
genre_gross = df.groupby('Genre')['Gross'].sum().sort_values(ascending=False).head()
genre_inflation_adjusted_gross = df.groupby('Genre')['Inflation-Adjusted Gross'].sum().sort_values(ascending=False).head()
genre_top_movie_gross = df.groupby('Genre')['Top Movie Gross (That Year)'].max().sort_values(ascending=False).head()
fig = make_subplots(rows=3, cols=1, subplot_titles=['Top Genres by Gross Revenue', 'Top Genres by Inflation-Adjusted Gross Revenue', 'Top Genres by Top Movie Gross (That Year)'])
fig.add_trace(go.Bar(x=genre_gross.index, y=genre_gross.values, name='Gross Revenue', marker_color='skyblue'), row=1, col=1)
fig.add_trace(go.Bar(x=genre_inflation_adjusted_gross.index, y=genre_inflation_adjusted_gross.values, name='Inflation-Adjusted Gross Revenue', marker_color='lightcoral'), row=2, col=1)
fig.add_trace(go.Bar(x=genre_top_movie_gross.index, y=genre_top_movie_gross.values, name='Top Movie Gross (That Year)', marker_color='lightgreen'), row=3, col=1)
fig.update_layout(height=900, showlegend=False, title_text="Financial Success of Genres")
fig.update_xaxes(title_text="Genres", row=3, col=1)
fig.update_yaxes(title_text="Total Gross Revenue", row=1, col=1)
fig.update_yaxes(title_text="Total Inflation-Adjusted Gross Revenue", row=2, col=1)
fig.update_yaxes(title_text="Top Movie Gross (That Year)", row=3, col=1)
fig.show()
5.3多年来的类型趋势和分析
# 多年来的类型趋势和分析
selected_genres = ['Action', 'Comedy', 'Drama', 'Adventure']
filtered_df = df[df['Genre'].isin(selected_genres)]
fig = px.line(filtered_df, x='Year', y='Movies Released', color='Genre',
title='Movie Releases Over Time for Selected Genres',
labels={'Movies Released': 'Number of Movies Released'},
line_shape='linear')
fig.show()
# 为不同年份的总收入创建一个交互式折线图
fig = px.line(filtered_df, x='Year', y='Gross', color='Genre',
title='Gross Revenue Over Time for Selected Genres',
labels={'Gross': 'Total Gross Revenue'},
line_shape='linear')
fig.show()
5.4一段时间内选定类型中票房最高的电影
# 一段时间内选定类型中票房最高的电影
selected_genres = ['Action', 'Comedy', 'Drama', 'Adventure']
filtered_df = df[df['Genre'].isin(selected_genres)]
# 创建一个交互式条形图来显示每种类型和年份中票房最高的电影
fig = px.bar(filtered_df, x='Year', y='Top Movie Gross (That Year)', color='Genre',
title='Highest-Grossing Movies in Selected Genres Over Time',
labels={'Top Movie Gross (That Year)': 'Gross Revenue'},
text='Top Movie', height=500)
fig.update_traces(textposition='outside')
fig.show()
5.5多年来的类型分布
# 多年来的类型分布
# 多年来类型分布的堆叠区域图
fig = px.area(df, x='Year', y='Movies Released', color='Genre',
title='Genre Distribution Over the Years',
labels={'Movies Released': 'Number of Movies Released'},
height=500)
fig.show()
5.6受众参与分析
# 受众参与分析
# 观众参与的散点图
fig = px.scatter(df, x='Tickets Sold', y='Gross', color='Genre',
title='Audience Engagement by Genre',
labels={'Tickets Sold': 'Number of Tickets Sold', 'Gross': 'Total Gross Revenue'},
height=500)
fig.show()
5.7历年最佳电影表现
