负载均衡案例:如何只用2GB内存统计20亿个整数中出现次数最多的整数
基于python实现。
如果是常规的小型文件,我们可以迅速地想到要建立字典。
以数字为key,以数字的出现次数为value,建立<int,int>类型的键值对存入字典,然后使用 max 函数结合字典的 items 方法来找到一个字典中 value 最大的 key即可。
在计算机底层中,<int, int>类型的键值对所占的大小为8个字节,20亿个整数极端情况下如果产生了20亿个键值对那么仅仅是存储就需要16GB的内存,更别论python中数据类型还封装了更多属性和方法,以及后续操作、计算机的其他程序操作也同样需要资源了。
基于抽象和拆分的编程思想,我们可以进行将操作步骤进行如下划分:
1、创建合理数量的小文件。
2、将20亿个数据分配进入小文件中,需要注意:相同的整数要在同一个文件中,并且文件大小尽量均匀。
3、计算每个文件中出现次数最多的整数,最后对比得出结果。
在一步步进行具体操作之前,我们先模拟创建出有20亿个整数(约16GB)的文件,并且存入硬盘。
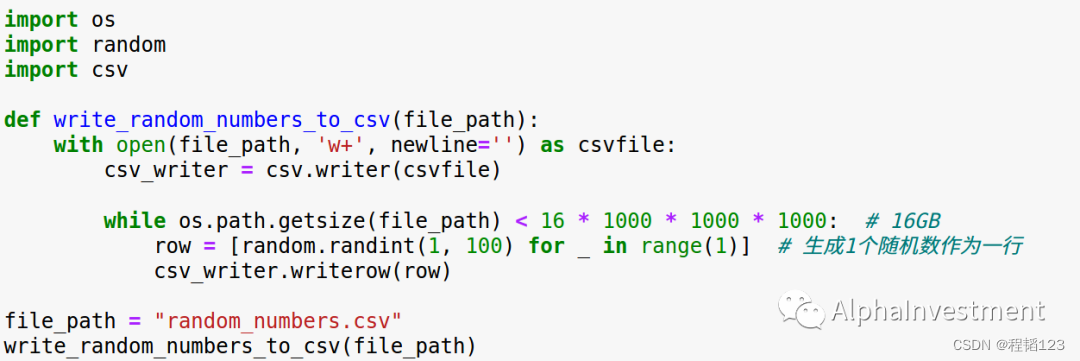
其次,我们需要确认创建多少个小文件。
20亿的数据极端情况下至少需要16GB的内存,如果平均拆成10个小文件,每个小文件约有2亿数据,键值对存储约需要1.6GB内存,正好满足不高于2GB的内存要求。为了保险可以多拆几个文件。如果凭借经验知道这20亿个数据中有较为不均匀的数据分布,也可根据经验进行数量拓展。因为我产生的数据比较了解,因此我就选择拆出10个小文件。
接着,我们需要将20亿个数据分入10个文件中,并且相同的整数要在同一个文件。
这里介绍一下哈希算法,哈希算法的具体定义可以上网查询。简单来说可以把哈希算法比作一个编号工具,我们给哈希算法一个数据,无论是什么类型的皆可,它经过一系列复杂的数学运算,就会给这个数据一个编号,这个编号是一般是一个长长的整数,通常情况下编号会和数据对应,如果是相同的数据那么得到的编号是完全一致的。如果我们给这个哈希算法喂了大量的数据,那么它就会吐出很多对应的编号,这些编号具有强随机分布的特征,也就是在哈希值的范围内分布很均匀。
我们把20亿个数据通通喂入哈希算法,再把这些编号对10取余进行散列,20亿个数据就被分入了10个文件中,以此可以完成把相同的数据分入同一个文件。说起来抽象其实写起来很简单,各位看看代码就明白了。
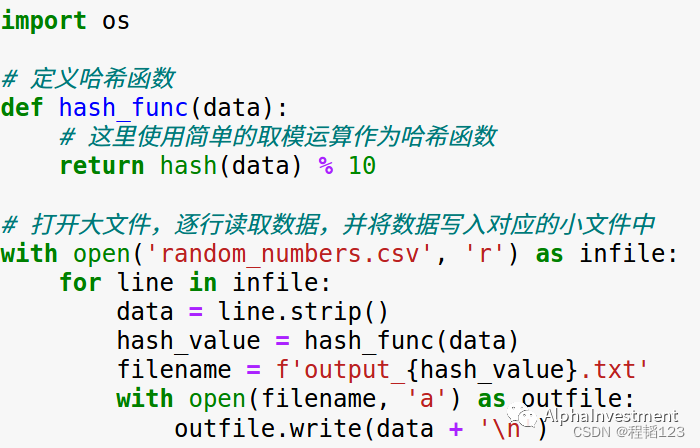
有些同学可能就问了,为什么要先哈希再取余呢?直接取余不行吗?用哈希算法是为了解决2方面的问题,一方面是我们实务中接触的数据有可能不是整数,另一方面是如果直接取余然后分配可能会导致文件之间大小不均衡,而哈希函数产生的编号分布是十分均匀的,取余之后,余数的分布也会很均匀,因此根据余数把整数分配进入文件的数据也会很均匀。
最后计算每个文件中出现次数最多的整数,再进行对比就可以得到结果了。根据上述的哈希算法的特征,每个文件的不同的整数不会超过2个亿,因此我们的内存是够用的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!