# 历年最佳电影表现
# 随时间变化的顶级电影表现的折线图
fig = px.line(df, x='Year', y='Top Movie Gross (That Year)', color='Genre',
title='Top Movie Performance Over Time',
labels={'Top Movie Gross (That Year)': 'Gross Revenue'},
height=500)
fig.show()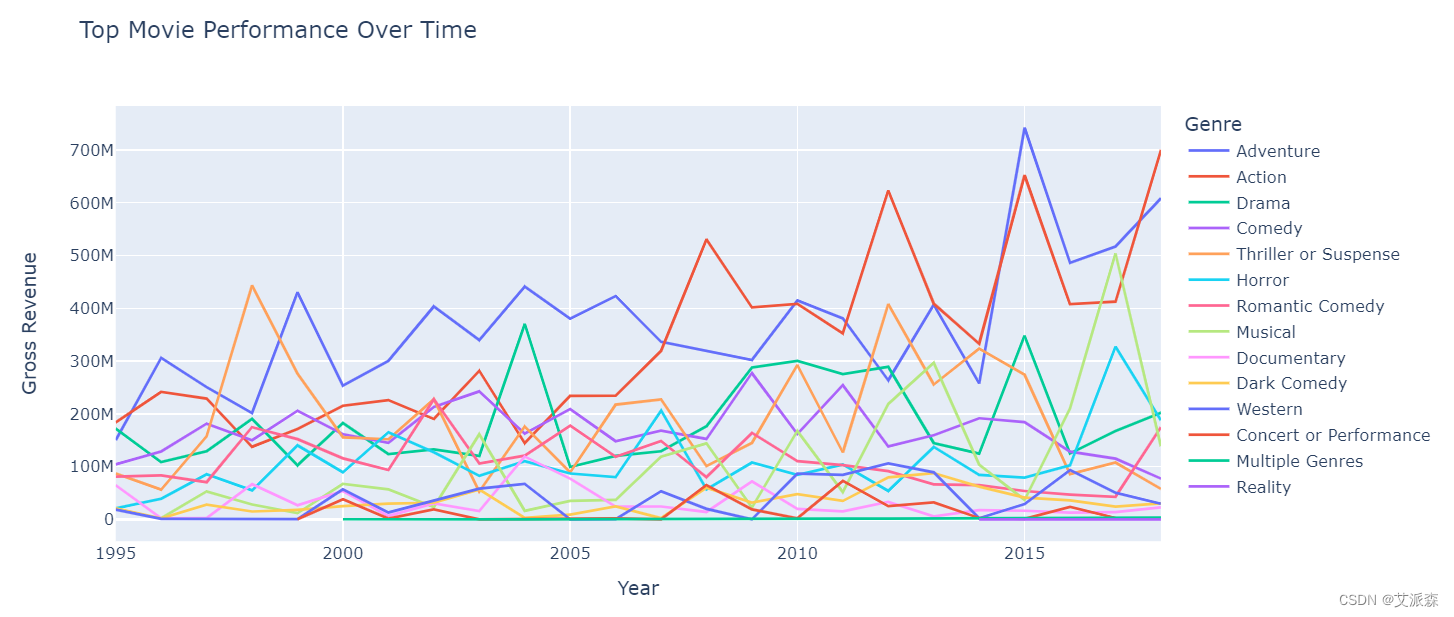
5.8按类型划分的每部电影平均收入
# 按类型划分的每部电影平均收入
# 按类型计算每部电影的平均收入
df['Average Revenue per Movie'] = df['Gross'] / df['Movies Released']
# 按类型划分的每部电影平均收入柱状图
fig = px.bar(df, x='Genre', y='Average Revenue per Movie',
title='Average Revenue per Movie by Genre',
labels={'Average Revenue per Movie': 'Average Revenue per Movie'},
height=500)
fig.show()
5.9不同类型的门票销售和发行
# 不同类型的门票销售和发行
fig = px.violin(df, x='Genre', y='Tickets Sold',
title='Genre-wise Ticket Sales Distribution',
labels={'Tickets Sold': 'Number of Tickets Sold'},
height=500)
fig.show()
5.10通货膨胀调整后总收益的类型趋势
# 通货膨胀调整后总收益的类型趋势
fig = px.line(df, x='Year', y='Inflation-Adjusted Gross', color='Genre',
title='Genre Trends in Inflation-Adjusted Gross Revenue',
labels={'Inflation-Adjusted Gross': 'Inflation-Adjusted Gross Revenue'},
height=500)
fig.show()
5.11每个类型和收入的顶级电影
# 每个类型和收入的顶级电影
unique_top_movies_count = df.groupby('Genre')['Top Movie'].nunique().sort_values(ascending=False)
top_movies_gross = df.groupby('Top Movie')['Top Movie Gross (That Year)'].max().sort_values(ascending=False).head(10)
fig = sp.make_subplots(rows=3, cols=1, subplot_titles=['Count of Unique Top Movies per Genre', 'Top Movies with the Highest Gross Revenue', 'Distribution of Gross Revenue for Top Movies'])
fig.add_trace(go.Bar(x=unique_top_movies_count.index, y=unique_top_movies_count.values),
row=1, col=1)
fig.add_trace(go.Bar(x=top_movies_gross.index, y=top_movies_gross.values),
row=2, col=1)
fig.add_trace(go.Box(x=df['Top Movie'], y=df['Top Movie Gross (That Year)']),
row=3, col=1)
fig.update_layout(height=1000, showlegend=False, title_text="Top Movie Analysis")
fig.show()
?文末推荐与福利
《AI时代Python金融大数据分析实战》免费包邮送出3本!
?
内容简介:
? ? ? ??本书是一本针对金融领域的数据分析和机器学习应用的实用指南。本书以ChatGPT为核心技术,结合Python编程和金融领域的基础知识,介绍如何利用ChatGPT处理和分析金融大数据,进行预测建模和智能决策。
????????通过阅读本书,读者将掌握使用ChatGPT和其他工具进行金融大数据分析的基本原理和方法。无论是金融行业 从业者还是数据分析员,都可以从本书中获得宝贵的实用知识,提升在金融领域的数据分析和决策能力。无论是对于初学者还是有一定经验的专业人士,本书都能够提供实用的案例和技巧,帮助读者更好地应用ChatGPT和其他技术解决金融领域的实际问题。
编辑推荐:? ? ?
1.金融大数据分析新模式:让金融大数据分析更高效、更快捷、更完美。
2.全流程解析:涵盖架构设计的不同应用场景,介绍从金融大数据分析Python基础、获取、基础库、数据库,再到预处理与清洗、分析、建模等关键环节。
3.实战检验:ChatGPT结合多种金融大数据分析工具及案例实操讲解,理解更加透彻。
4.快速提高金融大数据分析效率:揭秘ChatGPT与金融大数据分析高效融合的核心方法论和实践经验。
5.赠送资源:赠送教学视频及配套工具,供读者下载学习。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2024-1-6?20:00:00
?名单公布时间:2024-1-6?21:00:00?
?
资料获取,更多粉丝福利,关注下方公众号获取

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Jmeter 性能 —— 监控服务器!
- 代码随想录算法训练营第十四天 |二叉树理论基础、递归遍历、迭代遍历
- 力扣热题 100
- 【VTKExamples::Meshes】第一期 FillHoles
- vue3若依框架,在页面中点击新增按钮跳转到新的页面,不是弹框,如何实现
- Flex弹性布局给子组件设置flex-grow权重属性不生效问题
- C++模板进阶
- 景联文科技大模型数据集更新!教育题库新增高质量数学题、逻辑推理题及英文题
- 数据库(多对多表关系及关联查询)
- go interface 基本用法